国内头部以自动驾驶全站技术为主线的交流学习社区(感知、归控等),包含大量前沿论文解读、工程实践(源代码)、视频课程,热招岗位。欢迎加入!
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
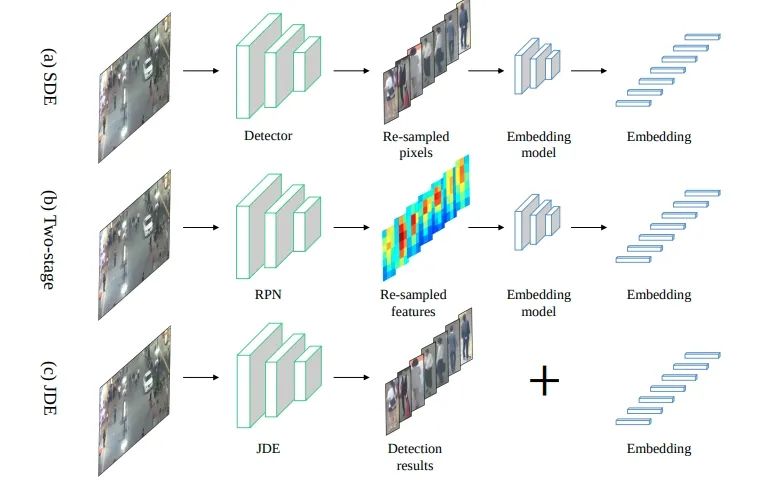
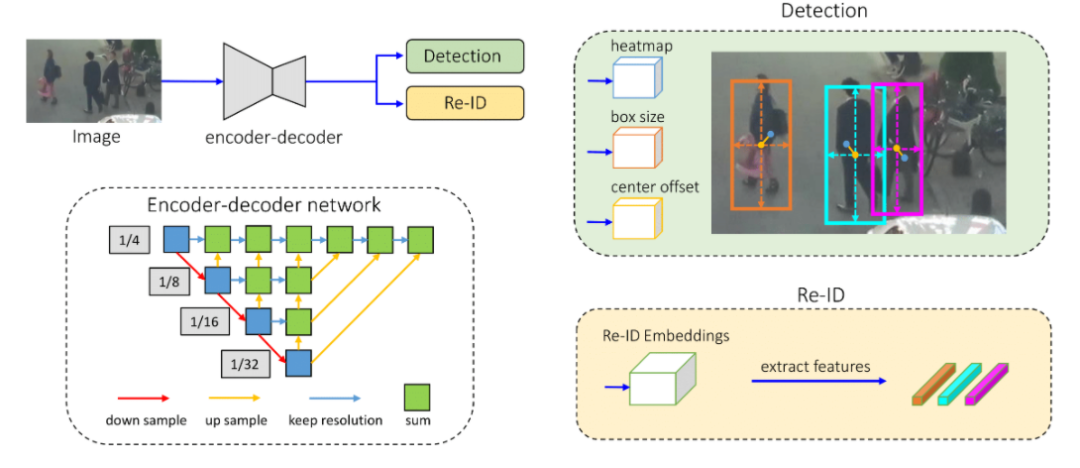
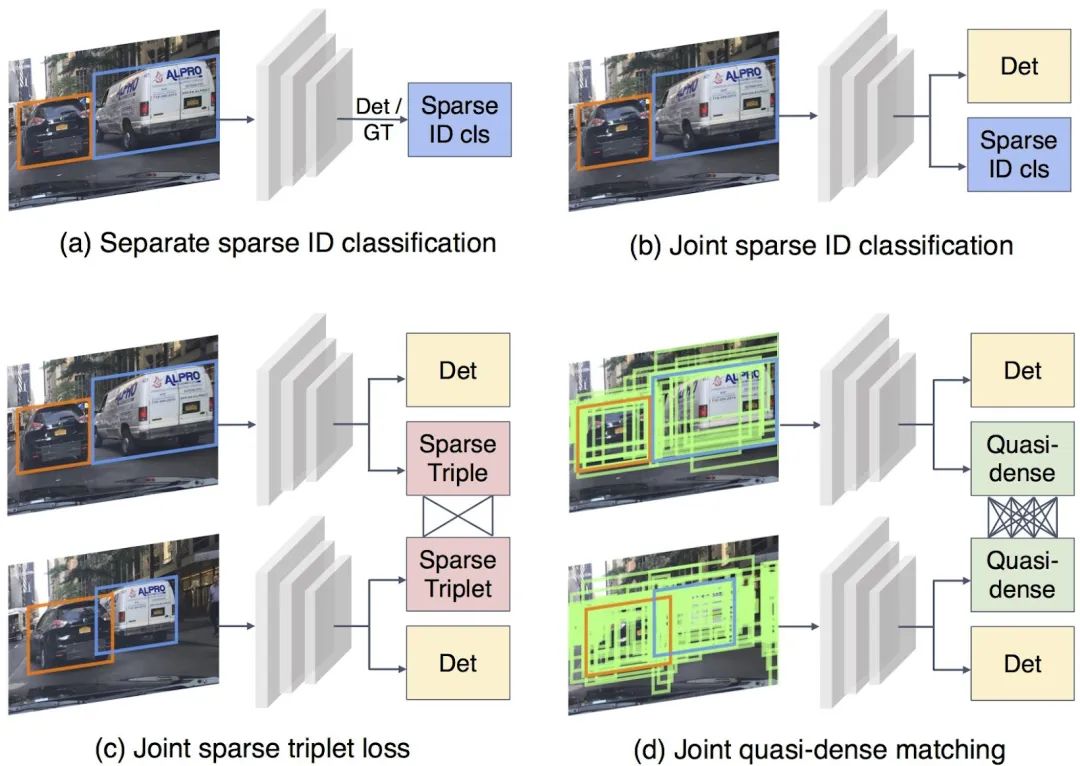
Joint detection and tracking (同时实现检测和跟踪)是Multiple Object Tracking(MOT)的一个重要研究方向。Multiple Object Tracking,多目标跟踪, 主要包括两个过程(Detection + ReID,Detection 是检测出图像或者点云中的目标框从而获取目标的位置,而ReID是将序列中同一个目标关联起来) ,因此一方面这涉及到时间和空间的特征学习和交互,另一方面也涉及到检测和重识别(特征的embedding)的多任务学习,导致MOT任务。目前MOT可以分成三大类(如图一所示):
SDE(Separate Detection and Embedding), 或者称为Tracking-by-detection, 该类的想法也非常直接,将多目标跟踪这个任务进行拆分,先进行单帧的目标检测得到每帧的目标框,然后再根据帧间同一目标的共性进行关联(association),帧间的关联的重要线索包括appearance, motion, location等,典型的代表算法包括SORT和Deep SORT。这类算法的优点是简单,将Detection和ReID解耦分开解决。