卷积切分图片
test1.py
import torch
from torch import nn
"""
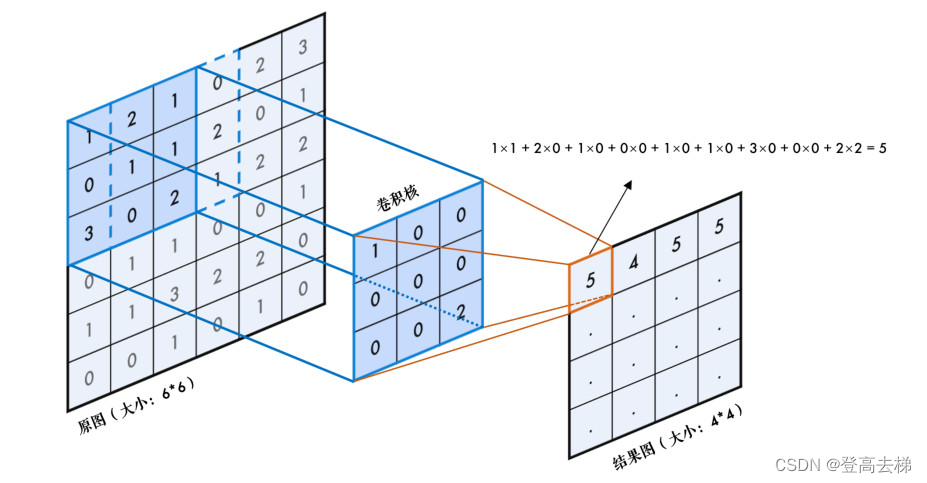
卷积对输入的图片有没有尺寸的要求?
就是 输入的图片尺寸 必须大于 卷积核的大小
"""
class Net(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(3, 12, 3),
nn.ReLU(),
nn.Conv2d(12, 32, 3),
nn.ReLU(),
nn.Conv2d(32, 56, 3),
nn.ReLU(),
nn.Conv2d(56, 128, 3),
nn.ReLU(),
nn.Conv2d(128, 256, 3)
)
def forward(self, x):
return self.layer(x)
if __name__ == '__main__':
net = Net()
x1 = torch.randn(1, 3, 32, 32)
y1 = net(x1)
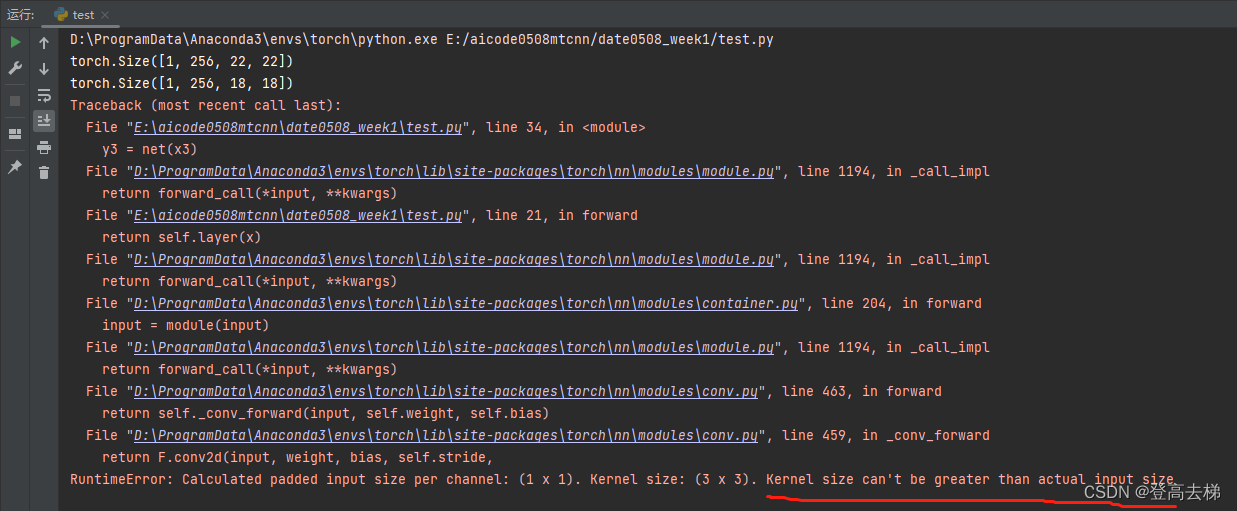
print(y1.shape)
x2 = torch.randn(1, 3, 28, 28)
y2 = net(x2)
print(y2.shape)
