博主之前有涉及过LSTM的文章,见下:
LSTM-理解 Part-1(RNN:循环神经网络)
Python LSTM时序数据的预测(一些数据处理的方法)
机器学习 Pytorch实现案例 LSTM案例(航班人数预测)
环境准备
这里需要准备较多的机器学习的框架,以及一些包。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
from fbprophet import Prophet
from sklearn.metrics import mean_squared_error
from math import sqrt
import datetime
from xgboost import XGBRegressor
from sklearn.metrics import explained_variance_score, mean_absolute_error, \
mean_squared_error, r2_score # 批量导入指标算法
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
安装 TensorFlow
这里涉及到很多机器学习的框架,如Sklearn,TensorFlow等,开始安装TensorFlow可参考下面教程(PASS:较新的博客-20230216写的,Python是3.9的):
anaconda+tensorflow安装完整步骤【亲测可用】
conda create -n TF2 python==3.9
不过安装TensorFlow可以使用这个命令(安装cpu版本的tensorflow),这部分细节可见:
用Anaconda安装TensorFlow(Windows10)
conda install tensorflow
安装完后可以测试:
python
import tensorflow as tf
tf.__version__

也可以测试一个简单的案例:
import tensorflow as tf
tensorflow_version = tf.__version__
gpu_avilable = tf.test.is_gpu_available()
print("tensorflow version: ", tensorflow_version,"\tGPU aviable:", gpu_avilable)
a = tf.constant([1.0,2.0], name = 'a')
b = tf.constant([1.0,2.0], name = 'b')
result = tf.add(a,b,name='add')
print(result)

代码解释:
这段代码利用 TensorFlow 库实现了一个简单的张量(tensor)计算,具体内容如下:
首先,代码中导入 TensorFlow 库,并分别打印 TensorFlow 的版本号和当前计算机是否支持 GPU 加速运算。tf.__version__ 可以获取 TensorFlow 的版本号,而 tf.test.is_gpu_available() 可以判断当前计算机是否支持 GPU。
接下来,代码中定义了两个常量张量 a 和 b,分别初始化为 [1.0, 2.0]。tf.constant() 函数用于创建常量张量,name 参数指定张量的名称。
然后,代码中利用 TensorFlow 的 tf.add() 函数对常量张量 a 和 b 进行加法运算,得到一个新的张量 result。tf.add() 函数用于对两个张量进行加法运算,name 参数指定新张量的名称。
最后,代码中利用 print() 函数打印张量 result 的值,输出结果为 [2. 4.]。这是因为张量 result 是由常量张量 a 和 b 的对应元素相加得到的,即 result = [a[0]+b[0], a[1]+b[1]]。
安装 fbprophet
可借鉴这篇博客:
解决报错“ModuleNotFoundError: No module named ‘fbprophet‘”
依次按照下面的步骤:
conda install pystan==2.19.1.1
conda install fbprophet==0.7.1 -c conda-forge
这后面会报错,正在尝试安装的 “fbprophet” 包的版本 (0.7.1) 不兼容你正在使用的 Python 版本 (Python 3.9)。根据包的规格说明,“fbprophet” 版本 0.7.1 只兼容 Python 版本大于等于 3.6 且小于 3.7,大于等于 3.7 且小于 3.8,或大于等于 3.8 且小于 3.9 的版本。
PASS: 后续还有其他问题(与其他包版本冲突),暂时先不考虑他

安装 seaborn
Seaborn 是一个基于 Python 的数据可视化库,它建立在 Matplotlib 库之上,提供了更高级别的界面和更多样化的图形展示方式,可以用于制作各种类型的统计图表,包括散点图、折线图、直方图、箱线图、热力图等等。Seaborn 的设计初衷是为了帮助用户更快地进行数据探索,特别是对于大型数据集的可视化分析。
