Java 基础数据类型占用内存空间简介
- 一 计算机简介
- 1.基本概念
- 2.CPU 三级缓存
- 3.本机参数查看
- 二 数据占用内存情况
- 1.多线程Demo
- 2.结果解析
- 1.直接计算
- 2.volatile 计算
- 3.缓存行填充
一 计算机简介
结合多线程计算机的硬件,从侧面理解数据存储如何影响我们的程序
1.基本概念
1.RAM:随机存储(主存等,断电数据丢失)
2.ROM:只读存储(磁盘等,断点数据保留)
3.BIOS:烧录在主板上ROM内的一段程序(基础输入/输出系统)
1.线程:程序或应用的某个功能点,由CPU分配时间片,进行调度
2.进程:完整的运行中的程序或应用,由操作系统进行调度
1.单核单线程:一个核心,只能运行一个线程,完全结束后才能开始下一个(串行)
2.单核多线程:一个核心,能调度多个线程,多个线程在某个时间段的不同时间片上运行(并发)
3.多核多线程:多个核心,每个核心至少支持一个线程,至少能有核心数的线程在某个时刻运行(并行)
4.DMA(Direct Memory Access):直接内存控制器,即CPU进行文件复制时,将总线控制权交给DMA,由DMA进行复制,此时CPU能继续进行内部运算或挂起,DMA结束后交还控制权;
