计算机操作数据时,一般是在内存中对数据进行处理,但是计算机的内存空间有限,服务器操作大量数据时,容易造成内存不足,且一旦计算机关机,则内存数据就丢失。所以我们需要将数据进行存储。
持久化(Persistence)即把数据保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中。当然也可以存储在磁盘文件中、XML数据文件中等。
我们学习过mysql、oracle的时候,通过sql命令去操作数据库进行数据的增删改查。对于开发人员来说,可以通过调用第三方库函数或方法,通过发送命令给数据库引擎,从而达到数据库的增删改查操作,比如pymysql库就是专门用来对mysql数据库进行操作的第三方库,pymysql的操作可以看这篇博客:pymysql的使用。
其实开发人员在进行数据库操作时,还有一个概念:ORM。
ORM:Object Relational Mapping,对象关系映射。作用是在关系型数据库和对象之间做一个映射,这样在具体操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像操作对象一样操作就可以了。简单理解就是:数据库中的每一行数据都是一个对象。
SQLAlchemy是python中最有名的ORM框架;在Flask中一般使用Flask-SQLAlchemy来操作数据库。
SQLAIchemy
Flask-SQLAlchemy的安装命令:pip install flask-sqlalchemy
官方文档:https://flask-sqlalchemy.palletsprojects.com/en/3.0.x/
首先我们先看看官方给的一个快速入门的例子:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 创建SQLAlchemy对象
db = SQLAlchemy()
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库URI信息
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///project.db"
# 初始化Flask对象中的数据库信息,即Flask对象与QLAlchemy()进行绑定
db.init_app(app)
从示例中我们可以看到在Flask中使用flask_sqlalchemy分为以下几步:
- 步骤1:创建SQLAlchemy对象
- 步骤2:创建Flask对象
- 步骤3:在Flask对象中,配置数据库URI信息
- 步骤4:初始化Flask对象中的数据库信息
- 步骤5:使用SQLAlchemy对象对数据库进行操作
步骤3中的数据库信息配置是非常重要的,其相当于包含了数据库连接、关闭等操作,我们需要配置数据库连接信息等内容,常用配置清单如下:
| 配置键 | 说明 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接数据库 |
| SQLALCHEMY_BINDS | 用于多数据库连接的配置 |
| SQLALCHEMY_TRACK_MODIFICATIONS | 追踪对象的修改 |
部分配置如SQLALCHEMY_ENGINE_OPTIONS、SQLALCHEMY_ECHO、SQLALCHEMY_RECORD_QUERIES、SQLALCHEMY_COMMIT_ON_TEARDOWN很少用到(没试过,后面有空再试),就不写了。
其他配置如SQLALCHEMY_NATIVE_UNICODE、SQLALCHEMY_POOL_SIZE、SQLALCHEMY_POOL_TIMEOUT、SQLALCHEMY_POOL_RECYCLE、SQLALCHEMY_MAX_OVERFLOW等配置键,在flask_sqlalchemy的3.0版本被移除了,这里就不过多介绍了。
SQLALCHEMY_DATABASE_URI的配置说明:
格式:dialect+driver://username:password@host:port/database
- dialect:表示数据库类型,比如sqlite、mysql
- driver:表示数据库引擎、驱动,比如python脚本库pymysql
- username:连接数据库的用户名
- password:连接数据库的密码
- host:数据库所在IP地址
- port:数据库监听端口
- database:数据库名称
示例:
- 连接sqlite:sqlite:///数据库db文件所在的路径
- 连接mysql:mysql+pymysql://root:123456@127.0.0.1:3306/库名
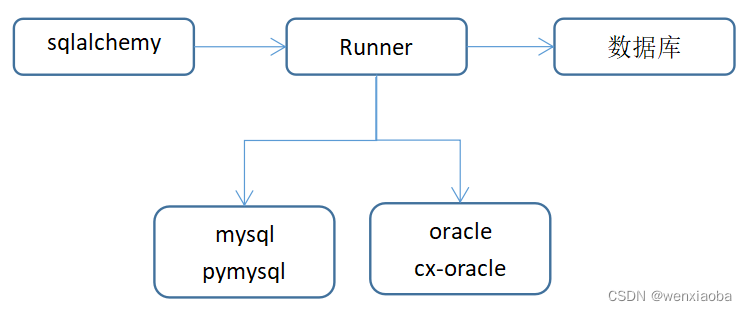
原理:sqlalchemy其实也是通过某个驱动去修改数据库,该驱动就是dialect和driver配置的,如图:
