本文是在一个全新的Ubuntu 22.04 虚拟机上安装Hadoop 3.3.4。
环境
- Ubuntu 22.04
- JDK 11
- Hadoop 3.3.4
安装Hadoop
首先安装JDK:
# apt install openjdk-11-jdk-headless
安装好以后查看:
# java -version
openjdk version "11.0.17" 2022-10-18
OpenJDK Runtime Environment (build 11.0.17+8-post-Ubuntu-1ubuntu222.04)
OpenJDK 64-Bit Server VM (build 11.0.17+8-post-Ubuntu-1ubuntu222.04, mixed mode, sharing)
注意:Hadoop 3.3.4貌似不支持JDK 17,会报一个类似 java.lang.IllegalStateException: Unable to load cache item 的错误,换成JDK 11就好了。参见 https://blog.csdn.net/duke_ding2/article/details/123932532 。
然后要求在localhost上ssh免密登录,效果如下:
# ssh localhost
Ubuntu 22.04.1 LTS
Last login: Wed Nov 30 18:29:00 2022 from 9.200.47.148
如果需要配置ssh免密登录,只需在客户端机器生成一对public/private key,把public key复制到服务器端机器(本例就是本机)的 ~/.ssh/authorized_keys 里面即可,具体做法不再赘述,可以网上搜一下。
访问 https://hadoop.apache.org/ ,下载Hadoop的压缩文件。我下载的文件是 hadoop-3.3.4.tar.gz 。
# wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压缩:
# tar -zxvf hadoop-3.3.4.tar.gz
编辑 etc/hadoop/hadoop-env.sh 文件,添加:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
注:我是用 which java 和 ll 命令来查看java所在目录的。
验证Hadoop
有3种模式:
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
Local (Standalone) Mode
Hadoop的默认配置就支持非分布式模式。所以现在就可以试一下。比如,复制一些文件到 input 目录,然后统计里面的一些特定文本信息。
# mkdir input
# cp etc/hadoop/*.xml input
# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
# cat output/*
1 dfsadmin
查看 output 目录:
# ll output/
total 16
drwxr-xr-x 2 root root 88 Nov 30 18:39 ./
drwxr-xr-x 13 1024 1024 4096 Nov 30 18:42 ../
-rw-r--r-- 1 root root 8 Nov 30 18:39 ._SUCCESS.crc
-rw-r--r-- 1 root root 12 Nov 30 18:39 .part-r-00000.crc
-rw-r--r-- 1 root root 0 Nov 30 18:39 _SUCCESS
-rw-r--r-- 1 root root 11 Nov 30 18:39 part-r-00000
# cat output/part-r-00000
1 dfsadmin
Pseudo-Distributed Mode
修改 etc/hadoop/core-site.xml 文件,添加如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改 etc/hadoop/hdfs-site.xml 文件,添加如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注意确认一下 ssh localhost 可以免密登录。
格式化HDFS:
