Yarn 概述
- Yarn概述
- 对Yarn的需求
- 简介
- 变迁
- YARN于MRv1的区别
- MRv1
- YARN介绍
- YARN集群安装部署
- 集群角色介绍
- ResourceManager(RM)
- NodeManager(NM)
- 集群部署规划
- YARN RM重启机制
- 概述
- **开启重启机制**
- RM状态数据的存储介质
- 开启
- 后续正在学习:YARN HA高可用
- YARN架构体系
- 官方架构图
- 抽象概念
- 三大组件
- RM
- Node Manager
- ApplicationMaster
- Container容器
- YARN 通信协议
- 组成
- 概述
- YARN交互流程
- YARN上引用类型
- 整体概述
Yarn概述
对Yarn的需求
- 可拓展性: 可以平滑的拓展至数万节点和并发的应用
- 可维护性:保证集群软件的升级与用户应用程序完全解耦
- 多租户:需要支持在同一集群中多租户并存,同时支持多租户间细颗粒度得共享单个节点
- 位置感知:将计算转移至数据所在的位置
- 高级群使用率:实现底层物理资源的高使用率
- 安全和可审计的操作:继续以安全的、可审计的方式使用集群资源
- 可靠性与可用性:具有高度可靠得用户交互、并支持高可用
- 对编程模型多样化得支持:支持多样化的编程模型,需要严谨为不仅仅以MapReduce为中心
- 灵活得资源模型:支持各个节点的动态资源配置以及灵活的资源模型
- 向后兼容:保持现有的MapReduce应用程序得向后兼容性
简介
YARN(Yes Another Resource Negotiator,另一种资源协调者),是一种新的hadoop资源管理器。YARN是一个*通用*资源管理系统的调度平台,可为上层应用提供统一的资源管理和调度。他的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大的好处。
如何理解通用资源管理系统和调度平台
资源管理系统:集群的硬件资源,和程序运行相关比如说内存、CPU等
调度平台:多个程序同时申请资源如何分配?调度的规则(算法)
通用:不仅仅支持MapReduce程序,理论上支持各种计算程序,YARN不关心你在干什么,只关心你要调用资源,在有的情况下就给你,用完还回来即可。
