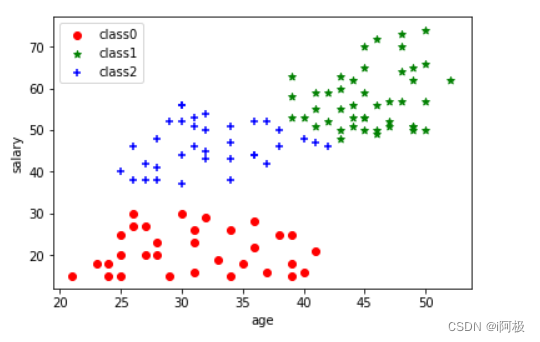
背景知识
堆区细粒堆划分
我们在申请堆空间时,我们只是设置了空间大小,并未设置空间从哪里结束。
堆区里面的详细信息,如某段空间从哪开始,从哪结束,由vm_area_struct负责记录,每申请一段空间就增加一个vm_area_struct,vm-area_struct是以双链表的形式进行连接,OS是可以做到让进程进行资源的细粒度划分。
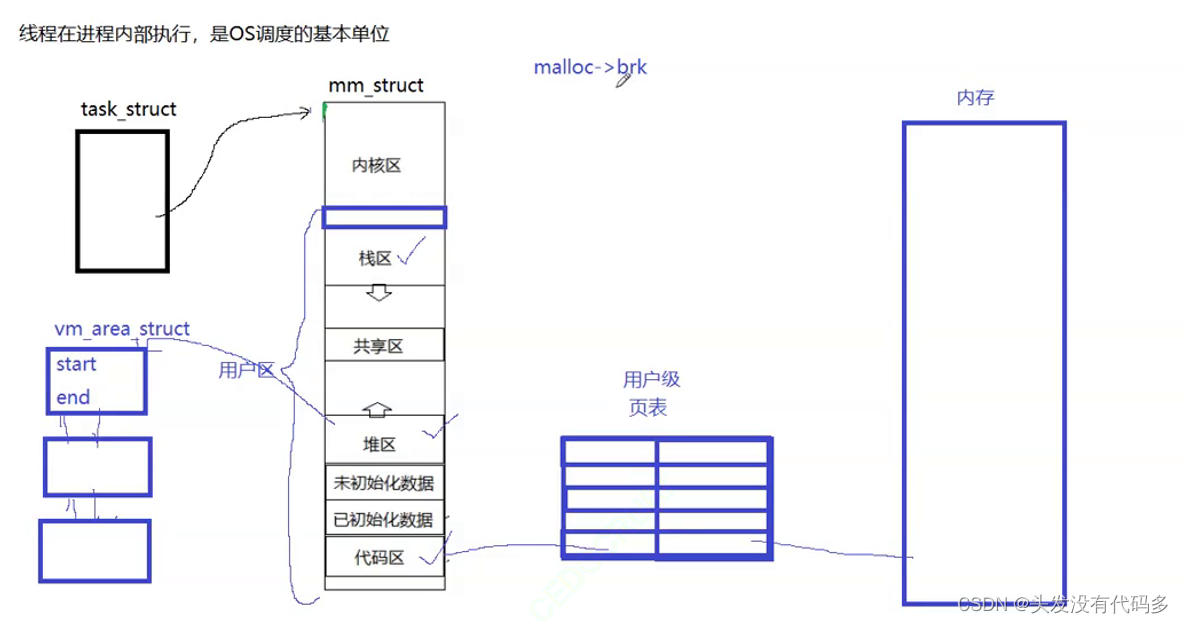
磁盘到内存映射IO
可执行程序和物理内存都被化为4KB,即以4KB为单位。
当内存不足的时候,OS会把内存中不用的数据刷新到磁盘或刷新缓冲区,进行代码访问时,代码区的哪些数据经过映射可以访问到物理内存当中,如果某个区域未被映射,则需要从磁盘中加载数据到内存。
OS要管理物理内存的每个4KB,这种管理的数据结构叫struct_page,struct_page是内核级别的数据结构,该数据结构中有好多标记位,管理方式:先描述(通过标记位描述),再组织(通过数组的方式将所有的page管理起来,struct page mem[1-100w])。
通过page知道物理内存的使用情况和属性。磁盘当中以4KB为单位的代码或数据即内容叫做页帧。而物理内存4KB大小叫页框。
IO的时候基本单位是4KB,IO的时候其实是把页帧装进页框里。从外设加载到内存时,是以4KB为单位,即使加载了1个字节,也是以4KB为单位。