x3 = torch.randn(1, 3, 5, 5)
y3 = net(x3)
print(y2.shape)
- 虽然 图片变小 了,但是 通道数 增加 了
- 卷积运算 把图片的特征 保留到 通道上面,有 多少个通道,就有 多少个特征
是通过 通道 来区分特征,而不是通过 图片的h.w 来区分特征
test2.py
import torch
from torch import nn
"""
输入的图片 和 特征图 的 信息 没有区别
前提是 卷积核的个数 不能太少,一个卷积核 只能 提取 一种特征 (卷积核 太少,可能会 丢失信息)
"""
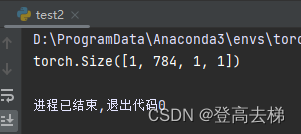
x = torch.randn(1,1,28,28)
layer = nn.Conv2d(1,784,28)
y = layer(x)
print(y.shape)
784个通道 1*1的特征图
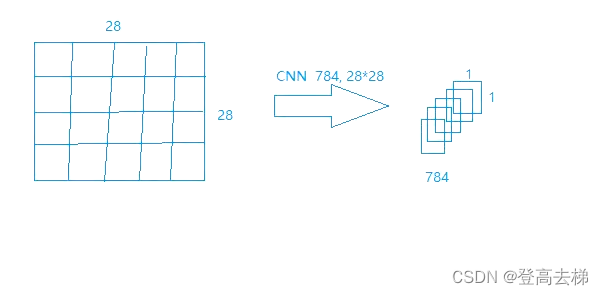
-
输入的图片 和 特征图 的 信息 没有区别
- 前提是 卷积核的个数 不能太少,一个卷积核 只能 提取 一种特征 (卷积核 太少,可能会 丢失信息)
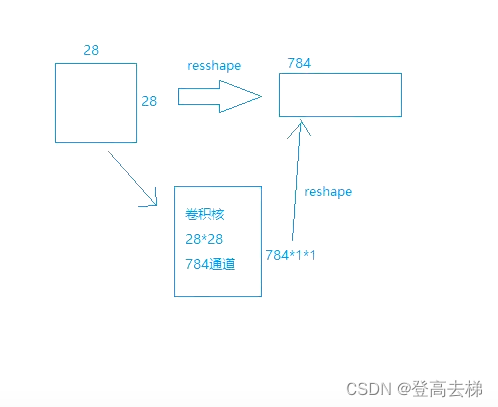
