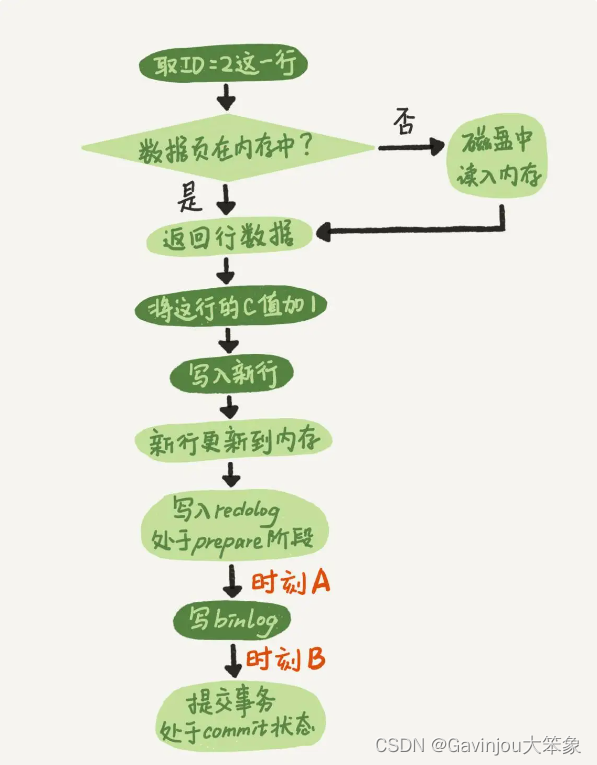
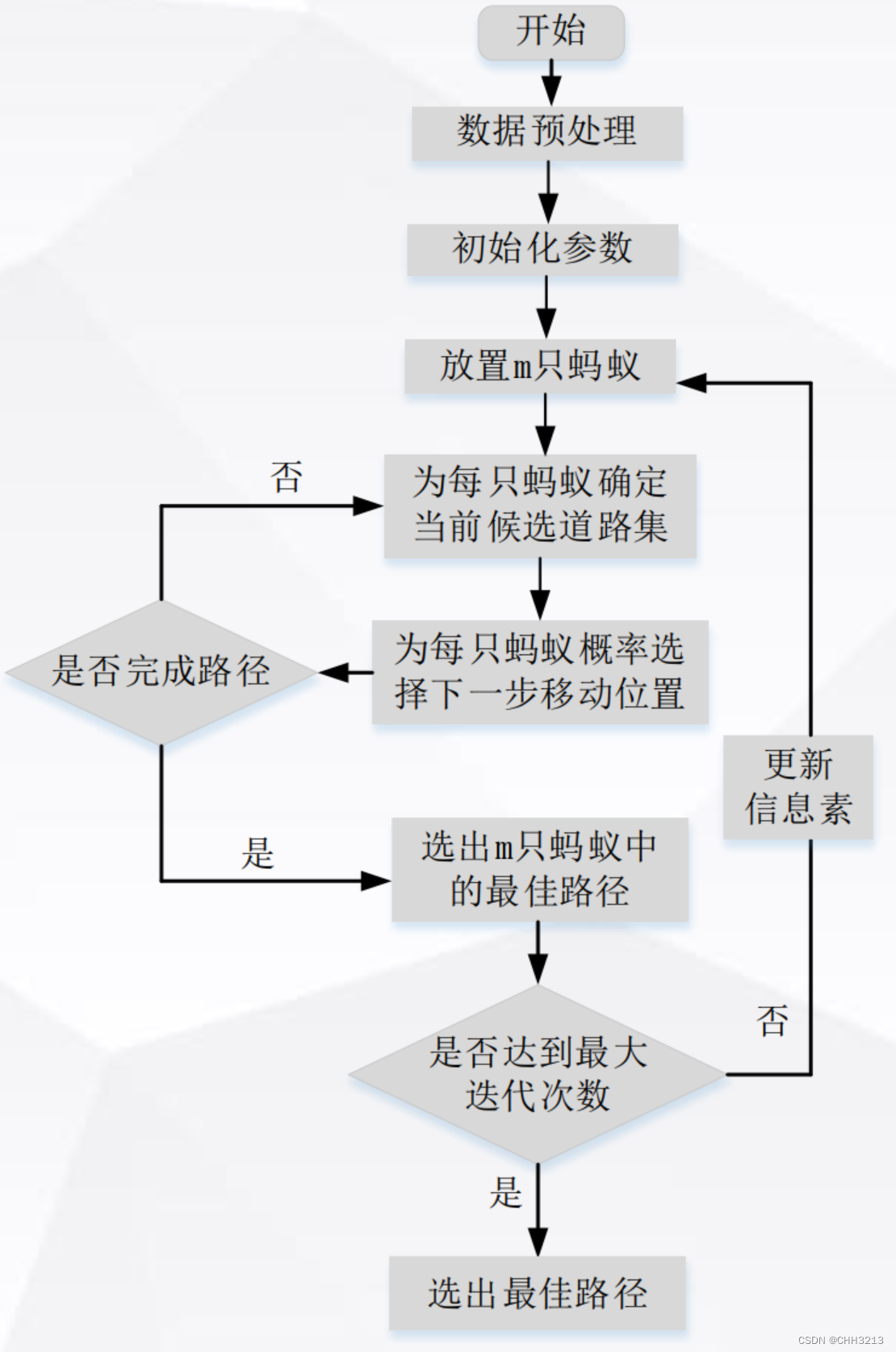
在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象? 如果 crash 发生在时刻 A
由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚 如果 crash 发生在时刻 B【主要】
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整
MySQL 怎么知道 binlog 是完整的? statement 格式的 binlog,最后会有 COMMIT row 格式的 binlog,最后会有一个 XID even MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性 redo log 和 binlog 是怎么关联起来的? 有一个共同的数据字段 XID,崩溃恢复的时候,会按顺序扫描 redo log
既有 prepare、又有 commit 的 redo log,就直接提交 只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务 处于 prepare 阶段的 redo log 加上完整 binlog,重启就能恢复,MySQL 为什么要这么设计? 数据与备份的一致性有关。采用这个策略,主库和备库的数据就保证了一致性 能不能只用 redo log,不要 binlog? 理论上可以,把 binlog 关掉,这样就没有两阶段提交了,但系统依然是 crash-safe 的 但 binlog 作用是归档,而 redo log 是循环写,起不到归档作用 redo log 一般设置多大? 对于几个 TB 的磁盘,设置为 4 个文件、每个文件 1GB 正常运行中的实例,数据写入后的最终落盘,是从 redo log 更新过来的还是从 buffer pool 更新过来的呢? 如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与 redo log 毫无关系 在 crash 场景下,InnoDB 如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让 redo log 更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态 redo log buffer 是什么?是先修改内存,还是先写 redo log 文件? begin ;
insert into t1 . . .
