一、概述
近在阅读近五年的一区高分的机器学习文献,其中有一种图出现频率特别高——热图。《Machine Learning and the Future of Cardiovascular Care: JACC State-of-the-Art Review》 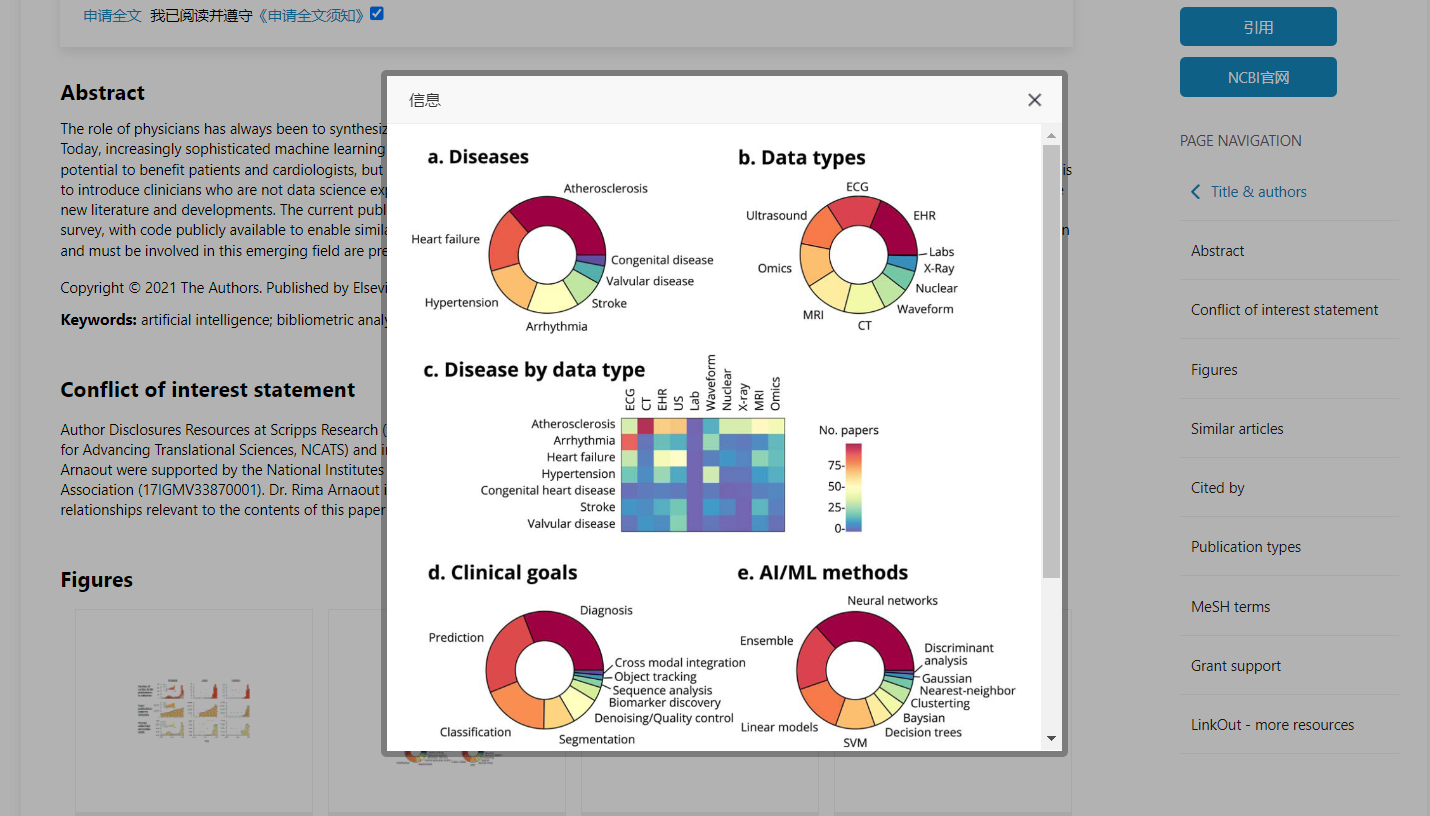 《Comparison of Machine Learning Methods for Predicting Outcomes After In-Hospital Cardiac Arrest》
《Comparison of Machine Learning Methods for Predicting Outcomes After