例如上述的SORT和Deep SORT的检测器可以不受到限制,使用SOTA的检测方法,在目标关联上使用卡尔曼滤波+匈牙利匹配等传统方法。但是缺点也很明显,就是解耦开无法促进多任务学习,特别受限目标关联阶段的方法而且依赖目标检测算法,也只能处理比较简单的场景。
Two-Stage方法也可称之为Tracking-by-detection,只不过其中的ReID变成第一阶段网络学习得到的ROI特征然后在第二阶段进行embedding特征的学习,相对于第一类进步点在于 appearance特征 可由第一阶段获得,但是两阶段方法的诟病是inference比较慢,而且我觉得detection特征和embedding特征还是没有构成多任务学习的状态。
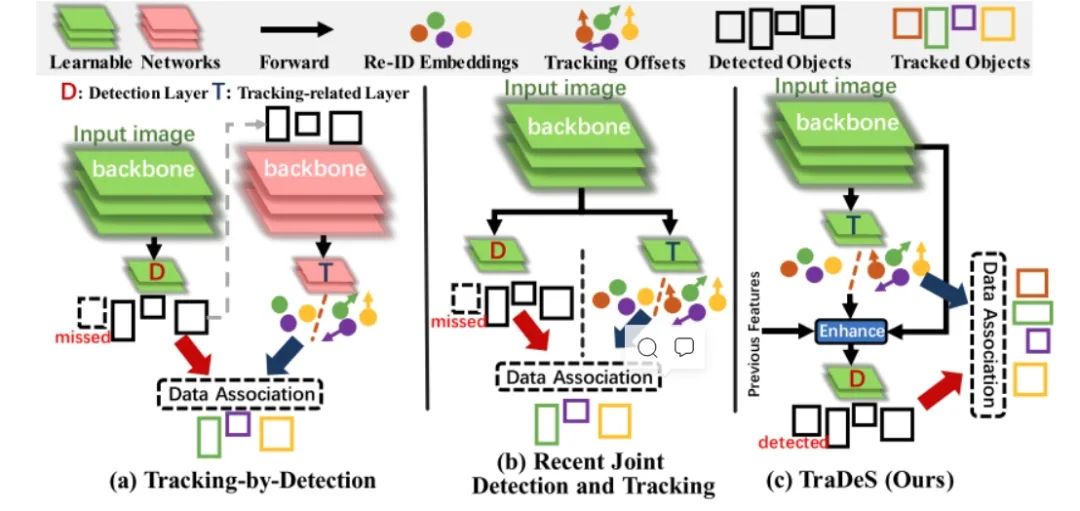
JDE(Joint Detection and Embedding)或者是Joint detection and tracking 这类算法是在一个共享神经网络中同时学习Detection和Embedding,使用一个多任务学习的思路共享特征学习网络参数并设置损失函数,从而可以实现Detection和ReID的交互和促进,然后由于属于一阶段模型,因此在速度上是可以达到实时,所以是可以保证应用的。因此是Joint detection and tracking 这类算法我们关注的重点。
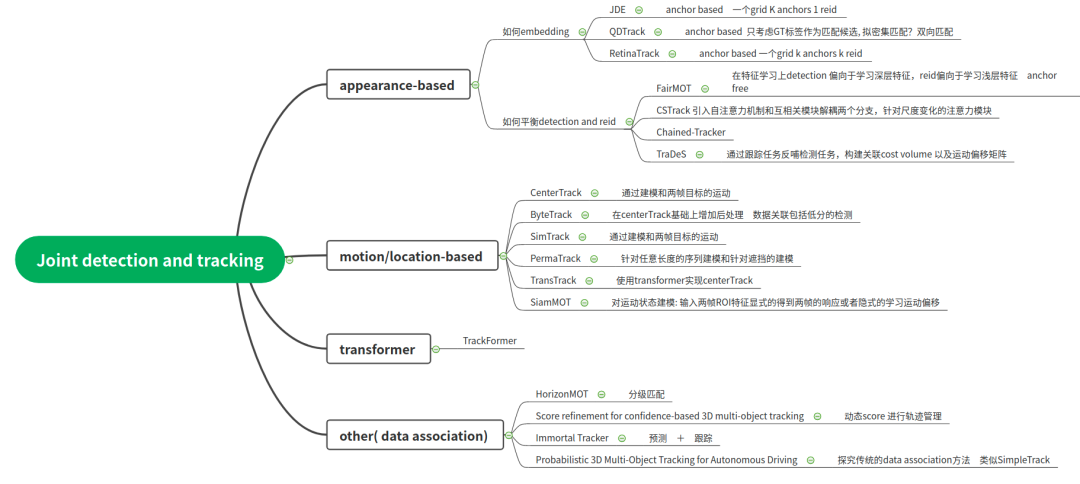
同时为了实现Joint detection and tracking,需要解决如下几个问题(也包括一些思路):
多任务学习中如何同时输出检测和帧间的数据关联, 特别是数据关联如何实现?损失函数如何设计?