可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
Hadoop能有今天的地位,YARN可以说功不可没,因为有了YARN,更多计算框架可以接入到HDFS中,而不单单是MapReduce,正是因为YARN的包容性,使得其他计算框架能够专注于计算性能的提升。HDFS可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,YARN功不可没
变迁
YARN于MRv1的区别
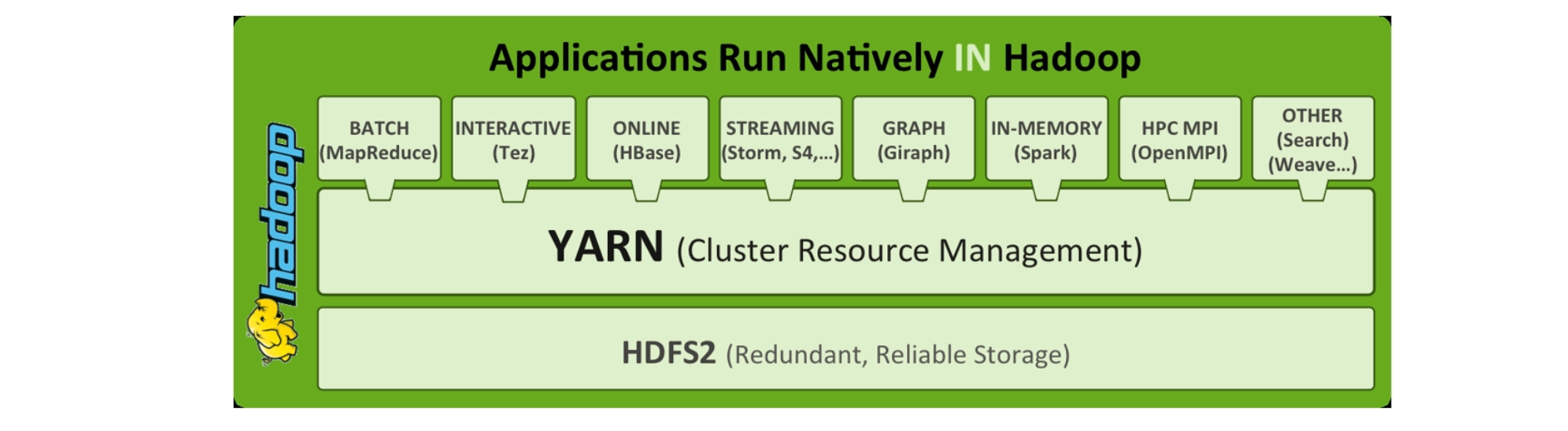
Hadoop从1到2的过程中,最大的变化就是拆分MapReduce,剥离出新的单独组件:YARN。Hadoop3系列整体架构和2一致
在Hadoop1中,MapReduce(MRv1)负责:数据计算、资源管理,身兼多职
在Hadoop2中,MapReduce(MRv2)负责数据计算,YARN负责资源管理
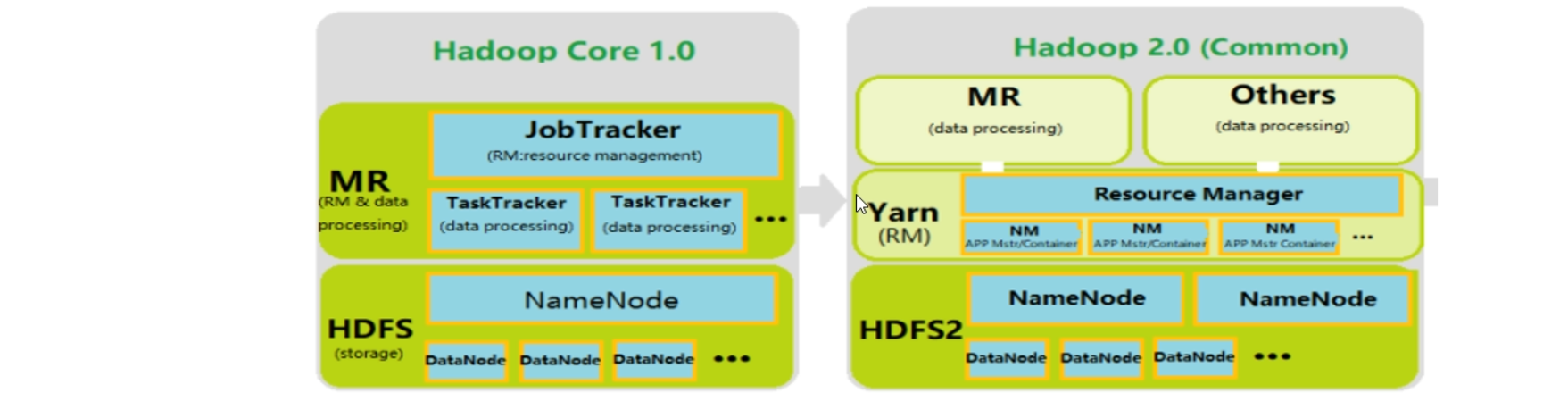
MRv1
MRv1包括三个部分
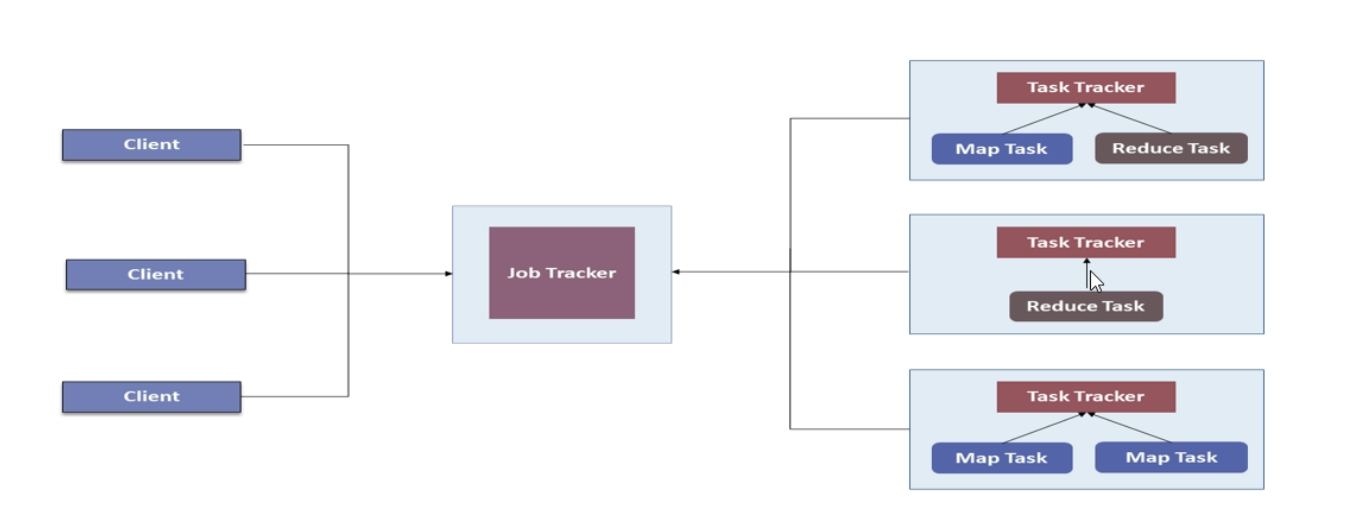
运行时环境(JobTracker 和TaskTracker)、编程模型(MapReduce)、数据处理引擎(Map Task 和Reduce Task)
JobTracker负责资源和任务的管理和调度,TaskTracker负责单个节点的资源管理和任务执行。
MRv1将资源管理和应用程序管理两个部分混杂在一起,使得它在拓展性和容错性和多框架支持等方面存在明显的缺陷
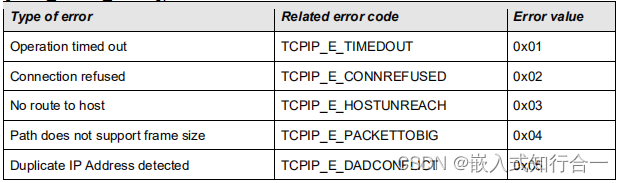
YARN介绍
MRv2重用MRv1中的编程模型和数据处理引擎,但是运行时环境(resourcemanager、nodemanager)被完全重写,由YARN来专管资源管理和任务调度。并且YARN将程序内部具体管理职责交给一个叫做ApplicationMaster的角色,自己专注于集群资源管理,成为了一个通用的资源管理系统