In-Hospital Cardiac Arrest》 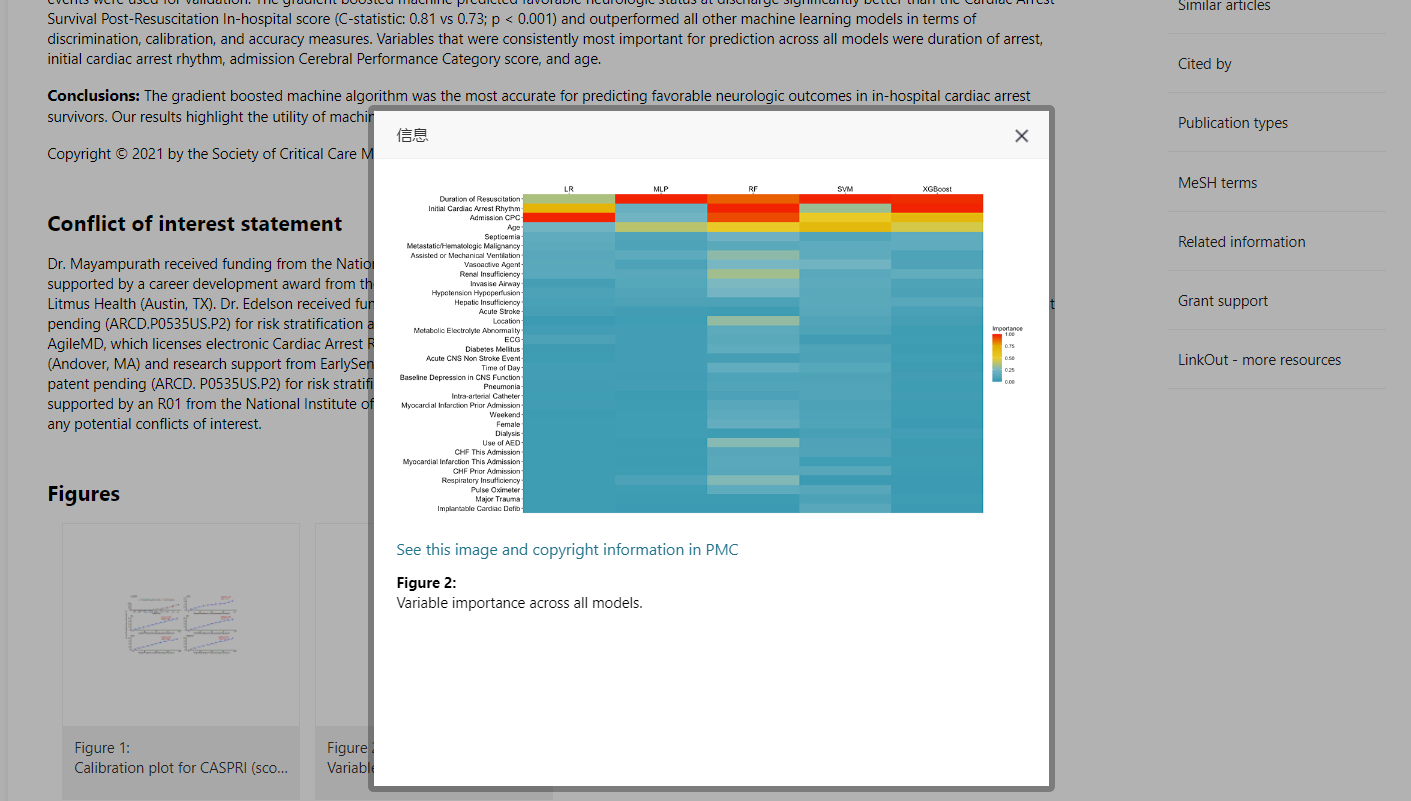
1. 什么是热图(Heatmap)?
热图(Heatmap)是一种常见的数据可视化技术,通常用于展示高维数据的结构、相互关系,以及在不同条件或时间点下的变化等信息。热图的主要特点是使用颜色来表示数据的大小或相对大小,能够有效地展示大量的数据,并帮助用户快速发现数据中的规律和趋势。
热图(Heatmap)通常由两个坐标轴组成,一个表示样本或实验条件,另一个表示变量或特征。数据通常以矩阵的形式呈现,每个单元格的颜色代表该位置上的数据值。不同颜色通常代表不同的数值范围,例如红色可以表示高值,蓝色可以表示低值。
2. 热图的应用?
