[362页]
1、 verify_area函数给其他文件使用的,跳转开始位置;
2、 copy_mem函数复制内存页表;
3、 copy_process函数是fork.c主要函数;
4、find_empty_process函数就2个作用:在一个范围内找last_pid和找空槽;
^ _ ^大神说简单的哈。Fork is rather simple
8-9 fork.c程序
8-9-1 功能描述
fork()系统调用用于创建子进程。Linux中所有进程都是进程0(任务0)的子进程。该进程是sys_fork(在kernel/sys_call.s中从208行开始)系统调用的辅助处理函数集,给出了sys_fork()系统调用中使用的两个C语言函数:find_empty_process()和copy_process()。还包括进程内存区域验证与内存分配函数verify_area()和copy_men()。
copy_process()
copy_process()用于创建并复制进程的代码和数据段以及环境。在进程复制过程中,工作主要牵涉到进程数据结构中信息的位置。
(a)系统首先为新建进程在主内存区中申请一页内存来存放其任务数据结构信息,
并复制当前进程任务数据结构中的所有内容作为新进程任务数据结构的模板。
(b)随后对已复制的任务数据结构内容进行修改。把当前进程设置为新进程的父进程,清除信号位图并复位新进程各统计值。
©接着根据当前进程环境设置新进程任务状态段(TSS)中各寄存器的值。由于创建进程是新进程返回值应为0,所以需要设置tss.eax=0。新建进程内核堆栈指针tss.esp0被设置成新进程任务数据结果所在内存页面的顶端,而堆栈段tss.ss0被设置成内核数据段选择符。tss.ldt被设置为局部描述符在GDT中的索引值。
(d)如果当前进程使用了协处理器,则还需要把协处理器的完整状态保存到新进程的tss.i387结构中。
(e)此后系统设置新任务代码段和数据段的基址和段限长,并复制当前进程内存分页管理的页目录项和页表项。
(f)如果父进程中有文件是打开的,则子进程中相应的文件也是打开着的,因此需要将对应的打开次数增1。
(g)接着在GDT中设置新任务的TSS和LDT描述符项,其中基地址信息指向新进程任务结构中的tss和ldt。
(h)最后再将新任务设置成可运行状态,并向当前进程返回新进程号。
verify_area()
图8-13是内存验证函数verify_area()中验证内存的起始位置和范围调整示意图。因为内存写验证函数write_verify()需要以内存页面为单位(4096字节)进行操作,因此在调用write_verify()之前,需要把验证的起始位置调整为页面起始位置,同时对验证范围作相应调整。
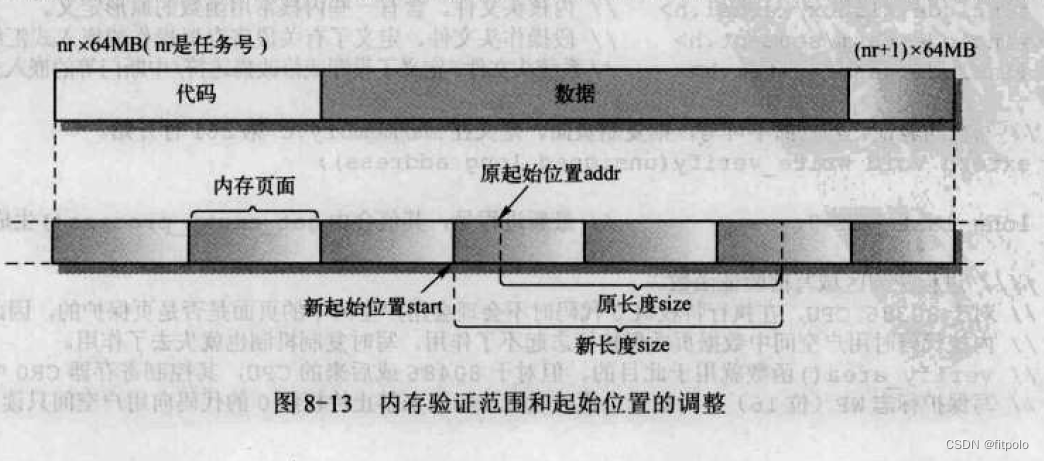
fork.c
上面根据fork.c程序中各函数的功能描述了fork()作用。这里我们从总体上再对其稍加说明。
(a)总的来说fork()首先会为新进程申请一页内存用来复制父进程的任务数据结构(PCB)信息,
(b)然后会为新进程修改复制的任务数据结构的某些字段值,包括利用系统调用中断发生时逐步压入堆栈的寄存器信息(即copy_process()的参数)重新设置任务结构中的TSS结果的各字段值,让新进程的状态保持父进程即将进入中断过程前的状态。
©然后为新进程确定在线性地址空间的起始位(nrX64MB)。
补充:对于CPU的分段机制,Linux0.12的代码段和数据段在线性地址空间中的位置和长度完全相同。
(d)接着系统会为新进程复制父进程的页目录项和页表项。
补充:对于Linux0.12内核来说,所有程序共用一个位于物理内存开始位置处的页目录表,而新进程的页表则需要另外申请一页内存来存放。
在fork()的执行过程中,内核并不会立刻为新进程分配代码和数据内存页。新进程将于父进程共同使用父进程已有的代码和数据内存页面。只有当以后执行过程中如果其中有一个进程以写方式访问内存时被访问的内存页面才会在写操作前被赋值到新申请的内存页面中。
8-9-2 代码注释
头文件和声明
/*
* linux/kernel/fork.c
*
* (C) 1991 Linus Torvalds
*/
/*
* 'fork.c'中含有系统调用'fork'的辅助子程序(参见system_call.s),以及一些
* 其他函数('verify_area')。一旦你了解了fork,就会发现它是非常简单的,但
* 内存管理却有些难度。参见'mm/memory.c'中的'copy_page_tables()'函数。
*/
#include <errno.h>
#include <linux/sched.h>
#include <linux/kernel.h>
#include <asm/segment.h>
#include <asm/system.h>