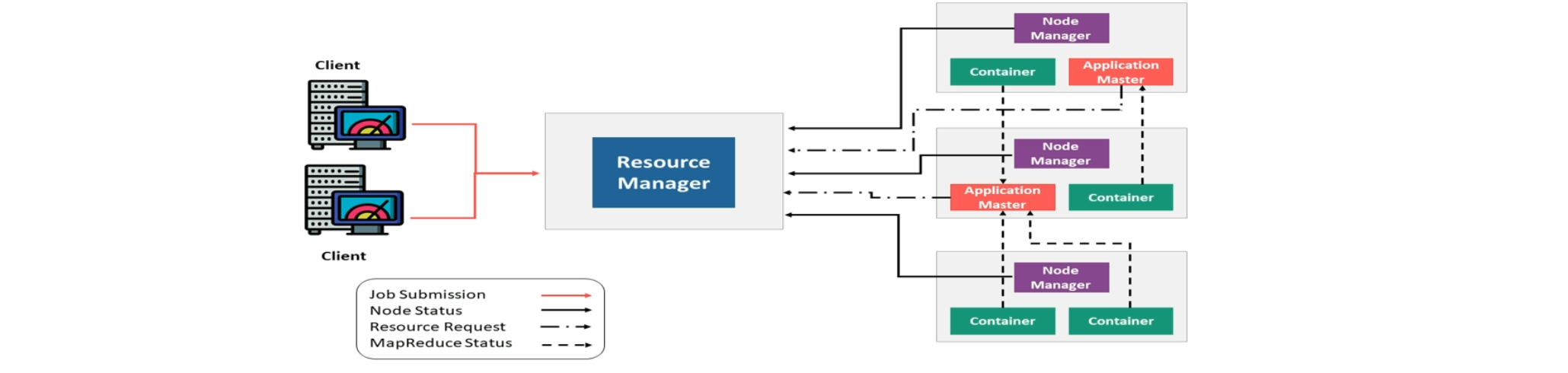
YARN集群安装部署
集群角色介绍
Apache Hadoop YARN是一个标准的Master/Slave集群(主从架构),其中ResourceManager(RM)为Master,NodeManager(NM)为Slave,常见的是一主多从集群,也可以搭建RM的HA高可用集群
ResourceManager(RM)
RM是YARN中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终的仲裁者。RM接受用户的作业提交,并通过NodeManager分配、管理各个机器上的计算资源,资源以Container形式给予,此外,RM还具有一个可插拔组件scheduler,负责为各种正在运行的应用程序分配资源,根据决策进行调度
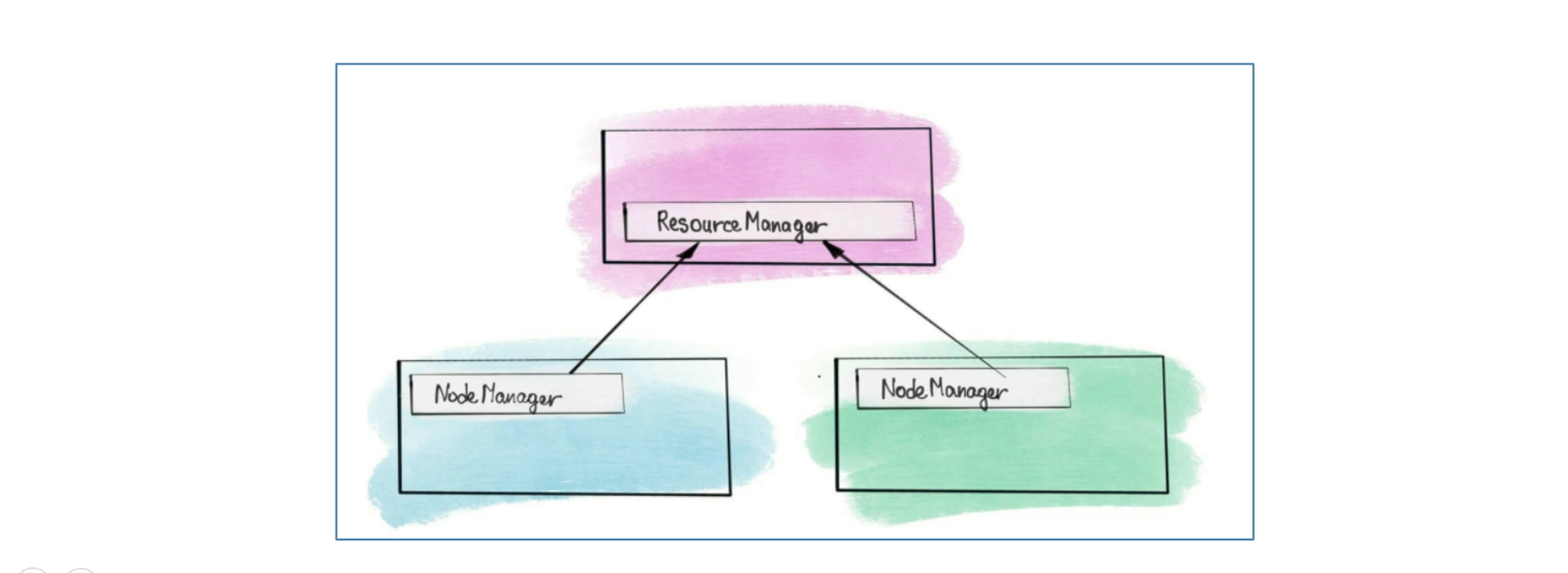
NodeManager(NM)
NM事YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。NM根据RM命令,启动Container容器,监视容器的资源使用情况,并且向RM主角色汇报资源使用情况
集群部署规划
理论上YARN集群可以部署在任意机器上,但是实际上通常把NodeManager和DataNode部署在同一台机器上。(有数据的地方就可能会产生计算,移动程序的成本比移动数据的成本低)。作为Hadoop的与部分,通常会把YARN集群和HDFS集群一起搭建
详细内容:请见Hadoop分布式集群搭建
YARN RM重启机制
概述
ResourceManager负责资源管理和应用的调度,是YARN的核心组件,存在单点故障的问题。ResourceManager Restart重启机制是使RM在重启动时能够使YARN集群正常工作的特性,并且使RM的出现的失败不会被用户知道。重启机制不是自动帮助我们重启的意思,所以不能解决单点故障问题
不开启RM重启机制现象
如果RM出现故障重启后,之前的信息全部都将消失,正在执行的任务也会失败
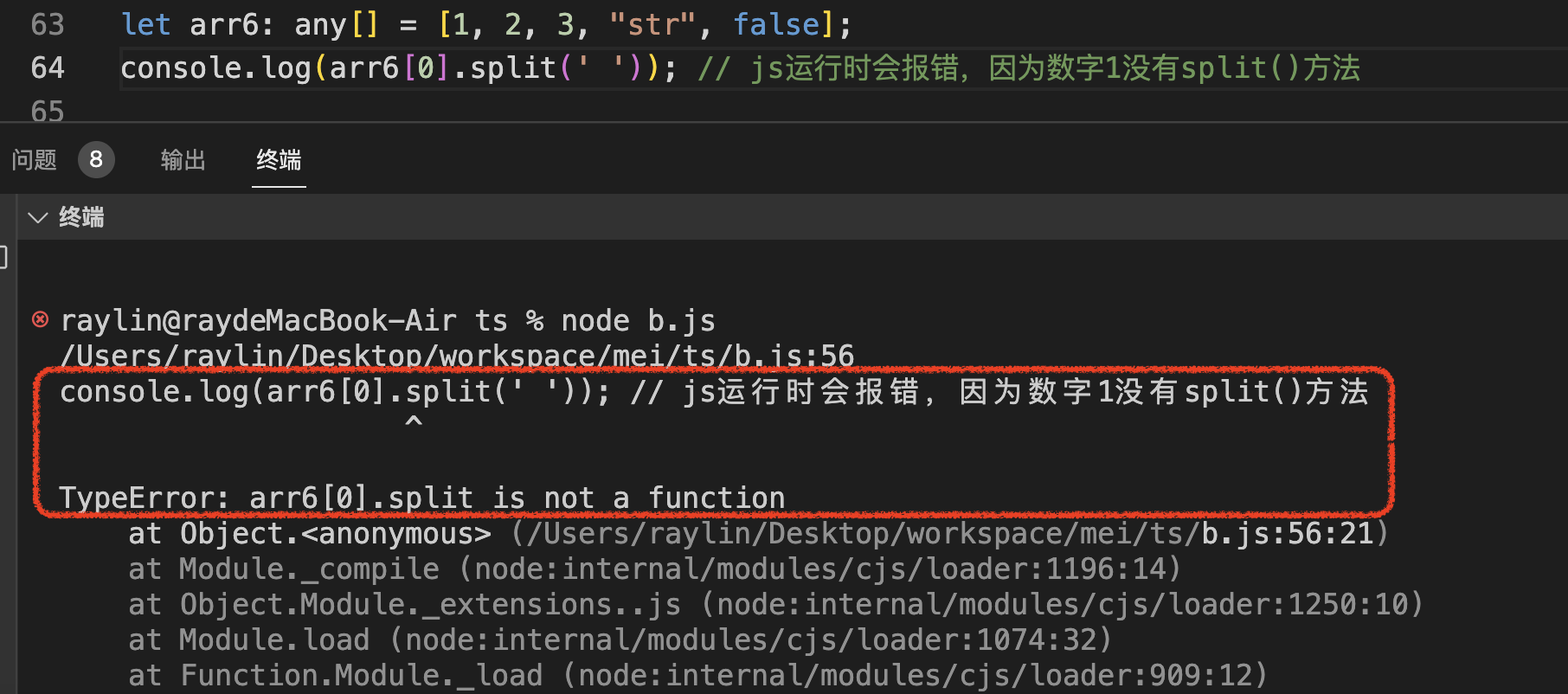