基因表达谱研究:热图可以用来展示基因在不同样本中的表达水平,从而帮助研究人员发现基因的表达模式和相关性。
生物信息学研究:热图可以用来展示基因组、转录组、蛋白质组等生物信息学数据的分布和关系,从而帮助研究人员分析数据并发现相关性。
市场分析:热图可以用来展示市场中不同产品或服务的销售情况,从而帮助企业分析市场需求和趋势。
社交网络分析:热图可以用来展示社交网络中不同用户之间的关系和交互情况,从而帮助研究人员分析社交网络的结构和特征。
环境监测:热图可以用来展示环境监测数据中不同地点或时间点的数据变化情况,从而帮助环境监测人员分析环境变化和趋势。
二、数据集
- 安装及其使用
install.packages('pheatmap')
library(pheatmap)- 读取数据
首先,我们需要读取sbpdata数据集,查看数据集信息
# 加载 R 自带数据集 mtcars
data(mtcars)
# 删除数据集的一列,并转换数据集的行列
mtcars_matrix <- t(as.matrix(mtcars[, -1]))数据集展示
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout Valiant Duster 360 Merc 240D Merc 230 Merc 280 Merc 280C Merc 450SE Merc 450SL Merc 450SLC Cadillac Fleetwood
cyl 6 6 4 6 8 6 8 4.0 4.0 6.0 6.0 8.0 8.0 8.0 8
disp 160 160 108 258 360 225 360 146.7 140.8 167.6 167.6 275.8 275.8 275.8 472
hp 110 110 93 110 175 105 245 62.0 95.0 123.0 123.0 180.0 180.0 180.0 205
Lincoln Continental Chrysler Imperial Fiat 128 Honda Civic Toyota Corolla Toyota Corona Dodge Challenger AMC Javelin Camaro Z28 Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa
