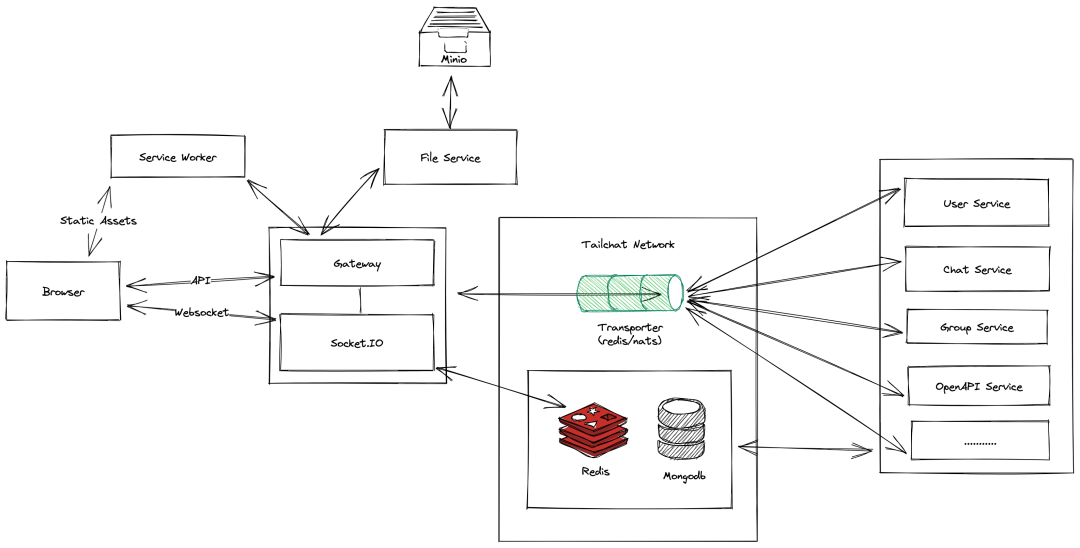
大数据技术栈现状
大数据技术整体设计图
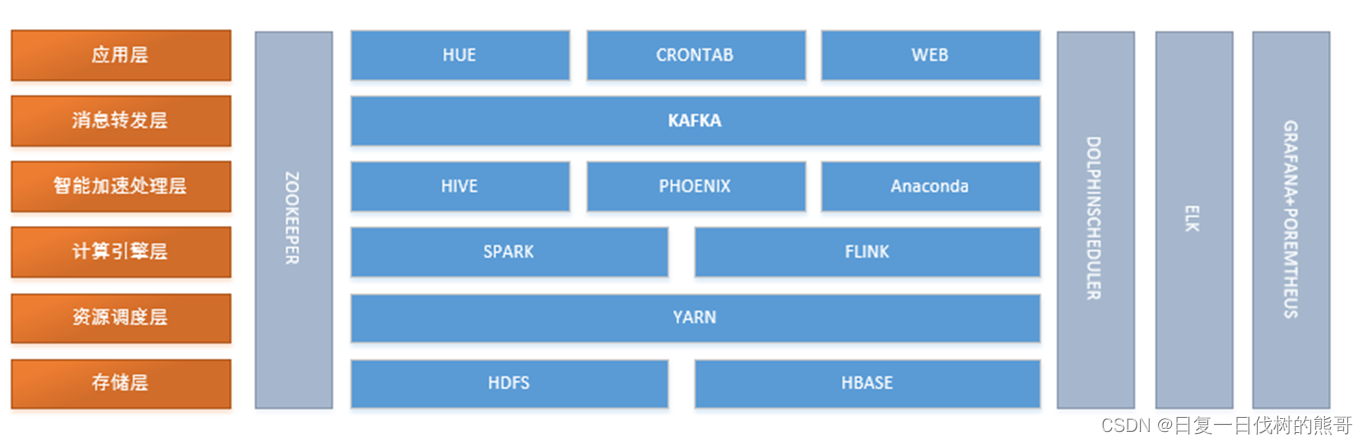
当前大数据各组件版本
ZooKeeper 3.4.5
Spark 2.4.0
Hue 4.3.0
Hive 2.1.1
Hbase 2.1.4
Hadoop 3.0.0
Kafka 2.2.1
Phoenix 5.0.0-cdh6.2.0
Dolphinscheduler 3.0.0
Yarn 3.0.0-cdh6.3.2
Logstash 7.7.0
Kibana 7.7.0
Elasticsearch 7.7.0
Grafana 8.0.0
Anaconda 3
Flink 1.13.2
现状的难题与挑战
- 海量数据的近实时条件查询效率问题。如:HBASE中的信号经纬度条件查询。
- 统计分析业务开发和维护复杂度高的问题。如:在线计算模块的统计。
- 缺乏专业大数据运维人员。
- 免费版的CDH支持的组件版本相对落后,无法更友好的支持其他非CDH的大数据生态技术,导致部分技术不兼容。如:FLINK的Hive Catalog不兼容,无法更加友好地处理小文件问题。
- 申请资源比较困难,现有资源较难以支撑越来越丰富的业务诉求。
- 无法支持近实时的统计分析业务场景。
- 无法支持即席查询的条件查询业务场景。
- 现有技术栈较复杂,开发人员学习成本高,维护成本也高。如:同时存在hive、spark、flink技术栈。