我们先启动一个YARN进程,通过hadoop提供的一个测试程序来计算圆周率,然后我们快速的杀死这个线程然后在重启这个YARN进程
yarn jar hadoop-mapreduce-examples-3.3.1.jar pi 50 50
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SXRDyLPB-1683853833837)(https://kele-1305880580.cos.ap-beijing.myqcloud.com//blog/image-20230511210924406.png)]
然后我们快速杀死ResourceManager线程在通过YARN进行重启
但是结果如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1iAtxBar-1683853833838)(https://kele-1305880580.cos.ap-beijing.myqcloud.com//blog/image-20230511211559922.png)]
直接提示找不到这个任务最后以报错结束运行
开启重启机制
两种实现:
- Non-work-preserving RM restart 不保留工作的RM重启,在Hadoop 2.4.0版本实现
- Work-preserving RM restart 保留工作的RM重启 在Hadoop 2.6.0版本实现
保留工作与不保留工作的区别
不保留工作RM重启机制只保存了application提交的信息和最终的执行状态,并不保存运行过程中的相关数据,所以RM重启后,会先杀死正在执行的任务,然后再重新提交,从0开始执行任务。
保留工作RM重启机制保存了application运行中的数据状态,所以在RM重启之后,不需要杀死之前的任务,而是接着原来执行到的进度继续执行
不保留RM重启机制
当client提交一个application给RM使,RM会将该application的相关信息给存储起来,具体存储的位置可以在配置文件中指定的,可以存储到本地文件系统上,也可以存储到HDFS或者zookeeper中,此外RM也会保存application的最终状态信息(file、killed、finished),如果是在安全环境下运行,RM还会保存相关的证书文件。