CPU 与 DMA 还可交替访问内存,此时总线相当于一个换路器。DMA也是我们常说的【零拷贝技术】依赖的硬件基础
1.并发:一个计算单元(CPU核心),某一时刻只能运行一个线程,某个时间段多个线程在这个核心内轮询执行就是并发
所以并发在本质上调度仍然是串行,只不过每个时间片很短,给我们的感觉是所有程序同时在运行
其实,由此可以引出多线程开发设置核心线程数的参考原因:
CPU密集型:核心线程数最好与实际核心数一致,CPU密集则尽量使每个线程落在一个核心上,使他们之间发挥并行的效果,核心线程数过大则会在某个核频繁切换上下文(轮询),切换上下文涉及现场保存和恢复等,会消耗性能
IO密集型:核心线程数约为实际核心数二倍,由于IO操作的耗时性,当IO等待时,可以让CPU去执行其他线程操作(反正要等待,不如顺便切换几次上下文)
2.并行:多个计算单元(CPU核心),某一个时刻分别运行了一个线程,则这几个线程此刻是并行的
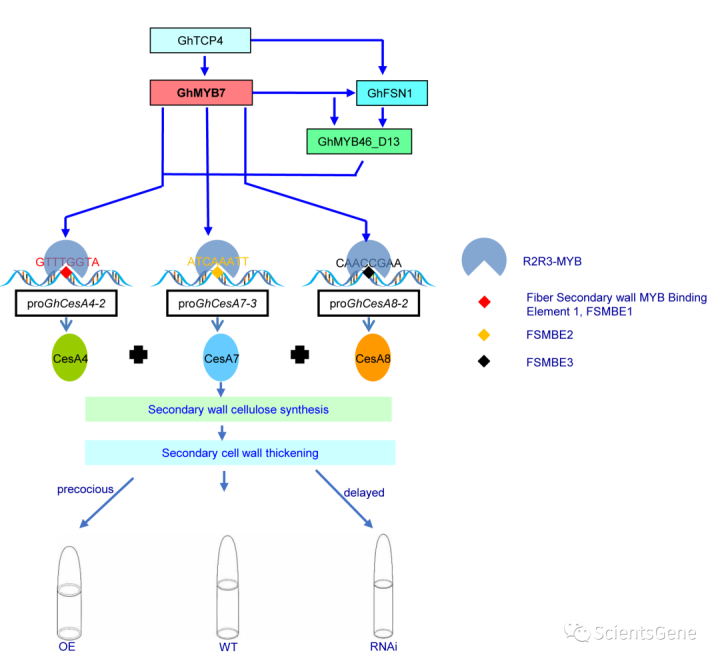
2.CPU 三级缓存
CPU从硬件角度来看,本身设计也是多级缓存的,结构示意如图,而多级缓存的主要目的,和
