uuid,jdk自带,但是数据库性能差,32位呀。
mysql数据库主键越短越好,B+tree产生节点分裂,大大降低数据库性能,所以uuid不建议。
redis的自增,但是要配置维护redis集群,就为了一个id,还要引入一套redis。费事,成本高。
如果有序自增别人就知道你的业务量多少了。
雪花算法
分布式自增id算法snowflake,京东还有好多大厂使用这个。
经测试每秒能产生26w个自增可以排序的id
1.生成id能按照时间有序生成
2.生成id结果是一个64bit大小的整数,为一个Long型(转换成字符串长度最多19)
3.分布式系统内不会产生id碰撞(由datacenter和worderId作区分)并且效率高。
雪花算法几个核心组成部分


1bit,符号位,不用,因为二进制中最高位是符号位,1表示负,0表示正。生成的id是正数,所以是0.
5位机房id,5位机器id

一毫秒内只能生成4095,如果超过只能到下一秒了,需要获取下一个时间戳
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
如何使用,整合springboot即可
hutool工具包
雪花算法源码
判断是否时钟回拨,回拨抛异常不做处理
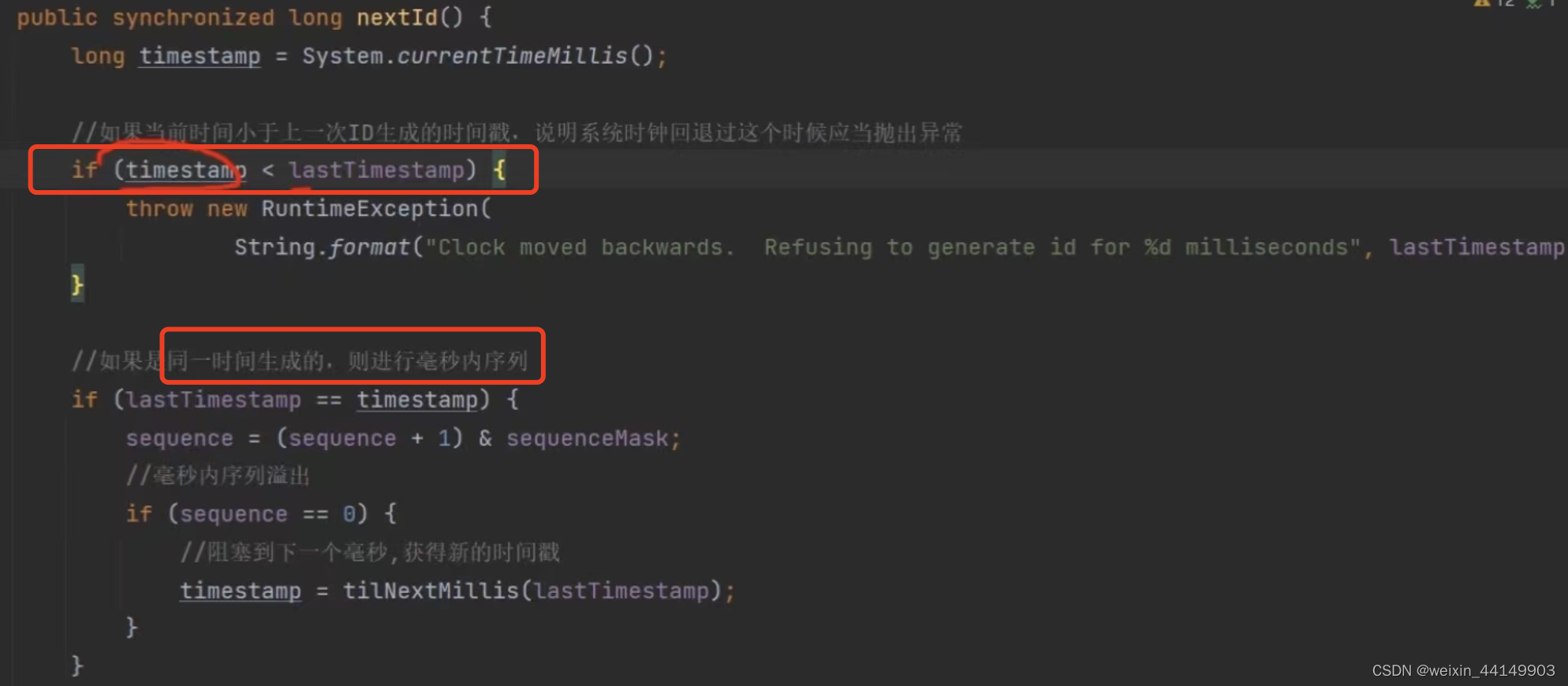
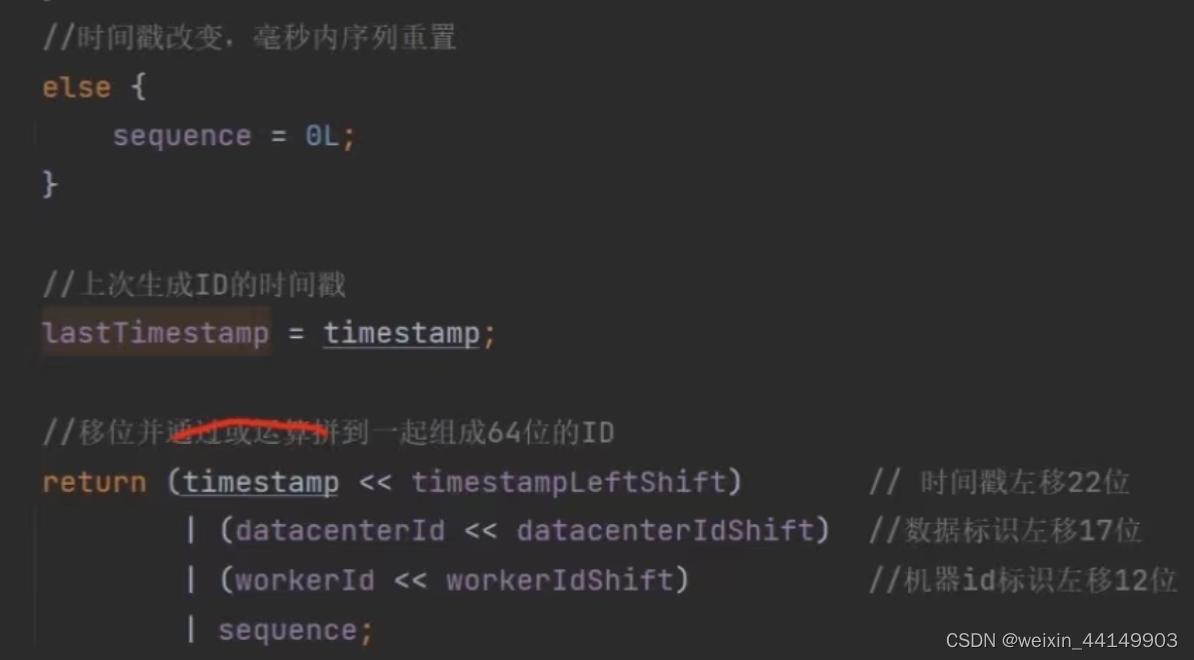