目前看到的方案中主要分成两大类,一种是通过motion based 例如一个head实现输出目标的速度或者是目标的偏移,然后通过位置关联实现(CenterTrack系列)。另外一种是appearance based 在新增加的heading中通过对比学习得到各目标在特征上的差异, 但是匹配还是通过计算相似度并且二分匹配,也不是真正意义上的Joint detection and tracking。
网络设计上如何实现detection和embedding的联合训练?
Detection和ReID模型的学习是存在不公平的过度竞争的,这种竞争制约了两个任务(检测任务和 ReID 任务 )的表示学习,导致了学习的混淆。具体而言,检测任务需要的是同类的不同目标拥有相似的语义信息(类间距离最大),而ReID要求的是同类目标有不同的语义信息(类内距离最大)。
需要将对embedding分支和现detection分支分开,以及可以在embedding内部进行注意力机制的建模。(CSTrack里面引入自相关注意力机制和互相关权重图)
浅层特征对于ReID任务更有帮助,深层特征对于Detection任务更有帮助。(FairMOT)
Detection和Tracking模型的相互促进,如何做到Detection帮助Tracking, Tracking反哺Detection(TraDeS构建CVA和MFW分别进行匹配和特征搬移,该部分和多帧的特征学习相似,利用学习到的运动信息搬移历史特征到当前帧,辅助当前帧的目标检测)
在图像里目标较大的尺度变化也对embedding的学习有很大的影响,之前embedding的学习是固定大小的proposal区域。(CSTrack里引入尺度感知注意力网络)
如何进行多帧的学习,时间和空间的交互?
目前大部分的网络输入的一帧或者两帧,学习到的数据关联都是短时的,如何拓展到任意多帧,例如使用convGRU的方法等(可以参见Perma Track)。
如何处理遮挡?遮挡包括局部遮挡以及全部遮挡,尤其是全部遮挡,一方面需要根据多帧来将历史的状态进行推移,另一方面也需要处理appearance特征和motion特征的关系,并且在损失函数设计上如何处理Detection和ReID不一致的地方。
需要同时cover 住short-range matching和long-range matching, 也就是分成正常情况下的matching, 短时间的遮挡和长时间的遮挡如何对特征的利用。
对运动信息的显示建模,例如学习特征图的运动信息(或者场景流之类的)也是多帧融合的一种方案,同时该运动信息也是帧间目标关联的依据。
appearance, motion, location特征如何学习和使用?
appearance特征对于long-range matching比较有用,但是没法处理遮挡,可能会带来干扰。
motion和location特征没有那么准确,特别进行long-range matching, 但是在short-range matching可以发挥作用,而且在被全部遮挡的情况下可以发挥作用。
anchor-based vs anchor-free
此部分其实也是属于网络设计的一部分,目前的Joint detection and tracking都是基于detection的框架,而detection分成anchor-based与anchor-free两部分,目前而言,使用anchor-based的方法进行建模的包括JDE以及RetinaTrack,例如JDE进行训练的时候一个grid分成很多个anchor, 但是分成1个track id, 这个造成遮挡的id匹配的模棱两可,RetinaTrack是每一个anchor分配一个track id
anchor free使用点携带所有特征进行分类或者位置回归,如果需要学习embedding只是加上一个分支,模棱两可更小一点,所以建议使用anchor-free方法。
通过历史heatmap和当前heatmap构成存在置信度(SimTrack)
通过双向匹配(QDTrack)
依照传统的方法(CenterTrack系列)
分类(部分方法)
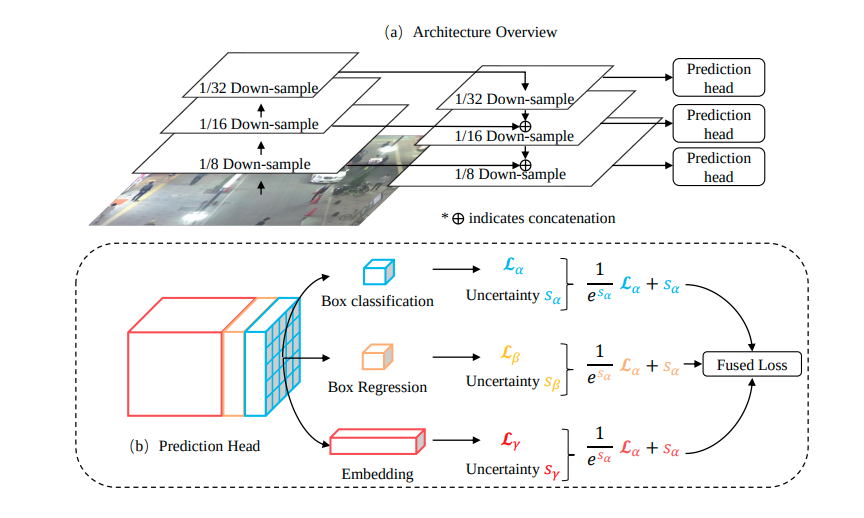
JDE: Towards Real-Time Multi-Object Tracking
paper: https://arxiv.org/abs/1909.12605v1
code: https://github.com/Zhongdao/Towards-Realtime-MOT
JDE同时输出了检测框和embedding信息。后面通过卡尔曼滤波和匈牙利算法进行目标的匹配。总的来说,还是分为检测和匹配双阶段。
另外属于anchor based,而且一个grid K anchors 1 reid,这是很大的缺点。
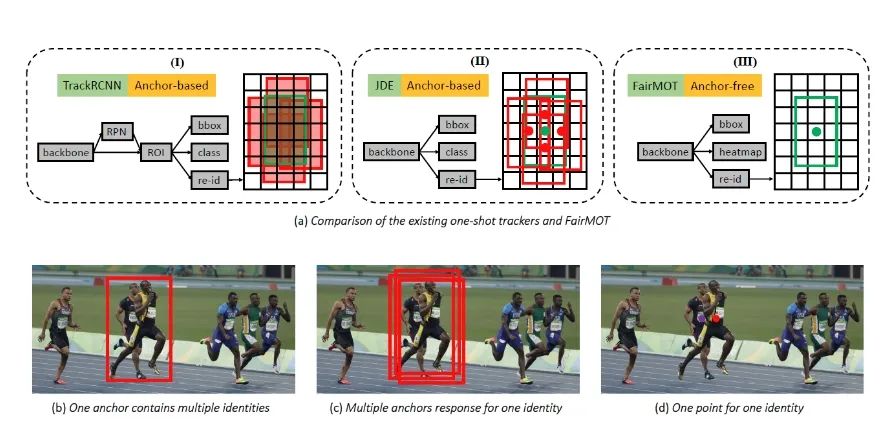
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
paper: https://arxiv.org/abs/2004.01888
code: https://github.com/ifzhang/FairMOT
A simple baseline for one-shot multi-object tracking
行人性能比较好 tracking = detection + re-id 单类别?
