随着 flink 的快速发展与 API 的迭代导致新老版本差别巨大遂重拾 flink,在回顾到时间语义时对 watermark 有了不一样的理解。
一、如何生成
在 flink 1.12(第一次学习的版本)时 watermark 生成策略还有两种: punctuated 和 periodic,在 1.17 中 punctuated 已被标记过时。这里简单阐述一下这两种策略的不同
- punctuated: 随事件进行生成,每条数据后插入一个根据当前事件解析出来的 watermark
- periodic: 随时间进行生成,默认每 200ms 生成一次 watermark
当 flink 系统吞吐量巨大 punctuated 策略会导致系统数据量剧增甚至阻塞业务数据的流动(提前透露一下 watermark 本质也是一条数据);periodic 策略就很好的解决这个痛点,可能有人疑惑了: 当 flink 没有数据时 periodic 也会定时无限的生成 watermark 会不会有问题?显然是不会的,因为 flink 本身就是大数据处理框架这点 QPS 简直是洒洒水,其次下游对 watermark 的处理逻辑也是轻量级的(第三章)。下面是当前版本 flink 生成 watermark 的 api
package org.vital.eu.job.time;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class WaterMarkGenerateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.socketTextStream("127.0.0.1", 1111)
.map(x -> x)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forMonotonousTimestamps()
.withTimestampAssigner((element, recordTimestamp) -> Long.parseLong(element)))
.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out) {
System.out.println("当前 watermark: " + ctx.timerService().currentWatermark());
out.collect(value);
}
})
.print();
env.execute();
}
}
Tip: 这里的 map 算子很重要,是我能进行下去的重要依据
对于构造 watermark 的策略又有三种:
- forMonotonousTimestamps: 时间戳单调递增生成策略
- forBoundedOutOfOrderness: 为记录乱序的情况创建水印策略
- forGenerator: 自定义策略
这里不再赘述 forMonotonousTimestamps 和 forBoundedOutOfOrderness 应用场景,forGenerator 自定义生成也不再赘述(给的两种策略够用了)。下面是两种策略源码
static <T> WatermarkStrategy<T> forMonotonousTimestamps() {
return (ctx) -> new AscendingTimestampsWatermarks<>();
}
public class AscendingTimestampsWatermarks<T> extends BoundedOutOfOrdernessWatermarks<T> {
/** Creates a new watermark generator with for ascending timestamps. */