当我们的代码运行起来后,页表一头和虚拟地址空间中的代码去对应起来,另一头会和磁盘的定位置对应起来。页表中还有一些字段,此时页表会发现我们当前对应的数据并未在内存当中,此时会让OS先申请一个page,再根据页表找到磁盘当中可执行程序的内容,再把内容通过文件系统加载到内存当中,然后把物理内存4KB对应的地址覆盖到页表中的磁盘地址,因此页表和磁盘也就没有了联系。这一套过程被称为“缺页中断”。用户对页表中断0感知
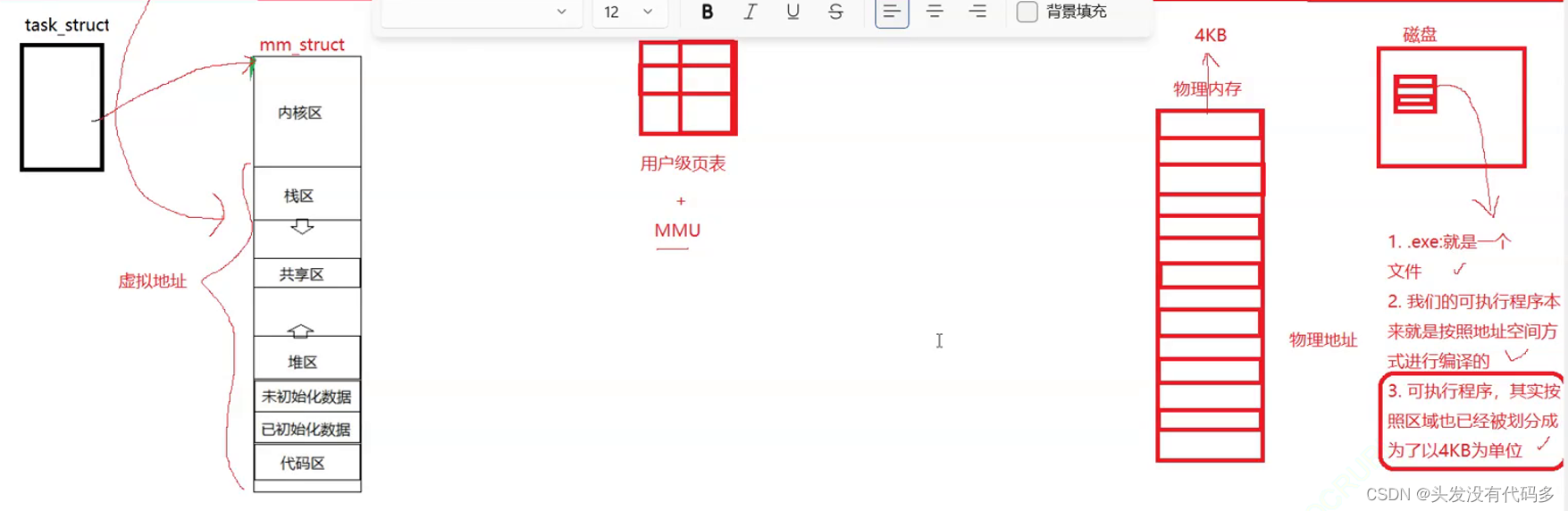
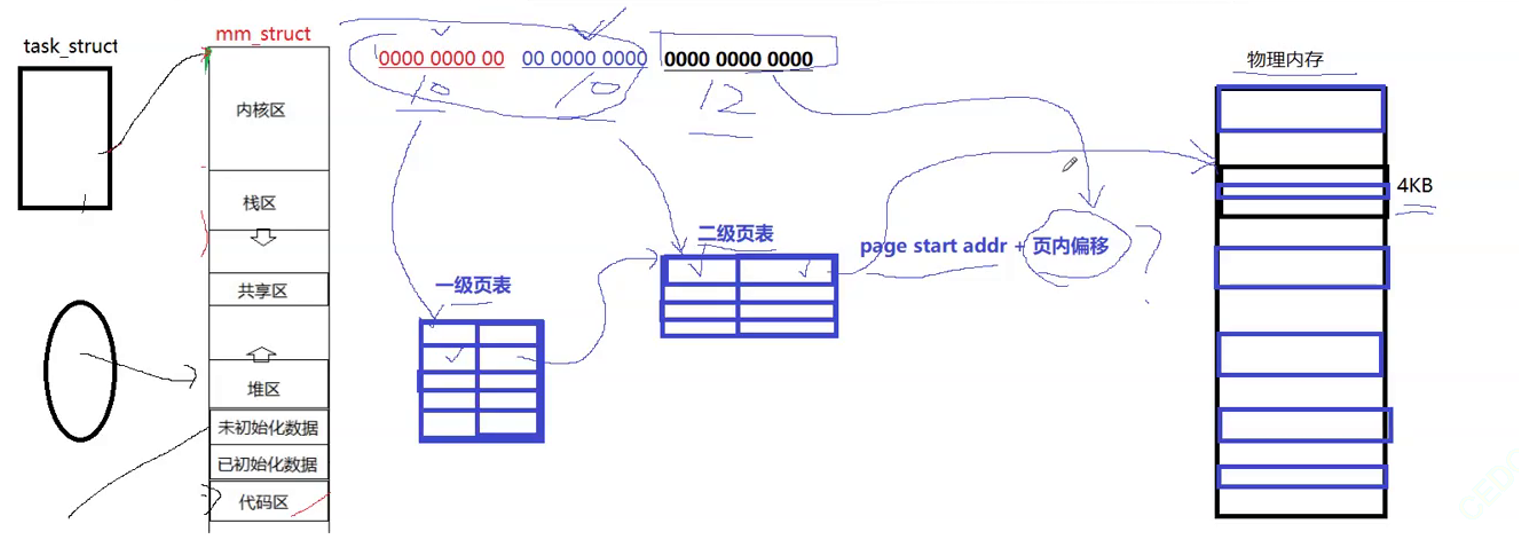
页表的划分
假设页表每个条目(页表的一行,上图的页表一行格子)为9字节,页表总共有2^32个条目,即4GB,而页表是需要保存在物理内存当中的,若要存页表大小就在9*4GB物理内存,而此时页表太大了,根本无法这样直接保存。
OS在虚拟地址(32位),把这32个比特位化为3个区,按照10,10,12划分

页表可看作是<k,v> k代表左边映射关系,v代表右边映射关系
页表是多个结构,一级页表被称作页目录,一级页表只对虚拟地址的前10个比特位进行索引,一级页表共2^10(1024)个条目,即1024对映射关系,假设每个条目大小为10字节,总共大小为10kb。一级页表的k是10个比特位,v是二级页表所在条目地址。
二级页表跟一节页表规则一样,二级页表的k是10个比特位,v(右侧)代表物理内存某一个页的起始地址(虚拟地址要映射的那个页)