如果是这个时间第一次,sequence=0,如果同一个时间有其他进入,则(sequence+1)& sequenceMask计算,这个计算就是和12个1做与运算,当你小于4095时后,还是你自己,当大于的时候,比方是4096,计算后就是0,如果并发特别高,1毫秒产生的大于4096,阻塞到下一毫秒。通过while循环等一下,等到下一毫秒,然后变成下一个时间段了。
真正自己代码会减掉一个自己的系统初始时间,可以让我们时间更长

通过zookeeper生成机器id
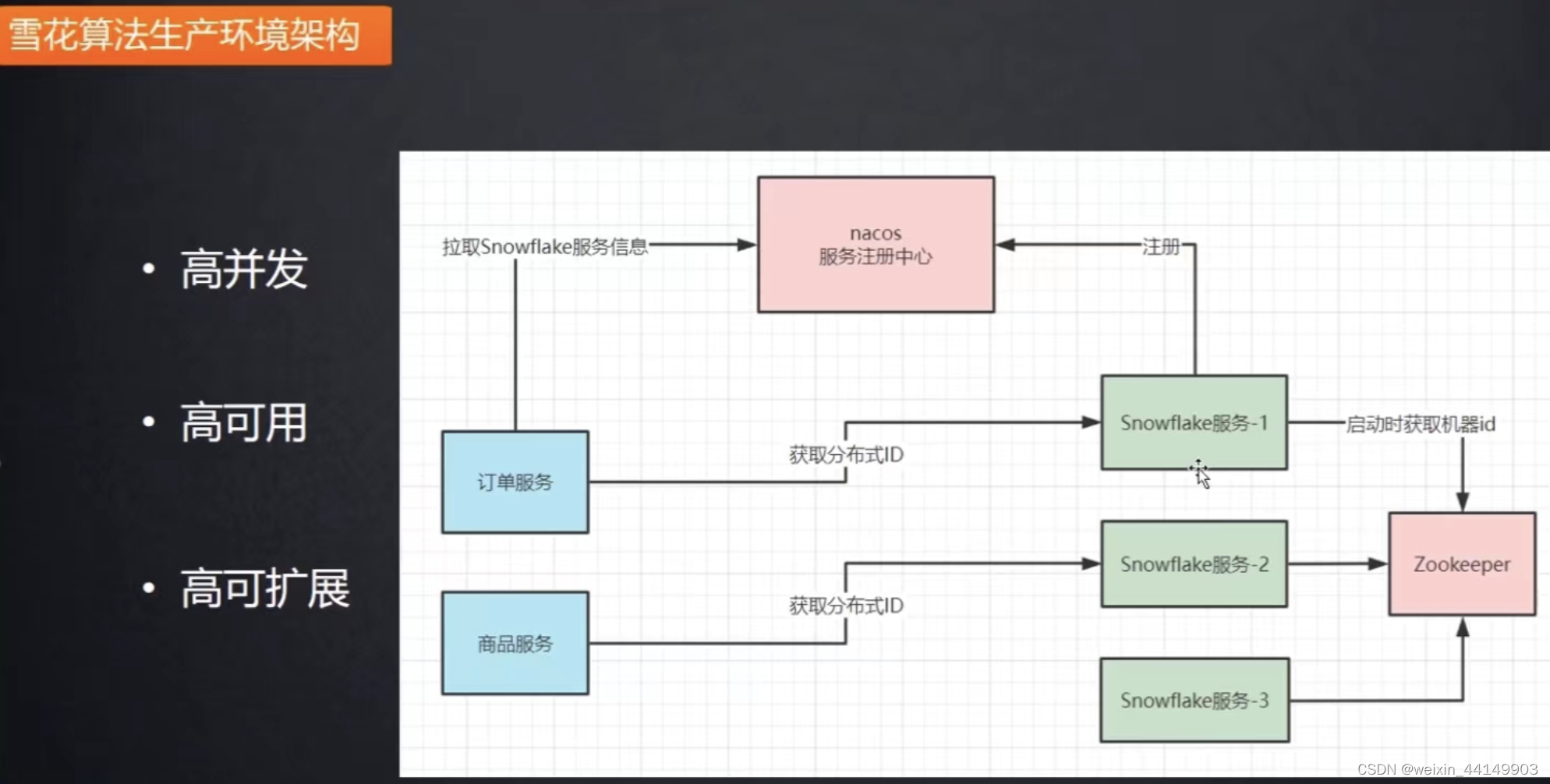
雪花服务注册到nacos注册中心
时钟回拨问题
雪花算法源码里面通过判断时间大小来判断是否发生时间回拨,如果发生,抛异常,拒绝生成。这里没有做任何时钟回拨处理,所以线上机器不要动。
如何处理时钟回拨问题呢?
