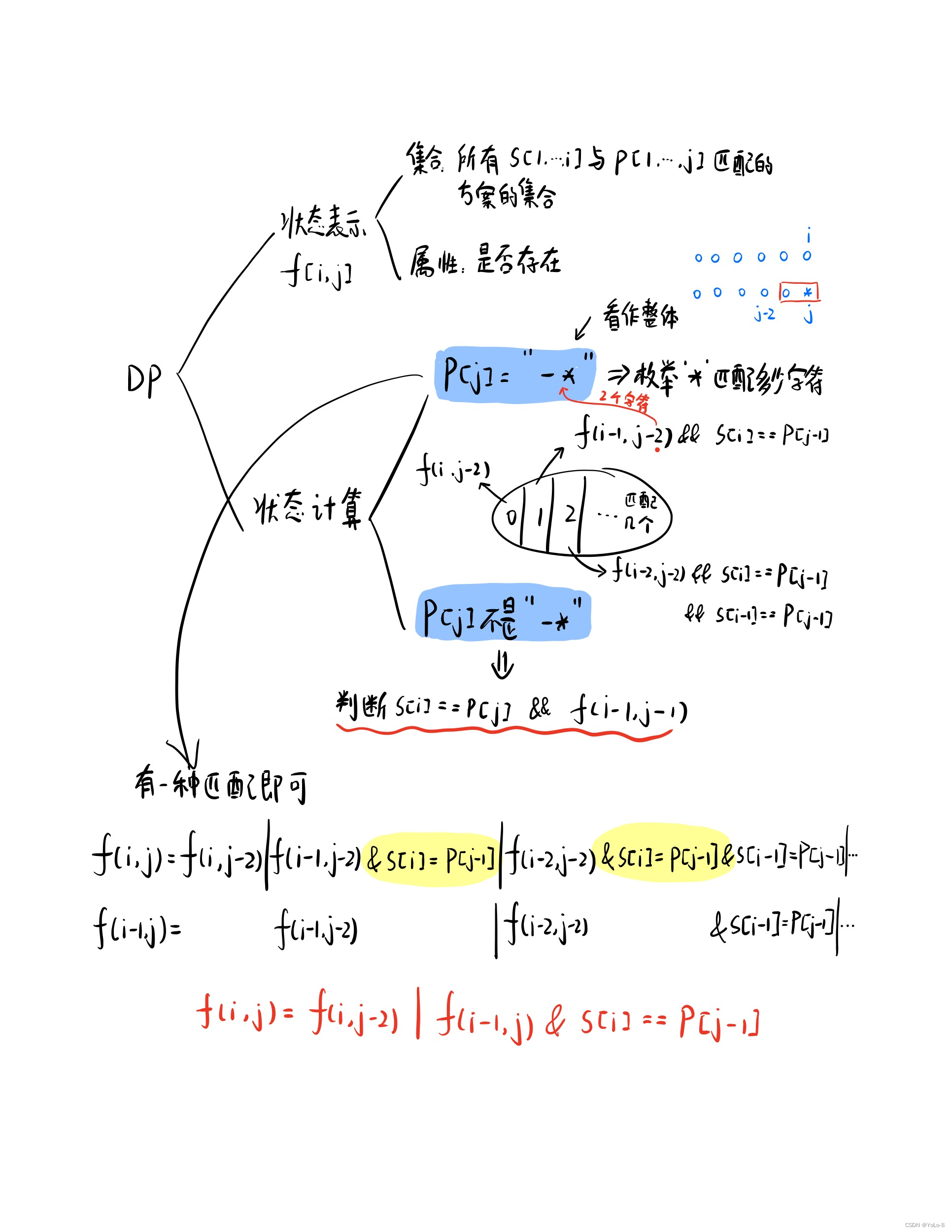
老规矩学习一个新技术首先从它的官网入手:Apache ZooKeeper
概览
一谈到集群,
从结构上看:
- 主从集群:主从集群就可以做读写分离,写在主、读在从
- 无主集群(比如redis cluster)
从数据上看:
- 复制集群:同步拷贝的集群,每个节点数据一样
- 分片集群:sharding分片集群
zk是复制集群、主从集群
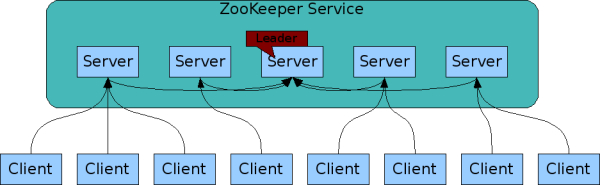
一般谈到集群谈到分布式,就会谈到角色,角色有:leader、follower、client
在讨论集群模式中,只要看到集群是主从结构的,立马就要条件反射一个事情,那就是主一定是单点的。而单点,就会有单点故障问题也就是说主可能会挂,主挂了就代表整个集群不可用了,因为不能执行写操作了
leader单点问题 -> leader可能会挂 -> 集群服务不可用 -> 不可靠的集群 -> 事实上,zk集群极其高可用
如何解决zk的主的单点故障问题?
如果有一种技术,可以快速的恢复出一个leader,可以通过选举,在主挂了以后在200ms以内的时间内,重新选择出一个新的主。而这200ms的期间,就是集群的无主状态(不可用状态)
也就是说,zk集群的运行有两种状态:
- 可用状态、
- 不可用状态
我们期待的是,从不可用状态恢复成可用状态越快越好
因为zk选择了比较简单的主从模型,主是单点了,单点会有单点故障问题,但是单点也有好处:就是它活着的时候,它一个人说了算,所以所有从 从节点转发过来的写请求,都会在主节点这里排队,它会给每一个写操作都排一个顺序的id号(这个顺序排队处理,有点像redis)
zk的数据结构是树的层级结构(分层命名空间),通过节点的概念来存储数据,但是每个节点的数据大小控制在1M,为什么要控制得这么小,这就与zk的设计理念有关,zk追求的就是对外提供协调服务时,能快速响应
zk集群的设计理念下,理想的读写比例是10比1,所以我们不要拿zk当数据库用,比如有的人拿zk存MQ的消费offset这会有大量的更新zk操作,是不合适的
安装、使用
因为zk就是一个java开发的项目,如果是java开发的项目,那么基本的模式就是
下载并解压安装包
按照安装包当前所在的位置,配置环境变量ZOOKEEPER_HOME,然后再环境变量path的最后追加ZOOKEEPER_HOME/bin
找到ZOOKEEPER_HOME/bin下的zk对应的启动脚本,执行该脚本就好,有时启动脚本后面还可能可以跟着不同的附加命令。当前zkServer.sh就是zk对应的启动脚本