由于2^12刚好是4KB,最后12个比特位,存的是当前在这个页内的偏移量,二级页表是起始地址,3级页表是偏移量,这个偏移量叫页内偏移
通过页的起始地址+页内偏移就可获得我们的数据在物理内存的哪个地址处。
这样会使页表的体积变小。
Linux线程概念
什么是线程
若我们已经创建好一个进程,此时再创建进程,此时就会有俩套task_struct,mm_struct,页表
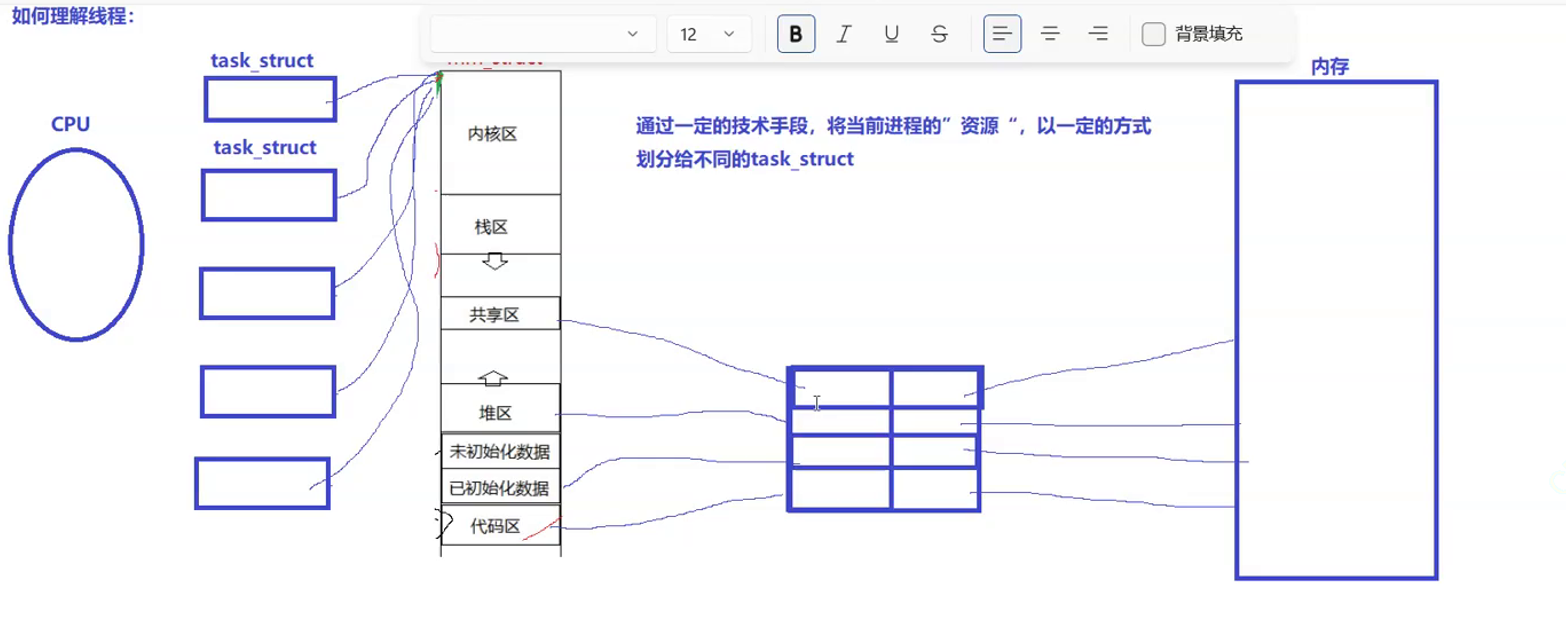
我们想在一个进程的基础上,在创建一个进程,而且这个新的进程只创建PCB(task_struct),这个PCB指向父进程对应的地址空间。
我们想以上面这种方式创建多个进程,而且通过一定的技术手段,将当前进程的“资源”,以一定的方式划分给不同的task_struct(如多个进程执行不同的代码)。而且对于CPU来说,这么多PCB不会影响到CPU。
只要创建出来了这种形式的PCB,如果需要资源,它们只需向自己的父进程要即可。
我们将这里的每一个task_struct可以称之为对应的线程。
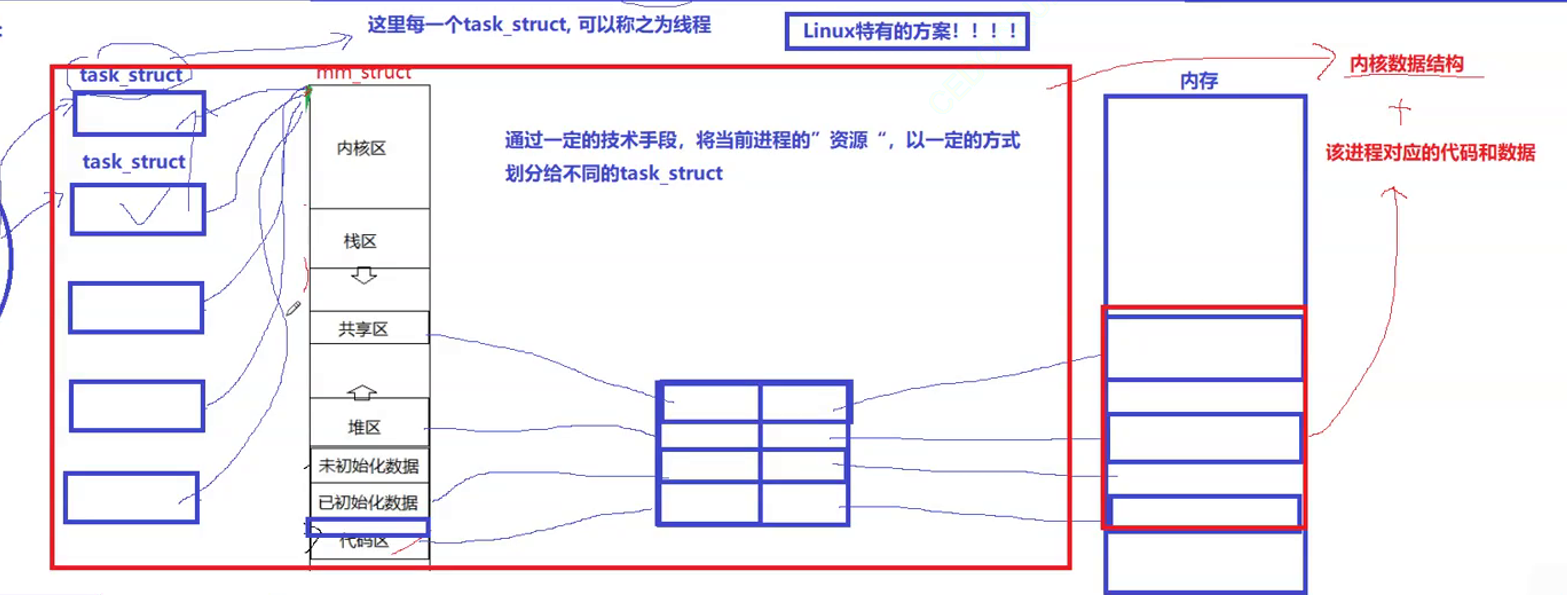
线程在进程内部执行(线程在进程的地址空间内运行),是OS调度的基本单位(CPU不关心执行流是进程还是线程,只关心PCB)。
上面这种线程的实现方案,是Linux特有的方案。Linux中没有专门为线程设计的数据结构(线程的很多工作和进程是重复的)。进程有地址空间,线程共享的是进程的地址空间。