public AscendingTimestampsWatermarks() {
super(Duration.ofMillis(0));
}
}
static <T> WatermarkStrategy<T> forBoundedOutOfOrderness(Duration maxOutOfOrderness) {
return (ctx) -> new BoundedOutOfOrdernessWatermarks<>(maxOutOfOrderness);
}
可以看出 forMonotonousTimestamps 本质上就是 forBoundedOutOfOrderness,只不过乱序程度为 0。
对于 watermark 生成策略在 flink 上是一个接口
public interface WatermarkGenerator<T> {
// 数据来一条调用一次
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
// 定时调用,默认 200ms
void onPeriodicEmit(WatermarkOutput output);
}
我们来看一下 forBoundedOutOfOrderness 是如何实现的
public class BoundedOutOfOrdernessWatermarks<T> implements WatermarkGenerator<T> {
// 记录接收到的最大时间戳
private long maxTimestamp;
// 乱序程度
private final long outOfOrdernessMillis;
public BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) {
checkNotNull(maxOutOfOrderness, "maxOutOfOrderness");
checkArgument(!maxOutOfOrderness.isNegative(), "maxOutOfOrderness cannot be negative");
this.outOfOrdernessMillis = maxOutOfOrderness.toMillis();
// 默认值为 Long 最小值 + 乱序程度 + 1
this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;
}
// ------------------------------------------------------------------------
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
// 每条数据都会更新最大值
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发送 watermark 逻辑
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
}
需要注意的是new Watermark(maxTimestamp - outOfOrdernessMillis - 1),减去 outOfOrdernessMillis 好理解是为了修正乱序,减 1ms 是为了后续的开窗函数,保证窗口是一个左闭右开的状态,保证上层 flink 中刚好是窗口关闭时间的数据只会落在一个窗口,例如某个 flink 任务的窗口是 [0,5)、[5,10),保证 5s 的数据只在一个窗口
Tip: punctuated 策略其实就是将发送 watermark 的逻辑写到 onEvent 中