当RM被关闭后,NodeManager 和Client由于发现连接不上RM就会不断的向RM发送消息,以便于能及时确认RM是否已经恢复正常,当RM重新启动,他会发送一条re-sync(重新同步)的命令给所有的NM和ApplicationMaster(后续简写AM),NM 收到重新同步命令后会杀所有正在运行的containers并重新向RM注册,从RM的角度来看,每台重新注册的NM跟一台跟一台新加入到集群的NM是一样的。
AM收到重新同步的命令后会自行将自己杀死,接下来RM会将存储的关于application的相关信息读取出来,将在RM关闭之前最终状态为正在运行的application重新提交
保留RM重启机制
与不保留工作不同的地方在于,RM会记录下container的整个生命周期的数据,包括application运行的相关数据、资源申请状况、队伍资源使用情况等信息。当RM重启之后,会读取之前存储的关于application的运行状态的数据,同时发送re-sync的命令,与第一种方式不同的是,NM在接收到重新同步的命令后并不会杀死正在运行的containers,而是继续运行containers中的任务,同时jiangcontainers的运行状态发送给RM,之后RM根据自己所掌握的数据重构container实例和相关的application运行状态,这样一来就实现了RM重启之后紧接着RM关闭时的任务状态继续执行。
RM状态数据的存储介质
RM重启机制本质上是将RM内部的状态信息写入到外部存储介质中,在RM启动时会初始化状态信息的目录,当Application运行时会将相关的状态写入到对应的目录下,如果RM发生故障或者重启,可以通过外部存储进行回复。RM状态存储的实现使RMStateStore抽象类,
开启
需要zookeeper进行操作
后续正在学习:YARN HA高可用
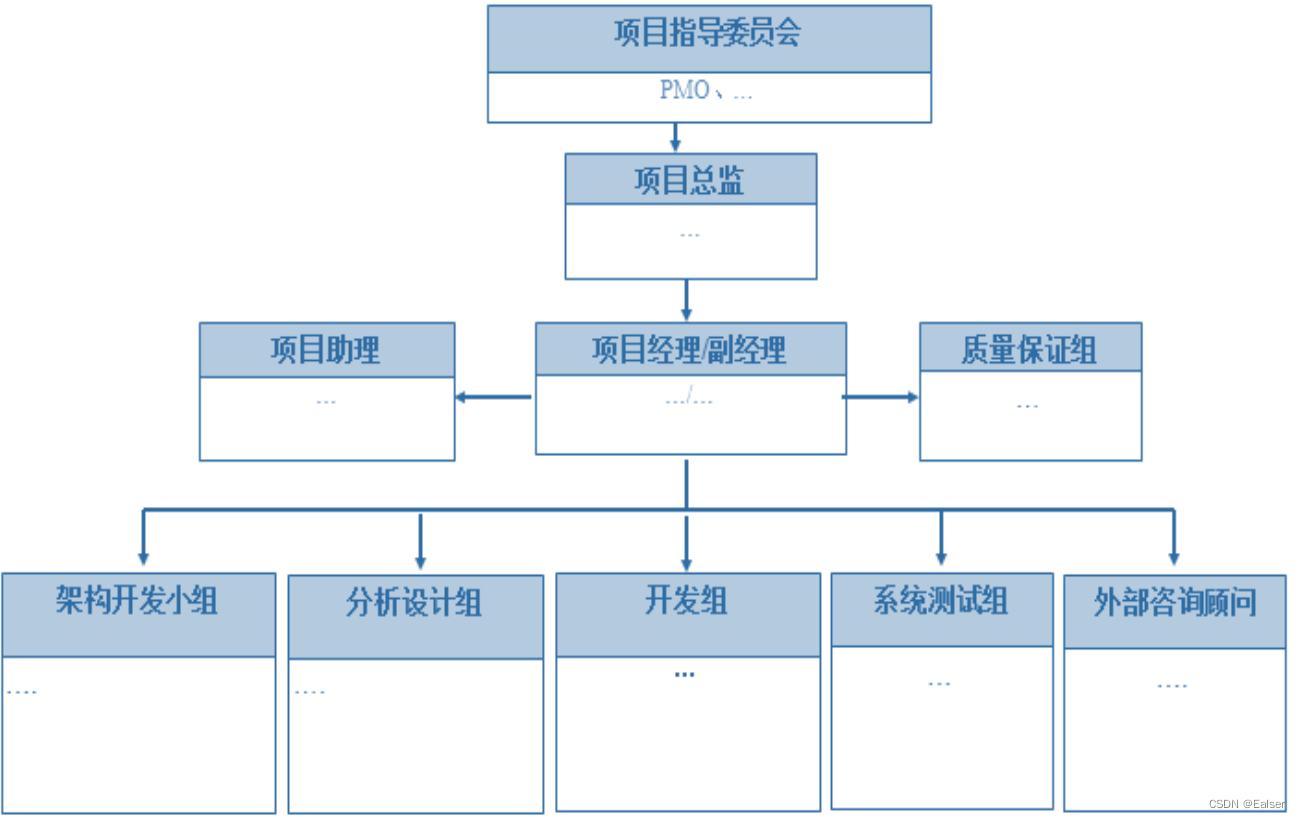
YARN架构体系
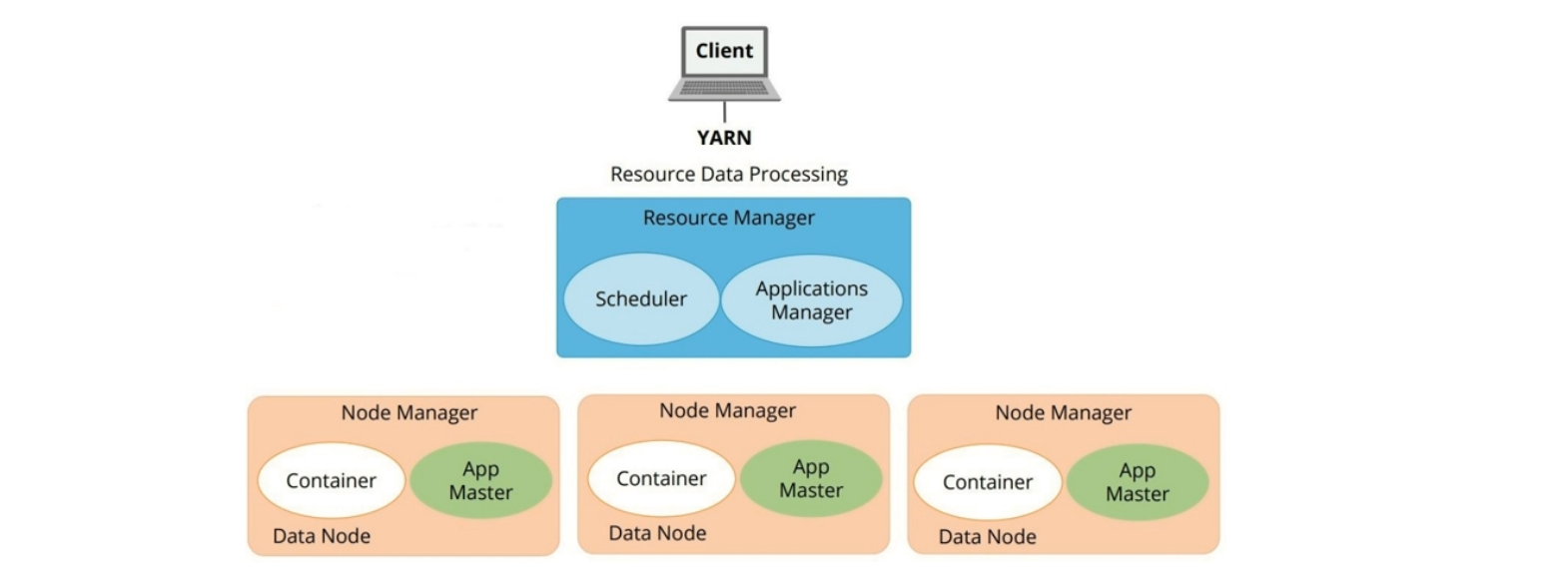
官方架构图


抽象概念
三大组件
ResourceManager(RM)