cyl 8 8 4.0 4.0 4.0 4.0 8 8 8 8 4 4.0 4.0
disp 460 440 78.7 75.7 71.1 120.1 318 304 350 400 79 120.3 95.1
hp 215 230 66.0 52.0 65.0 97.0 150 150 245 175 66 91.0 113.0
Ford Pantera L Ferrari Dino Maserati Bora Volvo 142E
cyl 8 6 8 4
disp 351 145 301 121
hp 264 175 335 109
三、基础用法
用pheatmap函数绘制热图,标准化参数scale可选"none", "row", "column";分别是不做归一化处理,按行均一化,按列均一化
1. 不做归一化处理(none)
pheatmap(mtcars_matrix,scale='none')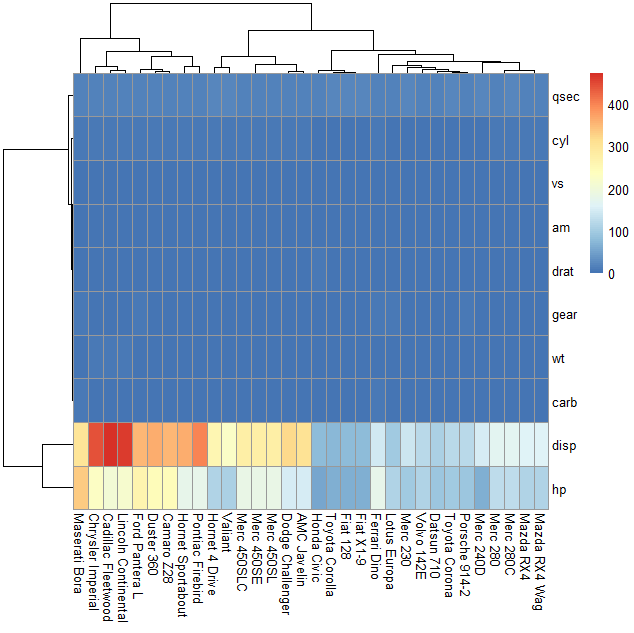
2. 均一化(row)
pheatmap(mtcars_matrix,scale='row')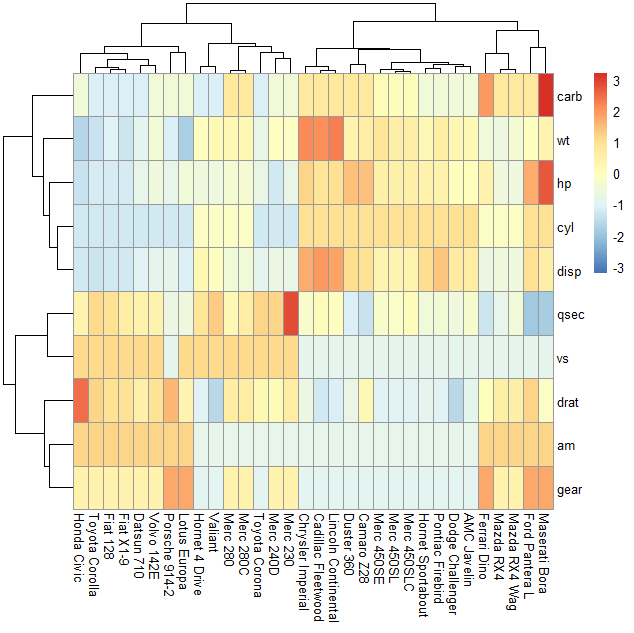
3. 按列均一化(column)
pheatmap(mtcars_matrix,scale='column')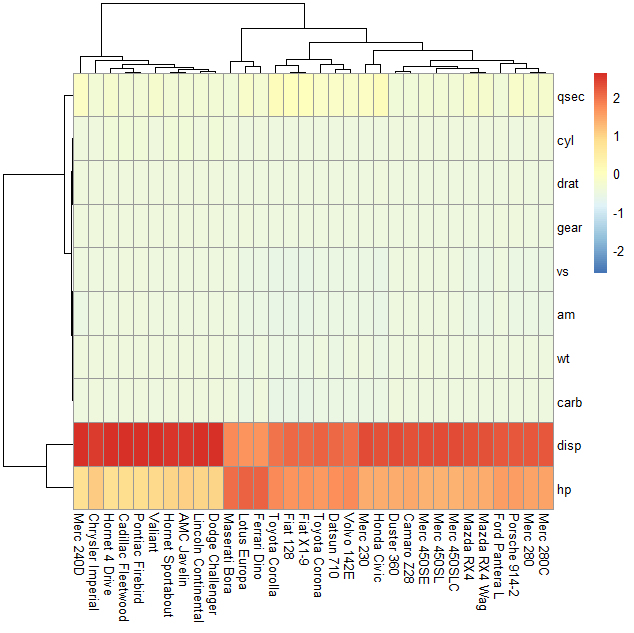
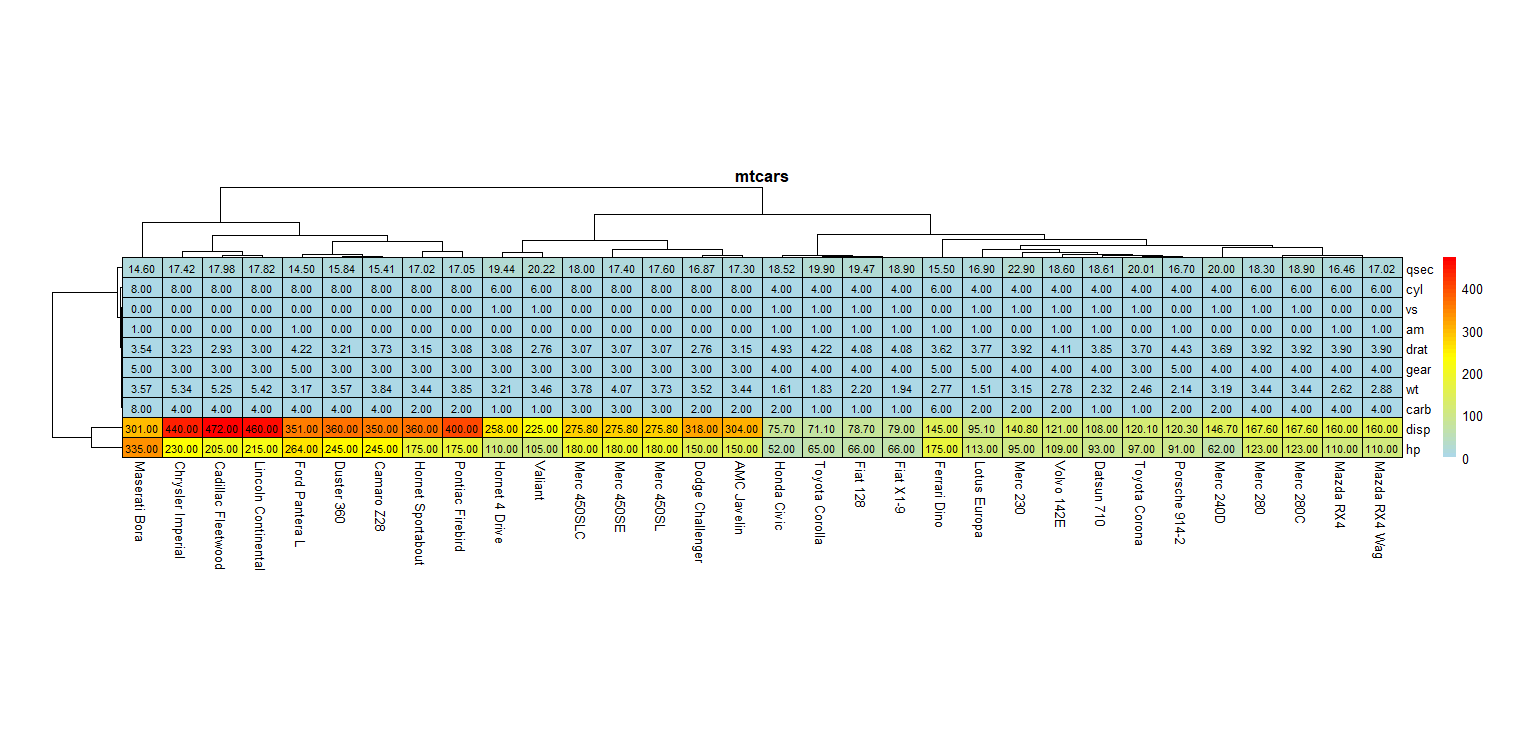
4. 一些个性化参数的设置
pheatmap(mtcars_matrix,scale = "none",
show_colnames = TRUE, # 显示列名
show_rownames=TRUE, # 显示行名
fontsize=10, # 字体大小
color = colorRampPalette(c('#ADD8E6','yellow','#ff0000'))(50), # 指定颜色,50代表生成了50种渐变色的向量