表操作
| 方法 | 说明 |
|---|---|
| create_all() | 根据继承的Model的类创建表,如果表名已经存在,则不创建也不更改 |
| drop_all() | 根据继承的Model的类删除对应表 |
关于类与表的映射:
- 类名相当于表名
- 如果想自定义表名,在类中定义属性:
__tablename__ = 自定义的表名 - python一般是驼峰命名的类名,表名是根据类名转为下划线连接,如class UserInfo建立的表名是user_info
- 如果想自定义表名,在类中定义属性:
- 在类型,通过
属性名 = db.Column()方法来映射成表中的字段- 若Column()中第一个参数默认是字段名称,字符串类型,若非字符串类型,则字段名称默认为属性名
- 字段类型常用的有:String、Integer、Float、Double、Boolean、DateTime、Text等等,可以在python的安装目录的\Lib\site-packages\sqlalchemy\sql\sqltypes.py文件中找到支持的数据类型,官网说明:Declaring Models
- primary_key:是否为主键,设置为True时表示该字段是主键。主键默认不能为空且自增
- unique:是否唯一,为True时表示该字段值唯一、不重复
- nullable:是否可为null,为True时表示可为null
- autoincrement:是否自增,为True时表示该字段自增
- default:默认值
注意:db是SQLAlchemy对象
示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库信息
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:wen@127.0.0.1:3306/test?charset=utf8"
# app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
# 初始化Flask对象中的数据库信息
# db = SQLAlchemy(app)
db = SQLAlchemy()
db.init_app(app)
class UserInfo(db.Model):
id = db.Column("user_id", db.Integer, primary_key=True)
name = db.Column(db.String(50))
class SubjectManagement(db.Model):
__tablename__ = "subject_info"
subject_name = db.Column(db.String(25))
subject_id = db.Column(db.Integer, primary_key=True)
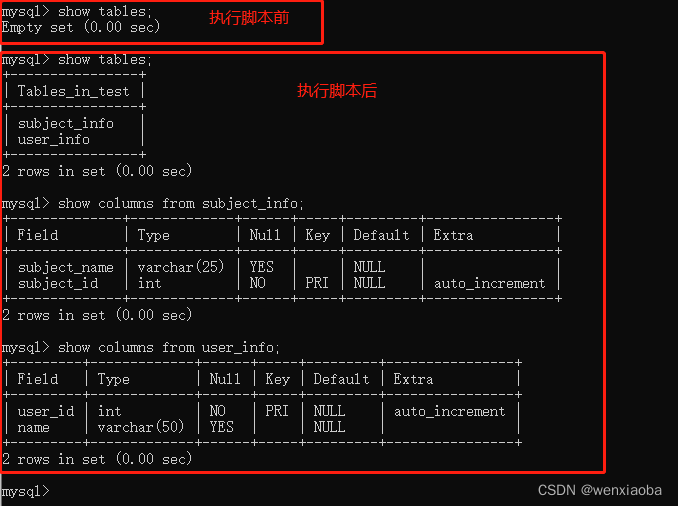
if __name__ == "__main__":
# 根据官网指示,需要在app_context()下进行表的创建和删除
with app.app_context():
# 创建表
db.create_all()
# 删除表
# db.drop_all()
表数据操作
| 方法 | 描述 |
|---|---|
| db.session.add(类对象) | 添加单条数据 |
| db.session.add_all(instances) | 一次性添加多条数据。 instances一般是列表、元组等类型的数据 |
| db.session.commit() | 将数据提交(如果对数据库有修改,则需要提交才能在数据库中生效,未commit前都是暂存在暂存区 |
| db.session.close() | 关闭session(记得关闭session,不然太多暂存区会占用内存空间) |
| 类.query.filter_by(属性名=值).filter_by(属性名=值).xxx | filter_by表示根据条件进行过滤,多个条件就多个filter_by方法(注意:是按照属性名不是按照字段名,底层会将属性名识别成字段名) |
| 类.query.filter_by(属性名=值).first() | 获取查询结果的第一条数据,返回类的对象 |
| 类.query.filter_by(属性名=值).all() | 获取查询结果的所有数据,返回一个列表,列表中元素是类的对象 |
注意:db是SQLAlchemy对象
添加数据
示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库信息
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:wen@127.0.0.1:3306/test?charset=utf8"
