论文题目:《Scaling Instruction-Finetuned Language Models》
论文链接:https://arxiv.org/abs/2204.02311
github链接1:https://github.com/lucidrains/PaLM-pytorch/tree/main;
github链接2:https://github.com/conceptofmind/PaLM
huggingface链接:https://huggingface.co/conceptofmind/palm-1b
1 主要贡献
- 提出了 Pathways Language Model (PaLM),这是一个 5400 亿参数、密集激活的 Transformer 语言模型。
- PaLM 使用 Pathways 在 6144 TPU v4 芯片上进行训练,Pathways 是一种新的 ML 系统,可以跨多个 TPU Pod 进行高效训练。
- 它通过在数百种语言理解和生成基准上实现小样本学习sota结果,证明了scaling的良好效果。
2 PaLM模型

2.1 模型结构
PaLM 在decoder-only架构中使用标准的 Transformer 模型架构(即每个时间步只能关注其自身和过去的时间步),并进行以下修改:
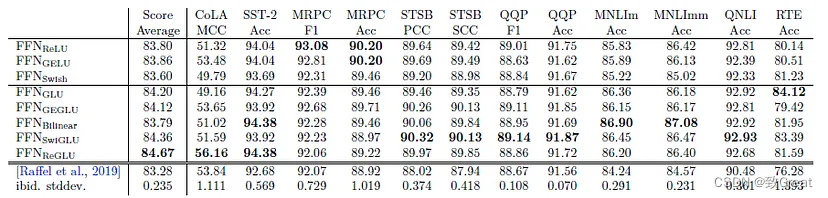
(1)采用SwiGLU激活函数:用于 MLP 中间激活,因为与标准 ReLU、GELU 或 Swish 激活相比,《GLU Variants Improve Transformer》论文里提到:SwiGLU 已被证明可以显著提高模型效果。
我们回顾下上面提到的激活函数:
ReLU激活函数:
R
e
L
U
(
x
)
=
m
a
x
(
0
,
x
)
ReLU(x)=max(0,x)
ReLU(x)=max(0,x)
GeLU激活函数:
G
e
L
U
(
x
)
=
x
Φ
(
x
)
=
x
∫
−
∞
x
1
2
π
e
−
t
2
2
d
t
=
x
⋅
1
2
[
1
+
e
r
f
(
x
2
)
]
GeLU(x)=x\Phi(x)=x\int_{-\infty}^{x}\frac{1}{\sqrt{2\pi}}e^{-\frac{t^{2}}{2}}dt=x\cdot \frac{1}{2}[1+erf(\frac{x}{\sqrt{2}})]
GeLU(x)=xΦ(x)=x∫−∞x2π1e−2t2dt=x⋅21[1+erf(2x)]
其中erf为误差函数。
Swish激活函数:
S
w
i
s
h
=
x
⋅
s
i
g
m
o
i
d
(
β
x
)
Swish=x\cdot sigmoid(\beta x)
Swish=x⋅sigmoid(βx)
我们不难发现,激活函数就是对x乘以一些数,以对某些值进行约束。
G L U ( x ) = σ ( W x + b ) ⊗ ( V x + c ) GLU(x)=\sigma (Wx+b) \otimes (Vx+c) GLU(x)=σ(Wx+b)⊗(Vx+c)
三种 GLU 变体如下:

SwiGLU实现如下:
class SwiGLU(nn.Module):
def forward(self, x):
x, gate = x.chunk(2, dim=-1)
return F.silu(gate) * x
按照下面的方法用于FNN:
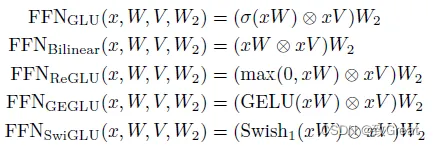
(2)提出Parallel Layers:每个 Transformer 结构中的“并行”公式:与 GPT-J-6B 中一样,使用的是标准“序列化”公式。具体来说,标准公式可以写成:

并行公式可以写成:

并行公式使大规模训练速度提高了大约 15%。消融实验显示在 8B 参数量下模型效果下降很小,但在 62B 参数量下没有模型效果下降的现象。
# parallel attention and feedforward with residual
# discovered by Wang et al + EleutherAI from GPT-J fame
class ParallelTransformerBlock(nn.Module):
def __init__(self, dim, dim_head=64, heads=8, ff_mult=4):
super().__init__()
self.norm = LayerNorm(dim)
attn_inner_dim = dim_head * heads
ff_inner_dim = dim * ff_mult
self.fused_dims = (attn_inner_dim, dim_head, dim_head, (ff_inner_dim * 2))
self.heads = heads
self.scale = dim_head**-0.5
self.rotary_emb = RotaryEmbedding(dim_head)
self.fused_attn_ff_proj = nn.Linear(dim, sum(self.fused_dims), bias=False)
self.attn_out = nn.Linear(attn_inner_dim, dim, bias=False)
self.ff_out = nn.Sequential(
SwiGLU(),
nn.Linear(ff_inner_dim, dim, bias=False)
)
# for caching causal mask and rotary embeddings
self.register_buffer("mask", None, persistent=False)
self.register_buffer("pos_emb", None, persistent=False)
def get_mask(self, n, device):
if self.mask is not None and self.mask.shape[-1] >= n:
return self.mask[:n, :n]
mask = torch.ones((n, n), device=device, dtype=torch.bool).triu(1)
self.register_buffer("mask", mask, persistent=False)
return mask
def get_rotary_embedding(self, n, device):
if self.pos_emb is not None and self.pos_emb.shape[-2] >= n:
return self.pos_emb[:n]
pos_emb = self.rotary_emb(n, device=device)
self.register_buffer("pos_emb", pos_emb, persistent=False)
return pos_emb
def forward(self, x):
"""
einstein notation
b - batch
h - heads
n, i, j - sequence length (base sequence length, source, target)
d - feature dimension
"""
n, device, h = x.shape[1], x.device, self.heads
# pre layernorm
x = self.norm(x)
# attention queries, keys, values, and feedforward inner
q, k, v, ff = self.fused_attn_ff_proj(x).split(self.fused_dims, dim=-1)
# split heads
# they use multi-query single-key-value attention, yet another Noam Shazeer paper
# they found no performance loss past a certain scale, and more efficient decoding obviously
# https://arxiv.org/abs/1911.02150
q = rearrange(q, "b n (h d) -> b h n d", h=h)
# rotary embeddings
positions = self.get_rotary_embedding(n, device)
q, k = map(lambda t: apply_rotary_pos_emb(positions, t), (q, k))
# scale
q = q * self.scale
# similarity
sim = einsum("b h i d, b j d -> b h i j", q, k)
# causal mask
causal_mask = self.get_mask(n, device)
sim = sim.masked_fill(causal_mask, -torch.finfo(sim.dtype).max)
# attention
attn = sim.softmax(dim=-1)
# aggregate values
out = einsum("b h i j, b j d -> b h i d", attn, v)
# merge heads
out = rearrange(out, "b h n d -> b n (h d)")
return self.attn_out(out) + self.ff_out(ff)
(3)Multi-Query Attention:每个头共享键/值的映射,即“key”和“value”被投影到 [1, h],但“query”仍被投影到形状 [k, h],这种操作对模型质量和训练速度没有影响,但在自回归解码时间上有效节省了成本。
(4) 使用RoPE embeddings:使用的不是绝对或相对位置嵌入,而是RoPE,是因为 RoPE 嵌入在长文本上具有更好的性能 ,具体原理可看苏神文章《Transformer升级之路:2、博采众长的旋转式位置编码》