软件一样,为了提升程序执行和数据访问速度;但是既然是缓存,就涉及到数据一致的问题,
多核CPU下,常见的缓存一致性协议有 MESI
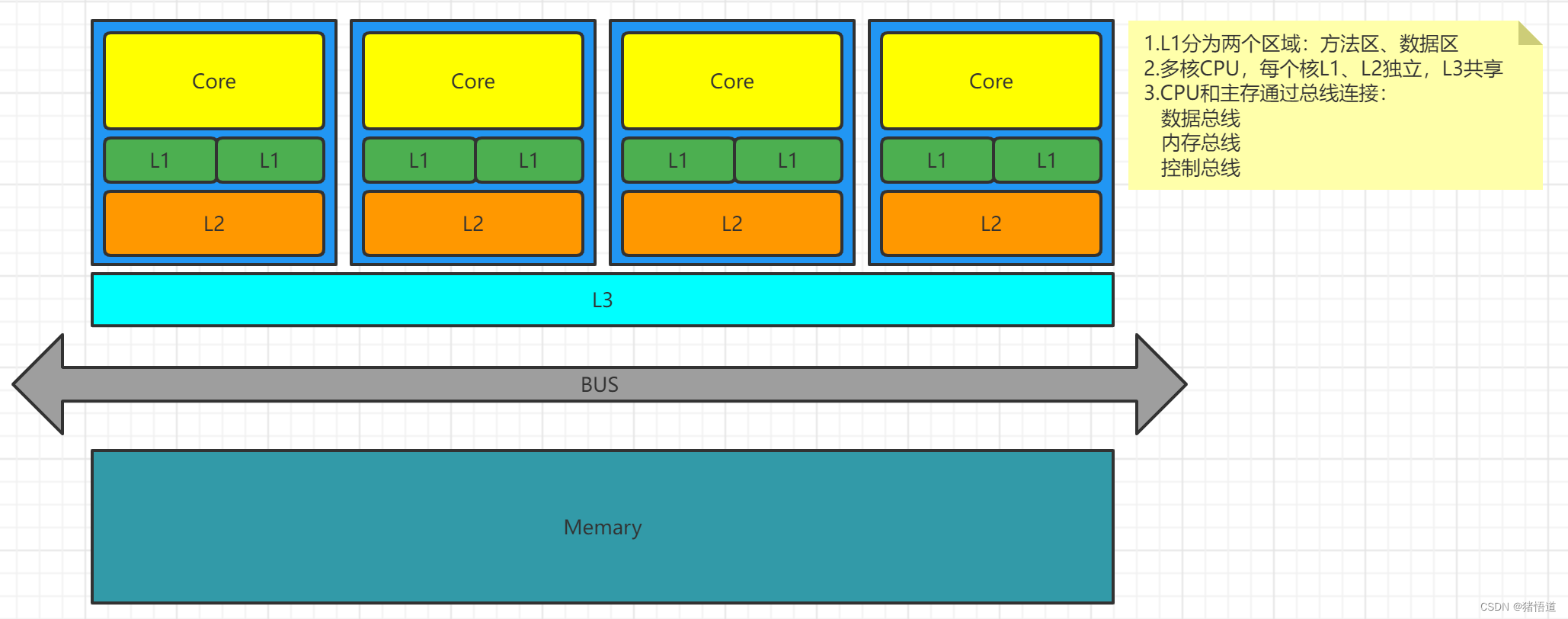
三级缓存下 ALU 访问资源时间
| 资源对象 | 周期(可有频率换算) | 时间(纳秒) |
|---|---|---|
| 寄存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 内存 | ~120-240 cycles | ~60-120ns |
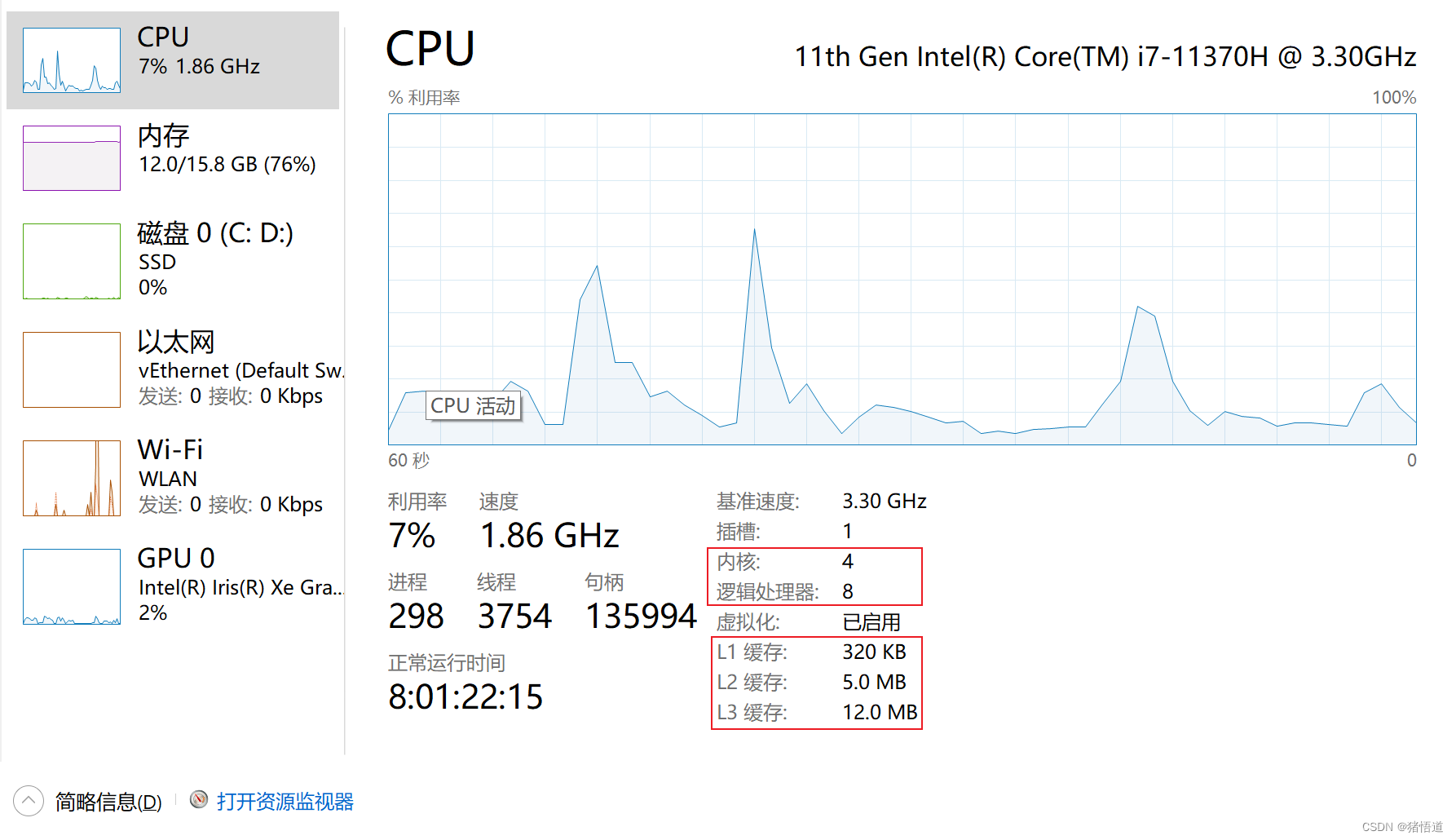
3.本机参数查看
其中逻辑处理器,是基于物理内核虚拟出来的,本机共 4 个内核,虚拟后相当于有 8 个内核
二 数据占用内存情况
在 Java 里面,使用 volatile 修饰变量时,可能会存在一个伪内存共享问题,我们下面演示一下
volatile 本身有两个作用:可见性、防止指令重排
程序运行时,我们的数据不是一位一位加载的,而是一块一块的,缓存的最小结构是缓存行
,一次填充一个缓存行的数据,这样做也是为了提高处理速度,缓存行大小一般为 64 字节;
volatile 如何保证可见性呢?