- 前提是 卷积核的个数 不能太少,一个卷积核 只能 提取 一种特征 (卷积核 太少,可能会 丢失信息)

-
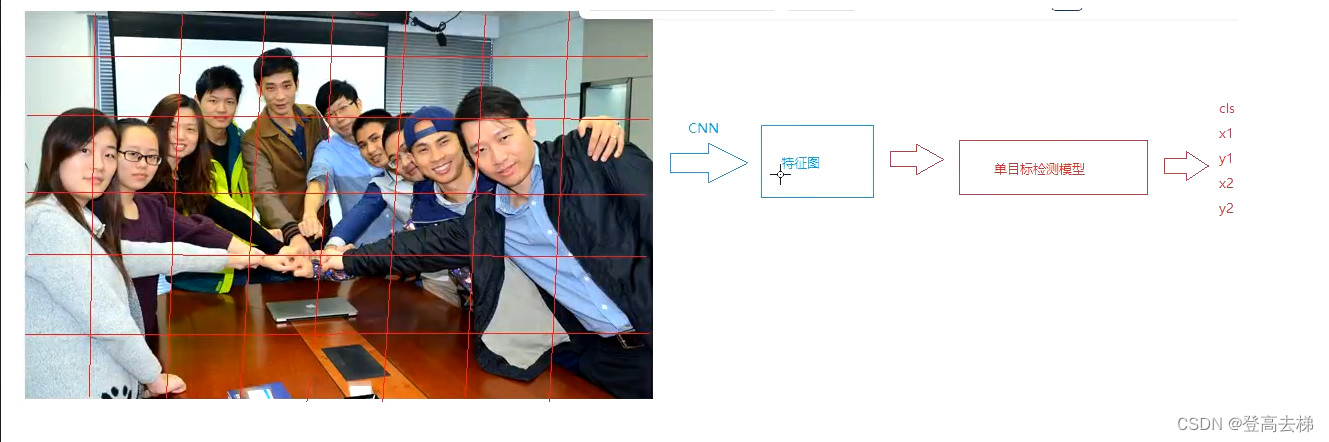
图片切分:
- 把图片 切分成 一个一个区域,按一定的 步长 进行分割,把每一个区域 传到 单目标检测模型 中,这就相当于 卷积的 运算过程,切分的格子的大小 就是 卷积核的大小,用卷积 来代替 切分的过程。
- 把 原图 输入到模型中 去检测,转变为 把 卷积运算后的特征图 输入到模型 去检测,
- 前提是 原图 和 特征图 的 信息量 要 对等
- 如果 信息量 要对等的话,需要 增加卷积核的个数
- 图片上面的信息 可以放到 特征图的通道 上面
全卷积结构 - 1
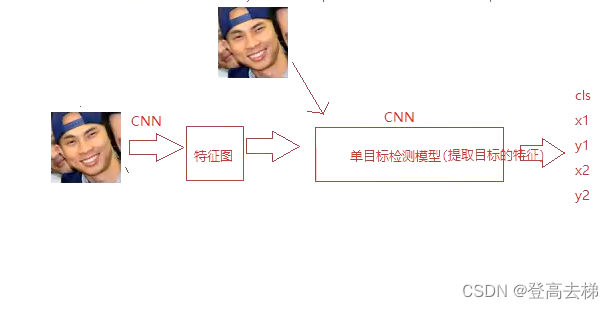
test3.py
import torch
import torch.nn as nn
"""
能否把两个卷积合并成一个卷积?
卷积分解
"""
conv = nn.Conv2d(1,1,5)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(1,1,3),
nn.ReLU(),
nn.Conv2d(1,1,3)
)
def forward(self,x):
return self.layer(x)
