作者 | 智商掉了一地
近日有很多团队基于用户友好的 ChatGPT 进行再创作,其中不乏有比较亮眼的成果。InternChat工作强调了用户友好性,这是通过超越语言的方式(光标与手势)与聊天机器人交互来进行多模态任务的。InternChat 的命名也比较有趣,代表着互动(interaction)、非语言(nonverbal)和聊天机器人(chatbots),可以简称为iChat。与现有依赖纯语言的交互系统不同,iChat 通过加入指向指令,显著提高用户与聊天机器人之间的交流效率。此外,作者还提供了一个名为哈士奇(Husky)的大型视觉语言模型,可以进行 capture 和视觉问答,在仅用 70 亿参数的情况下,也能给 GPT-3.5-turbo 留下深刻印象。
各个大模型的研究测试传送门
阿里通义千问传送门:
https://tongyi.aliyun.com
百度文心一言传送门:
https://yiyan.baidu.com
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇到浏览器警告点高级/继续访问即可):
https://gpt4test.com
不过由于 Demo 网站过于火爆,团队官方暂时关停了体验页面,咱们先通过下面这个视频来了解这项工作内容吧~
【麻烦排版同学注意:插入那个演示视频】
论文题目:
InternChat: Solving Vision-Centric Tasks by Interacting with Chatbots Beyond Language
论文链接:
https://arxiv.org/abs/2305.05662
Demo 地址:
https://ichat.opengvlab.com/
项目地址:
https://github.com/OpenGVLab/InternChat/
系统主要特点
作者在项目首页上提供了一些任务截图,可以直观地看到这个交互系统的一些功能与效果:
(a)移除遮盖的对象

(b)交互式图像编辑
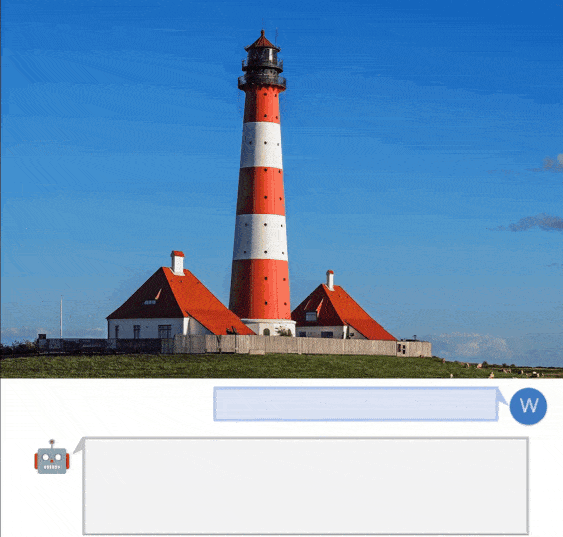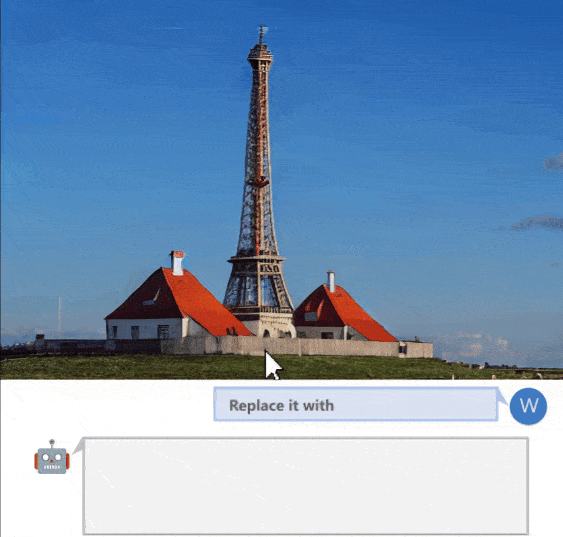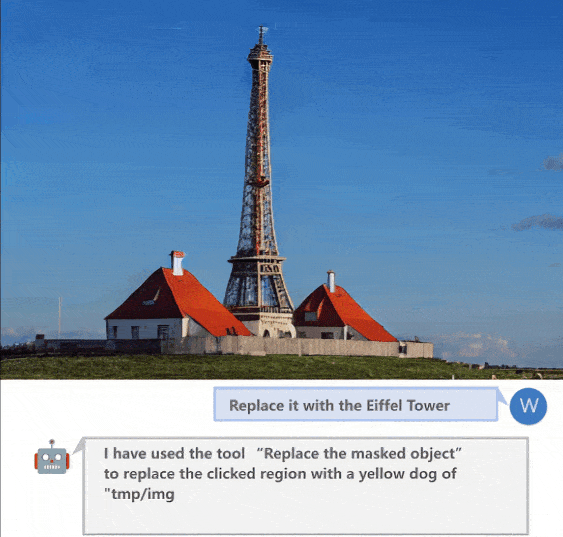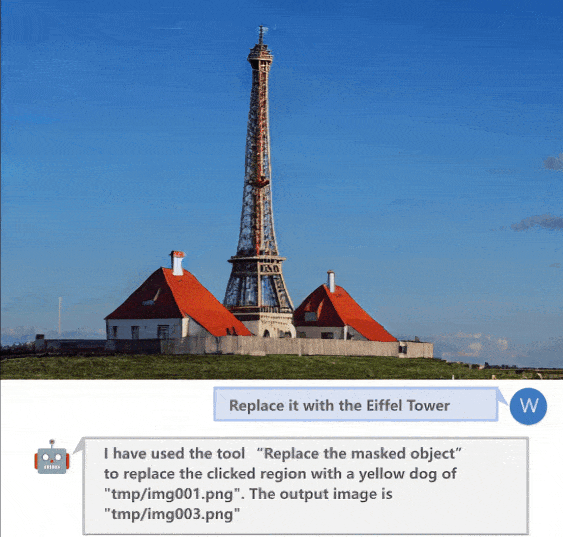
(c)图像生成

(d)交互式视觉问答

(e)交互式图像生成
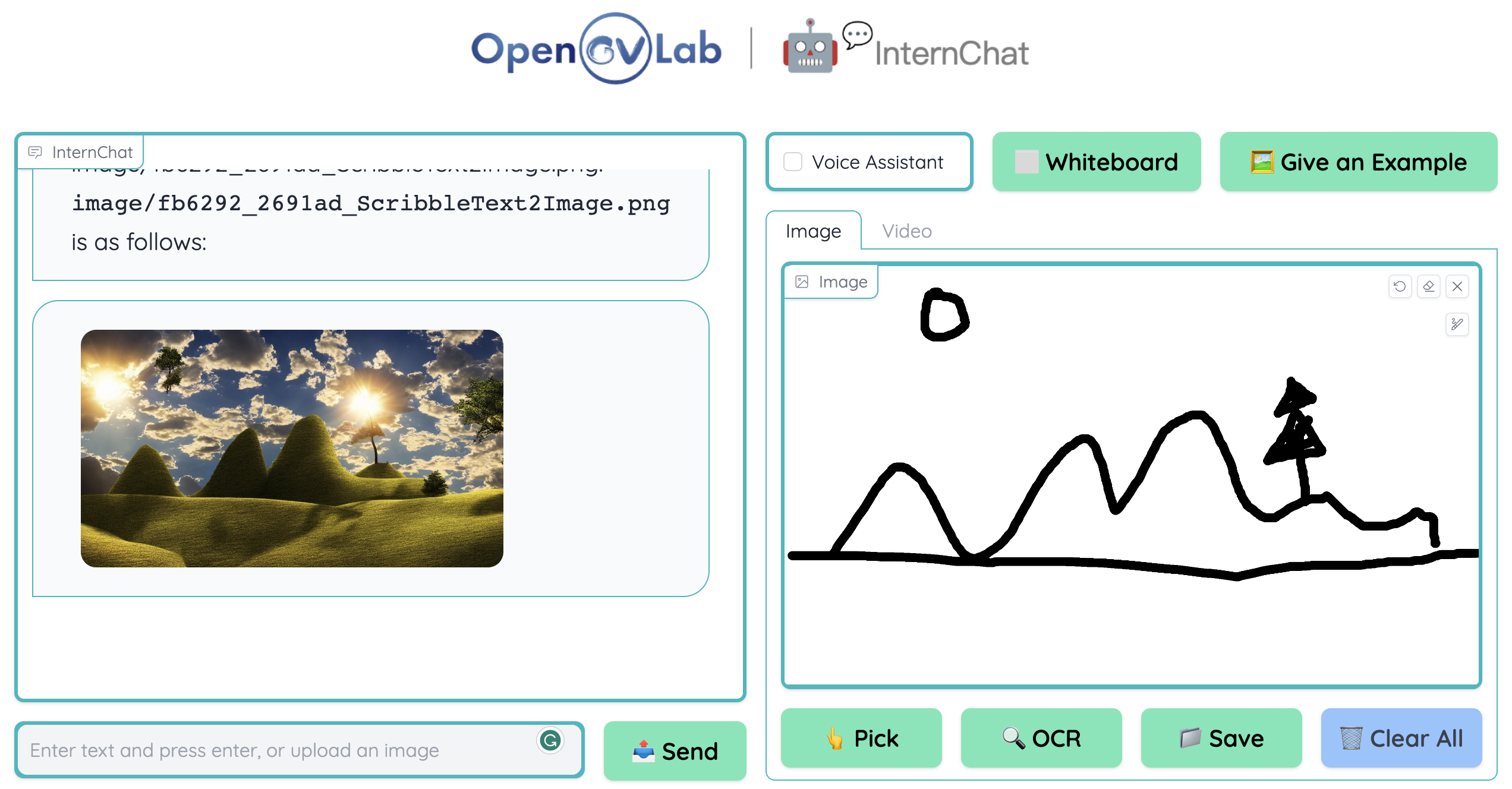
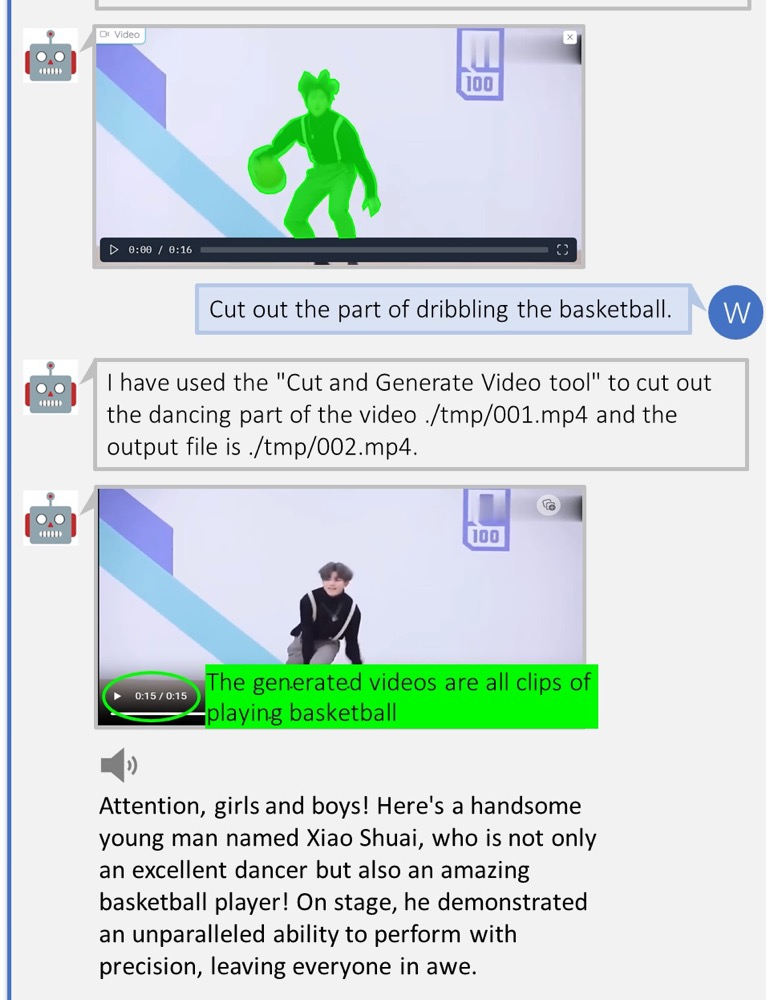
(f)视频高光解释
论文速览