annotation_legend=TRUE, # 显示图例
border_color="black", # 每个方块边框颜色
cluster_rows = TRUE, # 对行聚类
cluster_cols = TRUE, # 对列聚类,行列聚类使用的度量方法clustering_distance_rows=“euclidean”,一般默认欧氏距离;也可选用其他度量方法,如可选用 "correlation"表示按照 Pearson correlation方法进行聚类
display_numbers=TRUE, # 在热图中每个单元格中显示具体数值
number_color="black", # 数值的颜色
cellwidth = 30,cellheight = 15, # 设置热图方块宽度和高度
main="mtcars" # 设置图形标题
)
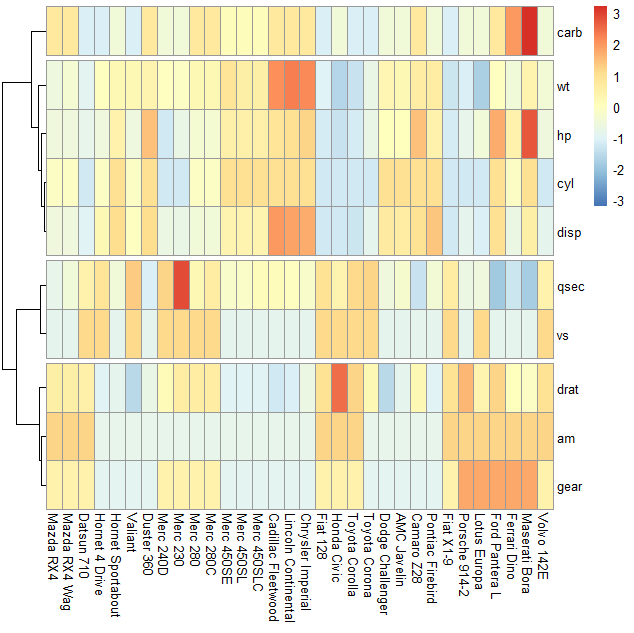
5. 聚类热图划分隔断
# 尝试进行聚类热图划分隔断,假设导入的数据未进行相关性系数计算,
pheatmap(mtcars_matrix,
scale = "row", # 按行归一化,查看因子在不同样本中的分布情况
cluster_cols = FALSE, clustering_distance_rows = "correlation", # 取消列聚类,表示行聚类使用皮尔森相关系数聚类
treeheight_row = 30, # 设置行聚类树高
cutree_rows =4 # 根据样品列聚类情况将热图的行方向隔开为4份
)
四、组合图进阶
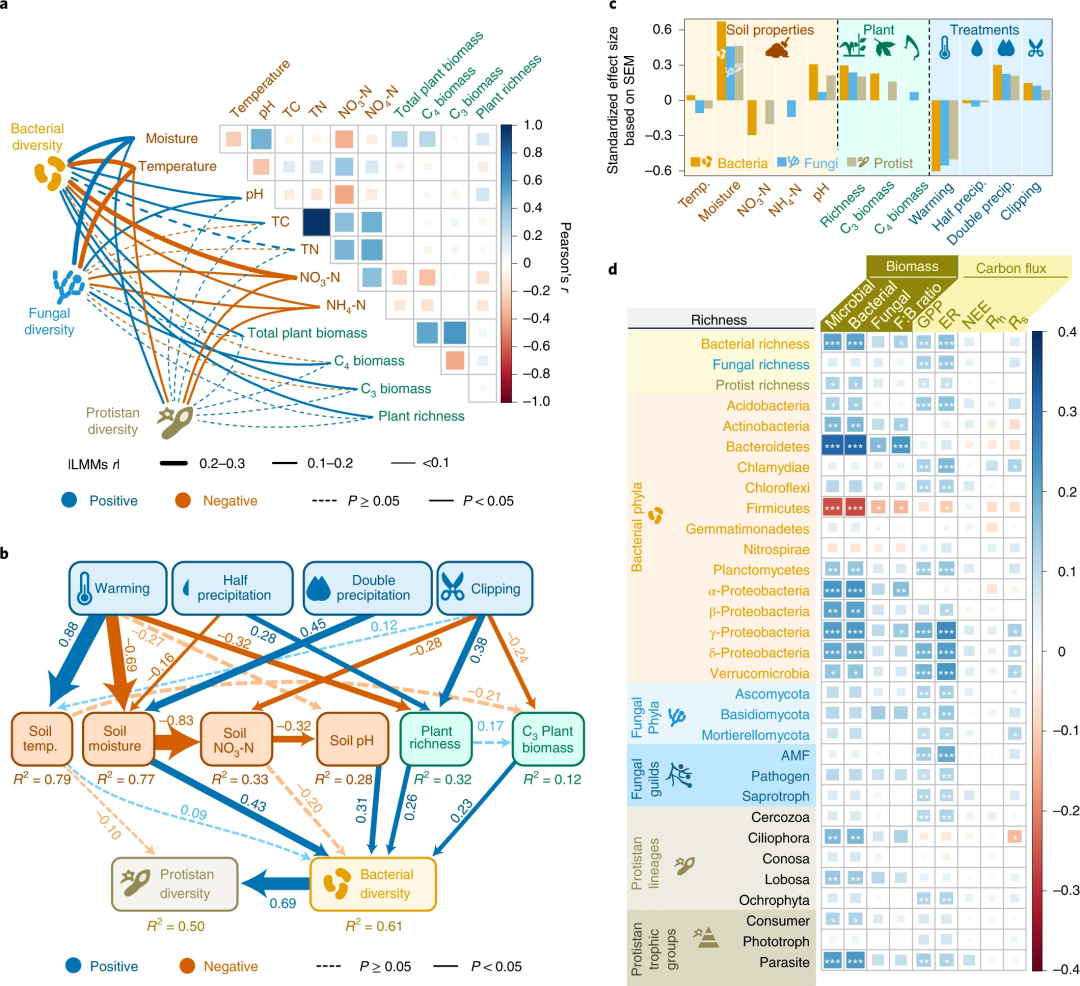
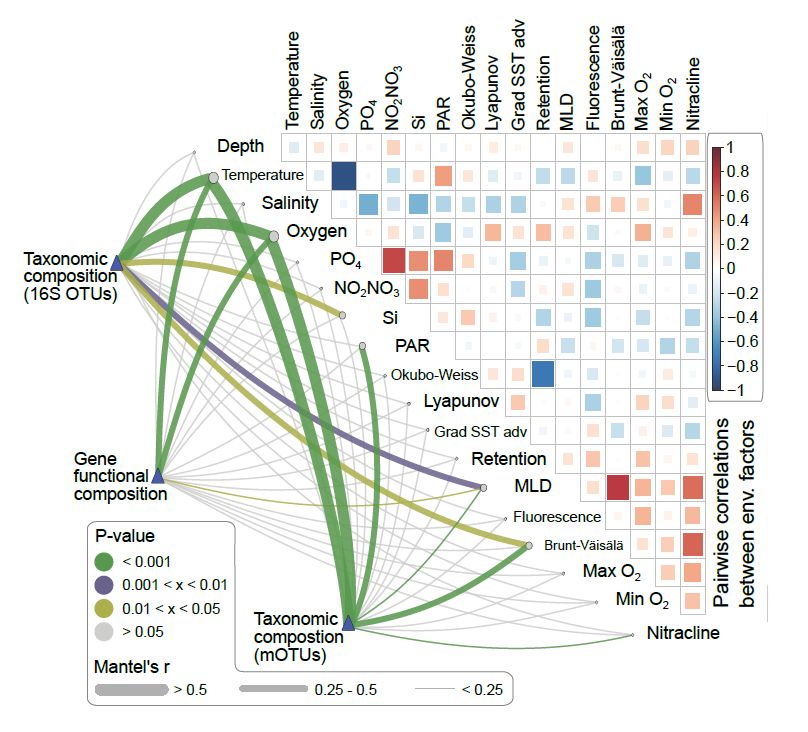 一篇Science文章的一个高颜值高难度组合图表(如上图)
一篇Science文章的一个高颜值高难度组合图表(如上图)
install.packages("devtools")
library(devtools)