// 写页面验证。若页面不可写,则复制页面。定义在mm/memory.c 第261行开始。
extern void write_verify(unsigned long address);
long last_pid=0;// 最新进程号,其值会由get_empty_process()生成。
verify_area()
进程空间区域写前验证函数。
// 对于80386 CPU,在执行特权级0代码时不会理会用户空间中的页面是否是页保护的,因此
// 在执行内核代码时用户空间中数据页面保护标志起不了作用,写时复制机制也就失去了作用。
// verify_area()函数就用于此目的。但对于80486或后来的CPU,其控制寄存器CR0中有一个
// 写保护标志WP(位16),内核可以通过设置该标志来禁止特权级0的代码向用户空间只读
// 页面执行写数据,否则将导致发生写保护异常。从而486以上CPU可以通过设置该标志来达
// 到使用本函数同样的目的。
// 该函数对当前进程逻辑地址从 addr 到 addr + size 这一段范围以页为单位执行写操作前
// 的检测操作。由于检测判断是以页面为单位进行操作,因此程序首先需要找出addr所在页
// 面开始地址start,然后 start加上进程数据段基址,使这个start变换成CPU 4G线性空
// 间中的地址。最后循环调用write_verify() 对指定大小的内存空间进行写前验证。若页面
// 是只读的,则执行共享检验和复制页面操作(写时复制)
void verify_area(void * addr,int size)
{
unsigned long start;
// 首先将起始地址start调整为其所在页的左边界开始位置,同时相应地调整验证区域大小。
// 下句中的 start & 0xfff 用来获得指定起始位置addr(也即start)在所在页面中的偏移
// 值,原验证范围 size 加上这个偏移值即扩展成以 addr 所在页面起始位置开始的范围值。
// 因此在 30行上 也需要把验证开始位置 start 调整成页面边界值。参见前面的图“内存验
// 证范围的调整”。
start = (unsigned long) addr;
size += start & 0xfff;
start &= 0xfffff000;
// 下面把 start 加上进程数据段在线性地址空间中的起始基址,变成系统整个线性空间中的地
// 址位置。对于Linux 0.1x内核,其数据段和代码段在线性地址空间中的基址和限长均相同。
// 然后循环进行写页面验证。若页面不可写,则复制页面。(mm/memory.c,274行)
start += get_base(current->ldt[2]);// include/linux/sched.h,277行。
while (size>0) {
size -= 4096;
write_verify(start);
start += 4096;
}
}
copy_mem()
// 复制内存页表。
// 参数nr是新任务号;p是新任务数据结构指针。该函数为新任务在线性地址空间中设置代码
// 段和数据段基址、限长,并复制页表。 由于Linux系统采用了写时复制(copy on write)
// 技术, 因此这里仅为新进程设置自己的页目录表项和页表项,而没有实际为新进程分配物理
// 内存页面。此时新进程与其父进程共享所有内存页面。操作成功返回0,否则返回出错号。
int copy_mem(int nr,struct task_struct * p)
{
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
// 首先取当前进程局部描述符表中代码段描述符和数据段描述符项中的段限长(字节数)。
// 0x0f是代码段选择符;0x17是数据段选择符。然后取当前进程代码段和数据段在线性地址
// 空间中的基地址。由于Linux 0.12内核还不支持代码和数据段分立的情况,因此这里需要
// 检查代码段和数据段基址是否都相同,并且要求数据段的长度至少不小于代码段的长度
// (参见图5-12),否则内核显示出错信息,并停止运行。
// get_limit()和get_base()定义在include/linux/sched.h第277行和279行处。
code_limit=get_limit(0x0f);
data_limit=get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
// 然后设置创建中的新进程在线性地址空间中的基地址等于(64MB * 其任务号),并用该值
// 设置新进程局部描述符表中段描述符中的基地址。接着设置新进程的页目录表项和页表项,
// 即复制当前进程(父进程)的页目录表项和页表项。 此时子进程共享父进程的内存页面。
