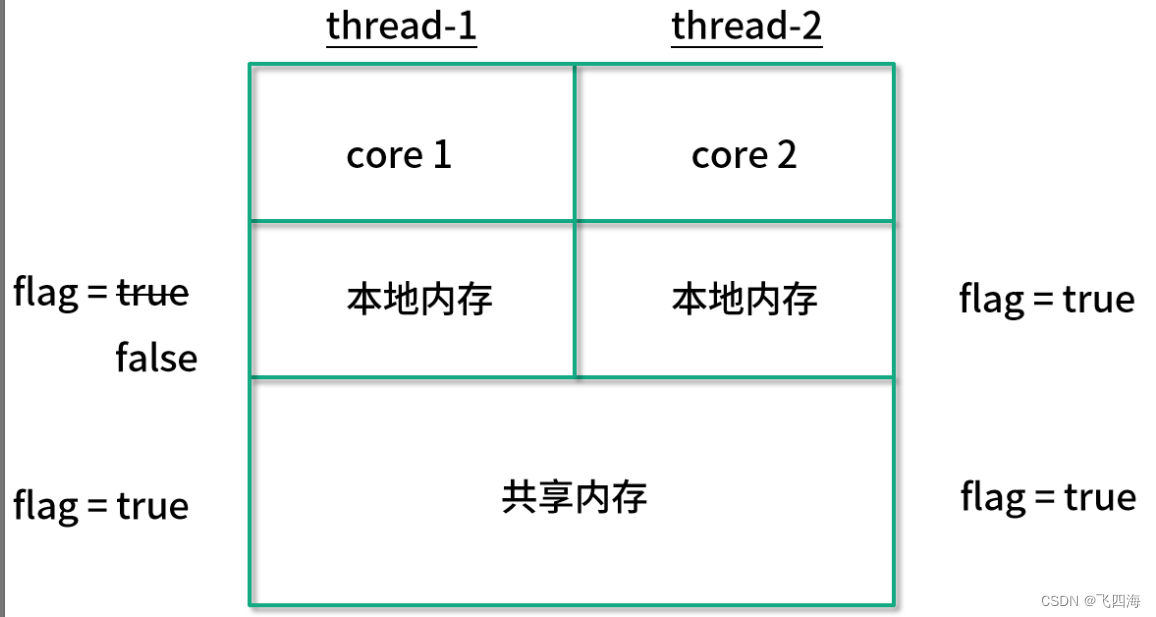
1. 预备知识:强软弱虚引用
在Java中有四种引用的类型:强引用、软引用、弱引用、虚引用。
设计这四种引用的目的是可以用程序员通过代码的方式来决定对象的生命周期,方便GC。
强引用
强引用是程序代码中最广泛使用的引用,如下:
Object o = new Object();
这就是强引用了,可以说在代码中随处可见。强引用规定:只要某个对象有强引用与之关联,这个对象永远不会被回收,即使内存不足,JVM宁愿抛出OOM,也不会去回收。
那要怎么回收强引用的对象呢,方法就是将该引用置为null,这样对象和引用之间就断了关系:
public class TestStrongReference {
@Override
protected void finalize() throws Throwable {
System.out.println("Strong Reference 对象被回收了");
}
public static void main(String[] args) {
TestStrongReference testStrongReference = new TestStrongReference();
testStrongReference = null;
System.gc();
Object o = new Object();
}
}
执行结果
Strong Reference 对象被回收了
从上面的代码中可以看到,我们重写了TestStrongReference中的finalize方法,这个方法是虚拟机尝试回收该对象前,最后拯救该对象的方法(将对象和引用重新关联起来)。可以看到,我们将引用赋值为null,testStrongReference对象就不可达了,就会被回收掉了。
软引用
我们先看看代码是如何创建一个软引用的:
SoftReference<byte[]> softReference = new SoftReference<byte[]>(new byte[1]);
System.out.println(softReference.get());
可以看到,软引用就是用SoftReference把对象包裹一下,可以通过get方法获取被包裹的对象。
软引用的特点是:当内存不足,会触发虚拟机的GC,如果GC后,内存还是不足,就会把软引用包裹的对象干掉。也就是在内存不足时,才会回收该对象。例如我们进行如下实验:
import java.lang.ref.SoftReference;
public class TestSoftReference {
public static void main(String[] args) {
SoftReference<byte[]> softReference = new SoftReference<byte[]>(new byte[1024*1024*10]);
System.out.println(softReference.get());
System.gc();
System.out.println(softReference.get());
byte[] b = new byte[1024*1024*10];
System.out.println(softReference.get());
}
}
执行结果:
// 虚拟机参数:-Xmx15M
[B@1b6d3586
[B@1b6d3586
null
在代码中,我们设置虚拟机最大堆内存时15M,同时我们先创建了一个10M大小的虚引用,可以看到在第一次GC的时候,因为内存还够用,所以没有被回收。接着我们又创建了一个10M大小的强引用,这时内存就不够用了,GC就会回收掉软引用。
弱引用
弱引用的使用实际和软引用时类似的,只是将关键字变成WeakReference:
WeakReference<byte[]> weakReference = new WeakReference<byte[]>(new byte[1]);
System.out.println(weakReference.get());
弱引用的特点:不管内存是否足够,只要发生GC,就都会被回收。 我们通过实验来进行验证:
import java.lang.ref.WeakReference;
public class TestWeakReference {
public static void main(String[] args) {
WeakReference<byte[]> weakReference = new WeakReference<byte[]>(new byte[1024*1024*10]);
System.out.println(weakReference.get());
System.gc();
System.out.println(weakReference.get());
}
}
运行结果:
[B@1b6d3586
null
可以看到,即使内存充足,GC也是会将弱引用对象回收。
虚引用
我们先看下虚引用的实现方式:
final ReferenceQueue queue = new ReferenceQueue();
PhantomReference<byte[]> phantomReference = new PhantomReference<byte[]>(new byte[1],queue);