conda install seaborn
安装 sklearn
Scikit-learn(也称为sklearn)是一个基于Python的机器学习库,它提供了各种用于分类、回归、聚类和降维等机器学习任务的工具和算法。Scikit-learn建立在NumPy、SciPy和Matplotlib库之上,通过NumPy和SciPy提供的高效数组操作和科学计算功能以及Matplotlib提供的可视化功能,为机器学习任务提供了强大的支持。
Scikit-learn提供了大量的机器学习算法和工具,包括支持向量机、随机森林、K均值聚类、主成分分析等等。这些算法和工具可以帮助用户处理各种类型的数据,包括结构化数据、非结构化数据和图像数据等等。此外,Scikit-learn还提供了许多特征提取、特征选择和数据预处理工具,可以帮助用户更好地准备和清理数据。
Scikit-learn还提供了丰富的模型评估和选择工具,可以帮助用户评估模型的性能和选择最佳的模型。这些工具包括交叉验证、网格搜索、学习曲线等等。Scikit-learn还支持多种模型的集成,例如投票、堆叠和Bagging等等。
sklearn安装:
pip install -U scikit-learn
十分钟上手sklearn:安装,获取数据,数据预处理
sklearn学习:
scikit-learn: Machine Learning in Python
scikit-learn中文社区
安装 XGboost
XGBoost是一个基于树模型的集成学习算法,它是Gradient Boosting算法的一种高效实现。XGBoost的全称是“eXtreme Gradient Boosting”,它在传统的Gradient Boosting框架上提出了一些创新性的改进,如并行处理、缺失值处理、正则化等,从而使得算法更加高效和准确。
XGBoost的主要特点包括:
-
高效性:XGBoost采用了高效的并行处理技术和缓存优化技术,在处理大规模数据时能够更快地训练模型,同时还能够有效地减少内存使用和计算时间。
-
准确性:XGBoost采用了基于树模型的集成学习算法,能够更好地拟合复杂的数据分布和非线性关系,从而提高模型的准确性和稳定性。
-
灵活性:XGBoost提供了灵活的参数设置和正则化方法,可以帮助用户更好地控制模型的复杂度和泛化能力。
-
可解释性:XGBoost能够输出特征的重要性分值,帮助用户理解模型的决策过程和特征的贡献。
XGBoost可以用于分类和回归等多种机器学习任务,特别是在结构化数据和稠密数据的场景下表现优异。它已经成为了机器学习竞赛中的常胜算法,并被广泛应用于金融、电商、广告等领域。
XGBoost的安装也很简单,可以使用pip包管理器直接安装。在Python环境中输入以下命令即可安装:
pip install xgboost
测试其效果:
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
from sklearn.metrics import accuracy_score # 准确率
#定义模型的训练参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.75,
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
#训练的轮数
num_round = 5
model = xgb.train(params, dtrain, num_round)
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))

XGBoost的简单安装及入门使用
实战:实现 LSTM 对销售额的预测
环境配置好后面就是实战了。
数据读取
这里的数据可以私信给作者获取。
# 读取数据
raw_data = pd.read_csv('./data/train.csv')
raw_data.set_index('datetime', inplace=True)
raw_data.head()
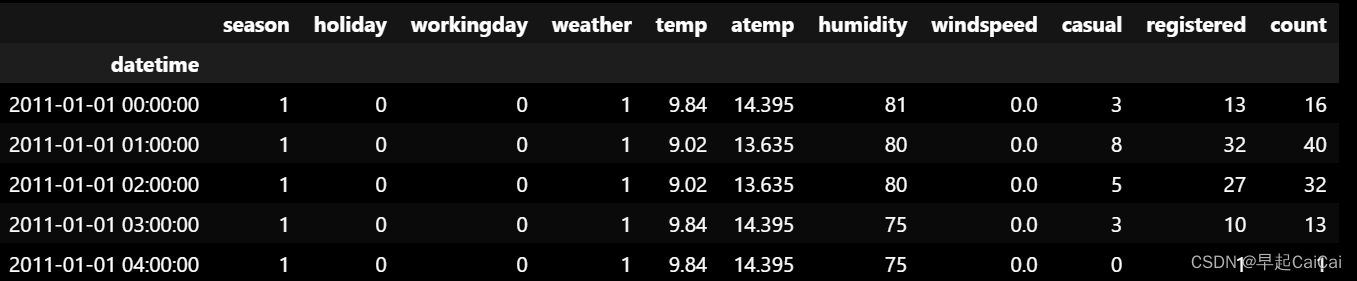
inplace=True表示直接在原数据上进行修改。
特征工程
拆分数据集
train 数据的长度近乎为1年。
num = 24*14 # 将最后2周划分为测试集
train, test = raw_data.iloc[:-num,:], raw_data.iloc[-num:,:]
数据缩放
scaler = MinMaxScaler(feature_range=(0,1))
train_scaled=scaler.fit_transform(train)
test_scaled=scaler.transform(test)
构造XY(样本数+时间步数+特征数)
将数据集构造成LSTM需要的格式