# app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
db = SQLAlchemy()
db.init_app(app)
class Person(db.Model):
id = db.Column("user_id", db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
gender = db.Column(db.String(1))
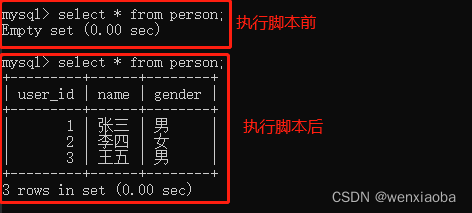
if __name__ == "__main__":
with app.app_context():
p1 = Person(id=1, name="张三", gender="男")
p2 = Person(id=2, name="李四", gender="女")
p3 = Person(id=3, name="王五", gender="男")
db.session.add(p1)
db.session.add_all((p2, p3))
db.session.commit()
db.session.close()
执行脚本,查询数据库数据,结果如下:
查询数据
示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import select, create_engine
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库信息
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:wen@127.0.0.1:3306/test?charset=utf8"
# app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
db = SQLAlchemy()
db.init_app(app)
class Person(db.Model):
id = db.Column("user_id", db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
gender = db.Column(db.String(1))
if __name__ == "__main__":
with app.app_context():
res1 = Person.query.filter_by(gender="男").first()
print("---------------first()---------------")
print("数据类型:", type(res1))
print(res1.id, res1.name, res1.gender)
res2 = Person.query.filter_by(gender="男").all()
print("\n---------------all()---------------")
print(f"数据类型:{type(res2)},元素类型:{type(res2[0])}")
print(res2)
for r in res2:
print(r.id, r.name, r.gender)
res3 = Person.query.filter_by(gender="男").filter_by(id=3).all()
print("\n---------------多个过滤条件---------------")
print(f"数据类型:{type(res3)},元素类型:{type(res3[0])}")
print(res3)
for r in res3:
print(r.id, r.name, r.gender)
数据库内容为:
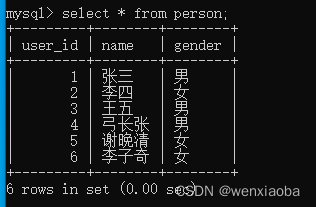
执行结果为:
---------------first()---------------
数据类型: <class '__main__.Person'>
1 张三 男
---------------all()---------------
数据类型:<class 'list'>,元素类型:<class '__main__.Person'>
[<Person 1>, <Person 3>, <Person 4>]
1 张三 男
3 王五 男
4 弓长张 男
---------------多个过滤条件---------------
数据类型:<class 'list'>,元素类型:<class '__main__.Person'>
[<Person 3>]
3 王五 男
修改数据
示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import select, create_engine