# rotary positional embedding
# https://arxiv.org/abs/2104.09864
class RotaryEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, max_seq_len, *, device):
seq = torch.arange(max_seq_len, device=device, dtype=self.inv_freq.dtype)
freqs = einsum("i , j -> i j", seq, self.inv_freq)
return torch.cat((freqs, freqs), dim=-1)
def rotate_half(x):
x = rearrange(x, "... (j d) -> ... j d", j=2)
x1, x2 = x.unbind(dim=-2)
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(pos, t):
return (t * pos.cos()) + (rotate_half(t) * pos.sin())
(5) 采用Shared Input-Output Embeddings:输入和输出embedding矩阵是共享的,这个我理解类似于word2vec的输入W和输出W’:

上图来自《Using the Output Embedding to Improve Language Models》
(6)不使用偏置项:在dense kernel或layer norm中都没有使用偏差,这种操作提高了大模型的训练稳定性。
(7) 词汇表:使用具有 256k 标记的 SentencePiece 词汇表,选择它来支持训练语料库中的大量语言,而无需过度标记化。
2.2 模型变体
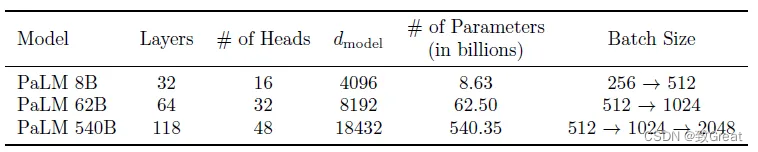
考虑了三种不同的模型尺度:540B、62B 和 8B 参数。
2.3 训练数据

- PaLM 预训练数据集包含一个包含 7800 亿个标记的高质量语料库,代表了广泛的自然语言用例。 该数据集是经过过滤的网页、书籍、维基百科、新闻文章、源代码和社交媒体对话的混合体。 该数据集基于用于训练 LaMDA(Thoppilan 等人,2022 年)和 GLaM(Du 等人,2021 年)的数据集。
- 所有三个模型都只在一个时期的数据上进行训练(所有模型的数据清洗方式都相同)。
- 除了自然语言数据,预训练数据集还包含 196GB 代码,从 GitHub 上的开源存储库获取,包括 Java、HTML、Javascript、Python、PHP、C#、XML、C++ 和 C。
最终的 PaLM 数据集混合如上表所示
2.4 训练硬件资源

总体来说,该程序包含用于 pod 内前向+反向计算(包括 pod 内梯度减少)的组件 A,用于跨 pod 梯度传输的传输子图,以及用于优化器更新的组件 B(包括本地和远程梯度的求和) ).
Pathways 程序在每个 pod 上执行组件 A,然后将输出梯度传输到另一个 pod,最后在每个 pod 上执行组件 B。
因此,它掩盖了延迟。 此外,它还分摊了管理数据传输的成本。
作者还详细提到了实际设置,例如两个 pod 之间的主机通过 Google 数据中心网络连接。 (感兴趣的请直接阅读论文。)
这块理解为 他们在TPU训练架构,不是单纯的多机多GPU,反正没TPU可以用看了。。

PaLM 代表了 LLM 训练效率向前迈出的重要一步。
2. 英语NLP任务效果
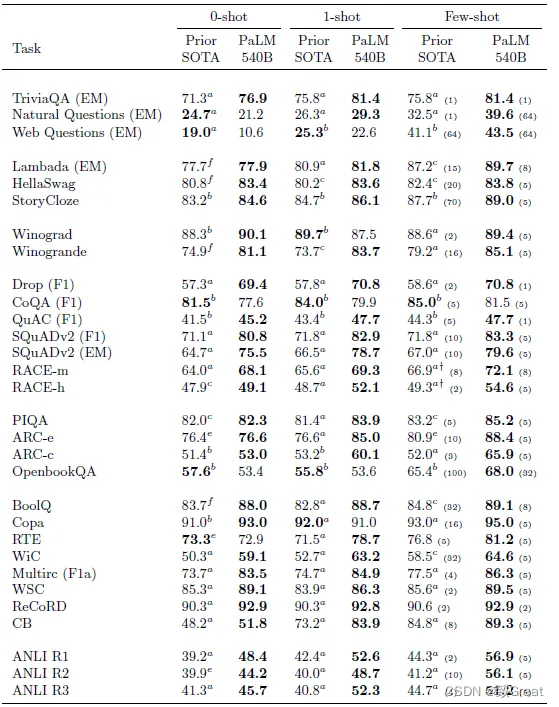
PaLM 模型在与 Du 等人相同的一组 29 个英语基准上进行评估。 (2021) 和布朗等人。 (2020)。
PaLM 540B 在 1-shot 设置的 29 个任务中的 24 个和在 few-shot 设置的 29 个任务中的 28 个任务上优于之前的 SOTA。 有趣的是,PaLM 540B 在一些阅读理解和 NLI 任务的小样本设置中比之前的 SOTA 高出 10 多分。
PaLM 540B 在所有基准测试中都优于类似尺寸的模型(Megatron-Turing NLG 530B)。 这表明预训练数据集、训练策略和训练期间观察到的标记数量在实现这些结果方面也起着重要作用。