// 正常情况下copy_page_tables()返回0,否则表示出错,则释放刚申请的页表项。
new_data_base = new_code_base = nr * TASK_SIZE;
p->start_code = new_code_base;
set_base(p->ldt[1],new_code_base);
set_base(p->ldt[2],new_data_base);
if (copy_page_tables(old_data_base,new_data_base,data_limit)) {
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
}
return 0;
}
copy_process()
/*
* OK,下面是主要的fork子程序。它复制系统进程信息(task[n])
* 并且设置必要的寄存器。它还整个地复制数据段(也是代码段)。
*/
// 复制进程。
// 该函数的参数是进入系统调用中断处理过程(sys_call.s)开始,直到调用本系统调用处理
// 过程(sys_call.s第208行)和调用本函数前(sys_call.s第217行)逐步压入进程内核
// 态栈的各寄存器的值。这些在sys_call.s程序中逐步压入内核态栈的值(参数)包括:
// ① CPU执行中断指令压入的用户栈地址ss和esp、标志eflags和返回地址cs和eip;
// ② 第83--88行在刚进入system_call时入栈的段寄存器ds、es、fs和edx、ecx、edx;
// ③ 第94行调用sys_call_table中sys_fork函数时入栈的返回地址(参数none表示);
// ④ 第212--216行在调用copy_process()之前入栈的gs、esi、edi、ebp和eax(nr)。
// 其中参数nr是调用find_empty_process()分配的任务数组项号。
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx, long orig_eax,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
// 首先为新任务数据结构分配内存。如果内存分配出错,则返回出错码并退出。然后将新任务
// 结构指针放入任务数组的nr项中。其中nr为任务号,由前面find_empty_process()返回。
// 接着把当前进程任务结构内容复制到刚申请到的内存页面p开始处。
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
// 随后对复制来的进程结构内容进行一些修改,作为新进程的任务结构。先将新进程的状态
// 置为不可中断等待状态,以防止内核调度其执行。然后设置新进程的进程号pid,并初始
// 化进程运行时间片值等于其 priority值( 一般为15个嘀嗒)。接着复位新进程的信号
// 位图、报警定时值、会话(session)领导标志 leader、 进程及其子进程在内核和用户
// 态运行时间统计值,还设置进程开始运行的系统时间start_time。
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;// 新进程号。也由find_empty_process()得到。
p->counter = p->priority;// 运行时间片值(嘀嗒数)。
p->signal = 0;// 信号位图。
p->alarm = 0;// 报警定时值(嘀嗒数)。
p->leader = 0; /* 进程的领导权是不能继承的 */
p->utime = p->stime = 0;// 用户态时间和核心态运行时间。
p->cutime = p->cstime = 0;// 子进程用户态和核心态运行时间。
p->start_time = jiffies;// 进程开始运行时间(当前时间滴答数)。
// 再修改任务状态段TSS 数据(参见列表后说明)。由于系统给任务结构 p分配了1页新
// 内存,所以 (PAGE_SIZE + (long) p) 让esp0正好指向该页顶端。 ss0:esp0 用作程序
// 在内核态执行时的栈。另外,在第3章中我们已经知道,每个任务在 GDT表中都有两个
// 段描述符,一个是任务的TSS段描述符,另一个是任务的LDT表段描述符。下面111行
// 语句就是把GDT中本任务LDT段描述符的选择符保存在本任务的TSS段中。当CPU执行
// 切换任务时,会自动从TSS中把LDT段描述符的选择符加载到ldtr寄存器中。
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;// 任务内核态栈指针。
p->tss.ss0 = 0x10;// 内核态栈的段选择符(与内核数据段相同)。