YARN集群中的主角色,决定系统中所有应用程序间资源分配的最终权限,即最终仲裁者,接受用户作业的提交,并通过NM分配、管理各个机器上的计算资源
NodeManager(NM)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源,根据RM命令,启动Container容器,监视容器的资源使用情况,并且向RM主角色汇报资源使用情况
ApplicationMaster(AM)
用户提交的每个程序均包含一个AM,应用程序内的老大,负责程序内部各个阶段的资源申请、监督程序的运行情况。
RM
RM 主要由两个组件组成:调度器(Scheduler)和应用程序管理器(Applications Manager ,AMS)
调度器(Scheduler)
根据容量、队列等限制条件(如每隔队列分配一定的资源,最多执行一定数量的作业等),将数据中的资源分配给各个正在运行的应用程序
应用程序管理器(Applications Manager)
负责整体管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动 它等
Node Manager
NodeManager是每个节点上资源和任务管理器
- 一方面他会定时向RM汇报本节点上资源使用情况和各个Container的运行状态
- 另一方面,他接受并处理来自AM的Container启动/停止等各种请求
ApplicationMaster
职责
- 与RM调度器协商以获取资源(用Container表示)
- 将得到的任务进一步分配给内部的任务
- 与NM通讯以启动/停止任务
- 监控所有任务运行状态,并在任务运行时重新为任务申请资源以重启任务
当前YARN自带两个AM的实现
- 一个用于演示AM编写方法的案例程序distributedshell
- 另一个是运行MapReduce应用程序的AM-MRAppMaster
Container容器
Container使YARN中抽象资源,它封装了某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是Container表示的,YARN回味每个任务分配一个Container,且该任务只能使用Container中描述的资源,需要注意的是,Container不同于MRv1的曹魏,他是一个动态资源划分单位,是根据应用程序的需求动态生成的