if __name__== "__main__":
x = torch.randn(1,1,15,15)
net = Net()
out1 = conv(x)
out2 = net(x)
print(out1.shape)
print(out2.shape)

1个5 * 5 的卷积,等价于两个3 * 3 的卷积
用一个模型 来代替 一层卷积 (如:模型里有两个3 * 3 的卷积,一层卷积是 1个5 * 5 的卷积)
- 我们可以用一个卷积 来代替 多个卷积
- 把两个卷积 合成 一个卷积,这个卷积 即做 图片切分 又做 特征提取
- 即做 图片切分,又做 单目标检测
- 用一个模型 来代替 一层卷积


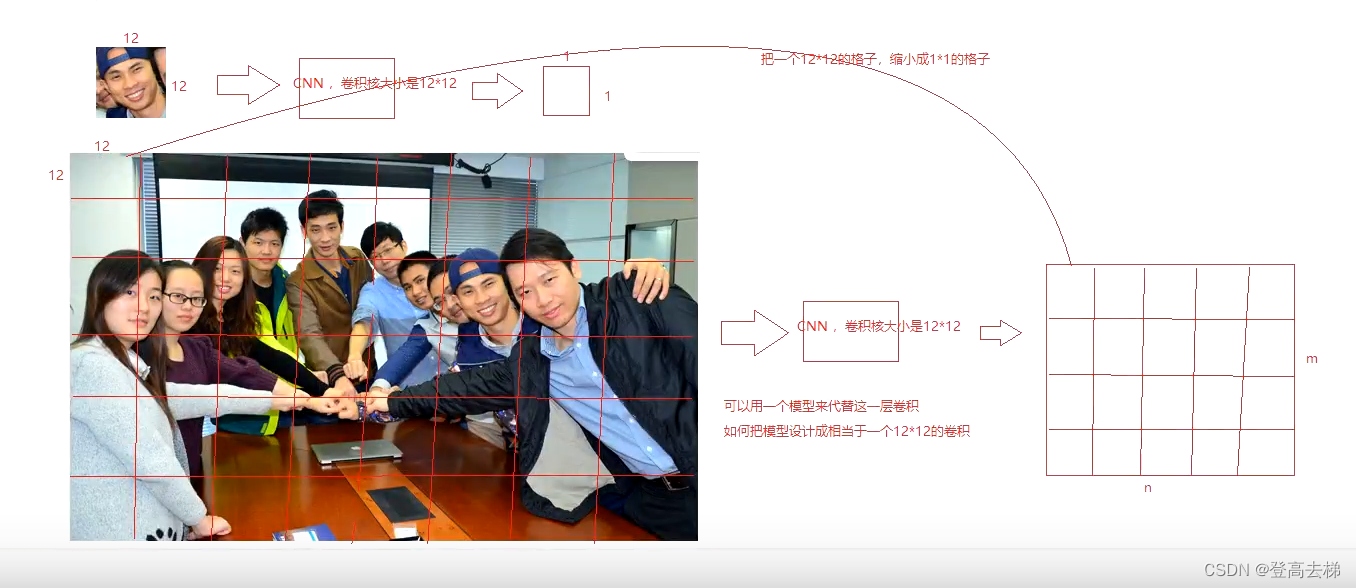
- 可以用 一个模型 来代替这 一层卷积
- 如何把 模型 设计成 相当于 一个12 * 12 的卷积
- 把一个 12 * 12 的格子,缩小成 1 * 1 的格子
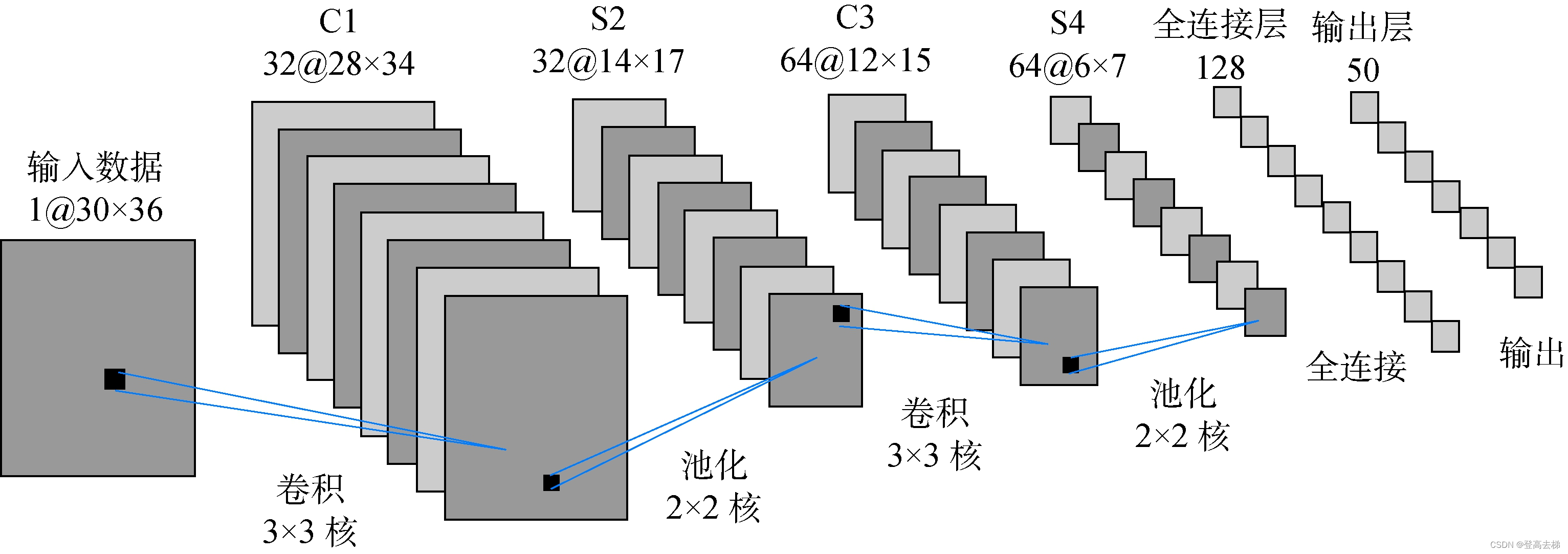
- 因为要把 所有的通道 合成 一个通道,特征融合,使用 全连结 来做 特征融合
test4.py
import torch
import torch.nn as nn
"""
能不能用 卷积 来做 特征融合?
