关注并星标
从此不迷路
计算机视觉研究院



公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
与基线FCOS(一种单阶段和无锚目标象检测模型)相比,新提出的模型在不同的主干上始终获得大约3 个AP的改进,证明了新方法的简单性和效率。
一、前言
Non keypoint-based的目标检测模型由分类和回归分支组成,由于不同的任务驱动因素,这两个分支对来自相同尺度级别和相同空间位置的特征具有不同的敏感性。point-based的预测方法,在基于高分类置信点具有高回归质量的假设上,导致错位问题。我们的分析表明,该问题进一步具体由尺度错位和空间错位组成。
研究者的目标是以最小的成本解决这一现象——对head network进行微调,并用一种新的标签分配方法代替。实验表明,与基线FCOS(一种单阶段和无锚目标象检测模型)相比,新提出的模型在不同的主干上始终获得大约3 个AP的改进,证明了新方法的简单性和效率。
二、背景
目标检测是深度学习时代比较发达的研究领域。通常考虑两种不同的任务,分类旨在研究跨多类的不同特征,回归旨在绘制准确的边界框。然而,由于这两个任务之间的巨大特征信息敏感性,TSD【Revisiting the sibling head in object detector】显示存在空间特征错位问题,并损害了基于NMS的模型预测高置信度分类和高质量回归结果的能力。

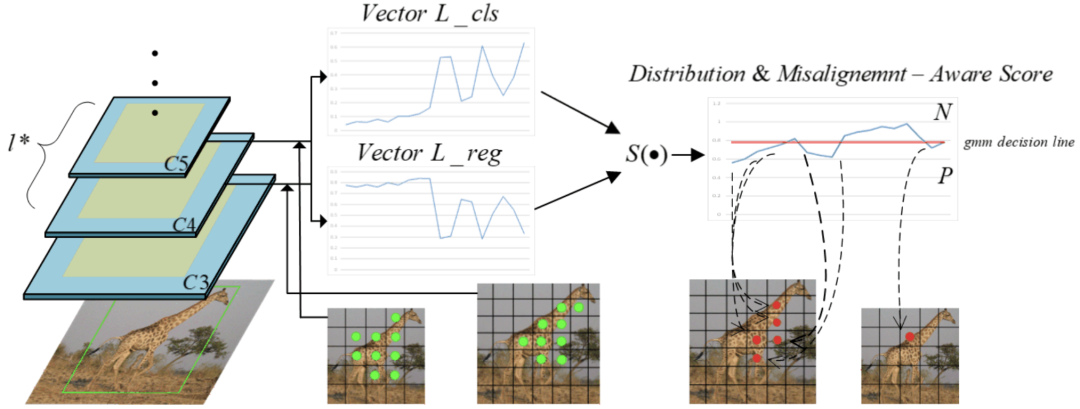
对于空间错位部分,研究者在同一实例中渲染了分类损失和回归损失的空间分布。如上图所示,两个分布高度错位。具有微小分类损失或回归损失的点具有更好的特征可供这两个分支分别利用。因此,两个任务损失的高度错位分布表明这两个任务不喜欢相同空间位置的特征。
在这些分析下,为了解决尺度特征错位问题,研究者为每个任务设计了一个任务驱动的动态感受野适配器,一个简单但有效的形变卷积模块。为了减轻空间特征错位带来的负面影响,设计了一种标签分配方法,挖掘空间最对齐的样本,以增强模型预测具有高分类分数的可靠回归点的能力。
三、新框架
dynamic receptive filed adaptor
在现代one-stage检测器的head,为了在两个分支上获得相同大小的特征图,来自两个分支的四个卷积操作的每一步共享完全相同的内核大小、striding和padding。每个分支的最终感受野由下式计算:
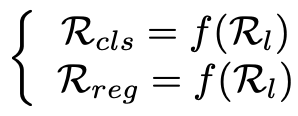
Rl是每个FPN级别馈送的初始特征图的输入图像上的感受野,f(•)是关于跨四个连续卷积层的感受野的静态计算方法。
值得注意的是,RFA模块仅应用于检测器head的第一步,具有两个单独的形变卷积,以增强每个分支对尺度信息的适应能力,并进一步减轻尺度错位的差异。 它不同于直接将形变卷积应用于主干或neck,而不考虑两个分支的不同感受野。 它也不同于VFNet和RepPoints,它们通过形变卷积合并两个分支的信息。 在我们的例子中,每个分支都放宽了规模不匹配,因为我们根据详细的特征信息使每个分支中的每个特征点具有不同的个体感受野。
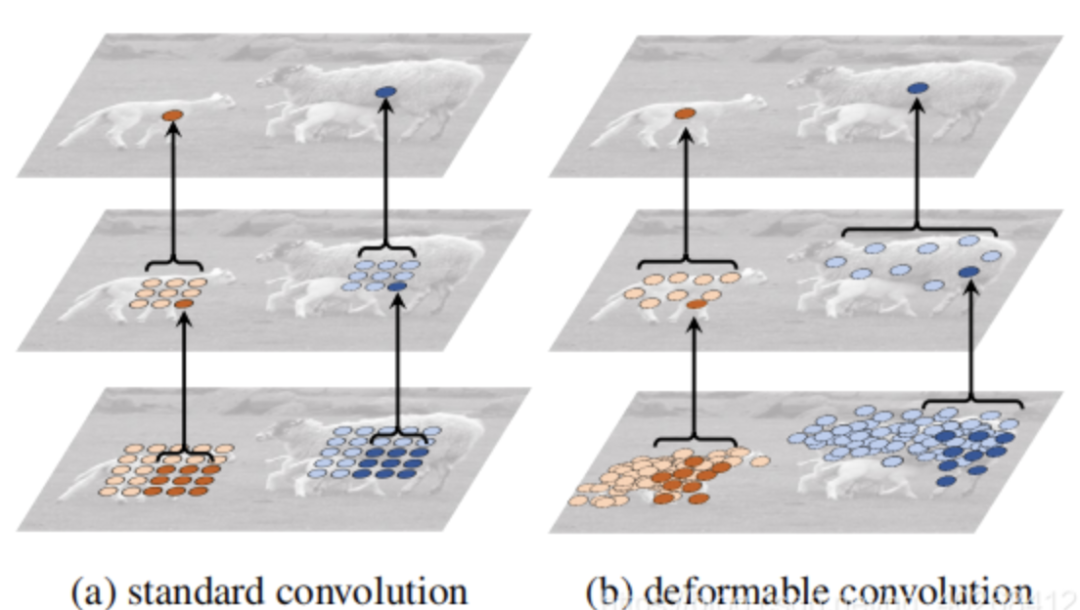
形变卷积(Deformable Convolution)原理
形变卷积的实现方法如下图所示:
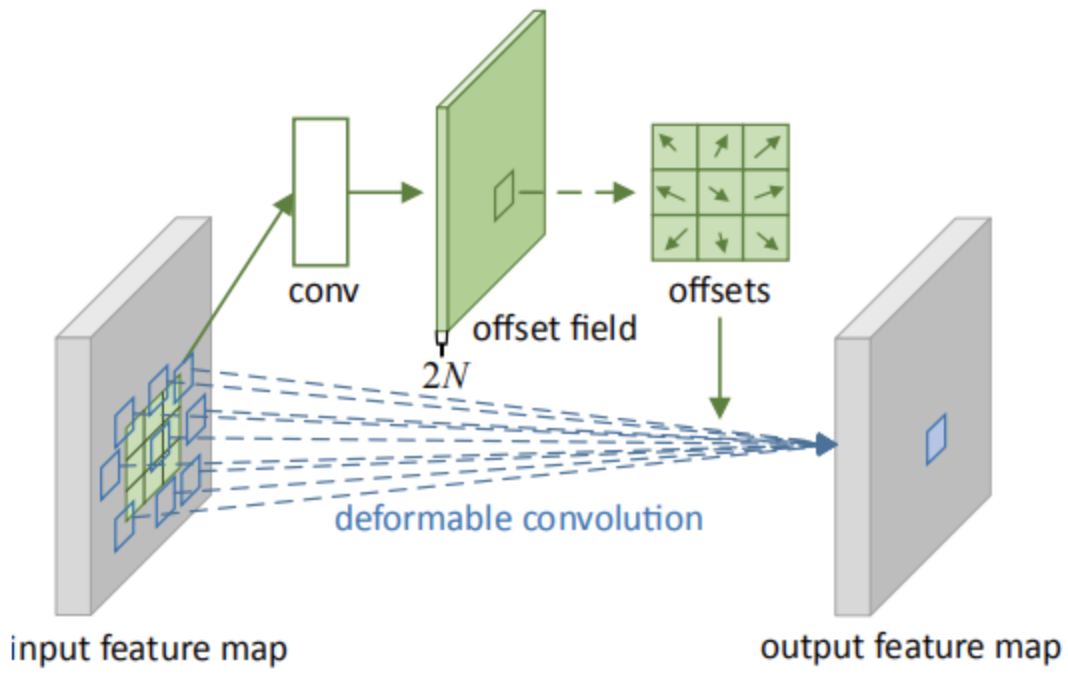
offset field通过在原图上进行标准卷积操作得到,通道数为2N表示N个2维的偏置量(△x,△y),N表示卷积核的个数即输出特征层的通道数。
形变卷积过程可以描述为:首先在输入feature map上进行标准卷积得到N个2维的偏置量(△x,△y),然后分别对输入feature map上各个点的值进行修正:
设feature map为P,即P ( x , y ) = P ( x + △ x , y + △ y ),当x+△x为分数时,使用双线性插值计算P(x+△x,y+△y)
形成N个feature map,然后使用N个卷积核一一对应进行卷积得到输出。标准卷积与形变卷积的计算效果如下图所示:
Aligned Spatial Points Assignment Procedur
给定每个实例Ii的尺度分配结果l∗和l∗中的候选点Cl∗,新框架的任务是进一步挖掘Cl∗中空间最对齐的点。每个候选点有两个指标需要考虑:(1)考虑到两个任务的整体适应度Sf;(2) 由空间上的未对准损失分布引起的未对准度Sm。
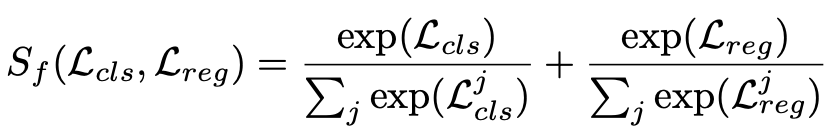
使用softmax函数将Lcls和Lreg分别重新分配到相同的可测标准中,这是由softmax函数单调且其输出之和为一的优点给出的。对于未对齐的程度Sm,由于我们发现sigmoid函数可以高效地将变体输入转换为相当统一的输出,因此将其定义如下:
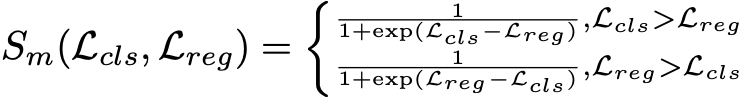