二、它的本质
2.1 assignTimestampsAndWatermarks 本质
它的本质是一个算子
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy) {
final WatermarkStrategy<T> cleanedStrategy = clean(watermarkStrategy);
// match parallelism to input, to have a 1:1 source -> timestamps/watermarks relationship
// and chain
final int inputParallelism = getTransformation().getParallelism();
final TimestampsAndWatermarksTransformation<T> transformation =
new TimestampsAndWatermarksTransformation<>(
"Timestamps/Watermarks",
inputParallelism,
getTransformation(),
cleanedStrategy,
false);
getExecutionEnvironment().addOperator(transformation);
return new SingleOutputStreamOperator<>(getExecutionEnvironment(), transformation);
}
更直观的可以使用 flink web ui,对 assignTimestampsAndWatermarks 应用禁用算子链策略(调用 disableChaining)

至于这个算子到底执行了什么逻辑定义在 TimestampsAndWatermarksOperator 中,其生命周期 open 方法
public void open() throws Exception {
super.open();
timestampAssigner = watermarkStrategy.createTimestampAssigner(this::getMetricGroup);
watermarkGenerator =
emitProgressiveWatermarks
? watermarkStrategy.createWatermarkGenerator(this::getMetricGroup)
: new NoWatermarksGenerator<>();
wmOutput = new WatermarkEmitter(output);
watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();
if (watermarkInterval > 0 && emitProgressiveWatermarks) {
final long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
}
首先从配置中获取定时生成 watermark 间隔参数并创建当前时间(处理时间)+间隔的定时器定义了第一个 watermark 是如何生成的。定时器会自动执行 onProcessingTime 方法
public void onProcessingTime(long timestamp) throws Exception {
watermarkGenerator.onPeriodicEmit(wmOutput);
final long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