当某个线程更新本地缓存中的 value 值后,会使其他线程的本地缓存中的 value 值失效,然后其他线程需要重新去主存取数据,也就保证了可见性
但是由于 value 是存在缓存行内的,每次置失效都要清掉整行数据,重新获取,此时即存在性能损耗
1.多线程Demo
package org.example;
import org.openjdk.jol.info.ClassLayout;
/**
* @author
* @date 2022-11-08 22:44
* @since 1.8
*/
public class CpuCache {
public static void main(String[] args) {
DemoEntity demo = new DemoEntity();
int length = 10000 * 10000;
Thread t1 = new Thread(()->{
for (int i = 0 ;i < length;i++){
demo.a++;
}
});
Thread t2 = new Thread(()->{
for (int i = 0 ;i < length;i++){
demo.f++;
}
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
long end = System.currentTimeMillis() - start;
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
System.out.println(String.format("Time:%s Data %s",end,demo));
}
/**
* 测试对象
*/
static class DemoEntity{
private long a;
private long f;
@Override
public String toString(){
return String.format("a:%s b:%s",a,f);
}
}
}
2.结果解析
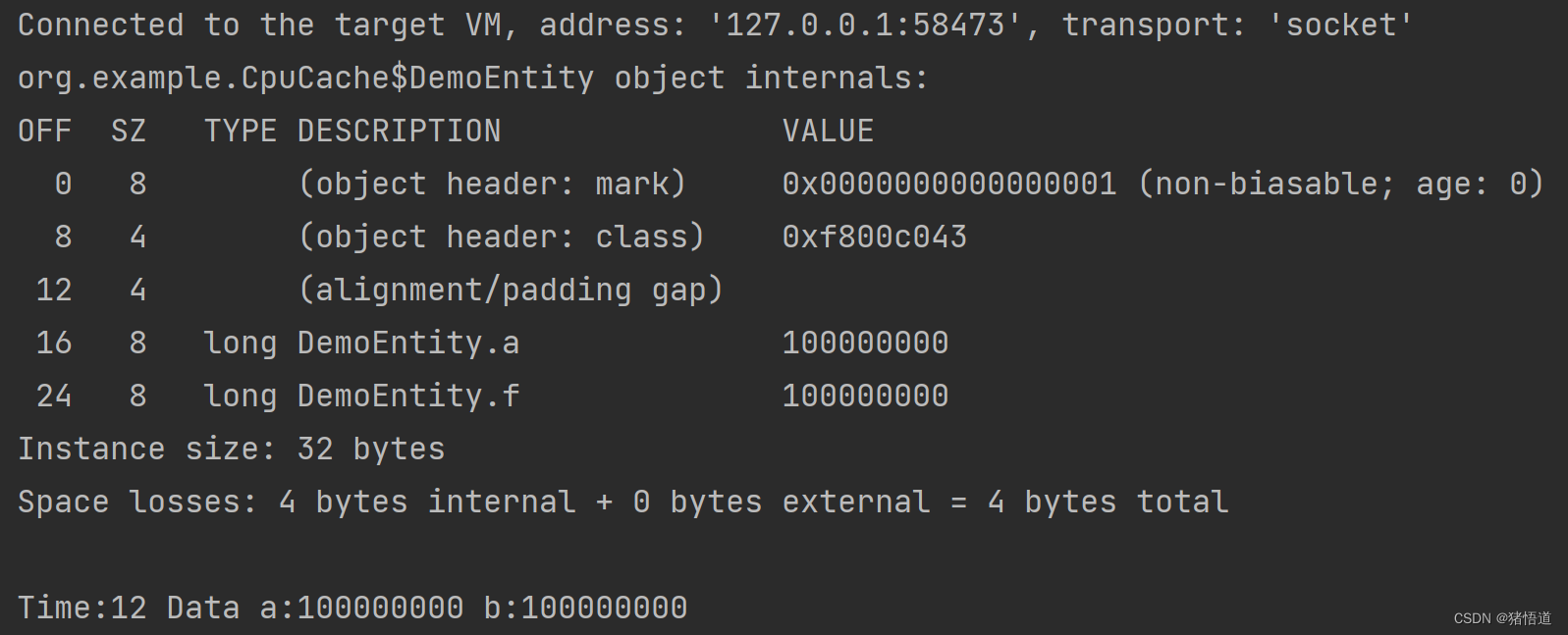
1.直接计算
线程 1 和 2 都加载了数据时,各自计算,12 毫秒完成了计算
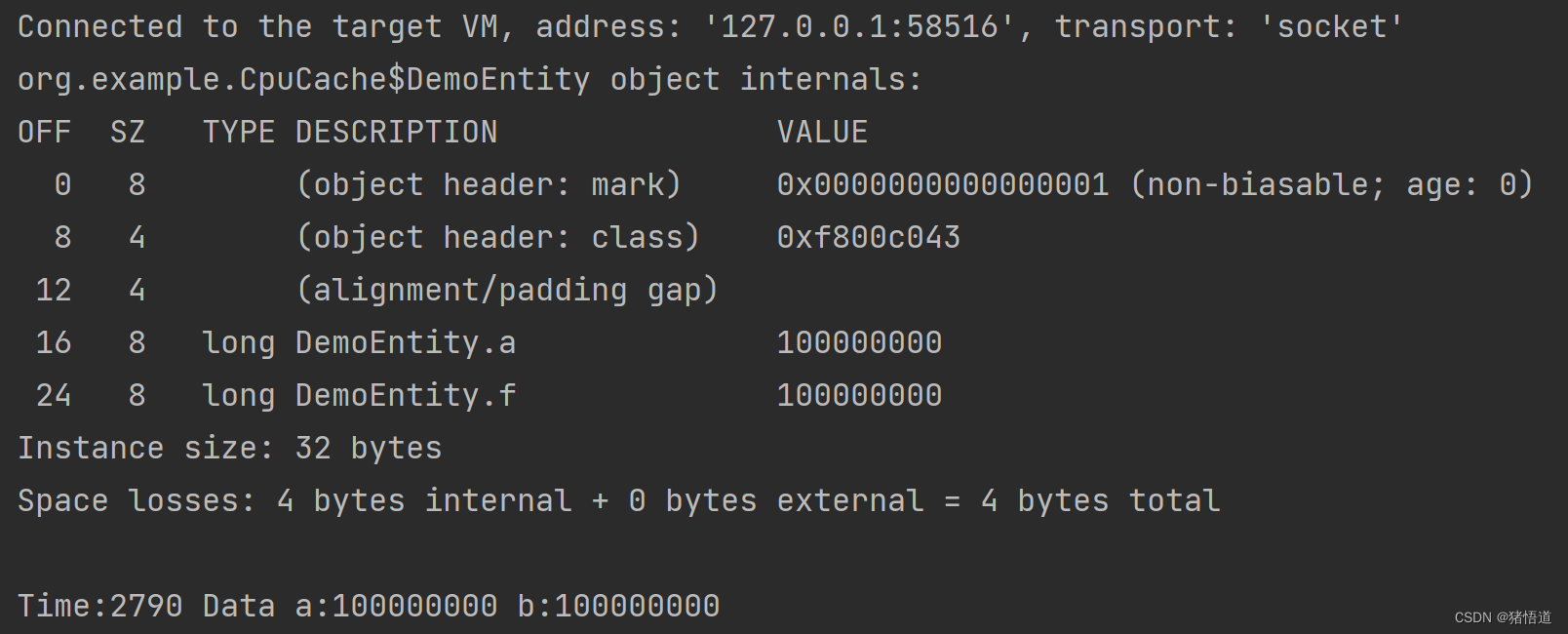
2.volatile 计算
修改代码,在 DemoEntity 的两个变量前加上 volatile 关键字修饰,重新运行;耗时 2790 毫秒 ?