devtools::install_github("shinepreventer/ggcor-hou")这个开发者把ggcor这个包关闭了,因此需要从备用仓库下载,而且下载会遇到一些错误,解决方法如下:
install.packages(c('ggnewscale', 'igraph', 'tidygraph'))
library(devtools)
devtools::install_github("Github-Yilei/ggcor")
# 执行结果,代表需要更新的R包
Which would you like to update?
1: All
2: CRAN packages only
3: None
4: rlang (1.0.6 -> 1.1.1) [CRAN]
5: purrr (0.3.5 -> 1.0.1) [CRAN]
6: cli (3.4.1 -> 3.6.1) [CRAN]
#下载一段时间后,会让你选择输入一个数字1-14,就是版本的问题,随便填写。
# 重启R,再执行
remove.packages("stringi")
install.packages("stringi", type="binary")
remove.packages("rlang")
install.packages("rlang", type="binary")
remove.packages("purrr")
install.packages("purrr", type="binary")
remove.packages("cli")
install.packages("cli", type="binary")
library(devtools)
devtools::install_github("Github-Yilei/ggcor",force=TRUE)
library(ggcor)1. 基本使用方法
install.packages('vegan')
library(vegan)
library(ggcor)
install.packages('dplyr')
library(dplyr)
quickcor(mtcars, cor.test = TRUE) +
geom_square(data = get_data(type = "lower", show.diag = FALSE)) +