# bin/hdfs namenode -format
启动HDFS,报错如下:
# sbin/start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [schlepps1.fyre.ibm.com]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
在网上搜了一下,解决方法是,在 etc/hadoop/hadoop-env.sh 里添加以下几行内容:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
参考: https://stackoverflow.com/questions/48129029/hdfs-namenode-user-hdfs-datanode-user-hdfs-secondarynamenode-user-not-defined
现在,就可以用 sbin/start-dfs.sh 命令启动HDFS了。
同理,也可以用 sbin/stop-dfs.sh 命令停止HDFS。
启动HDFS后,可以通过浏览器访问 http://<IP>:9870/ :
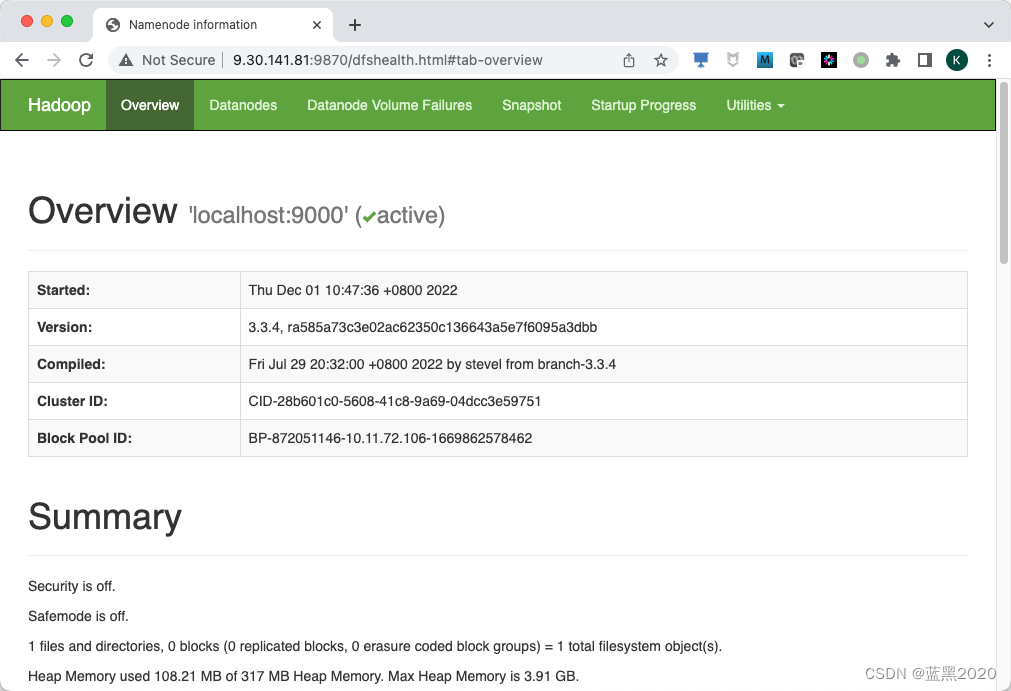
在HDFS里初始化root的根目录:
# bin/hdfs dfs -mkdir /user
# bin/hdfs dfs -mkdir /user/root
此时,目录是空的:
# bin/hdfs dfs -ls
我们来创建一个 input 目录:
# bin/hdfs dfs -mkdir input
再来查看一下:
# bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - root supergroup 0 2022-11-30 19:51 input
接下来,复制一些文件到HDFS。例如, input2 是一个本地目录,里面有 aaa.txt 和 bbb.txt 两个文本文件。把这两个文件复制到HDFS:
# bin/hdfs dfs -put /root/Downloads/hadoop-3.3.4/input2/* input
查看文件内容:
# bin/hdfs dfs -cat input/aaa.txt
abcdef
hi
haha
hello
world
hhii
# bin/hdfs dfs -cat input/bbb.txt
hhh
hihihi
aaabbb
cccddd
high
12345
统计 hi 出现的次数:
# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'hi'
运行完之后,会自动生成 output 目录。把 output 目录复制出来:
# bin/hdfs dfs -get output output
注:我先把已存在的本地 output 目录删掉了。
# ll output
total 8
drwxr-xr-x 2 root root 42 Nov 30 19:55 ./
drwxr-xr-x 14 1024 1024 4096 Nov 30 19:55 ../
-rw-r--r-- 1 root root 5 Nov 30 19:55 part-r-00000
-rw-r--r-- 1 root root 0 Nov 30 19:55 _SUCCESS
# cat output/part-r-00000
6 hi
Fully-Distributed Mode
略
参考
https://hadoop.apache.orghttps://yanglinwei.blog.csdn.net/article/details/125170230https://stackoverflow.com/questions/48129029/hdfs-namenode-user-hdfs-datanode-user-hdfs-secondarynamenode-user-not-defined





![[附源码]Python计算机毕业设计Django二次元信息分享平台的设计及实现](https://img-blog.csdnimg.cn/ceff51a9d2b549e690789410cb254629.png)



![Unity笔记(15):OnTriggerEnter2D [2D]](https://img-blog.csdnimg.cn/47b8de13359f470d8a67dcb651cea895.png)