雪花算法源码没有解决,真的线上不能使用,需要修改。才能达到高并发,高可用,高可扩展。
第一种解决方法,我们可以加个容忍时间,设置3ms,如果发生时钟回拨,我们用LockSupport锁来睡一下,睡上最大容忍时间3ms,然后再去看一下有没有时钟回拨问题。如果还是有问题呢?我们要通过人为干预解决了
第二种解决方法,雪花算法10位机器是可以控制的,我们用备用机解决,
回拨时间长短,如果短,等待一会儿。
如果时间适中,可以将最近的数据时间段,每一毫秒的maxId数据保存起来,在他最后面开始++。
如果时间再长,雪花算法10位机器是可以控制的,我们用备用机解决,重试其他机器,换一台机器。下次再走到,已经过了时间,没有回拨问题了。
如果时间更长,机器下线,不能用了,人为解决吧。调用nacos服务下限api,将这台机器直接下线。同步发送短信告知运维。
百度开源的 UidGenerator 是基于Java语言实现的唯一ID生成器,是在雪花算法 snowflake 的基础上做了一些改进(解决了时钟回拨问题)。
美团,Leaf
基于雪花算法进行修改封装。
工作进程怎么办,1024台怎么维护
分布式主键中间件获取id,由他区分工作进程,用美团的Leaf服务,Leaf也是高可用,负载均衡
保证leaf也是不同id,0-1023,zookeeper有序节点,启动leaf,一直能扩展到1023.
Leaf需要依赖zookeeper顺序节点,通过RPC去Leaf中获取id
还有就是解决时钟回拨问题
Leaf-snowflake 方案
Leaf-segment 方案可以生成趋势递增的 ID,同时 ID 号是可计算的,不适用于订单 ID 生成场景,比如竞对在两天中午 12 点分别下单,通过订单 id 号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,我们提供了 Leaf-snowflake 方案。
Leaf-snowflake不同于原始snowflake算法地方,主要是在workId的生成上,Leaf-snowflake依靠Zookeeper生成workId,也就是上边的机器ID(占5比特)+ 机房ID(占5比特)。Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
Leaf-snowflake 方案完全沿用 snowflake 方案的 bit 位设计,即是 “1+41+10+12” 的方式组装 ID 号。对于 workerID 的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf 服务规模较大,动手配置成本太高。所以使用 Zookeeper 持久顺序节点的特性自动对 snowflake 节点配置 wokerID。Leaf-snowflake 是按照下面几个步骤启动的:
启动 Leaf-snowflake 服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点)。
如果有注册过直接取回自己的 workerID(zk 顺序节点生成的 int 类型 ID 号),启动服务。
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的 workerID 号,启动服务。
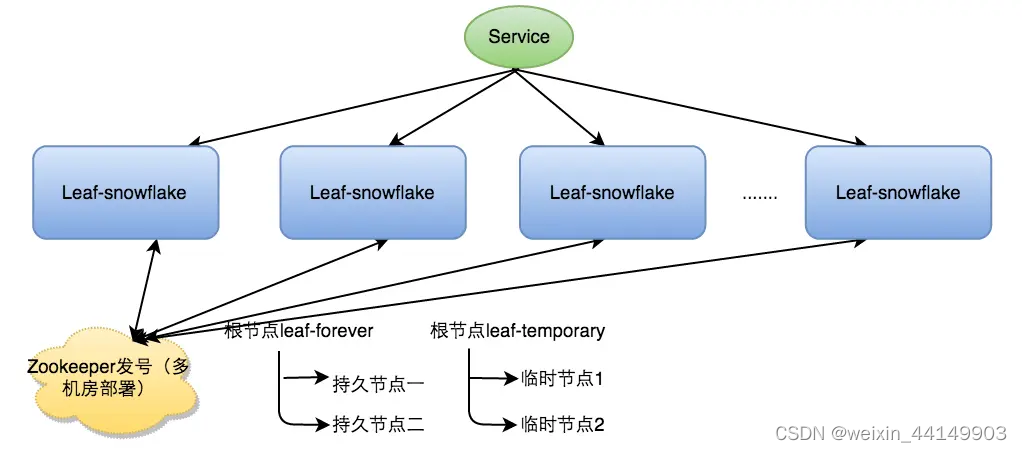
弱依赖 ZooKeeper