当下YARN仅支持CPU和内存两种资源,底层使用了轻量级资源隔离机制Cgroups进行隔离
YARN 通信协议
概述
分布式环境下,需要涉及机器跨网络通信,YARN底层使用RPC协议实现通讯。RPC是远程过程调用的缩写形式,基于RPC进行远程调用就像本地调用一样。在RPC协议中,通信双方有一端时Client,另一端为Server,且Client总是主动连接Server的,因此YARN实际上采用的是拉式(pull-based)通信模型
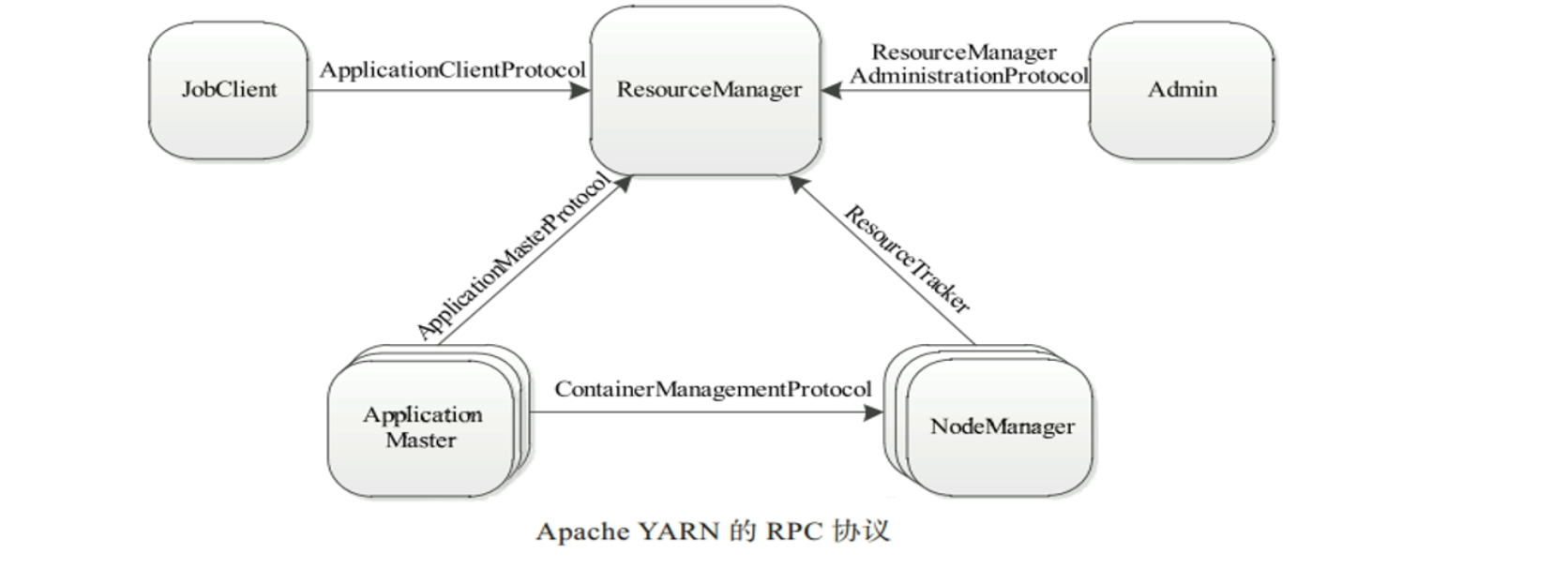
组成
-
JobClient(作业提交客户端)与RM之间的协议– ApplicationClientProtocol
客户端通过该RPC协议提交应用程序、查询应用程序状态
-
Admin与RM之间的通信协议 – ResourceManagerAdministrationProtocol
Admin通过该RPC协议更新YARN集群系统配置文件,比如说黑白名单、用户队列权限等
-
AM与RM之间的协议–ApplicationMasterProtocol
AM通过该RPC协议想RM注册和撤销自己,并为各个任务申请资源
概述
-
AM与NM之间的协议 – ContainerManagementProtocol
AM通过该RPC要求NM启动或者停止Container,获取各个Container的使用状态等信息。
-
NM与RM之间的协议
NM通过该RPC协议向RM注册,并定时发送心跳信息汇报当前节点的使用情况和Container运行情况
YARN交互流程
YARN上引用类型
短应用程序:指一定时间内(可能是秒级、分钟级或者小时级,尽管天级别或者更长时间的也存在,但是非常少)可运行完成并正常退出的应用程序,比如MapReduce作业、Spark作业等长应用程序:之不出意外,永不终止运行的应用程序,通常是一些服务,比如说Storm Service(主要包括Nimbus和Supervisor两类服务),Flink(包括JobManager和TaskManager 两类服务)等,而它们本身作为一个框架,提供了编程接口供用户使用