在方法上基于anchor的方法会使ReID的方法带来坏处 ,涉及到遮挡目标id分配问题
浅层特征对于使ReID会有益处,而且需要将detection和re-id分支分开
特别说明的是针对3d目前主要是motion/location-based 方法,这些对于3d joint detection and tracking首先采用anchor-free框架容易嵌套到我们的框架里,另外简单高效。特别是CenterTrack/SimTrack系列(包括CenterTrack, ByteTrack, SimTrack以及PermaTrack)。其中CenterTrack在原有anchor-free detection方法基础上增加一个位置偏移分支用于匹配,ByteTrack在此基础上为了增加匹配的成功率,进行级联匹配方式,PermaTrack对遮挡问题进行建模以提高long-range tracking能力(包括输入任意长度的帧)。从上述可以看到该框架仍然有一些改进点:1.对motion/location特征用的比较多,对于appearance特征发挥的作用灭有那么大。2.从实验也可以看到tracker management做的不是特别好, tracker id 容易切换,应该也是因为匹配的时候多用于motion/location特征的原因,有可能是对多帧建模较弱的原因(CenterTrack输入只有两帧,而且inference用的历史信息不足造成的,而且training和inference如何做到统一) 3. 遮挡情况下如何可以处理的更好,特征利用上一方面需要将历史特征搬到当前帧(如何搬,显式预测速度还是ConvGRU隐式的方式),损失函数如何设计,毕竟detection看不到reid需要。
下文对一些方法进行简单/详细的说明(详细说CenterTrack系列方法)。其中SimTrack可参见
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving论文阅读
CenterTrack: Tracking Objects as Points
paper: https://arxiv.org/abs/2004.01177
code: https://github.com/xingyizhou/CenterTrack
输入是当前帧图片和前一帧图片以及前一帧的heatmap(在训练的时候是由真值产生, 当然为了模拟测试的情况也加入一些噪声, 在测试的时候由检测框渲染生成)。预测当前帧的检测结果,然后使用当前帧的检测结果以及当前帧到上一帧的偏移。在预测的时候通过该偏移将目标中心点引入到上一帧和上一帧进行关联(使用贪婪匹配算法)

跟踪条件检测(Tracking-conditioned detection)利用多输入上一帧以及输入上一帧渲染出的heatmap来作为历史信息的输入
时间关联( Association through offsets)通过多输出偏移来进行目标ID的匹配
数据增强方法:真值生成heatmap增加噪声(数量不定的missing tracklets、错误定位的目标以及还可能有误检的目标存在),在输入的两帧上时间间隔不一定是连续的,从而规避掉模型对视频帧率的敏感性。(比较重要)
缺点:都是两帧的匹配,如果出现遮挡或者离开检测区域则可能会引起ID的切换和跳变,没有考虑如何在时间上有较大间隔的对象重新建立联系。此问题也是需要面对的问题。
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
paper: https://arxiv.org/abs/2110.06864
code: https://github.com/ifzhang/ByteTrack
从检测任务对接到跟踪任务时, 采用阈值过滤掉检测网络输出的边界框, 使得检测信息出现丢失,造成跟踪过程出现中断的情况,使得跟踪任务对检测任务的要求过高。对于出现的漏检以及轨迹中断的情况,作者分析原因为在将检测的目标框进行数据关联时设置了较高的阈值,导致一些低置信度的目标信息出现不可逆的丢失。为了避免低置信度边界框信息的丢失, 需要额外地解决低置信度带来的误检问题,通过引入二次关联 ,将能够同tracklets匹配上的low confidence boxes加入到tracklets中,无法匹配的boxes看成是背景,也就是误检。
传统的long-range association是将丢失的轨迹维持一段时间(30次),如果一直没被匹配则认为是确实丢失了。新出现的目标是连续两帧都同时出现才认为是都出现了。
第一次关联时可以使用位置信息和appearance信息,第二次关联时只使用位置信息,因为目标可能被遮挡等造成appearance信息不准确。
location,motion以及appearance是association的有用线索,SORT中使用location和motion来进行关联,相似性的计算主要是考虑到bounding boxes检测框和tracklets预测框之间的IoU。现在的一些做法是通过网络来学习object motions。在short-range matching中location和motion是比较准确的 。而appearance在long-range matching中则比较有帮助 ,长时间遮挡时依旧能够通过appearance来对对象进行Re-ID。
缺点是如果长时间没有出现也会出现跟踪目标切换ID的情况

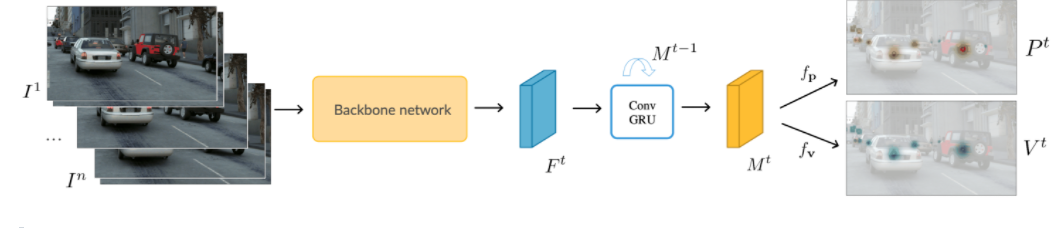
Perma Track: Learning to Track with Object Permanence
paper: https://arxiv.org/abs/2103.14258
code: https://github.com/TRI-ML/permatrack
在CenterTrack框架上,输入pairs of frame,同时扩展到任意长度的视频中从而可以利用历史的信息。此外增加了一个 spatio-temporal recurrent memory module 来对 完全遮挡的目标进行预测(完全遮挡的目标如何监督是本文需要考虑的另外一个点),保持trajectory的连贯性 ,从而提升模型的检测性能能够利用之前历史推理当前帧目标的位置以及identity。对于如何训练这个模型,首先构建了一个大规模的合成数据集( 为不可见目标提供了标注 ),并提出了在遮挡情况下监督tracking的几种方式。最后在合成和真实数据上联合训练。
基于object permanence的假设,目标一旦被发现说明是物理存在的
创新点在于
端到端和joint object detection and tracking that operates on videos of arbitrary length。
○ 使用spatio-temporal recurrent memory module convGRU
怎么对不可见的目标的轨迹通过在线的方式进行学习。
○ 学习一个heatmap表示这个目标是不是可见或者是被遮挡的, 对遮挡情况进行可视化等级划分
怎么弥补合成数据和真实数据之间的gap
合成数据与真实数据的差异性?
