CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.An Inverse Scaling Law for CLIP Training

标题:CLIP 训练的逆比例定律
作者:Xianhang Li, Zeyu Wang, Cihang Xie
文章链接:https://arxiv.org/abs/2305.07017
项目代码:https://github.com/UCSC-VLAA/CLIPA



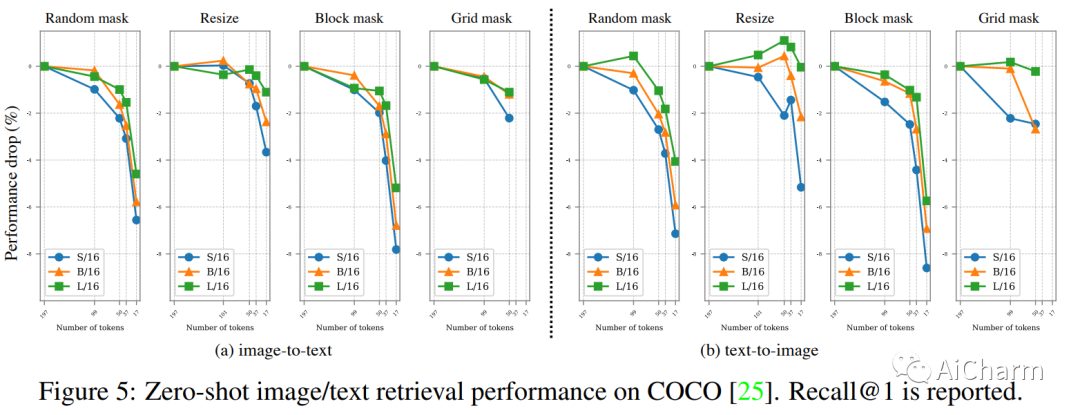
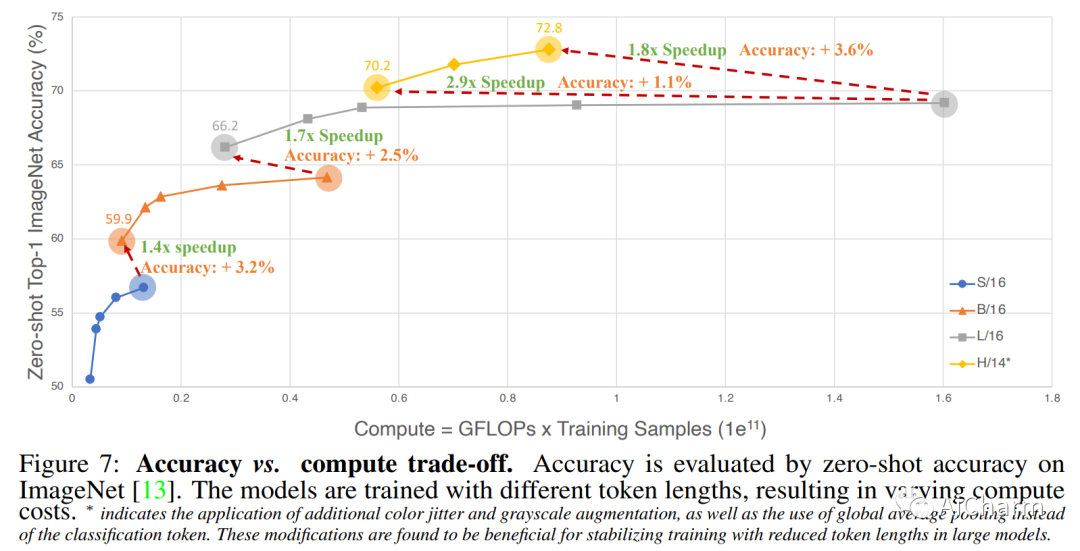

摘要:
CLIP 是第一个连接图像和文本的基础模型,最近在计算机视觉领域取得了许多突破。然而,其相关的培训成本高得令人望而却步,对其广泛探索构成了重大障碍。在本文中,我们提出了一个令人惊讶的发现,即 CLIP 训练存在逆比例定律,即使用的图像/文本编码器越大,可用于训练的图像/文本标记的序列长度越短。此外,我们展示了减少图像/文本标记长度的策略在确定该缩放定律的质量方面起着至关重要的作用。由于这一发现,即使使用学术资源,我们也能够成功地训练 CLIP。例如,在 A100 八 GPU 服务器上,我们的 CLIP 模型在 ~2 天内实现了 63.2% 的零样本 top-1 ImageNet 准确度,在 ~3 天内达到了 67.8%,在~4 天内达到了 69.3%。通过减少与 CLIP 相关的计算障碍,我们希望激发该领域的更多研究,尤其是来自学术界的研究。
2.InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning

标题:动态视频的自适应人类抠图
作者:Chung-Ching Lin, Jiang Wang, Kun Luo, Kevin Lin, Linjie Li, Lijuan Wang, Zicheng Liu
文章链接:https://arxiv.org/abs/2305.06500
项目代码:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip




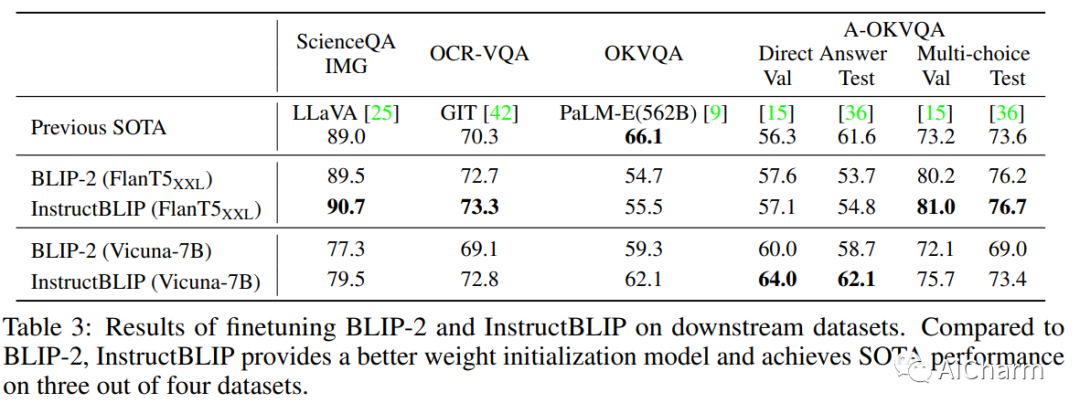
摘要:
在预训练和指令调优管道的驱动下,出现了可以解决各种语言领域任务的通用语言模型。然而,由于额外的视觉输入会增加任务差异,因此构建通用视觉语言模型具有挑战性。尽管视觉语言预训练已得到广泛研究,但视觉语言指令调优的探索相对较少。在本文中,我们基于预训练的 BLIP-2 模型对视觉语言指令调优进行了系统全面的研究。我们收集了各种 26 个公开可用的数据集,将它们转换为指令调优格式,并将它们分为两个集群,用于保持指令调优和保持零样本评估。此外,我们还引入了指令感知视觉特征提取,这是一种使模型能够提取针对给定指令定制的信息特征的关键方法。由此产生的 InstructBLIP 模型在所有 13 个保留数据集中实现了最先进的零样本性能,大大优于 BLIP-2 和更大的 Flamingo。当对单个下游任务进行微调时,我们的模型也会带来最先进的性能(例如,ScienceQA IMG 的准确率为 90.7%)。此外,我们定性地展示了 InstructBLIP 相对于并发多模态模型的优势。
3.Bot or Human? Detecting ChatGPT Imposters with A Single Question

标题:机器人还是人类?用一个问题检测 ChatGPT 冒名顶替者
作者:Hong Wang, Xuan Luo, Weizhi Wang, Xifeng Yan
文章链接:https://arxiv.org/abs/2304.05977
项目代码:https://github.com/hongwang600/FLAIR



摘要:
像 ChatGPT 这样的大型语言模型最近在自然语言理解和生成方面展示了令人印象深刻的能力,支持各种应用程序,包括翻译、论文写作和聊天。但是,有人担心它们可能会被滥用于恶意目的,例如欺诈或拒绝服务攻击。因此,开发检测参与对话的一方是机器人还是人类的方法至关重要。在本文中,我们提出了一个名为 FLAIR 的框架,即通过单个查询和响应寻找大型语言模型的真实性,以在线方式检测对话机器人。具体来说,我们针对可以有效区分人类用户和机器人的单个问题场景。这些问题分为两类:一类是人类容易但机器人很难的问题(例如,计数、替换、定位、噪声过滤和 ASCII 艺术),另一类是机器人容易但人类很难的问题(例如记忆)和计算)。我们的方法显示了这些问题在有效性方面的不同优势,为在线服务提供商提供了一种新方法来保护自己免受恶意活动的侵害并确保他们为真实用户提供服务。我们在此 https URL 上开源了我们的数据集,并欢迎社区贡献以丰富此类检测数据集。
更多Ai资讯:公主号AiCharm





![Prompt工程师指南[资料整合篇]:Prompt最新前沿论文整理合集、工具和库推荐、数据集整合、推荐阅读内容等,超全面资料](https://img-blog.csdnimg.cn/f4678da78ca54715bcf1cf62e262522e.png#pic_center)