一、前言
1、reids客户端向服务端发送命令分四步(发送命令-命令排队-命令执行-返回结果),并监听socket返回,通常以阻塞模式等待服务端响应。
2、服务端处理命令,并将结果返回给客户端
以上两步称为:Round Trip Time(简称RTT,数据包往返于两端的时间)。
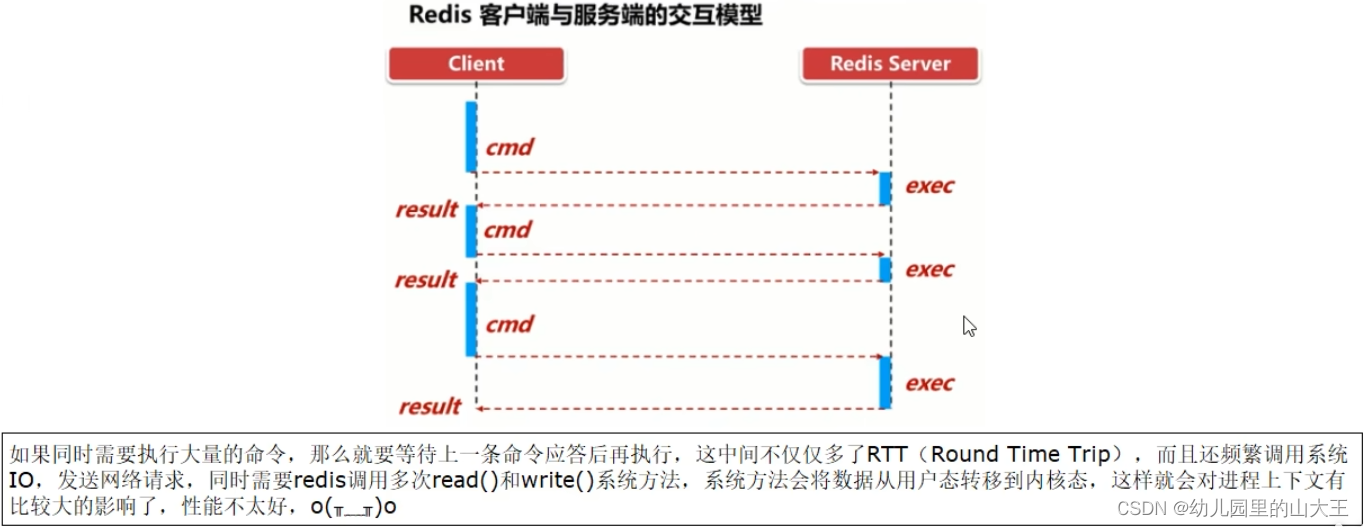
而管道主要解决的就是redis频繁命令往返造成的性能瓶颈
二、解决思路
管道(pipeline)可以一次性发送多条命令给服务端,服务端一次处理完毕后,通过一条响应一次性将结果返回,通过减少客户端与redis的通信次数来实现降低往返延时时间。pipeline实现的原理是队列,先进先出特性是保证数据的顺序性

三、定义
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
四、栗子
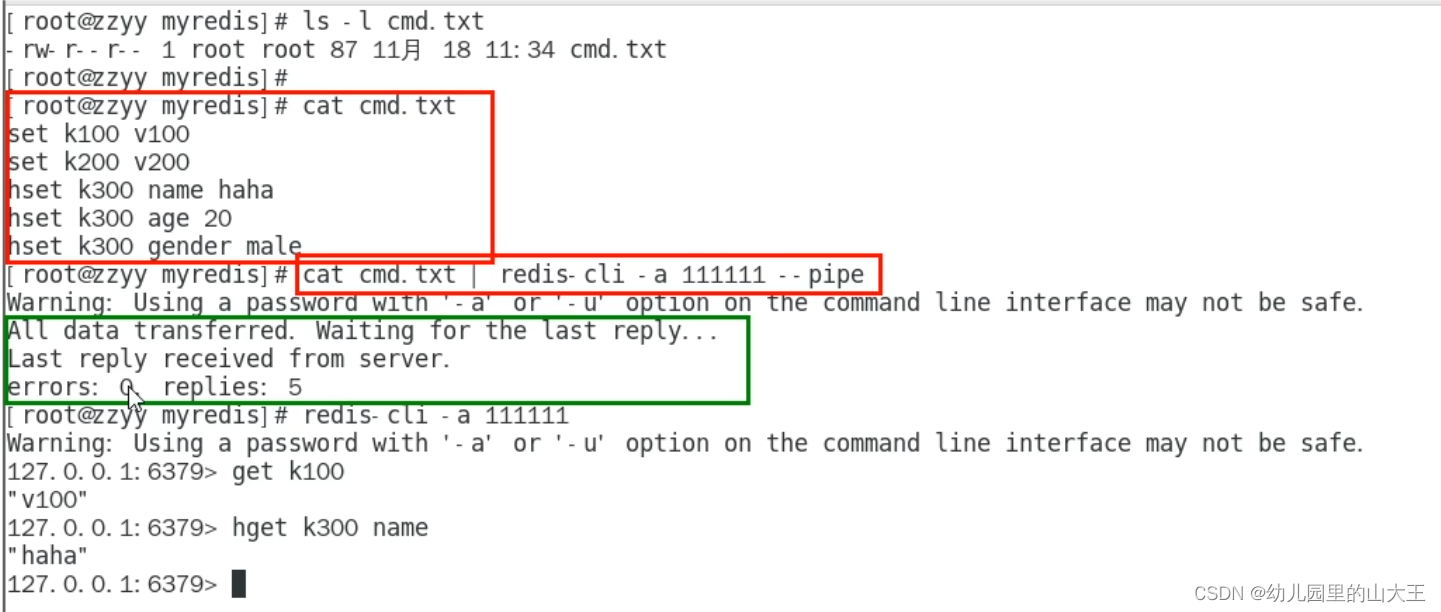
Jedis对管道的操作
Pipeline pipeline = conn.pipelined();
for (Student student: students){
String name= "name:" + student.getId();
pipeline.incry(name);
}List<Object> response = pipeline.syncAndReturnAll();