进程再认识
进程(图中红色部分)就是对应的内核数据(可以存在多个PCB)结构加所对应的代码和数据,这个结论是站在用户视角所看到的。
内核视角:进程是承担分配系统资源的基本实体。
如何理解曾经我们所写的代码?
以前我们的代码只有一个TASK_STRUCT,这种进程叫做内部只有一个执行流的进程,而上面的是内部具有多个执行流的进程。进程地址空间内有多个执行流的时候,叫做单进程,多线程程序。task_struct是进程内部的执行流。
在CPU视角:CPU在调度的时候不受任何影响,因为运行队列全是task_struct,CPU其实不怎么关心当前是进程还是线程这样的概念,只认task_struct。CPU调度的基本单位“线程”。
在Linux下,PCB<=其它操作系统内的PCB的。即,量级更轻。当整个进程内部只有一个执行流的时候此时是等于。Linux下的进程可统一称之为轻量级进程。
Linux没有真正意义上的线程结构,因为没有为线程设计专用的数据结构,但是Linux是用进程PCB模拟的线程。
Linux并不能直接给我们提供线程相关的接口,只能提供轻量级进程的接口。 Linux在用户层实现了一套用户层多线程方案,以库的方式提供给用户进行使用,这个库是pthread线程库,这是Linux系统自带的。pthread线程库又叫原生线程库。这个库对应的创建线程是pthread_create
pthread_create