可以看到 onPeriodicEmit 在这里被调用发送一次 watermark,随后再次创建下一次的定时器(这种思路可以在开发定时器时借鉴一下),作为一个算子肯定会接受数据并进行处理,即 processElement 方法
public void processElement(final StreamRecord<T> element) throws Exception {
final T event = element.getValue();
final long previousTimestamp =
element.hasTimestamp() ? element.getTimestamp() : Long.MIN_VALUE;
final long newTimestamp = timestampAssigner.extractTimestamp(event, previousTimestamp);
element.setTimestamp(newTimestamp);
output.collect(element);
watermarkGenerator.onEvent(event, newTimestamp, wmOutput);
}
从方法的入参可以看出来 flink 算子间的数据流动是 StreamRecord 对象。它对数据的处理逻辑是什么都不做直接向下游发送,然后调用 onEvent 记录最大时间戳,也就是说:flink 是先发送数据再生成 watermark,watermark 永远在生成它的数据之后。
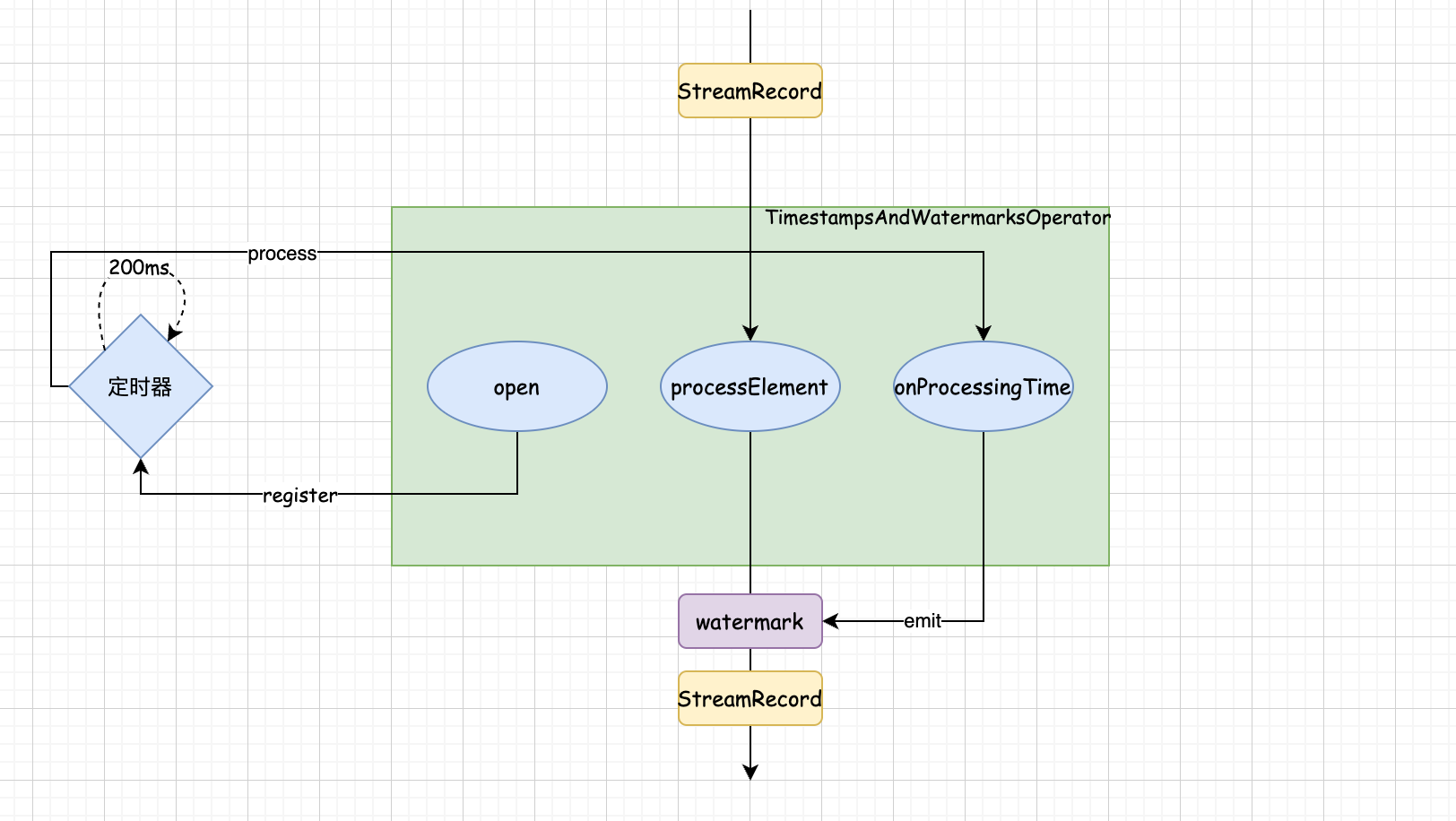
总结: watermark 生成器本质上是一个算子,在生命周期方法 open 中注册定时器并在定时器中发送记录的最大时间戳的 watermark 并继续注册定时器;算子对业务数据不做任务处理直接发送给下游后记录当前数据的时间与记录的最大时间作比较(即使是事件时间也不可回溯)
2.2 Watermark 本质
探究一下output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));做了什么,首先 output 是一个 WatermarkOutput 对象同样是在 open 方法中被定义
wmOutput = new WatermarkEmitter(output);
发送 watermark 的方法如下
@Override
public void emitWatermark(Watermark watermark) {
final long ts = watermark.getTimestamp();
if (ts <= currentWatermark) {
return;
}
currentWatermark = ts;
markActive();
output.emitWatermark(new org.apache.flink.streaming.api.watermark.Watermark(ts));
}
最终时间会被封装成org.apache.flink.streaming.api.watermark.Watermark
public final class Watermark extends StreamElement {
}
继承自 StreamElement,这个类就有意思了从第三章的分析可以得出结论,flink 算子见的数据流动统一是 StreamElement(用于 checkpoint 的 barrier 不在其中,它是分布式快照机制具有对应的操作,普通数据是没有操作的)。对于 StreamElement 有四个子类分别是:
- StreamRecord: 业务数据
- Watermark: 用于表示事件时间的特殊数据
