前言
在PyTorch2022开发者大会上,PyTorch团队发布了一个新特性——torch.compile,将PyTorch的性能推向了新的高度,称这个新版本为PyTorch2.0。torch.compile的引入不影响之前的功能,其是一个完全附加和可选的功能,因此PyTorch2.0完全向后兼容,基于之前1.x版本开发的项目可以直接迁移到PyTorch2.0使用。
环境升级
比较简单,按照官方说明安装即可。
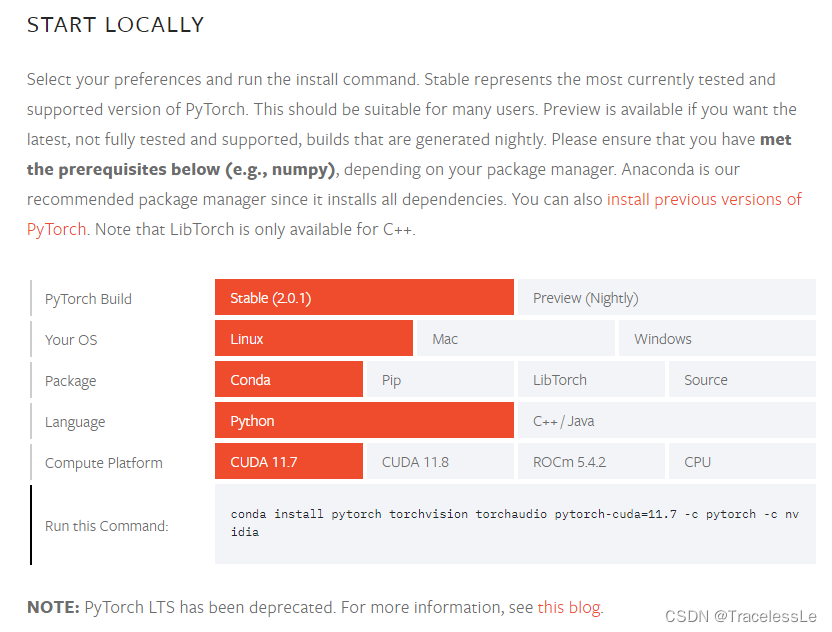
先建一个新环境torch2.0.1,python版本使用3.8+,在新环境中安装PyTorch2.0:
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
测试向后兼容性
待所有依赖包安装好之后,切换到新环境。
conda activate torch2.0.1
运行之前torch1.x下能正常运行的网络训练代码,可以看到能够正常运行。此时速度没什么明显差别。
需要注意的是,如果是使用DDP模式训练的话,可能会报“local_rank”相关的错。将代码中的相关配置参数修改一下:
__author__ = 'TracelessLe'
import argparse
import torch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
if (torch.__version__).startswith('2.0'):
parser.add_argument("--local-rank", type=int, required=True)
else:
parser.add_argument("--local_rank", type=int, required=True)
main()
测试加速效果
根据PyTorch官方博客中的内容,使用torch.compile后模型训练和推理的加速效果很明显。
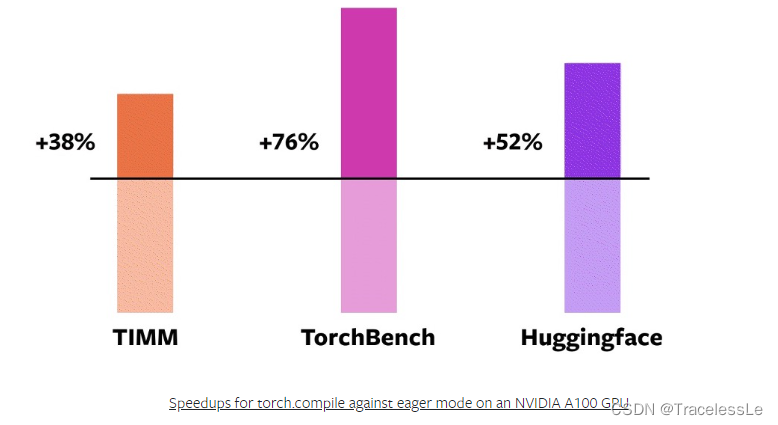
这里快速上手,直接根据新手教程中的操作来修改相应代码:
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet18', pretrained=True)
opt_model = torch.compile(model, backend="inductor")
model(torch.randn(1,3,64,64))
在实验中发现自己的某个简单的网络训练速度由~0.8s/step加速到~0.6s/step,加速比达到25%。实践说明该新功能确实能够加速训练速度。
本次不深入测试更多的功能,包括不同的backend,以及纯推理过程的加速比。
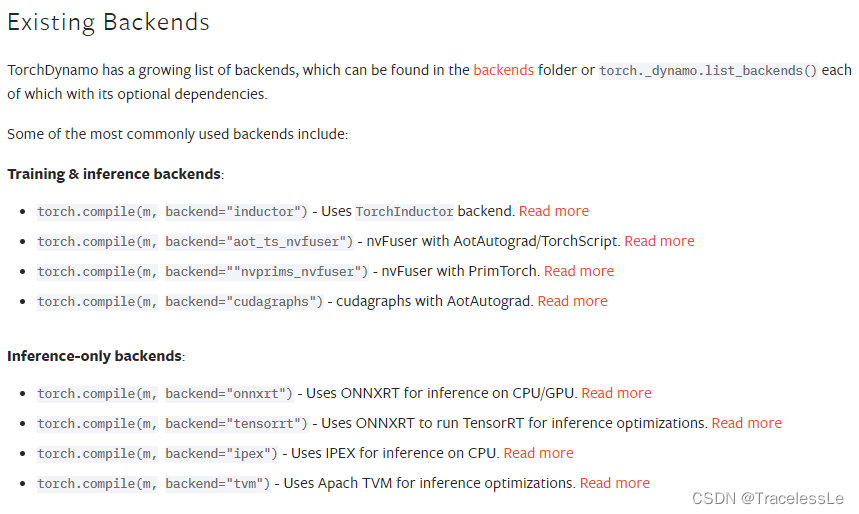
其他说明
使用torch.compile功能时如果同时需要加载预训练模型,根据预训练模型保存的版本和正在使用的PyTorch版本的区别分情况进行处理:
1、预训练好的模型由PyTorch1.x保存,需要使用PyTorch2.0的torch.compile加速功能。则需要网络先加载模型参数,再使用torch.compile进行编译。
__author__ = 'TracelessLe'
import torch
device = 'cuda:0'
model_pth = 'pretrained_model.pth'
model = TrainNet()
model_state_dict = torch.load(model_pth, map_location=device)
model.load_state_dict(model_state_dict, strict=False)
if (torch.__version__).startswith('2.0'):
model = torch.compile(model, backend="inductor")
2、预训练好的模型由PyTorch2.x保存,需要使用PyTorch2.0的torch.compile加速功能。则需要网络先编译再加载模型参数。
__author__ = 'TracelessLe'
import torch
device = 'cuda:0'
model_pth = 'pretrained_model.pth'
model = TrainNet()
if (torch.__version__).startswith('2.0'):
model = torch.compile(model, backend="inductor")