"""
x = torch.randn(1,32,4,4)
x1 = x.reshape(-1,32*4*4)
net1 = nn.Linear(32*4*4,5) #
y1 = net1(x1)
print(y1.shape)
#print(y1)
print("---------------")
net2 = nn.Conv2d(32,5,4) #
y2 = net2(x)
print(y2.shape)
#print(y2)
-
我们可以 把特征 放到通道 上面,让模型 通过通道 直接输出
如果 模型有 全连结层,那么模型的 输入 就 定死了
如果 模型是 全卷积结构,那么模型的 输入 就 不会定死 -
全卷积结构,理论上可以 输入 任意大小 的图片
前提是 输入的图片 的尺寸 大于 卷积核的大小

总结
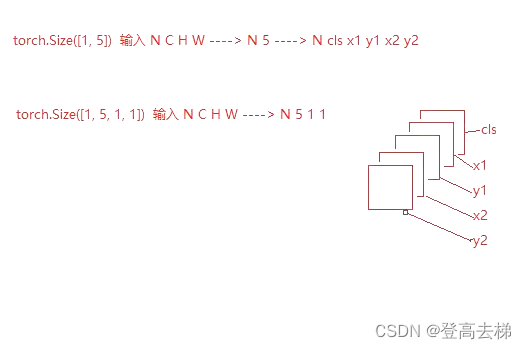
我们用一个 单目标检测网络 实现 输入任意大小 的图片,对图片按照 固定的大小 切
分,切分完了之后,传入模型里面,模型输出 5个通道,这个 5个通道 分别代表
cls,x1,y1,x2,y2,用 一个模型 就把这些 所有的事 做完了

全卷积结构 - 2

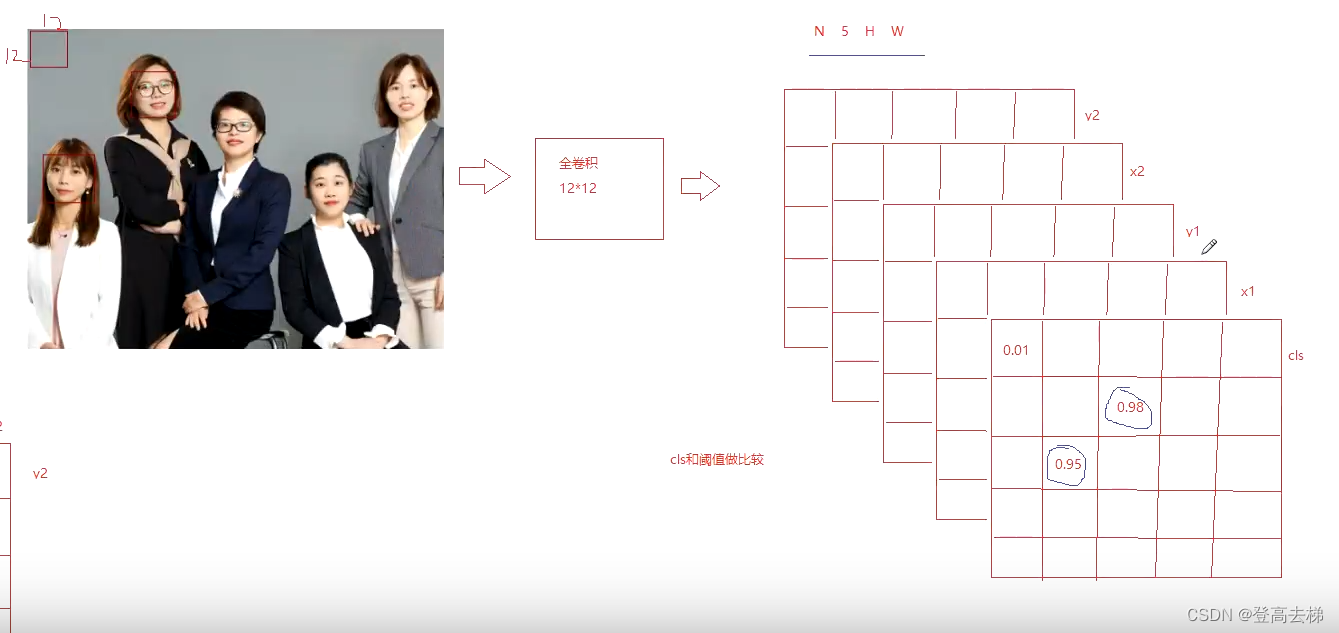
- 我们做 多目标检测 通过 单目标检测网络 来实现的,但是,我们 没有使用 opencv ,PIL 来 切图,使用 卷积 来达到 切图 的效果,
