目录
- 前言
- 0、transformers的安装以及介绍
- 0-1、 介绍
- 0-2、安装
- 一、分词——transformers.AutoTokenizer
- 1-0、相关参数介绍(常用参数介绍)
- 1-1、加载、保存
- 1-2、使用以及原理
- 二、黑盒子——transformers.pipeline
- 2-0、pipeline怎么理解?
- 2-1、目前可用的pipeline以及简单的小栗子
- 总结
前言
周四了,日复一日的时间过得飞快!
0、transformers的安装以及介绍
0-1、 介绍
Huggingface是一家在NLP社区做出杰出贡献的纽约创业公司,其创建的库Transformers被广泛使用,Transformers提供了数以千计针对于各种任务的预训练模型模型,开发者可以根据自身的需要,选择模型进行训练或微调,也可阅读api文档和源码, 快速开发新模型。
0-2、安装
# 安装轻量级Transformers,初学适用,一般情况下够用了。(包含AutoTokenizer、BertTokenizer,别的不知道)
pip install transformers
# 安装开发版本,进阶适用
pip install transformers[sentencepiece]
一、分词——transformers.AutoTokenizer
原理:Tokenizer的主要作用是将文本输入转化为模型可以接受的输入,即数值型的输入。
1-0、相关参数介绍(常用参数介绍)
- text (str, List[str], List[List[str]]`):就是输入的待编码的序列(或1个batch的),可以是字符串或字符串列表。
- add_special_tokens(bool, optional, defaults to True) :True就是给序列加上特殊符号,如[CLS],[SEP]
- padding (Union[bool, str], optional, defaults to False) :给序列补全到一定长度,True or ‘longest’: 是补全到batch中的最长长度,max_length’:补到给定max-length或没给定时,补到模型能接受的最长长度。
- truncation (Union[bool, str], optional, defaults to False) :截断操作,true or ‘longest_first’:给定max_length时,按照max_length截断,没给定max_lehgth时,到,模型接受的最长长度后截断,适用于所有序列(单或双)。only_first’:这个只针对第一个序列。only_second’:只针对第二个序列。
- max_length (Union[int, None], optional, defaults to None) :控制padding和truncation的长度。
- return_tensors (str, optional, defaults to None):返回数据的类型,可选tf’, ‘pt’ or ‘np’ ,分别表示tf.constant, torch.Tensor或np.ndarray
1-1、加载、保存
# tokenizer的加载和保存使用的方法是from_pretrained、save_pretrained
from transformers import AutoTokenizer
from transformers import BertTokenizer
from transformers import AutoConfig
from transformers import AutoModel
# 加载分词器
# bert-base-cased这里代表的是bert的基础版本
# 也可以加载本地保存的模型。
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# 保存
tokenizer.save_pretrained("no_more")
# 加载模型和加载模型配置
# AutoModel.from_pretrained('bert-base-uncased')
# AutoConfig.from_pretrained('bert-base-uncased')
bert的常用预训练模型:

1-2、使用以及原理
# 将文本转化为数字
tokenizer("It's impolite to love again", padding=True, truncation=True, return_tensors="pt")
# Tokenizer的过程先分词,后将分词后的token映射为数字
# 1、 分词
token = tokenizer.tokenize("It's impolite to love again")
# ['It', "'", 's', 'imp', '##oli', '##te', 'to', 'love', 'again']
# 2、 映射
ids = tokenizer.convert_tokens_to_ids(token)
# [1135, 112, 188, 24034, 11014, 1566, 1106, 1567, 1254]
# 3、 将映射后的数字再重新转变为文本
str = tokenizer.decode(ids)
# "It's impolite to love again"
# 4、也可以直接用对应的encode将字符串转变为数字
tokenizer.encode("It's impolite to love again")
# [1135, 112, 188, 24034, 11014, 1566, 1106, 1567, 1254]
二、黑盒子——transformers.pipeline
2-0、pipeline怎么理解?
含义:可以理解为一个打包好的黑盒子,内置流水线的处理方法(包含数据读取、数据预处理、创建模型、评估模型结果、模型调参等)。即输入原始数据,直接就可以给出结果,是不是十分方便?
2-1、目前可用的pipeline以及简单的小栗子
feature-extraction 特征提取:把一段文字用一个向量来表示
fill-mask 填词:把一段文字的某些部分mask住,然后让模型填空
ner 命名实体识别:识别文字中出现的人名地名的命名实体
question-answering 问答:给定一段文本以及针对它的一个问题,从文本中抽取答案
sentiment-analysis 情感分析:一段文本是正面还是负面的情感倾向
summarization 摘要:根据一段长文本中生成简短的摘要
text-generation文本生成:给定一段文本,让模型补充后面的内容
translation 翻译:把一种语言的文字翻译成另一种语言
以下为常见任务所用到的模型举例:
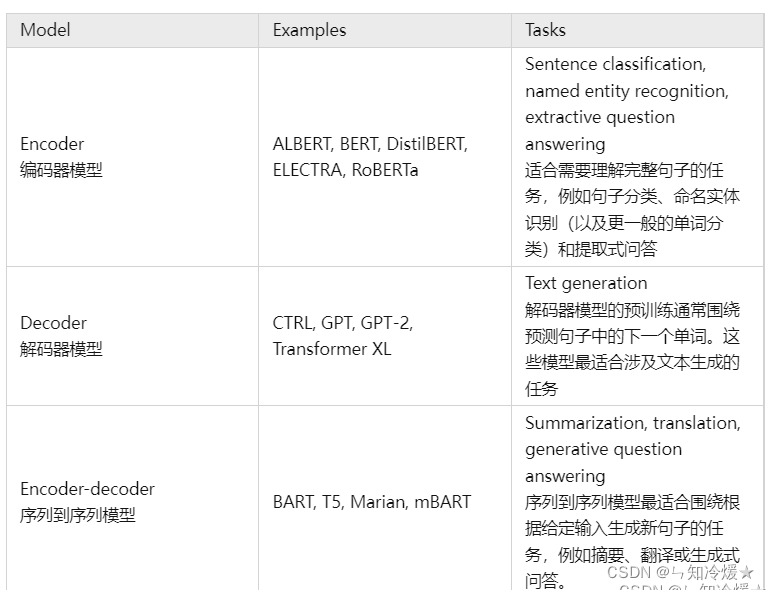
简单举例:
# 过程遇到一个无法加载torch下的一个什么配置文件的错误,找了一下午资料不知道是什么原因,一气之下删掉torch,结果问题解决了。
from transformers import pipeline
# 这里使用任务会自动下载对应的模型,注意预留好空间。
# 下载速度很慢,可以直接到末尾参考链接里下载。
# 选择任务为文本生成,使用pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
输出:
[{‘generated_text’: 'In this course, we will teach you how to understand and use ’
'data flow and data interchange when handling user data. We ’
'will be working with one or more of the most commonly used ’
'data flows — data flows of various types, as seen by the ’
‘HTTP’}]
参考文章:
Transformers Tokenizer API 的使用.
深度学习pipeline和baseline是什么意思?.
huggingface使用(一):AutoTokenizer(通用)、BertTokenizer(基于Bert).
[NLP] transformers 使用指南.
【Huggingface Transformers】保姆级使用教程02—微调预训练模型 Fine-tuning.
用huggingface.transformers在文本分类任务(单任务和多任务场景下)上微调预训练模型.
【Huggingface Transformers】保姆级使用教程—上.
【学习笔记】Transformers库笔记.
transformers官方文档.
AutoModel文档:.
AutoTokenizer文档:.
Pipeline文档:.
任务模型在这里下载:.
总结
再爱就不礼貌了。