通过同时训练合成数据(Parallel Domain(PD) simulation platform产生)和真实数据,然后将不可见数据只在合成数据上训练发现可以提高模型的性能。
其他一些经典的Track方法
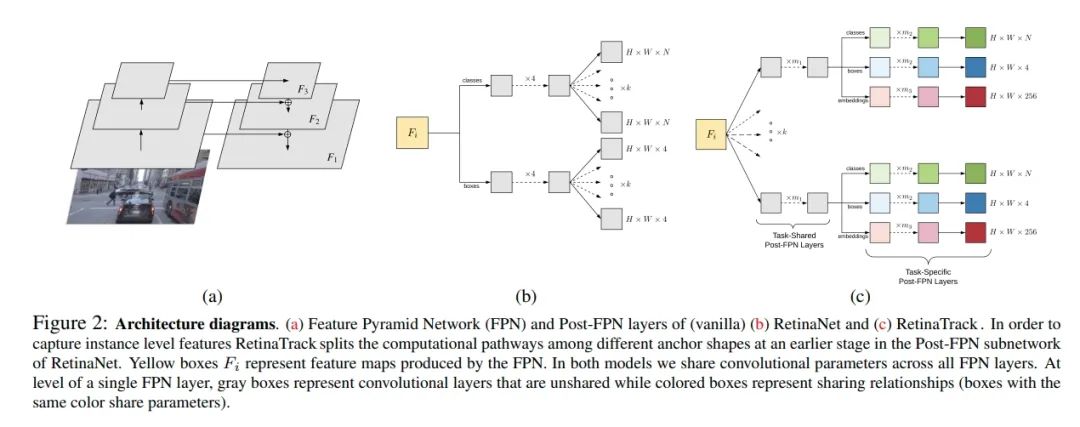
RetinaTrack: Online Single Stage Joint Detection and Tracking
paper: https://arxiv.org/abs/2003.13870
code:
和上述方式, 在RetinaTrack的基础上,将embedding分支和detection分支分开并且采用anchor-based的方式,每一个anchor都有对应的embedding特征(方便处理遮挡)。
embedding使用采样三组对比样本的批处理策略的三元组损失, 只监督和gt匹配的上的?
QDTrack:Quasi-Dense Similarity Learning for Multiple Object Tracking
paper: https://arxiv.org/abs/2006.06664
code: https://github.com/SysCV/qdtrack
现有的多目标跟踪方法仅将稀疏地面真值匹配作为训练目标, 而忽略了图像上的大部分信息区域 。在本文中提出了准稠密相似性学习,它对一对图像上的数百个区域建议进行稠密采样以进行对比学习。作者提出的QDTrack密集匹配一对图片上的上百个感兴趣区域,通过对比损失进行学习参数,密集采样会覆盖图片上大多数的信息区域。通过对比学习,一个样本会被训练同时区分所有的Proposal,相较于只使用真值标签来训练监督,更加的强大且增强了实例的相似度学习。对于消失轨迹的处理,会将背景作为一类,从而进行双向softmax增强一致性。
当前帧和上一帧的双向匹配可以实现轨迹的管理。
拟密集匹配其他算法不是这样做的?
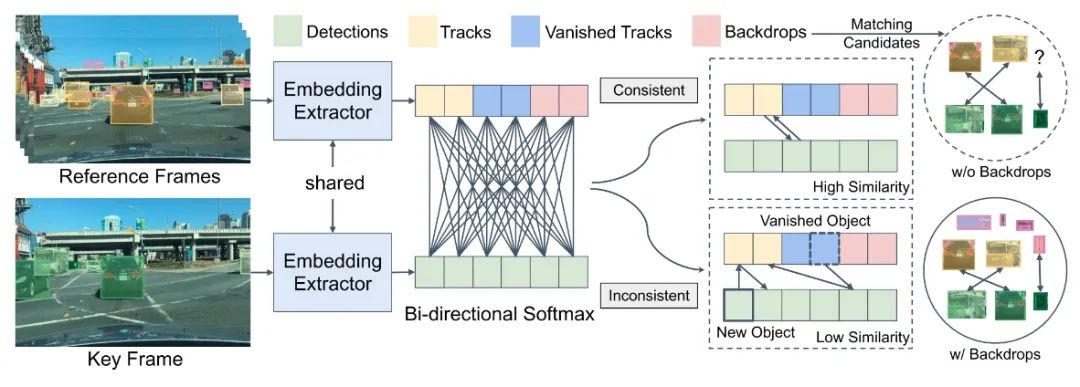

其中保留低置信度的目标?
