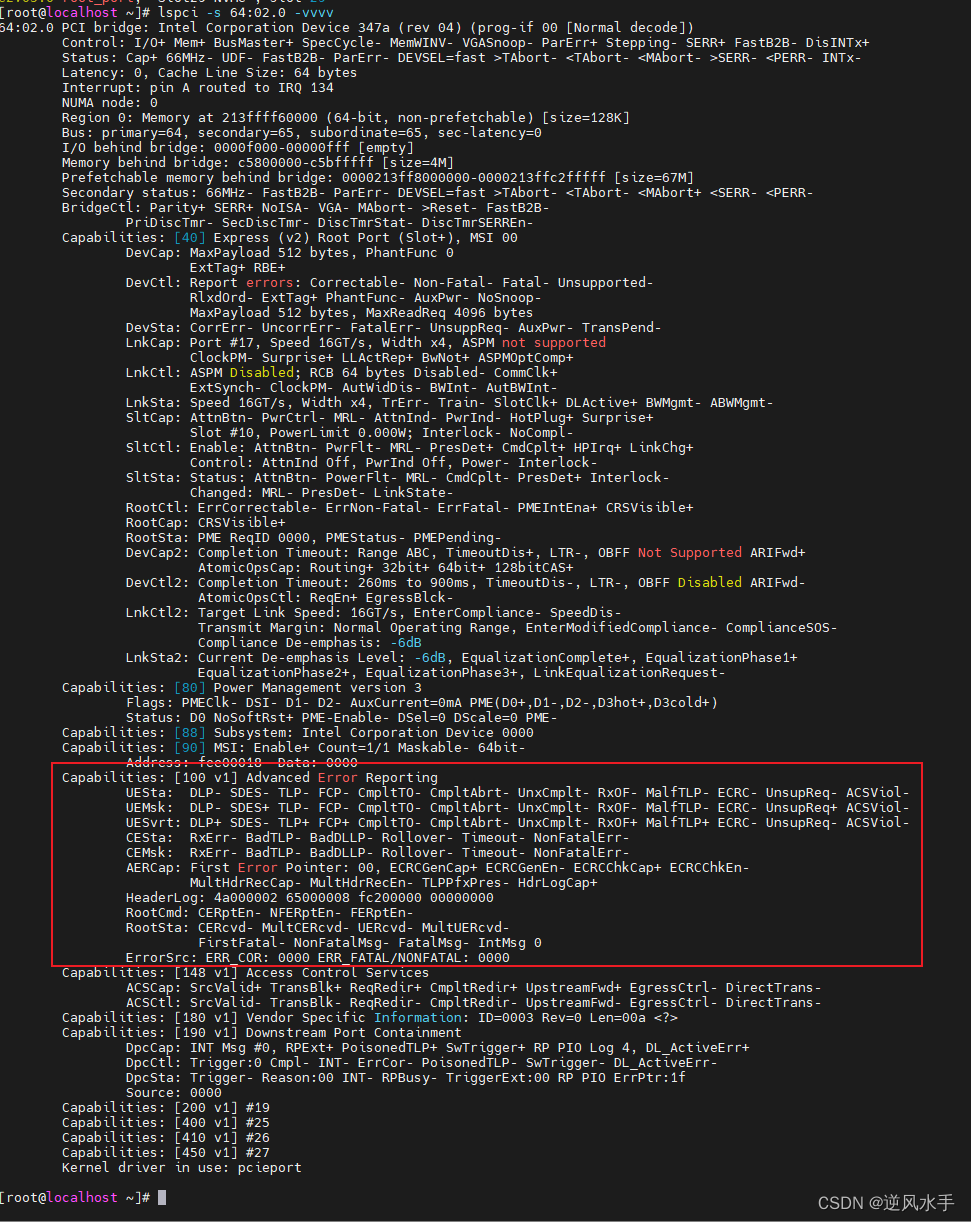
在训练之前先要按照一定目录格式准备数据:
VOC标签格式转yolo格式并划分训练集和测试集_爱钓鱼的歪猴的博客-CSDN博客
目录
1、修改数据配置文件
2、修改模型配置文件
3、训练
1、修改数据配置文件
coco.yaml

拷贝data/scripts/coco.yaml文件,
path 修改为VOCdevkit文件夹所在目录
train:修改为yolov5_train.txt
val: 修改为yolov5_val.txt
names也进行修改,保存为my-anther.yaml
具体如下:
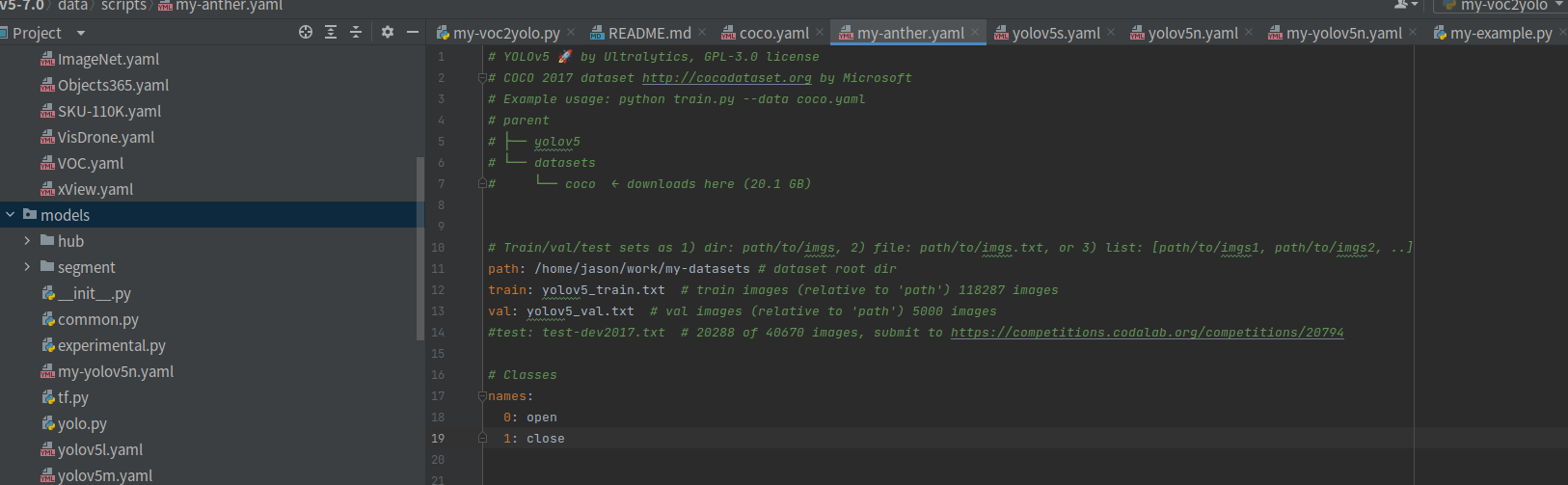
这样模仿VOC数据集的目录结构,与yolov5项目里的代码所匹配
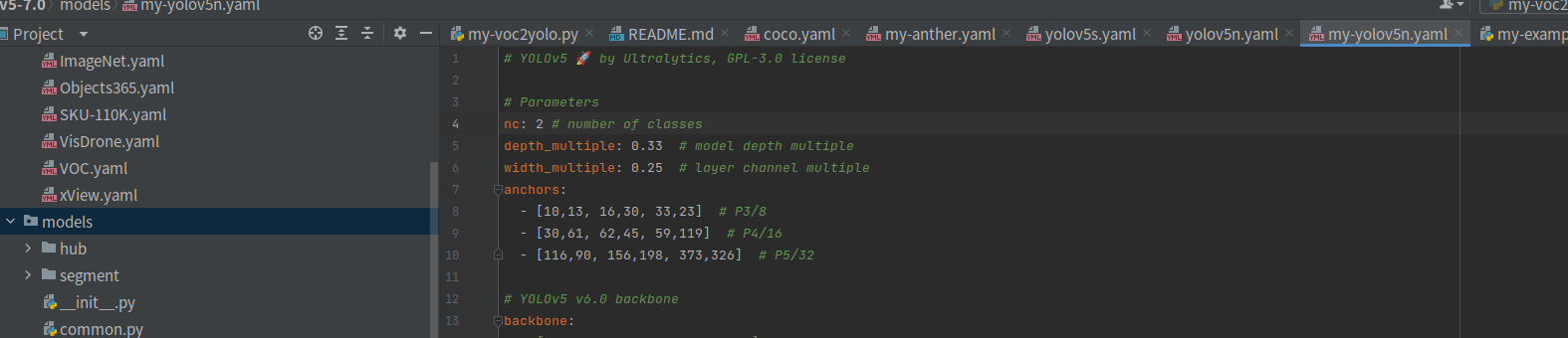
2、修改模型配置文件
把项目models/yolov5n.yaml文件拷贝一份,只修改类别数量(num of classes)就成,保存为my-yolov5n.yaml
3、训练
在项目目录下开启终端
运行:
python train.py --data my-anther.yaml --epochs 1 --weights yolov5n.pt --cfg my-yolov5n.yaml --batch-size 24
如果有GPU ,命令后面添加 --device 0。这里没有GPU,所以只跑一个 epoch。
batch可选择调为16、24、40、64、128....。先选一个小的,保证能跑起来,然后慢慢加大,如果内存不足报错,就返回上一个batch大小。
输出信息:
(yolo) jason@honor:~/PycharmProjects/pytorch_learn/yolo/yolov5-7.0$ python train.py --data my-anther.yaml --epochs 1 --weights yolov5n.pt --cfg my-yolov5n.yaml --batch-size 24
train: weights=yolov5n.pt, cfg=my-yolov5n.yaml, data=my-anther.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=1, batch_size=24, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
YOLOv5 🚀 2022-11-22 Python-3.8.13 torch-2.0.0+cu117 CPU
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
from n params module arguments
0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2]
1 -1 1 4672 models.common.Conv [16, 32, 3, 2]
2 -1 1 4800 models.common.C3 [32, 32, 1]
3 -1 1 18560 models.common.Conv [32, 64, 3, 2]
4 -1 2 29184 models.common.C3 [64, 64, 2]
5 -1 1 73984 models.common.Conv [64, 128, 3, 2]
6 -1 3 156928 models.common.C3 [128, 128, 3]
7 -1 1 295424 models.common.Conv [128, 256, 3, 2]
8 -1 1 296448 models.common.C3 [256, 256, 1]
9 -1 1 164608 models.common.SPPF [256, 256, 5]
10 -1 1 33024 models.common.Conv [256, 128, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 90880 models.common.C3 [256, 128, 1, False]
14 -1 1 8320 models.common.Conv [128, 64, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 22912 models.common.C3 [128, 64, 1, False]