这里首先介绍本文中提及的两个概念:
-
以视觉为中心的任务:为了让计算机能够理解它们从世界中看到的内容并做出相应反应。 -
非语言指令形式的交流:光标和手势之类的指向动作。
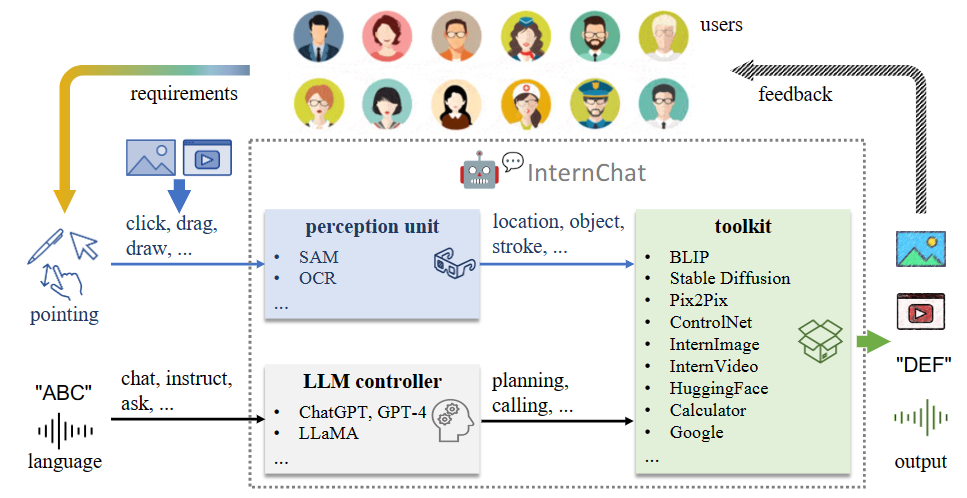
iChat 结合指向和语言指令的优势来执行以视觉为中心的任务。如图 1 所示,这个系统由 3 个主要组件组成:
-
处理图像或视频上指向指令的感知单元; -
具有可以准确解析语言指令的辅助控制机制的 LLM 控制器; -
集成 HuggingFace 各种在线模型、用户训练的私人模型以及其他应用(如计算器、搜索引擎)的开放世界工具包。
它可以在 3 个层级上有效运行,分别是:
-
基础交互; -
语言引导的交互; -
指向-语言增强的交互。
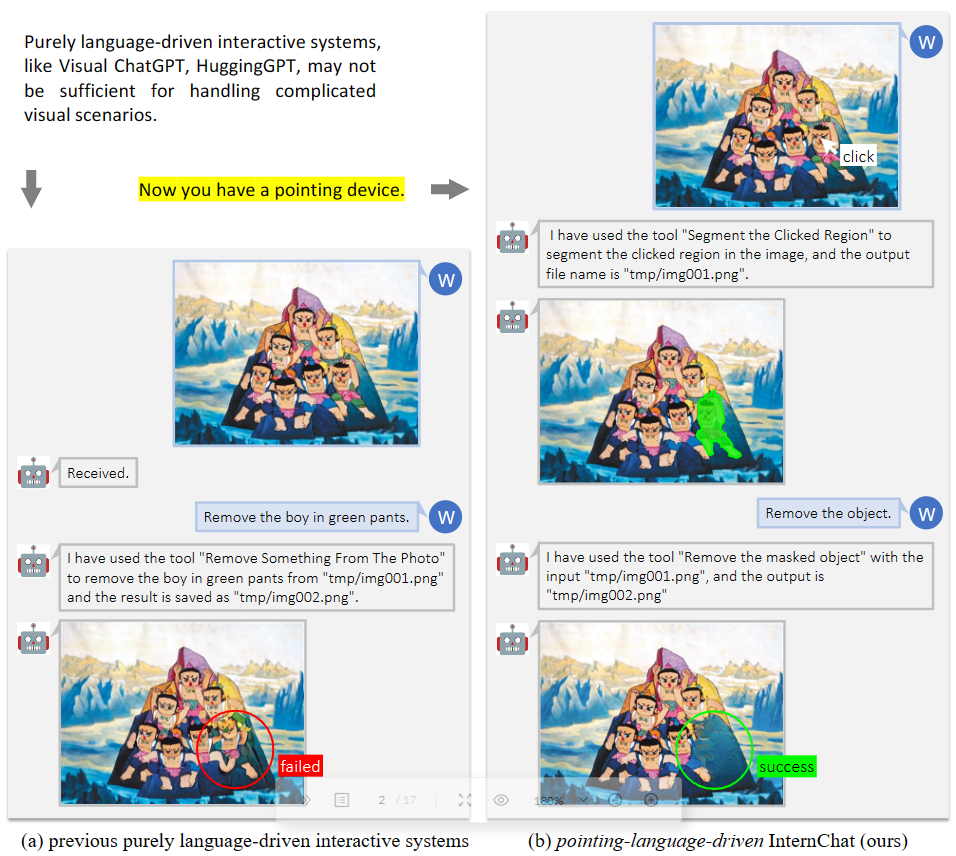