geom_mark(data = get_data(type = "upper", show.diag = FALSE)) +
geom_abline(slope = -1, intercept = 12)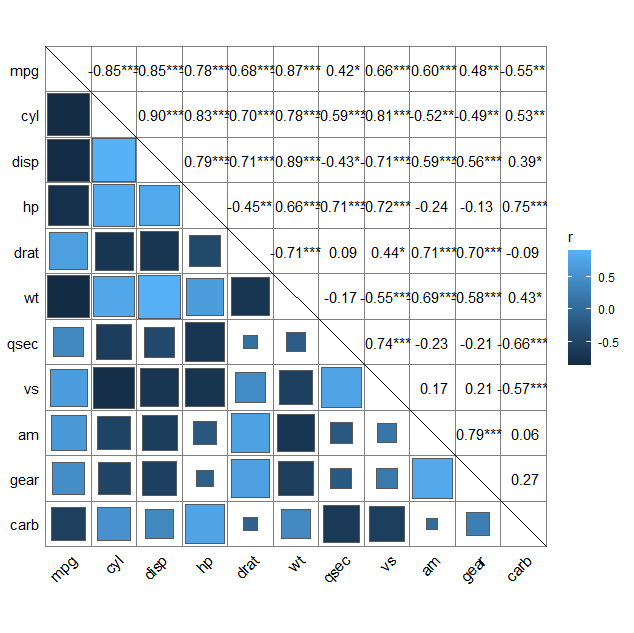
2. 进阶使用方法()
library(dplyr)
#> Warning: package 'dplyr' was built under R version 3.6.2
data("varechem", package = "vegan")
data("varespec", package = "vegan")
mantel <- mantel_test(varespec, varechem,
spec.select = list(Spec01 = 1:7,
Spec02 = 8:18,
Spec03 = 19:37,
Spec04 = 38:44)) %>%
mutate(rd = cut(r, breaks = c(-Inf, 0.2, 0.4, Inf),
labels = c("< 0.2", "0.2 - 0.4", ">= 0.4")),
pd = cut(p.value, breaks = c(-Inf, 0.01, 0.05, Inf),
labels = c("< 0.01", "0.01 - 0.05", ">= 0.05")))
quickcor(varechem, type = "upper") +
geom_square() +
anno_link(aes(colour = pd, size = rd), data = mantel) +
scale_size_manual(values = c(0.5, 1, 2)) +
scale_colour_manual(values = c("#D95F02", "#1B9E77", "#A2A2A288")) +
guides(size = guide_legend(title = "Mantel's r",
override.aes = list(colour = "grey35"),
