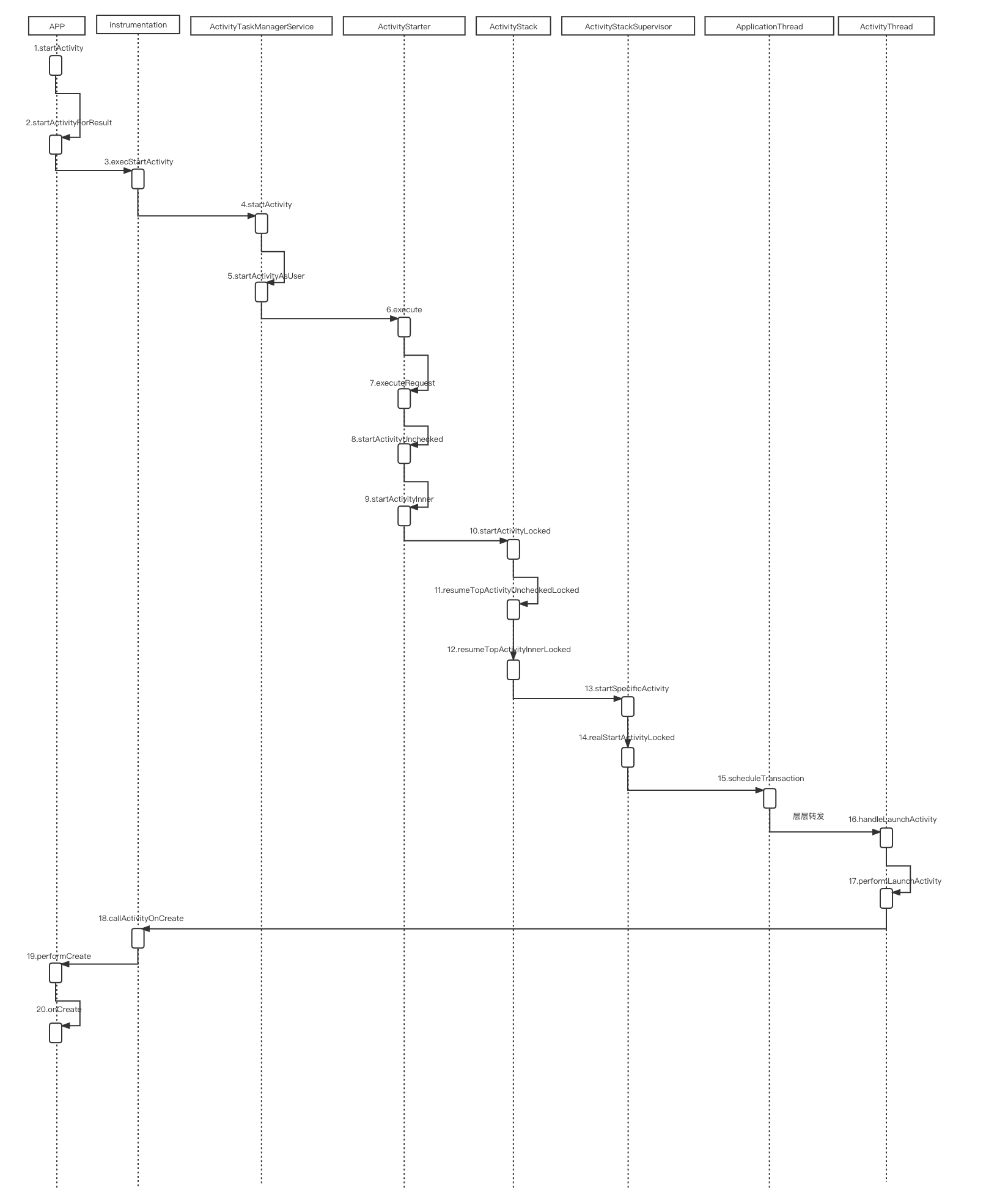
一.背景与问题
之前使用kafka-python库进行消费数据处理业务逻辑,但是没有深入里面的一些细节,导致会遇到一些坑。正常普通我们常见的一个消费者代码:(假设topic的分区数是20个)
from kafka import KafkaConsumer
bootstrap_servers = ['localhost:9092']
group_id = 'python-consumer'
consumer = KafkaConsumer(topic='test', bootstrap_servers=bootstrap_servers, group_id=group_id)
for msg in consumer:
s = msg.value.decode(encoding='utf-8')
print('从kafka获取到的数据: ' + s)这个代码本身没什么问题,消费数据都正常。但是消费能力随着数据写入量的增加,消费者消费能力跟不上,导致数据堆积严重。那到此我们先来回顾一下topic和分区相关知识。
1.topic是一个逻辑概念,数据实际存储是落在分区上的,所有的物理分区属于同一个topic。 每个topic的分区内的队列是有序的,但是不能保证某一条消息在全局是有序的。 一个topic有多个分区,能够解决其中的一个问题就是可以提高数据写入和消费能力。
2.一个消费组Group有多个消费者consumer,一个consumer可以消费一个topic里面的多个分区,但是一个topic分区只能被一个Group里面的一个消费者进行消费。
二.多进程消费
通过回顾的知识,我们理解了开篇的实例代码。 这个代码阐述的消费进程数和topic分区关系是:
1个进程消费了topic(test)的20个分区. 消费得到的msg对象,大家可以打印出所属分区id以及offset。
那也就很好解释了为什么随着生产者生产能力的增加,消费者为什么消费能力上不去。一个消费者同时消费20个分区的数据,消费能力自然上不来。 那此时我们可以使用多进程进行消费.那又有2个问题需要考虑:
1. 为什么不开启多进程而是多线程?