把切出来 的图片 输入到模型 里面,然后 输出结果,做 统计
全卷积结构 实现输入 任意尺寸 的图片
- 我们提出了 全卷积结构,输入 任意尺寸 的图片,输出的 H,W 是 任意 的
为什么输入 任意大小 的图片?
- 因为人脸的 个数 和 人脸的 尺寸 是 不固定 的
- 有 多少个 人脸,可以通过 H * W 的格子 统计 出来
- 人脸的 个数,就放在了 H和W 的维度上面
整个过程的 难点 在于 全卷积 的设计
- 将图片上面 12 * 12 的区域 转化 为 5 * 1 * 1 的格子
- 转化 的过程 就在做 特征提取
- 如果有 多个人脸,输入的尺寸 不受 限制,保证了 输出 不受 限制
全卷积结构 实现 多目标检测
- 输出 的 结果 就是 切分 的 结果
- 我们就使用 全卷积结构 来 实现 了 多目标检测
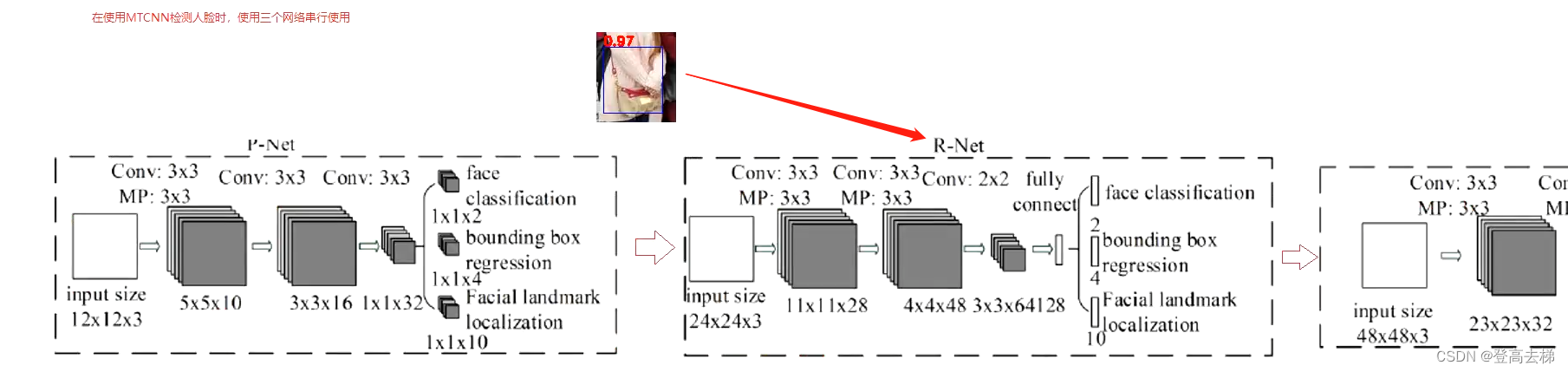
在使用 MTCNN 检测人脸 时, 三个网络 串行 使用
- p网络 是一个 全卷积结构,相当于一个 12 * 12 的 卷积核
对 海量数据 进行 筛选
大概 判断 哪些地方 有人脸,哪些地方 没人脸 (宁选错,勿放过 )
p网络 侧重 在于 速度
- 多目标 检测任务,目标个数 是 不固定 的
输出 肯定是 不固定 的,那么 输入 就 不固定 的
MTCNN 可以 接受 任意尺寸 的 图片