p->tss.eip = eip;// 指令代码指针。
p->tss.eflags = eflags;// 标志寄存器。
p->tss.eax = 0;// 这是当fork()返回时新进程会返回0的原因所在。
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff;// 段寄存器仅16位有效。
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr);// 任务局部表描述符的选择符(LDT描述符在GDT中)。
p->tss.trace_bitmap = 0x80000000;//(高16位有效)。
// 如果当前任务使用了协处理器,就保存其上下文。汇编指令clts用于清除控制寄存器CR0
// 中的任务已交换(TS)标志。每当发生任务切换,CPU都会设置该标志。该标志用于管理
// 数学协处理器:如果该标志置位,那么每个ESC指令都会被捕获(异常7)。如果协处理
// 器存在标志MP也同时置位的话,那么WAIT指令也会捕获。因此,如果任务切换发生在一
// 个ESC指令开始执行之后,则协处理器中的内容就可能需要在执行新的ESC指令之前保存
// 起来。捕获处理句柄会保存协处理器的内容并复位TS标志。指令fnsave用于把协处理器
// 的所有状态保存到目的操作数指定的内存区域中(tss.i387)。
if (last_task_used_math == current)
__asm__("clts ; fnsave %0 ; frstor %0"::"m" (p->tss.i387));
// 接下来复制进程页表。即在线性地址空间中设置新任务代码段和数据段描述符中的基址
// 和限长,并复制页表。如果出错(返回值不是0),则复位任务数组中相应项并释放为
// 该新任务分配的用于任务结构的内存页。
if (copy_mem(nr,p)) {
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
// 如果父进程中有文件是打开的,则将对应文件的打开次数增1。因为这里创建的子进程
// 会与父进程共享这些打开的文件。将当前进程(父进程)的pwd, root和executable
// 引用次数均增1。与上面同样的道理,子进程也引用了这些i节点。
for (i=0; i<NR_OPEN;i++)
if (f=p->filp[i])
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
if (current->library)
current->library->i_count++;
// 随后在GDT表中设置新任务TSS段和LDT段描述符项。这两个段的限长均被设置成104
// 字节。参见 include/asm/system.h,52—66 行代码。 然后设置进程之间的关系链表
// 指针,即把新进程插入到当前进程的子进程链表中。把新进程的父进程设置为当前进程,
// 把新进程的最新子进程指针p_cptr 和年轻兄弟进程指针p_ysptr置空。接着让新进程
// 的老兄进程指针p_osptr设置等于父进程的最新子进程指针。若当前进程却是还有其他
// 子进程,则让比邻老兄进程的最年轻进程指针p_yspter 指向新进程。最后把当前进程
// 的最新子进程指针指向这个新进程。然后把新进程设置成就绪态。最后返回新进程号。
// 另外, set_tss_desc() 和 set_ldt_desc() 定义在 include/asm/system.h 文件中。
// “gdt+(nr<<1)+FIRST_TSS_ENTRY”是任务nr的TSS描述符项在全局表中的地址。因为
// 每个任务占用GDT表中2项,因此上式中要包括'(nr<<1)'。
// 请注意,在任务切换时,任务寄存器tr会由CPU自动加载。
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->p_pptr = current;// 设置新进程的父进程指针。
p->p_cptr = 0;// 复位新进程的最新子进程指针。
p->p_ysptr = 0;// 复位新进程的比邻年轻兄弟进程指针。
p->p_osptr = current->p_cptr;// 设置新进程的比邻老兄兄弟进程指针。
if (p->p_osptr)// 若新进程有老兄兄弟进程,则让其
p->p_osptr->p_ysptr = p;// 年轻进程兄弟指针指向新进程。
current->p_cptr = p;// 让当前进程最新子进程指针指向新进程。
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid;
}
find_empty_process()