TraDeS:Track to Detect and Segment: An Online Multi-Object Tracker
paper: https://arxiv.org/abs/2103.08808
code: https://github.com/JialianW/TraDeS
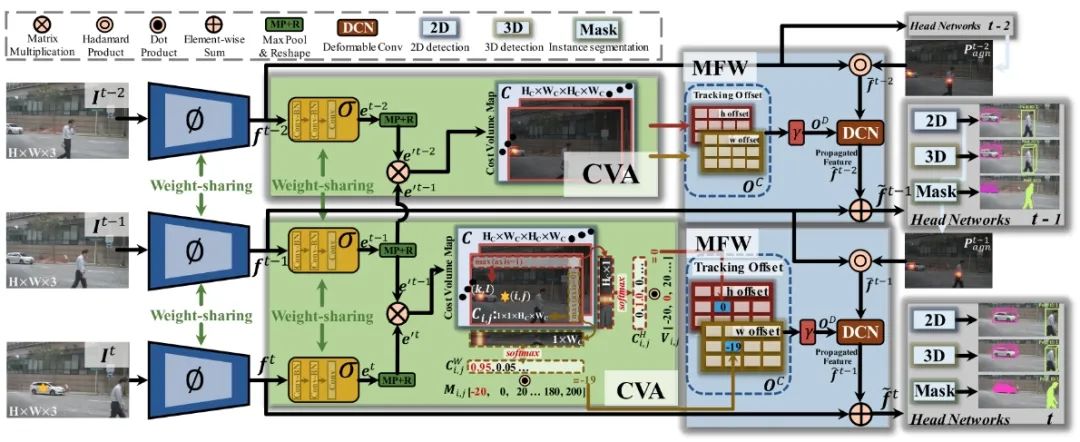
TraDeS通过cost volume来推断目标跟踪偏移量,该cost volume用于传播前帧的目标特征,以改善当前目标的检测和分割,其实可以理解为一个关联代价矩阵,主要由关联模块(CVA)和一个运动指导的特征变换模块(MFW)构成。CVA模块通过backbone提取逐点的ReID embedding特征来构建一个cost volume,这个cost volume存储两帧之间的embedding对之间的匹配相似度。继而,模型可以根据cost volume推断跟踪偏移(tracking offset),即所有点的时空位移,也就得到了两帧间潜在的目标中心。跟踪偏移和embedding一起被用来构建一个简单的两轮长程数据关联。之后,MFW模块以跟踪偏移作为运动线索来将目标的特征从前帧传到当前帧。最后,对前帧传来的特征和当前帧的特征进行聚合进行当前帧的检测和分割任务。
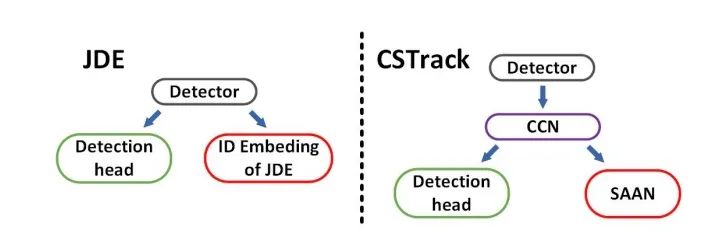
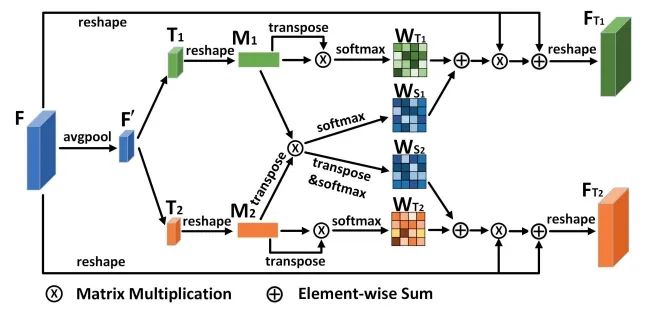
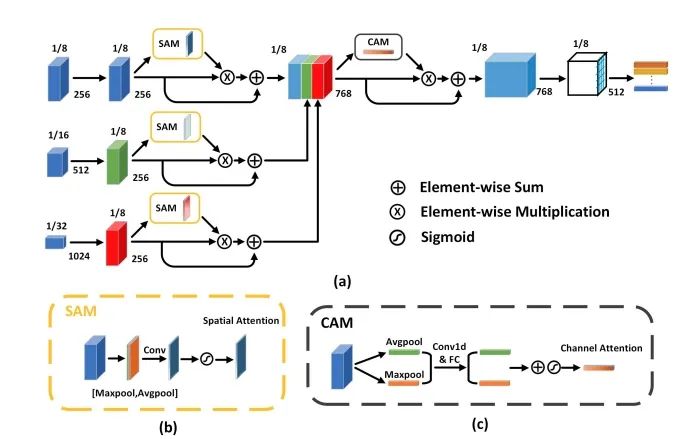
CSTrack:Rethinking the competition between detection and ReID in Multi-Object Tracking
paper: https://arxiv.org/abs/2010.12138
code: https://github.com/JudasDie/SOTS
论文提出了一种新的互相关网络(CCN)来改进单阶段跟踪框架下 detection 和 ReID 任务之间的协作学习。作者首先将 detection 和 ReID 解耦为两个分支,分别学习。然后两个任务的特征通过自注意力方式获得自注意力权重图和互相关性权重图。自注意力图是促进各自任务的学习,互相关图是为了提高两个任务的协同学习。而且,为了解决上述的尺度问题,设计了尺度感知注意力网络(SAAN)用于 ReID 特征的进一步优化,SAAN 使用了空间和通道注意力,该网络能够获得目标 不同尺度的外观信息,最后 不同尺度外观特征融合输出即可。
Immortal Tracker
paper: https://arxiv.org/abs/2111.13672
code: https://github.com/ImmortalTracker/ImmortalTracker
目前过早的轨迹终止是目标ID切换的主要原因,因此本方法使用简单的轨迹预测希望保留长时间的轨迹,轨迹预测方法就是简单的卡尔曼滤波 实现predict-to-track范式, 在匹配(3D IOU or 3D GIOU)的时候如果当前检测结果和预测可以匹配的上则更新轨迹,如果没有匹配的上则更新预测值。
思考:正常的跟踪不都是这个流程吗?