model_state_dict = torch.load(model_pth, map_location=device)
model.load_state_dict(model_state_dict, strict=False)
当然,PyTorch2.0保存的模型PyTorch1.x也是可以正常加载的,只是需要注意的是模型中存的key有一定差异需要特殊处理一下。
其中,PyTorch2.0模型的key前缀是“_orig_mod.module.”,而PyTorch1.x模型的key前缀是“module.”。根据这个差异对模型加载过程特殊处理即可。
__author__ = 'TracelessLe'
import torch
import collections
def load_model_compile(model, model_pth, device, strict=False, backend="inductor"):
# 兼容torch1/2大版本之间的模型加载
origin_dict = torch.load(model_pth, map_location=device)
state_dict = collections.OrderedDict()
# torch1_model_prefix = 'module.'
# offset1 = len(torch1_model_prefix)
torch2_model_prefix = '_orig_mod.'
offset2 = len(torch2_model_prefix)
for key, value in origin_dict.items():
if key.startswith(torch2_model_prefix):
if (torch.__version__).startswith('2.0'):
model = torch.compile(model, backend=backend)
model.load_state_dict(origin_dict, strict=strict)
else:
for key, value in origin_dict.items():
state_dict[key[offset2: len(key)]] = value
model.load_state_dict(state_dict, strict=strict)
else:
if (torch.__version__).startswith('2.0'):
model.load_state_dict(origin_dict, strict=strict)
model = torch.compile(model, backend=backend)
else:
model.load_state_dict(origin_dict, strict=strict)
break
return model
当然,也可以直接改模型中参数的key以适配不同版本,此处不再展开。
针对PyTorch2.0的变化在官方博客中讲的很详细,需要深入应用的同学可以进一步查阅相关资料。
版权说明
本文为原创文章,独家发布在blog.csdn.net/TracelessLe。未经个人允许不得转载。如需帮助请email至tracelessle@163.com或扫描个人介绍栏二维码咨询。

参考资料
[1] PyTorch 2.0 重磅发布:一行代码提速 30% - 知乎
[2] Getting Started — PyTorch 2.0 documentation
[3] torch.compile — PyTorch 2.0 documentation
[4] 解决报错:train.py: error: unrecognized arguments: --local-rank=1 ERROR:torch.distributed.elastic.multipr_WTIAW.TIAW的博客-CSDN博客
[5] torch.compile — PyTorch 2.0 documentation
[6] Accelerated Image Segmentation using PyTorch | PyTorch
[7] Accelerated Generative Diffusion Models with PyTorch 2 | PyTorch
[8] PyTorch 2.0 | PyTorch
[9] torch.compile Tutorial — PyTorch Tutorials 2.0.1+cu117 documentation
[10] Training Compiled PyTorch 2.0 with PyTorch Lightning