def createXY(dataset, n_past, target_p=-1):
'''
将数据集构造成LSTM需要的格式
dataset:数据集
n_past:时间步数,利用过去n的时间作为特征,以下一个时间的目标值作为当前的y
target_p:目标值在数据集的位置,默认为-1
'''
dataX = []
dataY = []
for i in range(n_past, len(dataset)):
dataX.append(dataset[i - n_past:i, 0:dataset.shape[1]])
dataY.append(dataset[i,target_p])
return np.array(dataX),np.array(dataY)
X_train, Y_train=createXY(train_scaled,30)
X_test, Y_test=createXY(test_scaled,30)
X_train.shape
输出结果:
(10520, 30, 11)
这段代码定义了一个函数 createXY,用于将原始的时间序列数据转化为 LSTM 模型所需要的格式,即将过去
n
n
n 个时间步的数据作为特征,以下一个时间步的目标值作为当前的
y
y
y 值。
具体来说,该函数的参数包括:
dataset:原始时间序列数据集;n_past:时间步数,即过去 n n n 个时间步的数据作为特征;target_p:目标值在数据集的位置,默认为 -1,即最后一列。
函数的实现过程如下:
首先,创建两个空列表 dataX 和 dataY,用于存储转化后的数据。然后,从第
n
_
p
a
s
t
n\_past
n_past 个时间步开始遍历数据集,每次取出过去
n
n
n 个时间步的数据(包括所有特征列),构成一个
n
×
m
n \times m
n×m 的矩阵,其中
m
m
m 是特征的数量。然后,将该矩阵添加到 dataX 列表中。同时,从原始数据集中取出下一个时间步的目标值,将其添加到 dataY 列表中。最后,将 dataX 和 dataY 转化为 Numpy 数组并返回。
接下来,使用该函数将训练集和测试集转化为 LSTM 模型所需的格式。具体来说,对训练集 train_scaled 和测试集 test_scaled 分别调用 createXY 函数,将时间步数 n_past 设置为 30,生成训练集的特征矩阵 X_train 和目标值向量 Y_train,以及测试集的特征矩阵 X_test 和目标值向量 Y_test。
最后,代码使用 X_train.shape 打印出训练集的特征矩阵 X_train 的形状,以便检查转化结果是否正确。
X_train 中可以看到有10520个训练样本,每个样本的形状为30*11,即过去30天的数据集合(30个样本,11个特征)。
Y_train 的 shape 为(10520,)
模型训练
定义LSTM
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(4, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
grid_model.add(LSTM(4)) # 防止预测值为三维
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model=KerasRegressor(build_fn=build_model,verbose=1,validation_data=(X_test,Y_test))
parameters = {'batch_size' : [16,20],
'epochs' : [8,10],
'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)
这段代码定义了一个函数 build_model 用于创建一个 LSTM 模型,并将其封装在 KerasRegressor 中以便进行超参数搜索。接着,使用 GridSearchCV 对该模型进行网格搜索,寻找最佳的超参数组合。
具体来说,函数 build_model(optimizer) 的参数是优化器 optimizer,用于编译模型时指定优化算法。函数首先创建一个 Sequential 对象 grid_model,用于存储 LSTM 模型的各个层。然后,向该模型中添加两个 LSTM 层,分别包含 4 个 LSTM 单元。第一个 LSTM 层设置 return_sequences=True,表示返回完整的输出序列,而不仅仅是最后的输出。第二个 LSTM 层没有设置 return_sequences,因此只返回最后的输出。紧接着,向模型中添加一个 Dropout 层,用于随机丢弃一部分神经元,以避免过拟合。最后,添加一个全连接层 Dense(1),用于输出预测值。模型的损失函数设置为均方误差,优化算法由参数 optimizer 指定。