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库信息
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:wen@127.0.0.1:3306/test?charset=utf8"
# app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
db = SQLAlchemy()
db.init_app(app)
class Person(db.Model):
id = db.Column("user_id", db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
gender = db.Column(db.String(1))
if __name__ == "__main__":
with app.app_context():
# 方式一:查询数据,修改数据对象的属性,提交session
res = Person.query.filter_by(id=2).first()
res.name = "力士"
db.session.commit()
db.session.close()
# 方式二:给定查询条件并直接update操作,提交session
res = Person.query.filter_by(id=4)
res.update({"gender": "女", "name": "章双双"})
db.session.commit()
db.session.close()
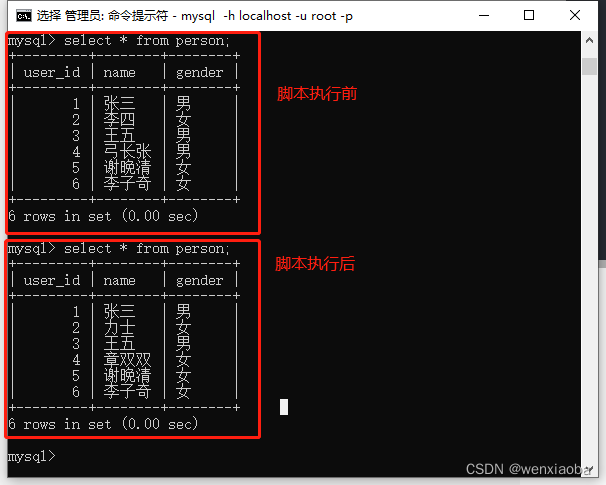
删除数据
示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import select, create_engine
# 创建Flask对象
app = Flask(__name__)
# 在Flask对象中,配置数据库信息
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:wen@127.0.0.1:3306/test?charset=utf8"
# app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
db = SQLAlchemy()
db.init_app(app)
class Person(db.Model):
id = db.Column("user_id", db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
gender = db.Column(db.String(1))
if __name__ == "__main__":
with app.app_context():
# 方式一:查询数据并删除,提交session
res = Person.query.filter_by(id=2).first()
db.session.delete(res)
db.session.commit()
db.session.close()
# 方式二:给定查询条件直接delete(),提交session
res = Person.query.filter_by(id=4)
res.delete()
db.session.commit()
db.session.close()
执行结果:
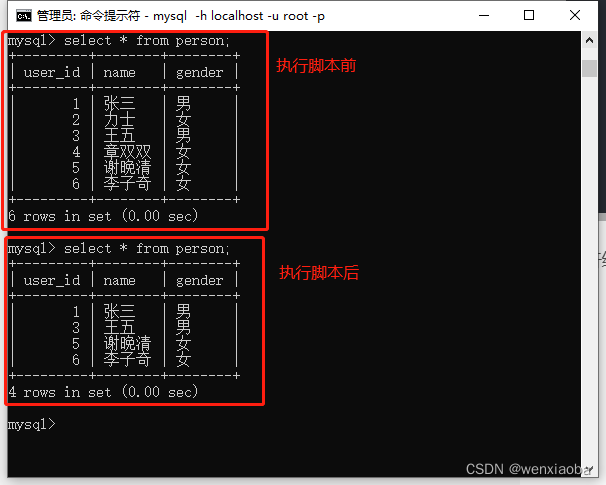
ORM优缺点
从以上的学习中可以了解到:
优势:
- 隐藏了数据访问细节
- ORM使我们构造固化数据结果变得非常简单
缺点:
- 性能下降,添加了关联操作,性能不可比秒的会下降
- 无法解决特别复杂的数据库操作




![[附源码]JAVA毕业设计高校医务管理系统(系统+LW)](https://img-blog.csdnimg.cn/73019ddedaf54807981140cf54650b99.png)
![[附源码]Python计算机毕业设计Django动物保护协会网站](https://img-blog.csdnimg.cn/6fc5aa5543b84e559dfd9795d742fc61.png)
![[激光原理与应用-26]:《激光原理与技术》-12- 激光产生技术-短脉冲、超短脉冲、调Q技术、锁模技术](https://img-blog.csdnimg.cn/9766698142a8462b9019a93768999643.png)


![[附源码]SSM计算机毕业设计疫情防控下高校教职工健康信息管理系统JAVA](https://img-blog.csdnimg.cn/0f8e7e4a232d44ccaf8b293b21908059.png)