3 BIG-Bench 效果
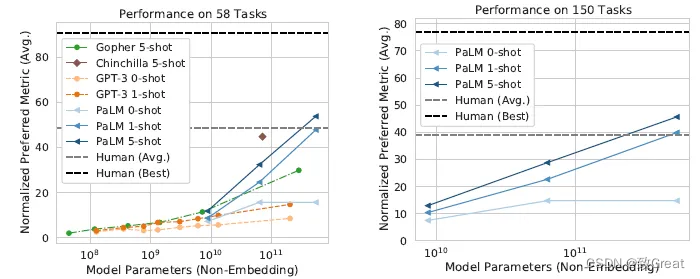
在 58 项任务中,PaLM 的表现明显优于 GPT-3、Gopher 和 Chinchilla,并且 5-shot PaLM 540B 的得分高于要求解决相同任务的人类的平均得分。

5-shot PaLM 540B 在 58 个常见任务中的 44 个上优于之前的 SOTA,每个任务的结果如上所示
4 逻辑推理效果
推理任务是需要多步算术或常识性逻辑推理才能产生正确答案的任务。

PaLM 540B 实现了 58% 的性能,优于 Cobbe 等人之前 55% 的 SOTA。
5 代码生成效果

来自 PaLM-Coder 540B 型号的示例。 (左上)从 OpenAI GSM8K 数学数据集转换而来的 GSM8K-Python 问题。 (左下)将一个简单函数从 C++ 转换为 Python 的 TransCoder 示例。 (右)转换后的 HumanEval 示例。
上面显示了代码任务数据集的一些示例。

PaLM-Coder 是 PaLM,具有 2 个阶段的代码进一步微调。
PaLM-Coder 540B 的性能进一步提高,在 HumanEval 上达到 88.4% pass@100,在 MBPP 上达到 80.8% pass@80。
6 翻译效果
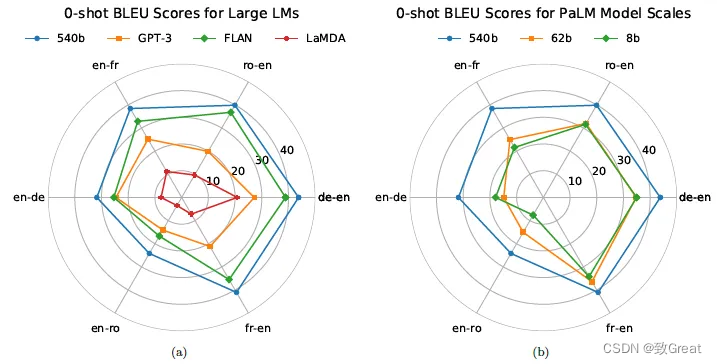
左图:PaLM 优于所有基线,有时非常果断,差异高达 13 BLEU。 右图:将 PaLM 从 62B 缩放到 540B 会导致 BLEU 分数出现几次急剧跳跃,这不符合“幂律”经验法则。
7 其他
还有其他结果,例如:多语言自然语言生成,多语言问答。
此外,还讨论了其他问题,例如:记忆、数据集污染、偏见、伦理问题、未决问题。