order = 2),
colour = guide_legend(title = "Mantel's p",
override.aes = list(size = 3),
order = 1),
fill = guide_colorbar(title = "Pearson's r", order = 3))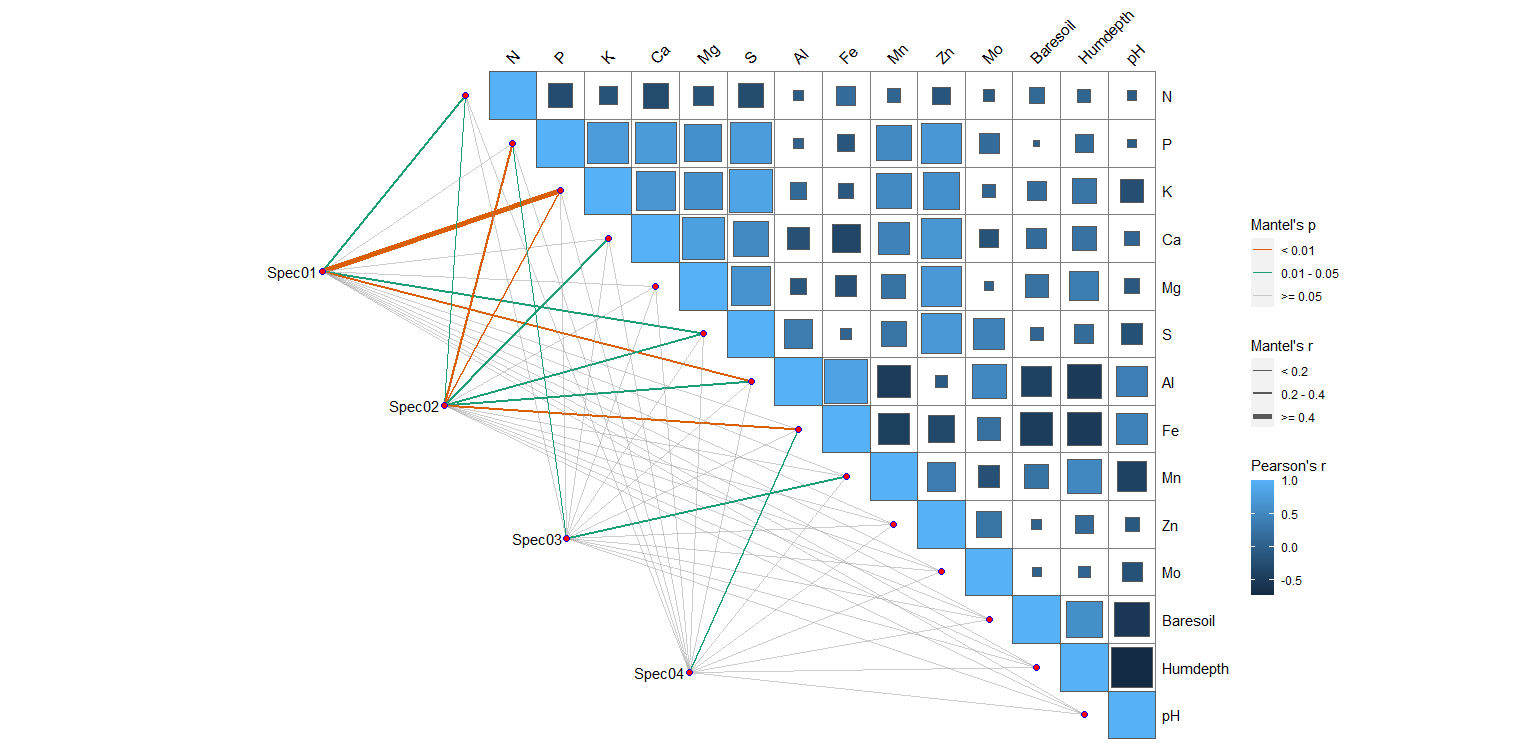
3. 高阶使用方法(原型热图)
install.packages('ambient')
library(ambient)
rand_correlate(100, 8) %>% ## require ambient packages
quickcor(circular = TRUE, cluster = TRUE, open = 45) +
geom_colour(colour = "white", size = 0.125) +
anno_row_tree() +
anno_col_tree() +
set_p_xaxis() +
set_p_yaxis()
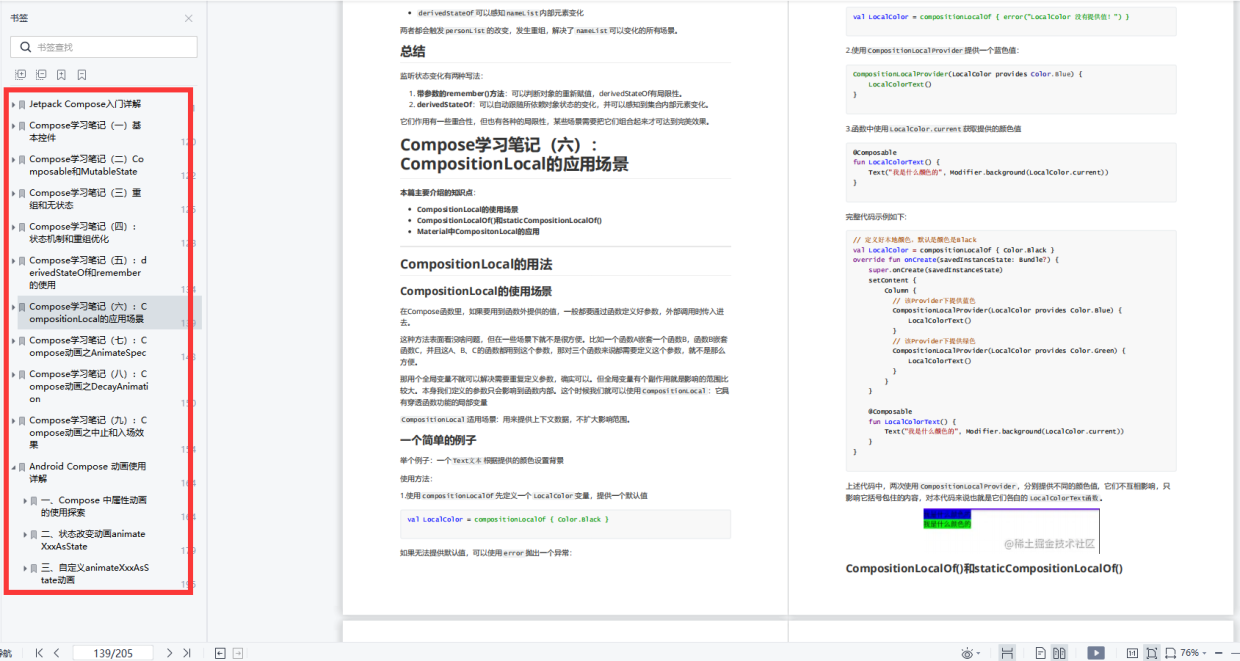
五、热图解析方法
观察颜色条:热图操作中最基本的部分就是颜色条,显示出了数据的分布情况和数据的值域。颜色条上颜色的变化从低到高,代表数据从小到大的变化。通过研究颜色条,可以快速了解数据的分布和值域,从而对热图中的数据分布产生直观感受。
识别异常值:通过比较颜色条的级别和图中对应单元格的颜色,可以识别矩阵中的异常值。某些红或蓝色(根据您使用的颜色映射)显然与其他大部分颜色不同,这些点就是潜在的异常值。识别这些异常值有助于进一步的探究和分析数据表。
查找模式:可以观察热图中的颜色模式来发现数据之间的关系。例如,一列中的许多蓝色通常表示值通常较小,而很少的红色可能表示较大的不寻常值。在热图中发现模式有助于理解数据之间的关系,进而引导进一步的数据分析和挖掘。
调整参数:热图通常是基于不同的参数得到的。您可以修改颜色条和颜色映射,或者选择在不同的颜色组中选择合适的颜色。这些调整允许您更好地理解数据并突出矩阵中重要的部分。
✔