除了每次会去 ZK 拿数据以外,也会在本机文件系统上缓存一个 workerID 文件。当 ZooKeeper 出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了 SLA
启动Leaf-snowflake模式也比较简单,启动本地ZooKeeper,修改一下项目中的leaf.properties文件,关闭leaf.segment模式,启用leaf.snowflake模式即可。
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=false
leaf.snowflake.enable=true
leaf.snowflake.zk.address=127.0.0.1
leaf.snowflake.port=2181
注意:在启动项目之前,请保证已经正常启动zookeeper
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的 ID 号,需要解决时钟回退的问题。
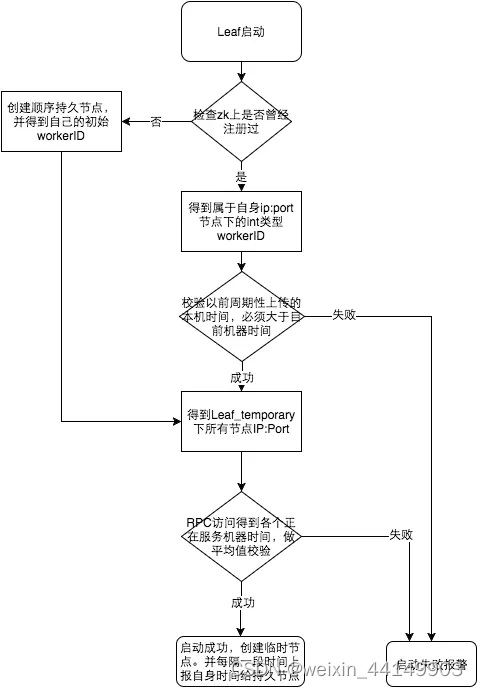
参见上图整个启动流程图,服务启动时首先检查自己是否写过 ZooKeeper leaf_forever 节点:
若写过,则用自身系统时间与 leaf_forever/ s e l f 节点记录时间做比较,若小于 l e a f f o r e v e r / {self} 节点记录时间做比较,若小于 leaf_forever/ self节点记录时间做比较,若小于leafforever/{self} 时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
若未写过,证明是新服务节点,直接创建持久节点 leaf_forever/${self} 并写入自身系统时间,接下来综合对比其余 Leaf 节点的系统时间来判断自身系统时间是否准确,具体做法是取 leaf_temporary 下的所有临时节点 (所有运行中的 Leaf-snowflake 节点) 的服务 IP:Port,然后通过 RPC 请求得到所有节点的系统时间,计算 sum (time)/nodeSize。
若 abs (系统时间 - sum (time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点 leaf_temporary/${self} 维持租约。
否则认为本机系统时间发生大步长偏移,启动失败并报警。
每隔一段时间 (3s) 上报自身系统时间写入 leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时 NTP 同步也会造成秒级别的回退,建议可以直接关闭 NTP 同步。要么在时钟回拨的时候直接不提供服务直接返回 ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try { //时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) { //还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else { //throw
throwClockBackwardsEx(timestamp);
}
} //分配ID
从上线情况来看,在 2017 年闰秒出现那一次出现过部分机器回拨,由于 Leaf-snowflake 的策略保证,成功避免了对业务造成的影响。