18 -1 1 36992 models.common.Conv [64, 64, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 74496 models.common.C3 [128, 128, 1, False]
21 -1 1 147712 models.common.Conv [128, 128, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 296448 models.common.C3 [256, 256, 1, False]
24 [17, 20, 23] 1 9471 models.yolo.Detect [2, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]
my-YOLOv5n summary: 214 layers, 1766623 parameters, 1766623 gradients, 4.2 GFLOPs
Transferred 342/349 items from yolov5n.pt
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005625000000000001), 60 bias
train: Scanning /home/jason/work/my-datasets/yolov5_train.cache... 2276 images, 0 backgrounds, 0 corrupt: 100%|██████████| 2276/2276 00:00
val: Scanning /home/jason/work/my-datasets/yolov5_val.cache... 568 images, 0 backgrounds, 0 corrupt: 100%|██████████| 568/568 00:00
AutoAnchor: 6.38 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train/exp2/labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs/train/exp2
Starting training for 1 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/0 0G 0.09858 0.3112 0.01833 1331 640: 100%|██████████| 95/95 10:55
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/12 00:00WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 8%|▊ | 1/12 00:08WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 17%|█▋ | 2/12 00:15WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 25%|██▌ | 3/12 00:23WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 33%|███▎ | 4/12 00:30WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 42%|████▏ | 5/12 00:38WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 50%|█████ | 6/12 00:47WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 58%|█████▊ | 7/12 00:54WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 67%|██████▋ | 8/12 01:00WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 75%|███████▌ | 9/12 01:07WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 83%|████████▎ | 10/12 01:14WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 92%|█████████▏| 11/12 01:21WARNING ⚠️ NMS time limit 2.500s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 12/12 01:28