HorizonMOT:1st Place Solutions for Waymo Open Dataset Challenges -- 2D and 3D Tracking
paper: https://arxiv.org/abs/2006.15506
运动模型
借鉴了DeepSort算法,使用了Kalman Filter算法,在3D跟踪中设定的状态变量为3D坐标、长宽高和位置的速度变化量。
表观模型
表观模型的引入主要是 为了防止拥挤和轨迹暂时丢失 的问题,行人输入为128x64,车辆输入为128x128,经过11个3x3卷积和3个1x1卷积以及一些pooling层得到512维向量。
数据关联(级联匹配)
数据关联的基础算法是匈牙利算法,这里作者将 关联过程分成了三个阶段 ,与此同时将检测结果按照置信度分成了两份,一份置信度大于t(s),一份介于t(s)/2和t(s)之间。
第一阶段的数据关联跟DeepSort一样,采用级联匹配的方式,对跟踪框和第一份检测结果进行匹配,也就是先匹配持续跟踪的目标,对于暂时丢失的目标降低优先级;
第二阶段的数据关联会对第一阶段中尚未匹配的跟踪轨迹(丢失时间小于3)和剩余的第一份检测结果进行匹配,当然也会降低一些匹配阈值
第三阶段的数据关联会对第二阶段尚未匹配的跟踪轨迹和第二份检测结果进行匹配,同样降低阈值标准。
Probabilistic 3D Multi-Object Tracking for Autonomous Driving
paper: https://arxiv.org/abs/2012.13755
code: https://github.com/eddyhkchiu/mahalanobis_3d_multi_object_tracking
使用马氏距离而不是3D IOU可以防止小目标(行人等)无法匹配
卡尔曼滤波参数使用训练集的统计值
使用贪心算法进行匹配而不是匈牙利算法
Score refinement for confidence-based 3D multi-object tracking
paper: https://arxiv.org/abs/2107.04327
code: https://github.com/cogsys-tuebingen/CBMOT
处理轨迹得分更新的问题,如果轨迹和当前检测结果匹配上了则该轨迹认为是比之前的轨迹得分和检测结果得分都大,如果没有匹配上则认为轨迹得分需要处于衰减状态。然后基于此设计一系列的函数来更新轨迹得分,创新点比较一般。但是在很多榜单上排名很高,是个有用的trick。
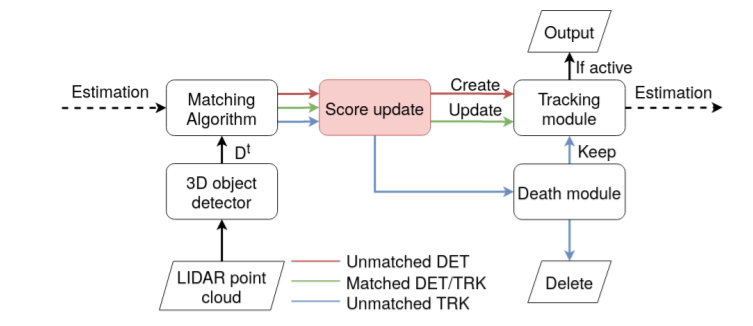
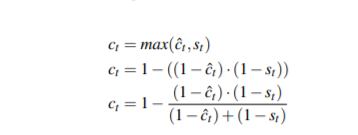
SiamMOT:Siamese Multi-Object Tracking
paper: https://arxiv.org/abs/2105.11595
code: https://github.com/amazon-research/siam-mot
孪生跟踪器根据其在一个局部窗口范围内搜索对应的实例, 然后获得当前帧和历史帧的特征
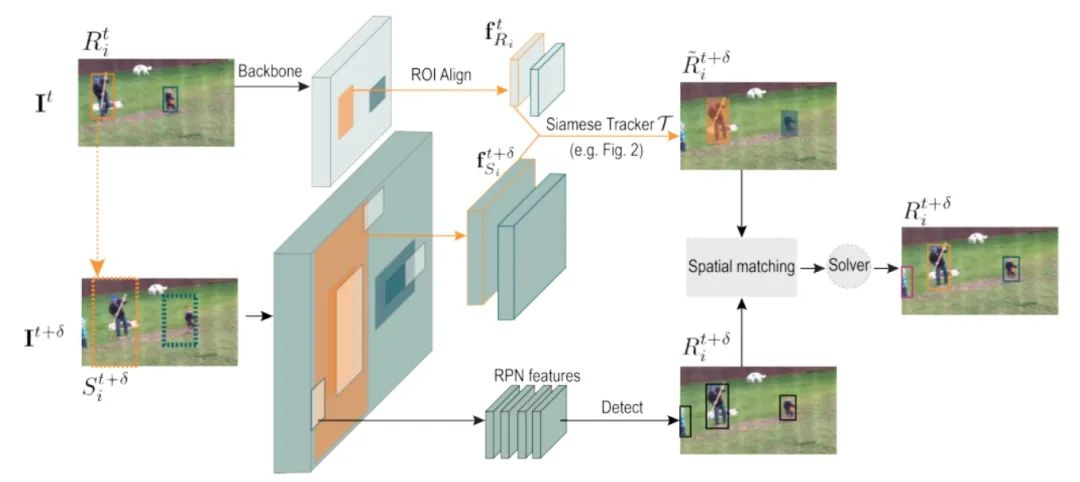
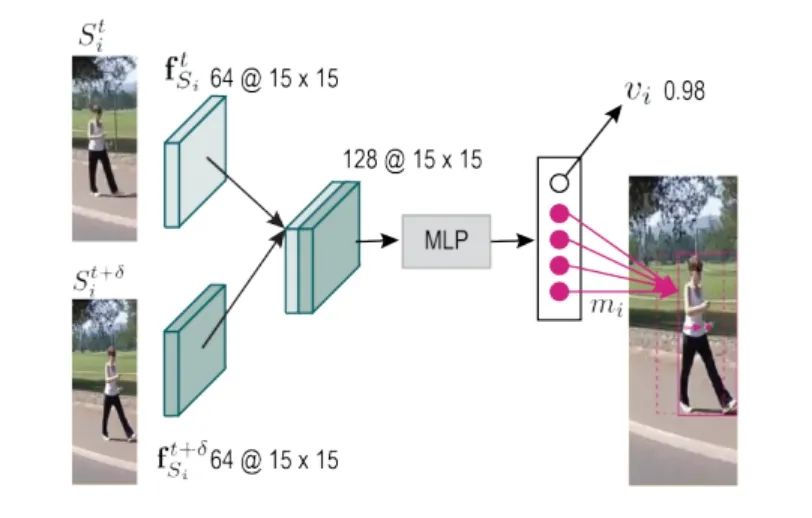
包括两种运动建模方式:1.将特征按通道连接在一起然后送入MLP中预测可见置信度和相对位置和尺度偏移;2.显式运动模型通过逐通道的互相关操作来生成像素级别的响应图
该方法是在Faster RCNN上进行改进的,而且是anchor-based, 参考意义有限,但是对于运动的建模以及根据特征判断遮挡与上述 Perma Track x想法相似,可以参考。
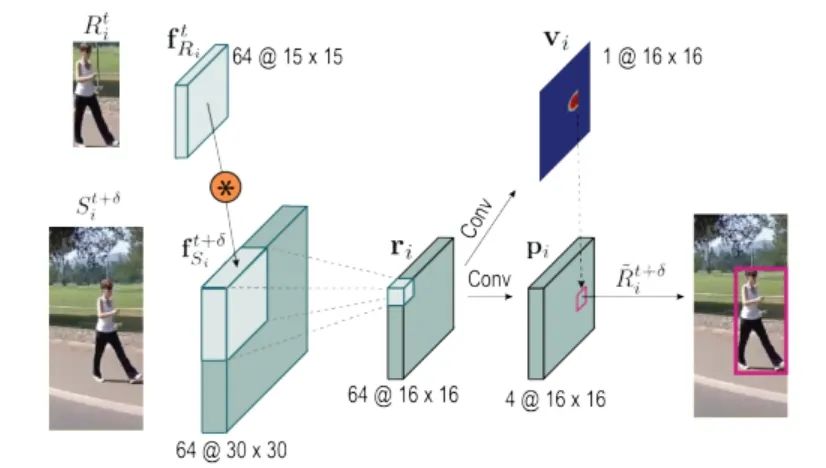
TransTrack: Multiple Object Tracking with Transformer
paper: https://arxiv.org/abs/2003.13870
code: https://github.com/PeizeSun/TransTrack
利用transfomer实现跟踪,类似于centerTrack,利用两个key-query学习检测和到上一帧的偏移

Reference:
https://github.com/luanshiyinyang/awesome-multiple-object-tracking
https://github.com/JudasDie/SOTS