解析:
上面我们说,数据是加载到缓存行的,我们添加了 volatile 关键字后,两个线程修改同一个对象时,为了保证可见性,会将其他其他缓存行数据清空
线程 1 和 2 的数据大概率加载后会在同一个缓存行,他们互相清空和争抢资源,导致耗时
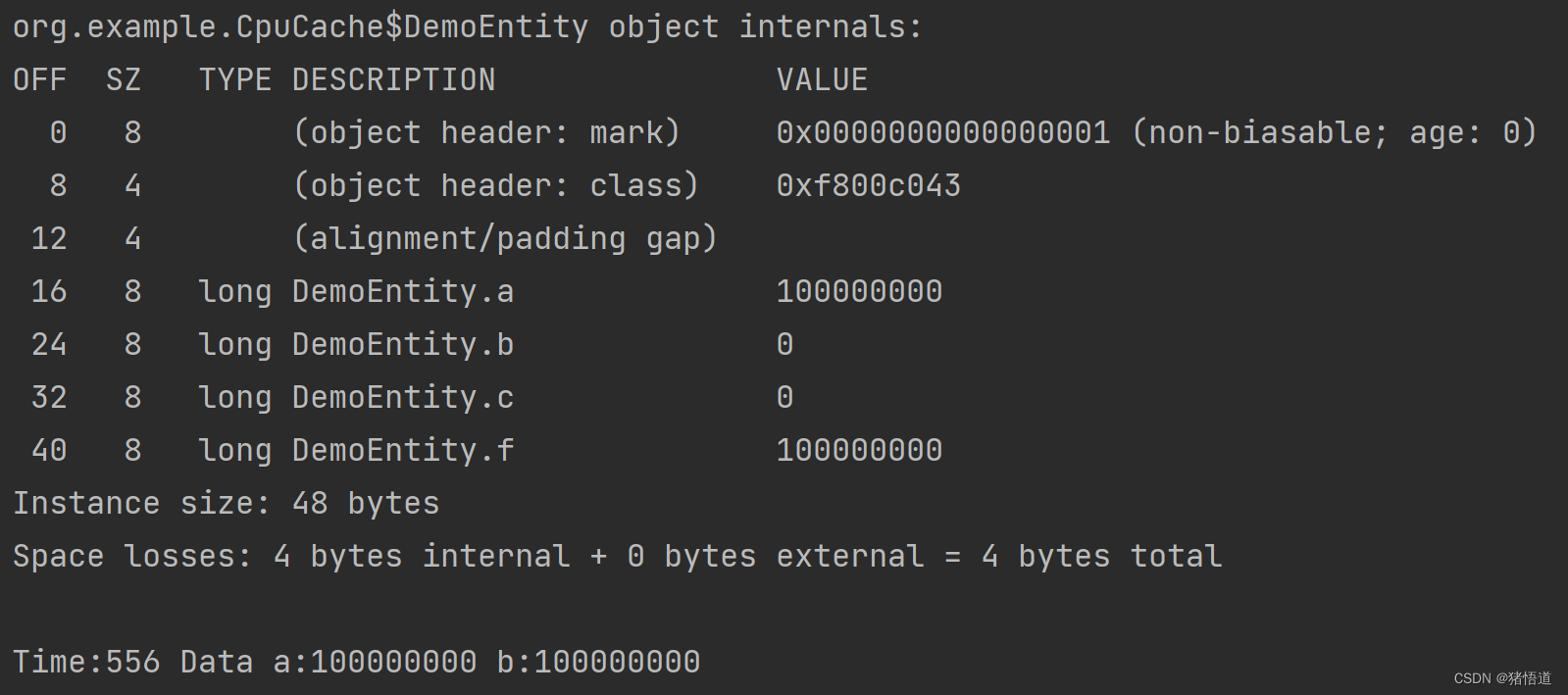
3.缓存行填充
原来一个 DemoEntity 对象 32 字节,我们在变量 a 和 f 之间填充两个 long 变量将 线程 2 的数据挤到下一个缓存行
耗时 556 毫秒