1.对筛选的多肽成分进行靶点预测:
①用Uniport中的蛋白进行一系列操作(水解,挑选2~8短肽,活性预测,毒性,过敏性预测,胃肠吸收度,半衰期和苦味的预测、生物活性功能预测)进行多肽的筛选。
②或者在EXCEL筛查短肽(=IF(LEN(A1)<=7,"T","F"),可惜最短都是7肽。
③用氨基酸单字符序列(AGW)在 Swissadme 里找到多肽对应的smiles结构(例如下图)
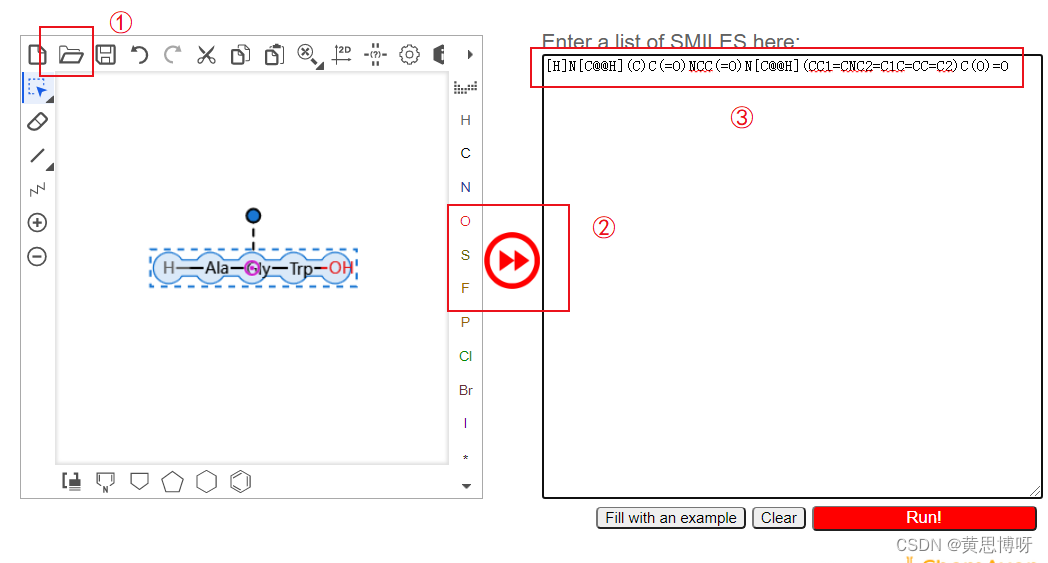
在框①里输入短肽单字符序列,框③就是得到的Smiles编号
解决在swissADME里得不到swiss号:
可以到 纽普生物 里去查找。
④用smiles编号在pubchem里查找,得到对应的Canonical Smiles(如下图)

④打开 SwissTargetPrediction ,进行成分靶点预测(操作如下图)
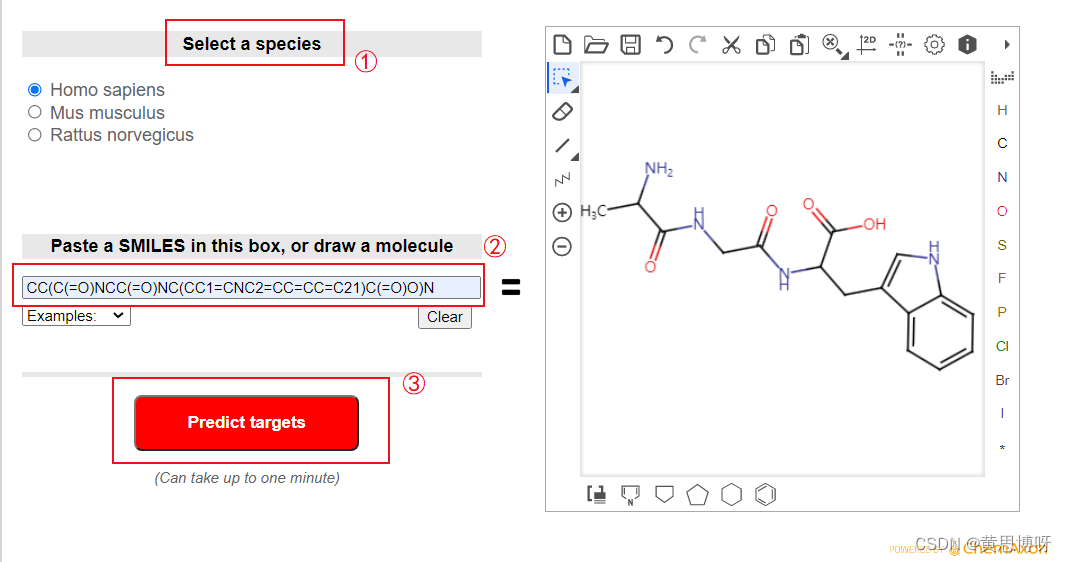
种类只能选择人类和小鼠(框①),在框②里输入Swiss编号,点击Predict target按钮(框③)
等待进条度加载完毕,保存预测的靶点到本地。
2.下载靶点,对靶点进行进一步筛选处理:
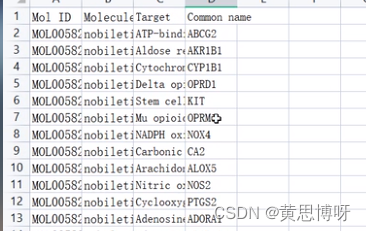
有多个成分,就能预测到多个靶点文件,将这些文件的【Target】和【Common name】汇总到一个新建表格,新增一列是这些靶点的药物成分。
Probability值越高,成分和靶点的关联就越强(会有为0的情况,要去掉)
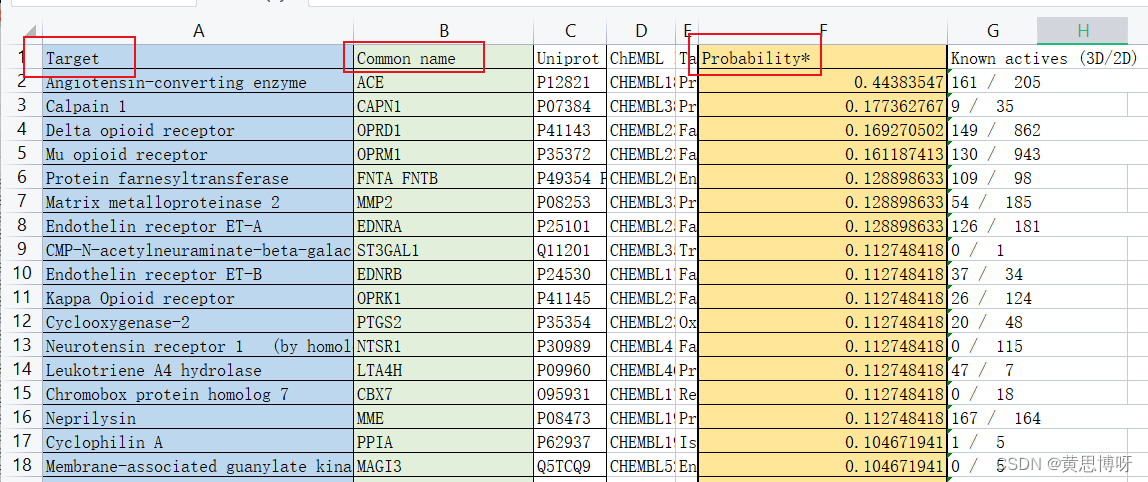
一般,我们保留Probability值>0的靶点
在视频教程里(下图),会在前两列添加Mol_ID和分子名(嗯,可做可不做)
另外,在【Common name】会出现下面这类情况:一个靶点对应两个Commom name
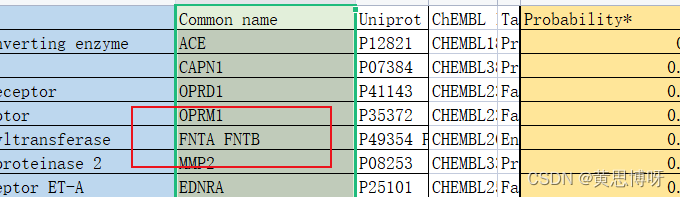
一个靶点有两个common name,我们需要只保留第一个(操作如图):
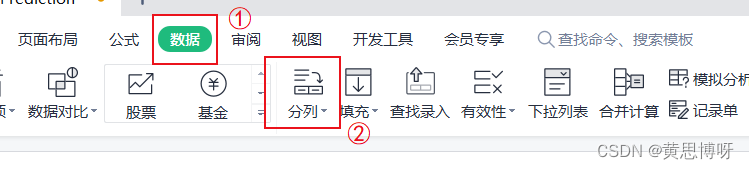
在Excel里,选择【数据】-->【分列】,按空格进行分列,将分列出的新列删除。
绘制成分—靶点网络(详见笔记:成分-靶点网络构建 )




![String类 [下]](https://img-blog.csdnimg.cn/0e589f1adfe3467d8fbf25b9bded99dc.png)