由于针对消费者线程安全问题, kafka-python库推荐使用多进程而非多线程:
GitHub - dpkp/kafka-python: Python client for Apache Kafka

2. 开启多少个进程合适呢? 消费进程越多消费能力越强?
非也. 消费者进程的数量并不是越多越好,也不是越少越好。 此时,我们通过上面的回顾知道,相同Group里面的一个consumer消费者进程可以消费同一个topic的多个分区,但是一个分区只能被一个消费者consumer消费。 针对20个分区,也就意味着我们最多只有20个消费者进程与之对应,一个分区能够被一个消费者消费,多出来的消费者进程是无法被kafka分配到消费"权利"的,那就意味着多出来的进程只能处于空转状态,白白消耗系统CPU和资源。
所以理想状态下,我们希望消费者consumer进程数量=分区数量,并且是一个消费者消费一个分区,此时消费效果应该较为合适。
此时我们针对代码修改,首先连接kafka,查询topic的分区数,然后开启和分区数一样多的进程。之后,我们针对每个分区分配一个消费者进程进行消费,每个进程维护自己消费分区的offset.
from kafka import KafkaConsumer, KafkaAdminClient, TopicPartition
from multiprocessing import Process
import sys
def run(topic_name, partition_id, group_id):
consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers,
max_poll_records=500, # 每次poll最大的记录数
max_poll_interval_ms=30000, # 两次间隔poll最大间隔时间ms
heartbeat_interval_ms=10000, # 每次心跳间隔ms
session_timeout_ms=20000, # 心跳会话超时时间ms
group_id=group_id
)
# 为进程指定消费的topic名称、分区id
consumer.assign([TopicPartition(topic_name, partition_id)])
while True:
messages = consumer.poll(timeout_ms=1000) # 拉取每次超时时间, 如果1000ms内拉到500条记录则直接返回,如果超过了1000ms拉不到500条也返回
for tp, messages_list in messages.items():
for message in messages_list:
print(message.value.decode(), message.offset)
if __name__ == '__main__':
# 获取分区数
bootstrap_servers = ['localhost:9092']
adminClient = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
topic = 'test'
topics = ['test']
group_id = 'python-consumer'
tps = adminClient.describe_topics()
partitions_len = len(tps[0]['partitions'])
if partitions_len <= 0:
print("topic 分区数 <= 0")
sys.exit(1)
# 开启多进程, 进程数 = 分区数
processes = []
for i in range(partitions_len):
p = Process(target=run, args=(topic, i, group_id,))
p.start()
processes.append(p)
# 等待所有进程结束
for p in processes:
p.join()
经过我们使用多进程的方式分别消费对应的分区数据,消费者能力一下子比原来消费能力翻了几倍甚至几十倍。 所以针对数据写入量大,同时消费能力也要跟得上的情况下,我们针对topic要设置多分区、启动多个消费者,但是消费者的数量尽量和topic分区数保持一样,这样每个进程就能消费对应一个分区,提高了资源的利用率和消费能力!
其他编程语言也是一样的原理,这个和实现的编程语言没关系,道理都是相同的。如果使用Golang编写,那么这里的多进程我们可以换成多协程实现都可以,具体情况具体分析即可。