MTCNN网络

P R O 三个网络都 可以 看成 一个 单目标检测网络,它们 做的事情 都是一样的
为什么 三个网络 输入的尺寸 越来越大?
- 因为 我们希望 R和O网络 的 精度 比 P网络 高
那么要 网络 更深 更大,还要 输入的 信息量 更多
为什么R O 网络最后面是一个 全连结? 为什么不把三个网络都设计成 全卷积结构?
能不能把全连结换成卷积?
可以
为什么没用?
-
用全连结 意味着 R和O的输入 定死了
-
因为R和O在 输入 之前, 人脸的个数 已经确定了
传给 R和O 的区域 只有 两种结果,要么有 一个人脸,要么 没有人脸,所以 输出 就 定死 了。
那么就可以用 全连结
R和O 完全可以看 一个单目标检测网络
分析:
输入给R网络的 就是P网络 框出来的部分
P网络 检测后 效果图
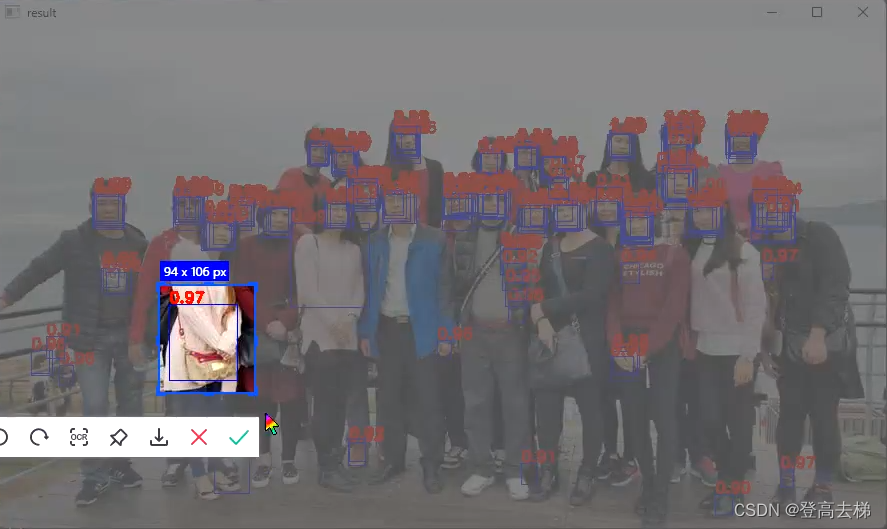
R网络就是 一个单目标侦测,侦测 这个区域 有没有人脸
P R O输入的尺寸分布是 12 24 48
网络的输入 都是 正方形
因为MTCNN是 专门为人脸 而生的,专门 做人脸检测的。人脸刚好接近于 一个正方形 ,所以这三个网络 输入都是 正方形。所以 用MTCNN 一般都是 做人脸检测的

经过P网络后 输出结果 :

经过P网络 经过R网络后 输出结果 :

经过P网络 经过R网络后 经过O网络 输出结果 :