接下来,使用 KerasRegressor 将模型封装成一个可用于 GridSearchCV 的评估器 grid_model。其中,verbose=1 表示输出训练过程中的日志信息,validation_data=(X_test,Y_test) 表示在训练过程中使用测试集进行验证。
然后,定义一个字典 parameters,包含三个超参数:批次大小 batch_size、迭代轮数 epochs 和优化算法 optimizer。其中,batch_size 和 epochs 的值分别取 [16, 20] 和 [8, 10],optimizer 的值取 ['adam', 'Adadelta']。
最后,使用 GridSearchCV 对 grid_model 进行网格搜索,寻找最佳的超参数组合。其中,estimator 参数指定要搜索的模型,param_grid 参数指定超参数的取值范围,cv 参数指定交叉验证的折数。
grid_search = grid_search.fit(X_train,Y_train)
grid_search.best_params_
模型拟合及输出最佳参数。
# 输出最优模型参数
print(grid_search.best_params_)
# 获取最优模型
model_lstm=grid_search.best_estimator_.model
# 预测值
pre_y=model_lstm.predict(X_test)
模型结果评估
逆缩放
# 构造同等宽度的pre_y,即生成与缩放同等列数
pre_y_repeat = np.repeat(pre_y, X_train.shape[2], axis=-1)
# 逆缩放并获取预测值
pred=scaler.inverse_transform(np.reshape(pre_y_repeat,(len(pre_y), X_train.shape[2])))[:,-1] # 选取目标列所在位置
# 对Y_test进行逆缩放
Y_test_repeat = np.repeat(Y_test, X_train.shape[2], axis=-1)
Y_test_original=scaler.inverse_transform(np.reshape(Y_test_repeat,(len(Y_test),X_train.shape[2])))[:,-1] # 选取目标列所在位置
模型评估
# 评估指标
model_metrics_functions = [explained_variance_score, mean_absolute_error, mean_squared_error,r2_score] # 回归评估指标对象集
model_metrics_list = [[m(Y_test_original, pred) for m in model_metrics_functions]] # 回归评估指标列表
regresstion_score = pd.DataFrame(model_metrics_list, index=['model_xgbr'],
columns=['explained_variance', 'mae', 'mse', 'r2']) # 建立回归指标的数据框
regresstion_score # 模型回归指标

模型预测结果展示
fig = plt.figure(figsize=(16,6))
plt.title('True and LSTM result comparison', fontsize=20)
# 时间索引
ds_index = [datetime.datetime.strptime(x, "%Y-%m-%d %H:%M:%S") for x in test.index[30:]]
# 真实序列
true_s=pd.Series(Y_test_original, index=ds_index)
plt.plot(true_s, color='red')
# 预测序列
pre_s=pd.Series(pred, index=ds_index)
plt.plot(pre_s, color='green')
plt.xlabel('Hour', fontsize=16)
plt.ylabel('Number of Shared Bikes', fontsize=16)
plt.legend(labels=['True', 'Pre_y'], fontsize=16)
plt.grid()
plt.show()
需要注意的是,代码中的 test.index[30:] 表示从测试集的第 30 个时间步开始绘制,是因为在将数据集转化为 LSTM 所需格式时,我们将时间步数设置为 30。因此,前 30 个时间步的数据是无法用于预测的,需要从第 30 个时间步开始绘制。

Test
测试集中 casual 和 registered数据缺失
暂时不过多关注。
**优化:**可以 train 数据集中不使用 casual 和 registered数据
Reference
时间序列预测(二)基于LSTM的销售额预测
使用 LSTM 对销售额预测(Python代码)