- LatencyMarker: 特殊记录数据,记录创建时间、算子id、subtask编号
- WatermarkStatus: 用于标记是否为空闲流,即:IDLE 和 ACTIVE
也就是说 watermark 本质上和业务数据没有什么区别,都是作为 StreamElement 在算子间流动,只不过下游分发策略是广播
三、如何传递
在 process 算子中打上断点进行 debug,通过分析调用方法的堆栈发现核心方法 processElement
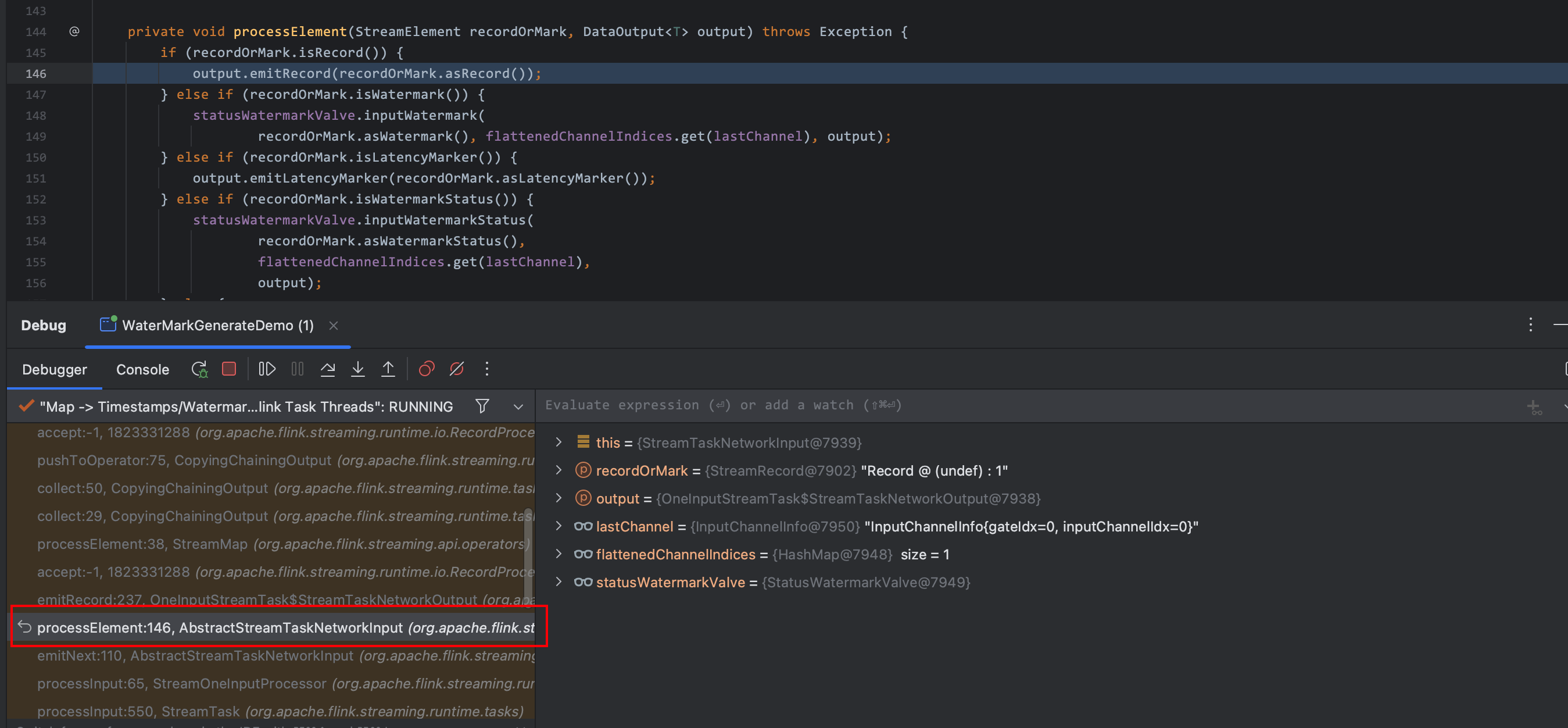
源码如下:
private void processElement(StreamElement recordOrMark, DataOutput<T> output) throws Exception {
if (recordOrMark.isRecord()) {
output.emitRecord(recordOrMark.asRecord());
} else if (recordOrMark.isWatermark()) {
statusWatermarkValve.inputWatermark(
recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);
} else if (recordOrMark.isLatencyMarker()) {
output.emitLatencyMarker(recordOrMark.asLatencyMarker());
} else if (recordOrMark.isWatermarkStatus()) {
statusWatermarkValve.inputWatermarkStatus(
recordOrMark.asWatermarkStatus(),
flattenedChannelIndices.get(lastChannel),
output);
} else {
throw new UnsupportedOperationException("Unknown type of StreamElement");
}
}
这里则验证上面的说明,算子间数据传递都被封装成 StreamElement,并在 processElement 中进行判断
3.1 StreamRecord 处理逻辑
StreamRecord 作为业务数据的封装,在后续被 ProcessOperator 中被 processElement 调用
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
collector.setTimestamp(element);
context.element = element;
userFunction.processElement(element.getValue(), context, collector);
context.element = null;
}
最终将数据传递给用户函数 userFunction 即我们再算子中定义的逻辑
3.2 Watermark 处理逻辑
我们知道当算子接收到 Watermark 时首先会进行对其操作并发送接收到的最小的 Watermark 到下游,也就是在多并行下 Watermark 传递规则是发送接收到的最小的 Watermark。
public void inputWatermark(Watermark watermark, int channelIndex, DataOutput<?> output)
throws Exception {
// ignore the input watermark if its input channel, or all input channels are idle (i.e.