由此,如图 2 所示,当纯语言的系统无法完成任务时,该系统仍可以成功执行复杂的交互任务。
实验
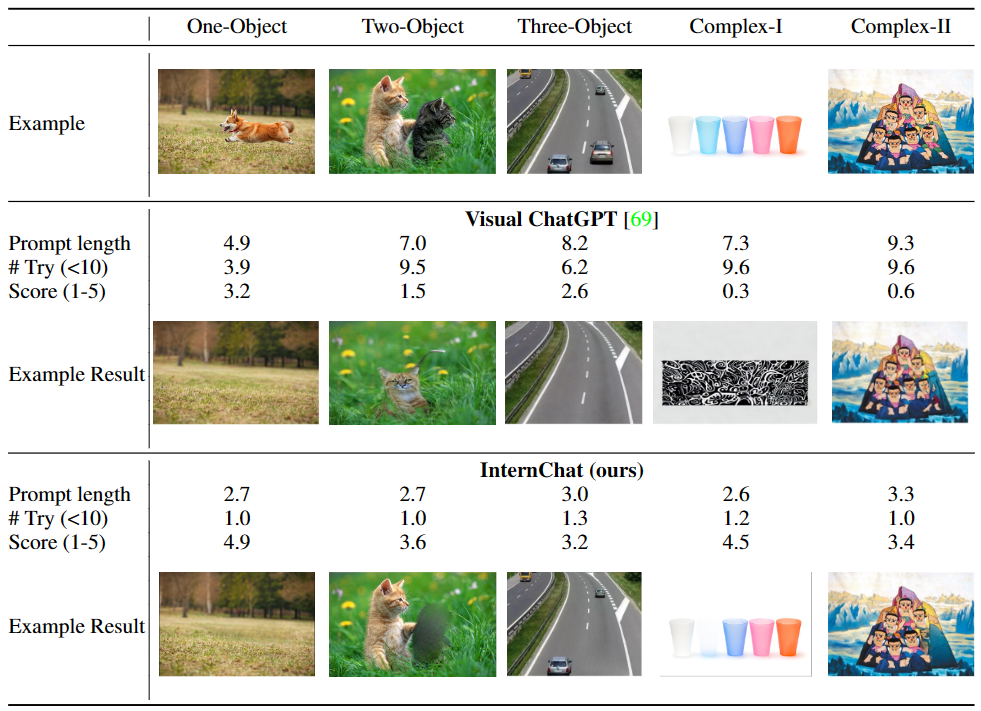
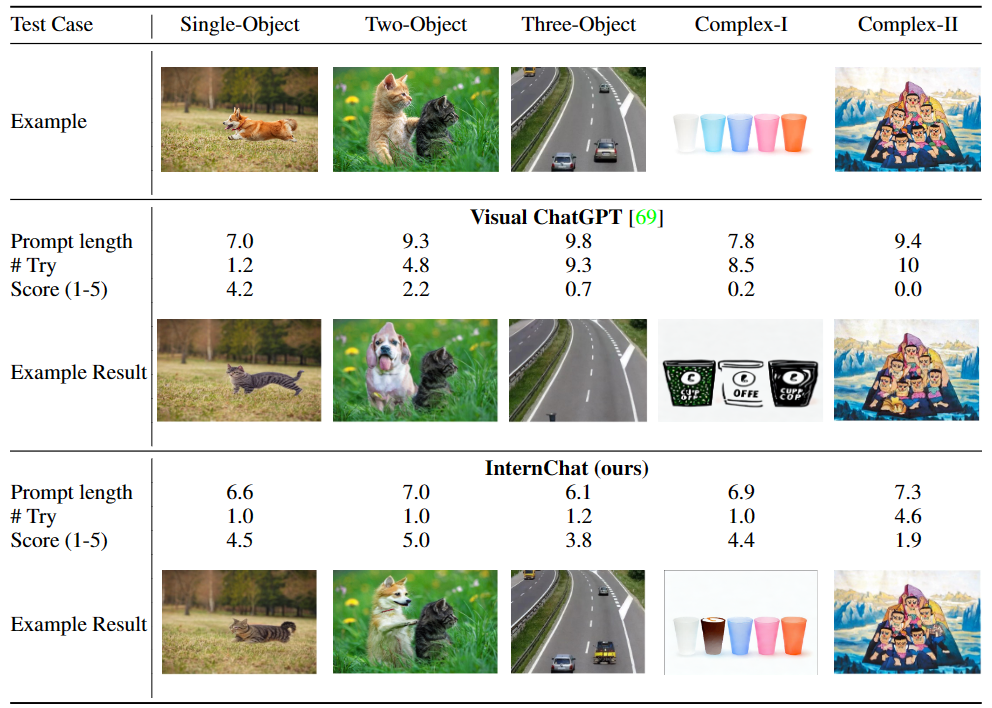
首先我们来看,同时结合语言和非语言指令来提升用于与交互系统之间的沟通效果。为了证明这种混合模式与单纯语言指令相比的优点,研究团队进行了一个用户调查。参与者与 Visual ChatGPT 和 iChat 聊天,并反馈他们的使用感受。表 1 和 2 的结果表明,iChat 比 Visual ChatGPT 更高效且对用户友好。
小结
不过,目前该系统仍存在着一些局限性,包括了:
-
iChat 的高效性在很大程度上取决于其底层开放源代码模型的质量和准确性。然而,这些模型可能存在一些局限或偏见,进而对 iChat 的性能造成不利影响。 -
随着用户交互变得更加复杂或实例数量增多,系统需要维护准确性和响应时间,这对于 iChat 来说可能具有挑战性。 -
此外,当前的视觉和语言基础模型之间缺乏可学习的协作,例如缺乏被指令数据调整的功能。 -
iChat 可能会在应对训练数据之外的新颖或不常见情况时遇到困难,导致性能受到影响。 -
在不同设备和平台上实现无缝集成可能会面临挑战,因为硬件能力、软件限制和可访问性要求各不相同。
在项目主页列出的计划清单上,目前还有几项目标尚未达成,其中就有小编每次在新的对话系统上都要体验的中文交互,目前该系统应该还是暂不支持中文问题,不过这貌似没办法,由于多模态数据集多是基于英文的,英汉互译较为浪费线上资源和处理时间,估计汉化之路还是需要一段时间的。
iChat 看着很有趣,还是期待作者们早点修好 Demo 页面,让俺亲自上手体验一番~

本文由 mdnice 多平台发布