// 为新进程取得不重复的进程号last_pid。函数返回在任务数组中的任务号(数组项)。
int find_empty_process(void)
{
int i;
// 首先获取新的进程号。如果last_pid增1后超出进程号的正数表示范围,则重新从1开始
// 使用pid号。 然后在任务数组中搜索刚设置的pid号是否已经被任何任务使用。如果是则
// 跳转到函数开始处重新获得一个pid号。 接着在任务数组中为新任务寻找一个空闲项,并
// 返回项号。 last_pid是一个全局变量,不用返回。如果此时任务数组中64个项已经被全
// 部占用,则返回出错码。
repeat:
if ((++last_pid)<0) last_pid=1;
for(i=0 ; i<NR_TASKS ; i++)
if (task[i] && ((task[i]->pid == last_pid) ||
(task[i]->pgrp == last_pid)))
goto repeat;
for(i=1 ; i<NR_TASKS ; i++) // 任务0项被排除在外。
if (!task[i])
return i;
return -EAGAIN;
}
8-9-3 任务状态段信息

struct tss_struct {
long back_link; /* 16 high bits zero */
long esp0;
long ss0; /* 16 high bits zero */
long esp1;
long ss1; /* 16 high bits zero */
long esp2;
long ss2; /* 16 high bits zero */
long cr3;
long eip;
long eflags;
long eax,ecx,edx,ebx;
long esp;
long ebp;
long esi;
long edi;
long es; /* 16 high bits zero */
long cs; /* 16 high bits zero */
long ss; /* 16 high bits zero */
long ds; /* 16 high bits zero */
long fs; /* 16 high bits zero */
long gs; /* 16 high bits zero */
long ldt; /* 16 high bits zero */
long trace_bitmap; /* bits: trace 0, bitmap 16-31 */
struct i387_struct i387;
};
TSS中的字段可以分为两类:
第1类是会在CPU进行任务切换时动态更新的信息集。这些字段有:通用寄存器(EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI)、段寄存器(ES,CS,SS,DS,FS,GS)、标志寄存器(EFLAGS)、指令指针(EIP)、前一个执行任务的TSS的 选择符(仅当返回时才更新)。
第2类字段是CPU会读取但不会更改的静态信息集。这些字段有:任务的LDT的选择符、含有任务页目录基地址的寄存器(PDBR)、特权级0~2的堆栈指针、当任务进行切换时导致CPU产生一个调试(debug)异常的T-位(调试跟踪位)、I/O位图基地址(其长度上限就是TSS的长度上限,在TSS描述符中说明)。
任务状态段可以存放在线性空间的任何地方。与其他各类段相似,任务状态段也是由描述符来定义的。当前正在执行任务的TSS是由任务寄存器(TR)来指示的。指令LTR和STR用来修改和读取任务寄存器中的选择符(任务寄存器的课件部分)。
I/O位图中的每1位对应1个I/O端口。比如端口41的位就是I/O位图基地址+5,位偏移1处。在保护模式中,当遇到1个I/O指令时(IN,INS,OUT,OUTS),CPU首先就会检查当前特权级是否小于标志寄存器的IOPL,如果这个条件满足,就执行该I/O操作。如果不满足,那么CPU就会检查TSS中的I/O位图。如果相应位是置位的,就会产生一般保护性异常,否则就会执行该I/O操作。
如果I/O位图基地址被设置成大于或等于TSS段限长,则表示该TSS段没有I/O许可位图,那么对于所有当前特权层CPL>IOPL的I/O指令均会导致发生异常保护。在默认情况下,Linux0.12 内核中把I/O位图基地址设置成了0x8000,显然大于TSS段限长104字节,因此Linux0.12内核中没有I/O许可位图。
在Linux0.12中,图中SS0:ESP0用于存放任务在内核态运行时的堆栈指针。SS1:ESP1和SS2:ESP2分别对应运行与特权级1和2时使用的堆栈指针,这两个特权级在Linux中没有使用。而任务工作于用户态时堆栈指针则保存在SS:ESP寄存器中。由上所述可知,每当任务进入内核态执行时,其内核态堆栈指针初始位置不变,均为任务数据结构所在页面的顶端位置处。