主动学习简介
- 主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。
- 主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。
- 主动学习的动机在于认识到并非所有标有标签的样本都同等重要。
active learning的基本思想
主动学习的模型如下:
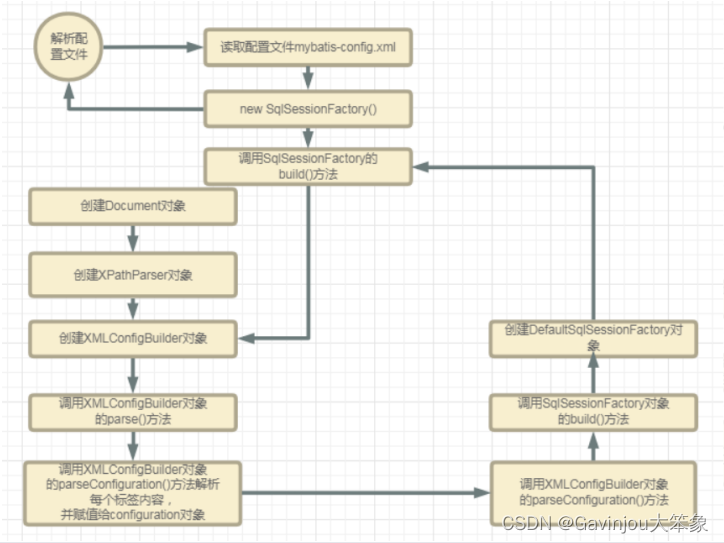
A=(C,Q,S,L,U),
其中 C 为一组或者一个分类器,L是用于训练已标注的样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查询。

在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。 不确定性越大代表信息熵越大,包含的信息越丰富;而差异性越大代表选择的样本能够更全面地代表整个数据集。
对于不确定性,我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。
那么差异性怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以新获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。
主动学习基础策略
常见主动学习策略
基于数据流的主动学习方法
基于流(stream-based)的主动学习中,未标记的样例按先后顺序逐个提交给选择引擎,由选择引擎决定是否标注当前提交的样例,如果不标注,则将其丢弃。
在基于流的主动学习中,所有训练样本的集合以流的形式呈现给算法。每个样本都被单独发送给算法。算法必须立即决定是否标记这个示例。从这个池中选择的训练样本由oracle(人工的行业专家)标记,在显示下一个样本之前,该标记立即由算法接收。
由于基于流的算法不能对未标注样例逐一比较,需要对样例的相应评价指标设定阈值,当提交给选择引擎的样例评价指标超过阈值,则进行标注,但这种方法需要针对不同的任务进行调整,所以难以作为一种成熟的方法投入使用。
基于数据池的主动学习方法
基于池(pool-based)的主动学习中则维护一个未标注样例的集合,由选择引擎在该集合中选择当前要标注的样例。
在基于池的抽样中,训练样本从一个大的未标记数据池中选择。从这个池中选择的训练样本由oracle标记。
基于查询的主动学习方法
这种基于委员会查询的方法使用多个模型而不是一个模型。
委员会查询(Query by Committee),它维护一个模型集合(集合被称为委员会),通过查询(投票)选择最“有争议”的数据点作为下一个需要标记的数据点。通过这种委员会可的模式以克服一个单一模型所能表达的限制性假设(并且在任务开始时我们也不知道应该使用什么假设)。
有两个假设前提:
- 所有模型在已标注数据上结果一致
- 所有模型对于未标注结果样本集存在部分分歧
不确定性度量
识别接下来需要标记的最有价值的样本的过程被称为“抽样策略”或“查询策略”。在该过程中的评分函数称为“acquisition function”。该分数的含义是:得分越高的数据点被标记后,对模型训练后的产生价值就越高。有很多中不同的采样策略,例如不确定性抽样,多样性采样等,在本节中,我们将仅关注最常用策略的不确定性度量。
不确定性抽样是一组技术,可以用于识别当前机器学习模型中的决策边界附近的未标记样本。这里信息最丰富的例子是分类器最不确定的例子。模型最不确定性的样本可能是在分类边界附近的数据。而我们模型学习的算法将通过观察这些分类最困难的样本来获得有关类边界的更多的信息。
参考
https://aistudio.baidu.com/aistudio/projectdetail/4897371
https://juejin.cn/post/7174224224733626375
rojectdetail/4897371
https://juejin.cn/post/7174224224733626375