CenterTrack https://github.com/xingyizhou/CenterTrack
ByteTrack https://github.com/ifzhang/ByteTrack
Perma Track https://github.com/TRI-ML/permatrack
https://github.com/DanceTrack/DanceTrack 提出一个数据集
https://github.com/ImmortalTracker/ImmortalTracker 用处不是特别大 感觉有点水
https://github.com/eddyhkchiu/mahalanobis_3d_multi_object_tracking
https://github.com/TuSimple/SimpleTrack 信息量不大
Score refinement for confidence-based 3D multi-object tracking https://github.com/cogsys-tuebingen/CBMOT
CenterTrack3D: Improved CenterTrack More Suitable for Three-Dimensional Objects
FairMOT https://github.com/ifzhang/FairMOT
HorizonMOT 地平线参加比赛的方案 https://arxiv.org/abs/2006.15506
PTTR: Relational 3D Point Cloud Object Tracking with Transformer https://github.com/Jasonkks/PTTR 单一目标跟踪器
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds https://github.com/fpthink/V2B 单一目标跟踪器
3D Object Tracking with Transformer https://github.com/3bobo/lttr 单一目标跟踪器
3D-FCT: Simultaneous 3D Object Detection and Tracking Using Feature Correlation 针对PVRCNN的改进
Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving 多传感器融合
https://github.com/wangxiyang2022/DeepFusionMOT 多传感器融合
Learnable Online Graph Representations for 3D Multi-Object Tracking graph-based
Neural Enhanced Belief Propagation on Factor Graphs graph-based
TransTrack: Multiple Object Tracking with Transformer https://github.com/PeizeSun/TransTrack
TrackFormer https://github.com/timmeinhardt/trackformer
https://jialianwu.com/projects/TraDeS.html with分割
http://www.cvlibs.net/datasets/kitti/eval_tracking.php
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!

专栏订阅:https://blog.csdn.net/charmve/category_10595130.html
推荐阅读
(更多“自动驾驶感知”最新成果)
从感知机到Transformer:一文概述深度学习发展史!
多模态 Generalized Visual Language Models
硬核!自动驾驶如何做数据标注?特斯拉EP3 Auto Labeling深度分析
ICRA 2022杰出论文:把自动驾驶2D图像转成鸟瞰图,模型识别准确率立增15%
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

国内头部以自动驾驶全站技术为主线的交流学习社区(感知、归控等),包含大量前沿论文解读、工程实践(源代码)、视频课程,热招岗位。欢迎加入!
如果觉得有用,就请点赞、转发吧!