// overall the valve is idle).
if (lastOutputWatermarkStatus.isActive()
&& channelStatuses[channelIndex].watermarkStatus.isActive()) {
long watermarkMillis = watermark.getTimestamp();
// if the input watermark's value is less than the last received watermark for its input
// channel, ignore it also.
if (watermarkMillis > channelStatuses[channelIndex].watermark) {
channelStatuses[channelIndex].watermark = watermarkMillis;
if (channelStatuses[channelIndex].isWatermarkAligned) {
adjustAlignedChannelStatuses(channelStatuses[channelIndex]);
} else if (watermarkMillis >= lastOutputWatermark) {
// previously unaligned input channels are now aligned if its watermark has
// caught up
markWatermarkAligned(channelStatuses[channelIndex]);
}
// now, attempt to find a new min watermark across all aligned channels
findAndOutputNewMinWatermarkAcrossAlignedChannels(output);
}
}
}
接收 Watermark 的前提条件是上游是活跃状态即不处于 IDLE,注意 channelIndex 代表当前通道的索引,channel 是 flink 算子内部维护了一组输入和输出通道,用于实现数据流的输入和输出
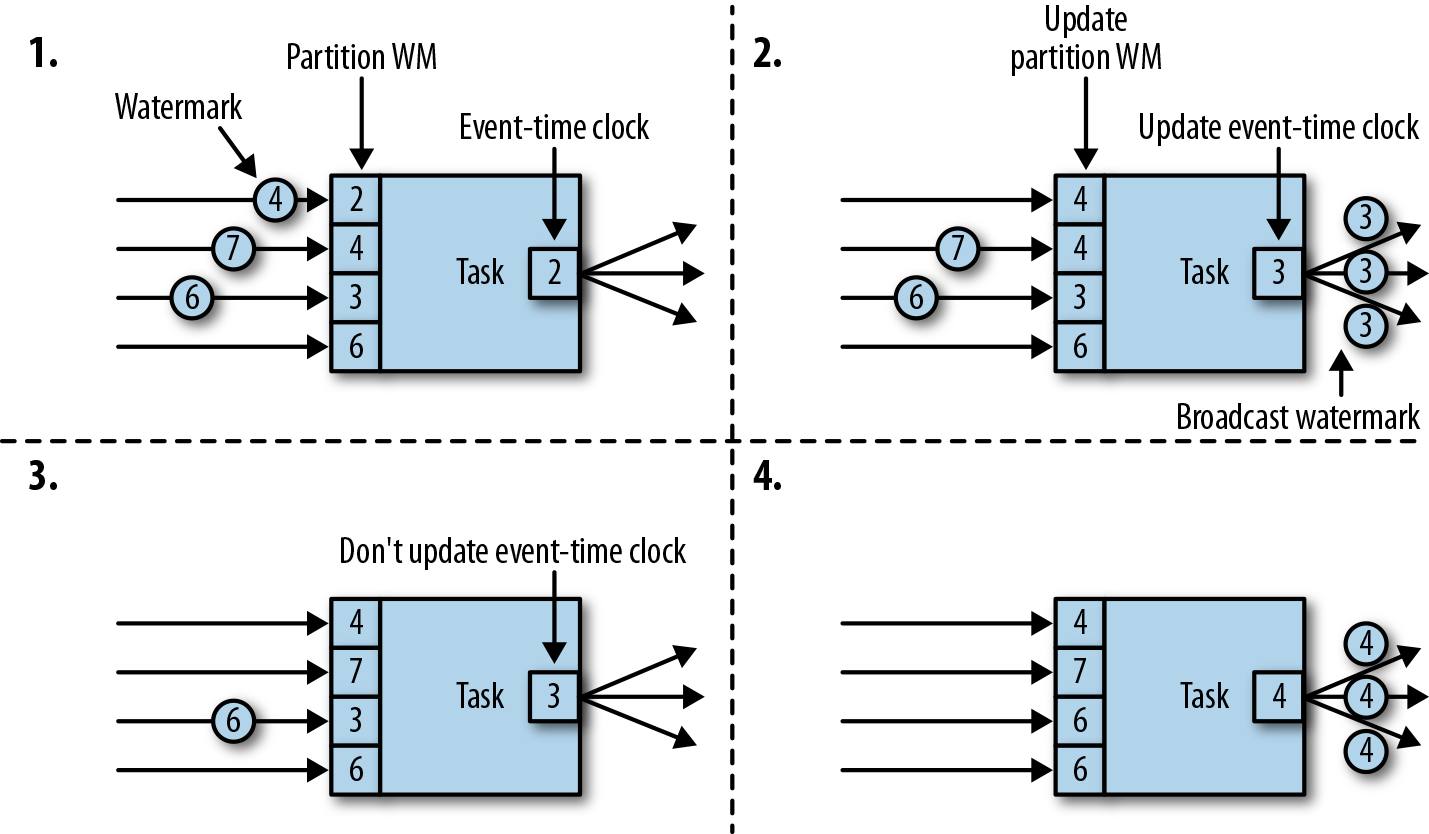
实现接收上游数据的通道在 flink 中由 InputChannel 实现(跑题了)
回到对 Watermark 的处理逻辑上,首先判断接收到的 Watermark 与保存的 Watermark 大小,如果小于保存的则什么都不做否则将保存接收到的 Watermark;随后进行通道对其,关于内部的对其逻辑博主还需要花时间继续研究一下,从方法名和参数来看初步判断是使用 PriorityQueue 来实现的(后续研究透了再来水一篇)。
3.3 WatermarkStatus 处理逻辑
WatermarkStatus 主要是将当前 channel 状态进行转换,从 idle -> active 或 active -> idle,除了状态上的变化还会修改其对其状态等
3.4 LatencyMarker 处理机制
这个最简单直接进行透传
总结: 从 processElement 中可以看出在算子内部数据、Watermark是串行处理的,当业务数据没有处理完是不会处理后面的数据,这也就是为什么我们通过上下文对象拿个当前的 Watermark 时都是会慢与当前数据,即使你在函数中等待 Watermark 触发定时也拿不到,因为此时 Watermark 还有没进入算子中没有被处理,算子在 processElement 中被阻塞了