尽管这两类应用程序作用不同,一类直接运行数据处理程序,一类用于部署服务(服务之上在运行数据处理程序),但是在YARN上运行的流程是相同的
整体概述
当用户向YARN提交一个应用程序后,YARN将分为两个阶段运行该应用程序。
第一阶段是启动ApplicationMaster
第二个阶段是由ApplicationMaster创建应用程序,为他申请资源,并监控他的整个运行过程,知道运行完成。
MR提交YARN交互流程
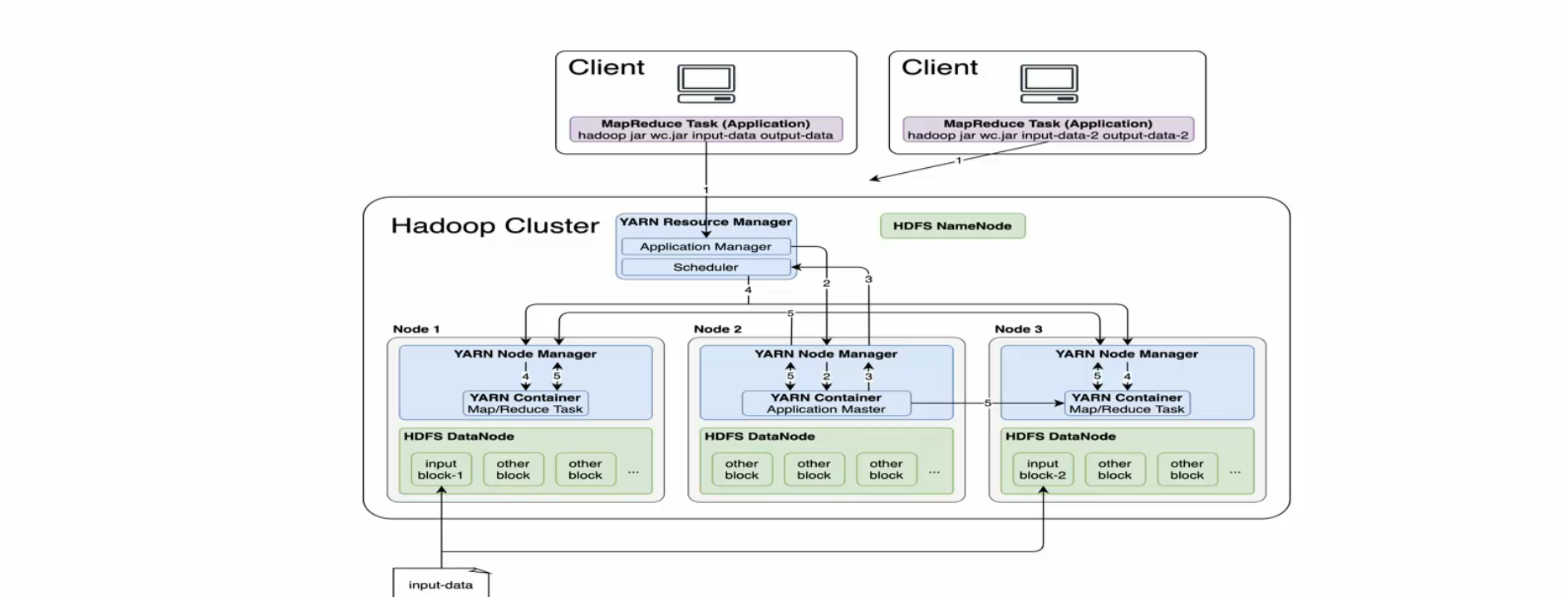
- 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
- ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求他在这个Container中启动应用程序的ApplicationMaster
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后他将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复4~7步骤即可
- ApplicationMaster通过RPC协议向ResourceManager申请和领取资源
- 一旦ApplicationMaster申请到资源后,便于对应的NodeManager通信,要求他启动任务
- NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写道一个脚本中,通过运行该脚本启动任务
- 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重启任务,在应用程序运行过程中,用户可以随时通过RPC向ApplicationMaster查询应用程序的运行状态
- 应用程序运行完成后,ApplicationMaster向ResourceManager注册并关闭自己




![[NLP] SentenceTransformers使用介绍](https://img-blog.csdnimg.cn/b1132f4d07904512bc5382d4135d7f68.png)