五、管道总结
1、管道与原生批量命令对比
1、原生批量命令是原子性的,例如:mget、mset。pipeline是非原子性的
2、原生批量命令一次只能执行一种命令,但是pipeline支持一次执行多中命令。
3、原生批量命令是服务端实现的,而pipeline需要服务端与客户端共同完成。
2、管道与事务对比
1、事务里面的命令是在服务端缓存,当发出exec命令的时候,服务端就会判断并执行事务命令。
管道里面的命令是在客户端缓存,当客户端结束管道后一次发送到服务端,服务端读取后按照先后顺序先后执行。所以事务的命令是一条一条发的,而管道的是一次性发送到服务端的。
2、执行事务时会阻塞其他命令的执行,而执行管道中的命令时不会。
3、事务中出现语法错误会导致事务不被执行,而管道出现语法错误,依然会执行其他命令。
3、使用pipeline注意事项
1、pipeline缓冲的命令只是会依次执行,不保证原子性,如果执行过程中发生异常,将会继续执行后续的命令。
2、使用pipeline组装的命令个数不能太多,不然数据量过大,客户端阻塞的时间可能过久,同时服务端此时也被迫恢复一个队列答复,占用很多内存。
官网:
使用管道发送命令时,服务器将被迫回复一个队列答复,占用很多内存。所以,如果你需要发送大量的命令,最好是把他们按照合理数量分批次的处理,例如10K的命令,读回复,然后再发送另一个10k的命令,等等。这样速度几乎是相同的,但是在回复这10k命令队列需要非常大量的内存用来组织返回数据内容。