insert into t2 . . .
commit ;
在执行第一个 insert 的时候,数据的内存被修改了,redo log buffer 也写入了日志 真正把日志写到 redo log 文件(文件名是 ib_logfile+ 数字),是在执行 commit 语句的时候做的 业务需求如下 A、B 两个用户,如果互相关注,则成为好友。
设计上是有两张表,一个是 like 表,一个是 friend 表,like 表有 user_id、liker_id 两个字段
我设置为复合唯一索引即 uk_user_id_liker_id
以 A 关注 B 为例:
第一步,先查询对方有没有关注自己(B 有没有关注 A)
select * from like where user_id = B and liker_id = A;
如果有,则成为好友
insert into friend;
没有,则只是单向关注关系
insert into like;
但是如果 A、B 同时关注对方,会出现不会成为好友的情况。
因为上面第 1 步,双方都没关注对方。
第 1 步即使使用了排他锁也不行,因为记录不存在,行锁无法生效。
请问这种情况,在 MySQL 锁层面有没有办法处理?
sql 模板设计大概这样 CREATE TABLE ` like` (
` id` int ( 11 ) NOT NULL AUTO_INCREMENT ,
` user_id` int ( 11 ) NOT NULL ,
` liker_id` int ( 11 ) NOT NULL ,
PRIMARY KEY ( ` id` ) ,
UNIQUE KEY ` uk_user_id_liker_id` ( ` user_id` , ` liker_id` )
) ENGINE = InnoDB ;
CREATE TABLE ` friend` (
` id` int ( 11 ) NOT NULL AUTO_INCREMENT ,
` friend_1_id` int ( 11 ) NOT NULL ,
` friend_2_id` int ( 11 ) NOT NULL ,
UNIQUE KEY ` uk_friend` ( ` friend_1_id` , ` friend_2_id` ) ,
PRIMARY KEY ( ` id` )
) ENGINE = InnoDB ;
出现业务 bug 的时序 第 1 步即使使用了排他锁也不行,因为记录不存在,行锁无法生效 解决方案 给 “like” 表增加一个字段,比如叫作 relation_ship,并设为整型,取值 1、2、3
1:表示 user_id 关注 liker_id 2:表示 liker_id 关注 user_id 3:表示互相关注 在应用代码里面比较 A 和 B 的大小
mysql> begin ;
insert into ` like` ( user_id, liker_id, relation_ship) values ( A, B, 1 )
on duplicate key update relation_ship= relation_ship | 1 ;
select relation_ship from ` like` where user_id= A and liker_id= B;
insert ignore into friend( friend_1_id, friend_2_id) values ( A, B) ;
commit ;
mysql> begin ;
insert into ` like` ( user_id, liker_id, relation_ship) values ( B, A, 2 )
on duplicate key update relation_ship= relation_ship | 2 ;
select relation_ship from ` like` where user_id= B and liker_id= A;
insert ignore into friend( friend_1_id, friend_2_id) values ( B, A) ;
commit ;
“like” 表里的数据保证 user_id < liker_id,这样不论是 A 关注 B,还是 B 关注 A,在操作 “like” 表的时候,如果反向的关系已经存在,就会出现行锁冲突 insert … on duplicate 语句(这个语句只有 mysql 里有),确保了在事务内部,执行了这个 SQL 语句后,就强行占住了这个行锁,之后的 select 判断 relation_ship 这个逻辑时就确保了是在行锁保护下的读操作 操作符 “|” 是按位或,连同最后一句 insert 语句里的 ignore,是为了保证重复调用时的幂等性 即使在双方 “同时” 执行关注操作,最终数据库里的结果,也是 like 表里面有一条关于 A 和 B 的记录,而且 relation_ship 的值是 3, 并且 friend 表里面也有了 A 和 B 的这条记录