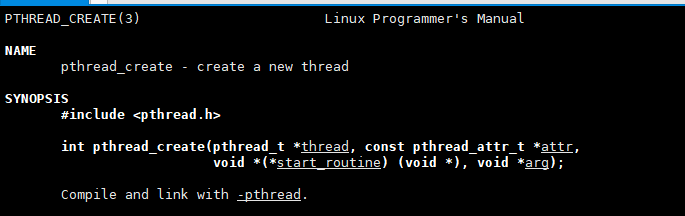
第一个参数是线程ID,第二个是线程属性,这个我们不用管,默认就可以。第三个参数是函数指针,返回值为void*,参数为void*,第四个参数是传递给函数指针的参数,当创建成功时,这个参数会被传递给前面的函数指针从而完成回调。
由于线程是用户层线程库,属于第三方(第一方语言,第二方OS接口),这个库不属于C/C++,属于OS,当我们编译代码直接使用该库就行,因为gcc,g++会帮我们找到相应的C/C++库,但由于这个库属于系统,我们在编译链接的时候要引入相应的选项来链接这个库。
若创建线程成功,返回0,否则返回错误码。
运行程序后,我们发现这里会报错,而且是链接时报错。
在makefile里加上-lpthread即可
我们可以看到我们是用了这个库的
稍微修改一下代码,然后运行
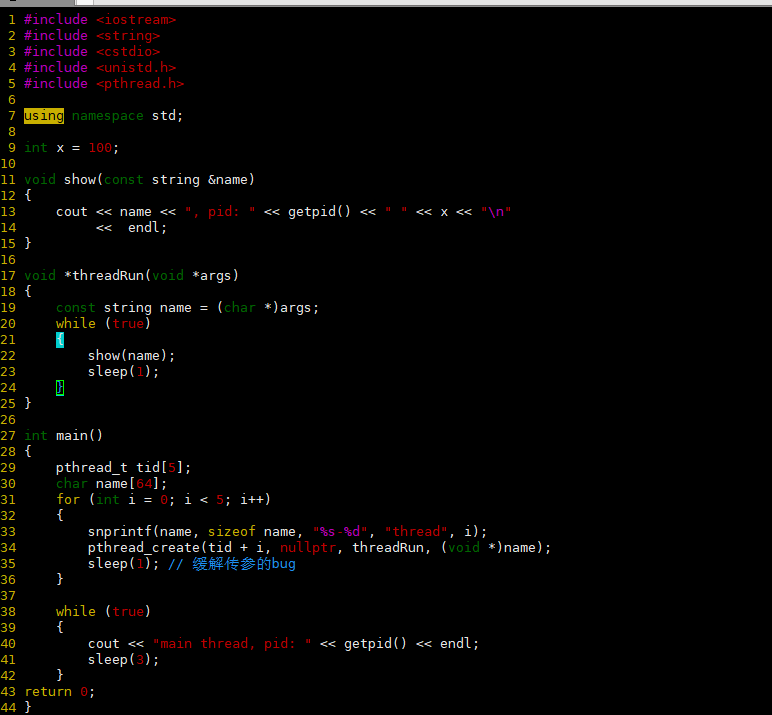
我们可以看到主线程和其它5个线程pid一样,因此说明了线程在进程内部运行

当程序运行的时候,我们进行执行流查看,我们发现只有一个进程。

我们用ps -aL查看到了六个执行流,而且这六个执行流PID都一样,LWP是轻量级进程对应的PID
第一个PID和LWP数字一样,说明第一个是主线程,当进行执行流调度的时候OS是根据LWP进行进行调度的,因为一个PID对应好多个执行流。

当我们杀掉这一个进程后,我们可以看到六个执行流全部退出

此时我们再查看执行流,我们发现已经没有执行流了

由于所有线程用的资源都来自进程,进程被干掉之后,进程的资源被回收,线程跟着退出。
线程如何看待进程的资源
进程的多个线程共享 同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程
中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
文件描述符表(一个线程打开一个文件分配的文件描述符是3,另一个线程打开文件分配的文件描述符是4)
每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
当前工作目录
用户id和组id
代码区也共享,堆区一般也是共享的,但是一般在使用的时候,每个线程申请的堆区认为是该线程私有的,因为只有一个线程能拿到该空间的地址,共享区也是共享的,栈区是私有的,但也可以设置为其它线程可见。
线程共享进程数据,但也拥有自己的一部分数据(b和c必须记住):
线程ID
一组寄存器
栈
errno信号屏蔽字
调度优先级
进程和进程切换,进程和线程进行切换,线程切换的成本更低。
地址空间不需要切换
页表不需要切换
因为CPU内部有硬件级别的缓存,L1~L3 cache,对内存的代码和数据,根据局部性原理(一条指令附近的代码有被使用的概率)预读到CPU内部。
如果进程切换由于进程具有独立性,CPU中对应的cache就立即失效,新进程需要重新缓存。