all 568 28591 0.613 0.262 0.108 0.0351
1 epochs completed in 0.207 hours.
Optimizer stripped from runs/train/exp2/weights/last.pt, 3.8MB
Optimizer stripped from runs/train/exp2/weights/best.pt, 3.8MB
Validating runs/train/exp2/weights/best.pt...
Fusing layers...
my-YOLOv5n summary: 157 layers, 1761871 parameters, 0 gradients, 4.1 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/12 00:00WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 8%|▊ | 1/12 00:08WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 17%|█▋ | 2/12 00:44WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 25%|██▌ | 3/12 01:07WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 33%|███▎ | 4/12 01:33WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 42%|████▏ | 5/12 01:42WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 50%|█████ | 6/12 01:49WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 58%|█████▊ | 7/12 01:57WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 67%|██████▋ | 8/12 02:04WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 75%|███████▌ | 9/12 02:10WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 83%|████████▎ | 10/12 02:18WARNING ⚠️ NMS time limit 2.900s exceeded
Class Images Instances P R mAP50 mAP50-95: 92%|█████████▏| 11/12 02:24WARNING ⚠️ NMS time limit 2.500s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 12/12 02:30
all 568 28591 0.61 0.228 0.0949 0.0317
open 568 2512 1 0 0.00273 0.00136
close 568 26079 0.219 0.456 0.187 0.062
Results saved to runs/train/exp2







![[架构之路-196] - 发现问题原因的通常步骤:提出问题、明确问题、偏差分析、因素分析、原因分析](https://img-blog.csdnimg.cn/img_convert/f7efe2bf33776de3a2e3b4fffb5ec56b.jpeg)


![05- redis集群模式搭建(上) (包含云服务器[填坑])](https://img-blog.csdnimg.cn/9f6f10ec1a8c4c2385205c9f4cbd4039.png)