四、实验
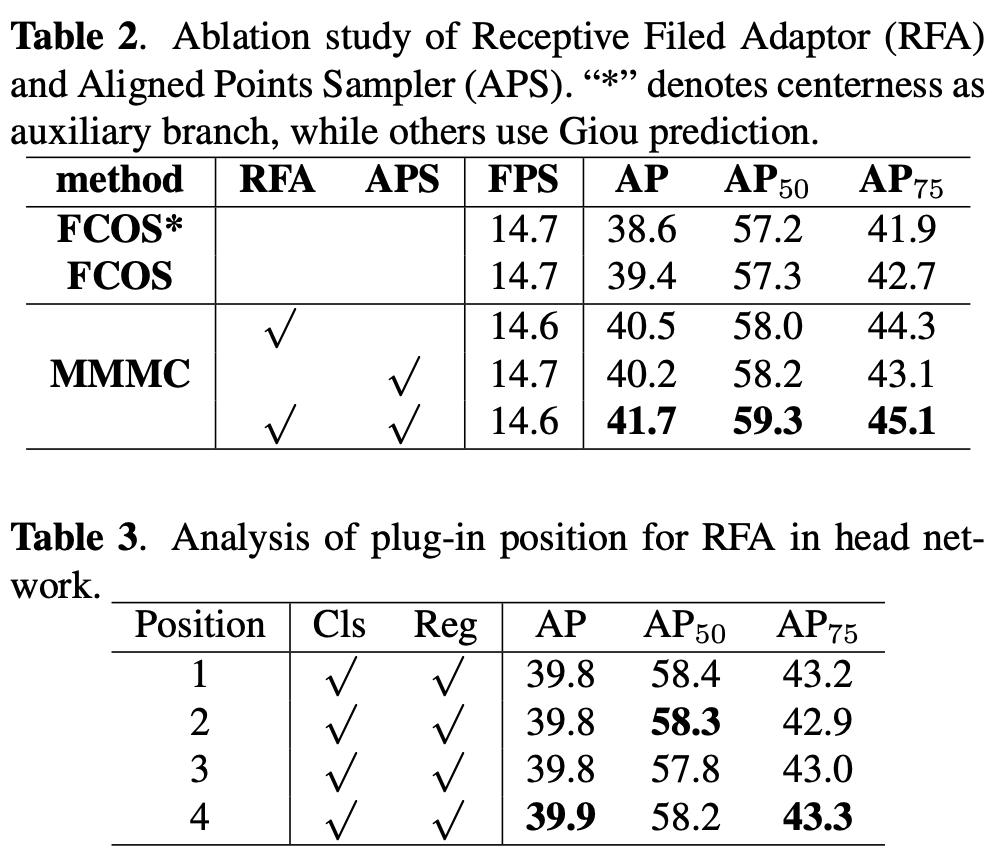
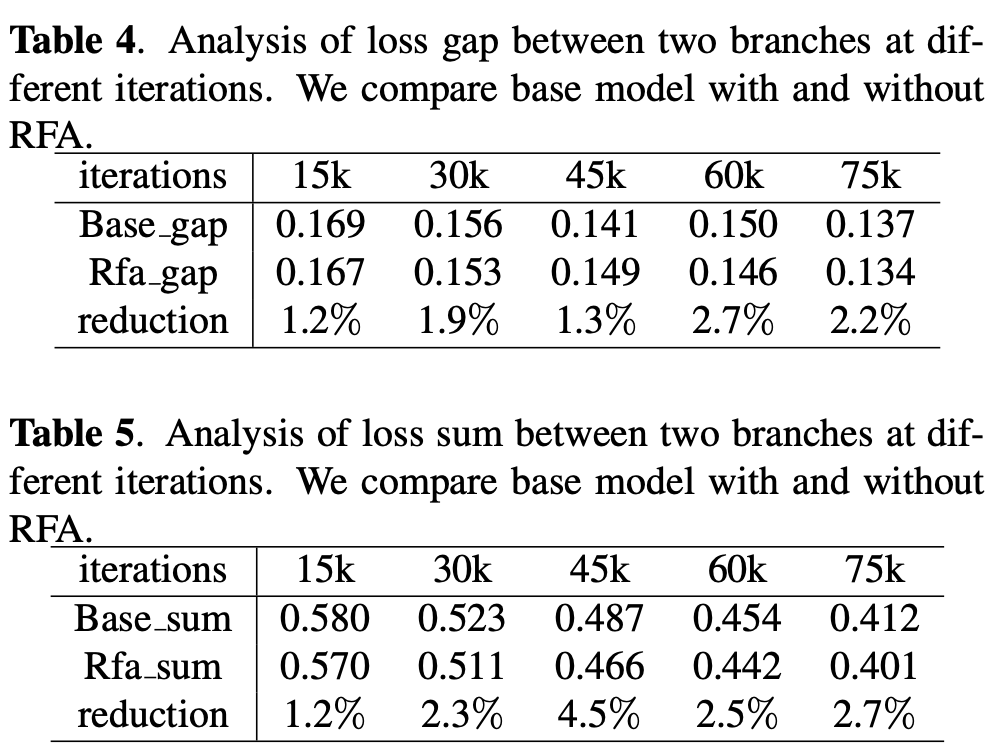
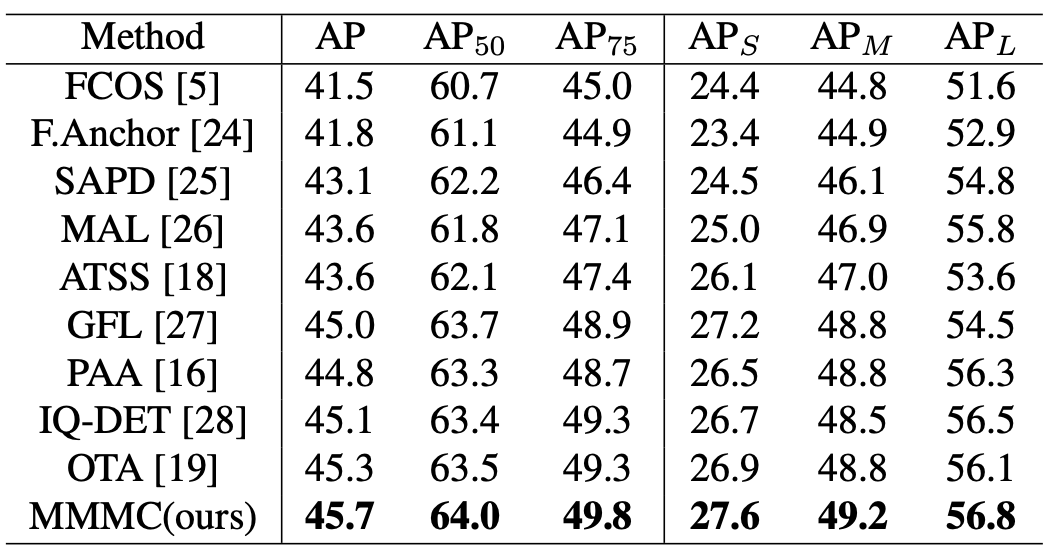
COCO数据集上的比较
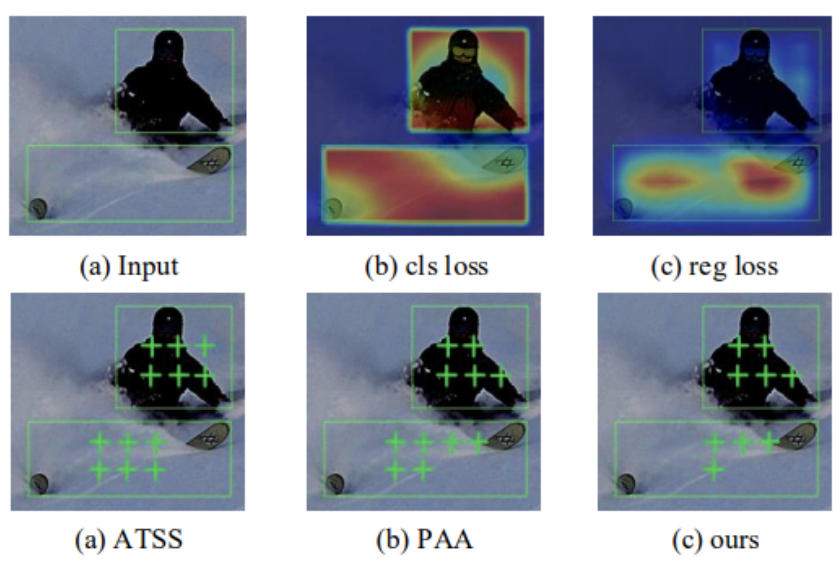
空间标签分配的可视化。第一行分别显示了两个任务的输入和损失分布。第二行的绿色十字是正分配点。
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
改进的YOLOv5:AF-FPN替换金字塔模块提升目标检测精度
用于吸烟行为检测的可解释特征学习框架(附论文下载)
图像自适应YOLO:恶劣天气下的目标检测(附源代码)
新冠状病毒自动口罩检测:方法的比较分析(附源代码)
NÜWA:女娲算法,多模态预训练模型,大杀四方!(附源代码下载)
实用教程详解:模型部署,用DNN模块部署YOLOv5目标检测(附源代码)
LCCL网络:相互指导博弈来提升目标检测精度(附源代码)
Poly-YOLO:更快,更精确的检测(主要解决Yolov3两大问题,附源代码)