虚引用又称为幻影引用,它的第一个特点是:无法通过虚引用来获取对一个对象的真实引用。 创建虚引用除了要使用PhantomReference将对象包裹,还需要传入一个ReferenceQueue,是一个队列。
虚引用的第二个特点:虚引用必须与ReferenceQueue一起使用,当GC准备回收一个对象,如果发现他还有一个虚引用,就会将这个虚引用加入到与之关联的ReferenceQueue中。我们通过代码来进行实验:
import java.lang.ref.PhantomReference;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.util.ArrayList;
import java.util.List;
public class TestPhantomReference {
public static void main(String[] args) {
//队列
final ReferenceQueue queue = new ReferenceQueue();
// 虚引用
PhantomReference<byte[]> phantomReference = new PhantomReference<byte[]>(new byte[1024*1024*10],queue);
final List<byte[]> list = new ArrayList<byte[]>();
// 线程1
Thread thread1 = new Thread(){
@Override
public void run() {
for(int i=0;i<100;i++){
list.add(new byte[1024*1024*10]);
}
}
};
// 线程2
Thread thread2 = new Thread(){
@Override
public void run() {
while(true){
Reference reference = queue.poll();
if(reference==null){
System.out.println("phantomReference被回收了");
break;
}
}
}
};
thread1.start();
thread2.start();;
}
}
运行结果
phantomReference被回收了
在上面的代码中,我们创建了一个虚引用。然后再线程1中不断创建一个byte数组,这样迟早会超出内存,就会触发GC。当触发GC后,虚引用指向的对象就会被回收,虚引用就会加入到队列中,线程2中就打印了虚引用信息。
虚引用可能我们平时用到不多,举个应用的例子就是:在NIO中,运用了虚引用管理堆外内存。
2.ThreadLoca简介
在之前介绍的多线程编程中,我们通常会利用synchronized或者各种lock来控制临界区资源的同步顺序,从而来解决线程安全问题。这实际是一种时间换空间的优化。
线程安全问题的核心就是多个线程会对同一个临界区资源进行操作。
ThreadLocal则是采用的是空间换时间的思想,让每个线程都拥有自己的共享资源,各自使用各自的,这样就不会出现线程安全问题。ThreadLocal意为“本地变量”,也就是达到人手一份的效果,不会出现竞争的情况。但是这种方式的缺点就是消耗的内存会大很多。
我们来对比下常用并发策略和ThreadLocal:假设现在有一百个同学需要填写一个表格,但是只有一支笔。一种策略是通过老师(锁)来控制用这支笔的先后顺序。而ThreadLocal就相当于,老师准备了一百只笔,这样每个同学都能用自己的笔,不会产生冲突。
3. ThreadLocal底层实现
要介绍ThreadLocal,首先还得从Thread类讲起:
public class Thread implements Runnable {
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
}
在Thread类中有一个成员变量叫threadLocals,它的作用是用来存储当前Thread的所有ThreadLocal的。threadLocals的类型是ThreadLocalMap,它是ThreadLocal的静态内部类。
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private Entry[] table;
}
从上面的ThreadLocalMap的代码中可以看到,ThreadLocalMap是基于Entry数组来实现的。Entry又是ThreadLocalMap的内部类,在构造函数中调用super方法设置key为当前Thread Local,并且ThreadLocal是一个弱引用,然后设置value为当前Thread Local对应的变量。也就是说,Entry对象存储了一个key-value键值对,key是ThreadLocal,value是对应的值。ThreadLocalMap利用Entry数组的方式来存储键值对。每个线程持有一个ThreadLocalMap
我们通过一张图来梳理下各个对象之间的关系:
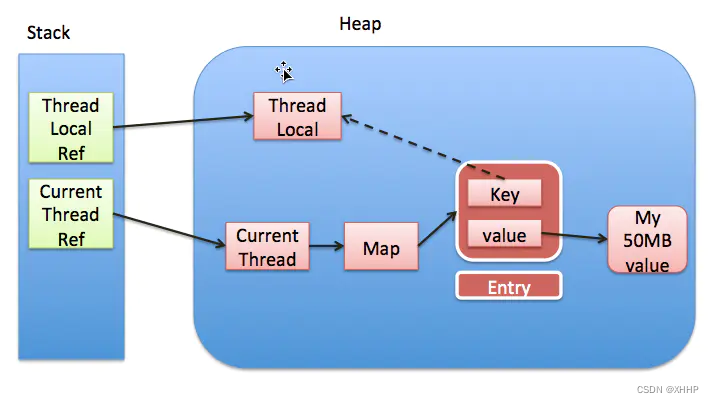
上图中,实现代表强引用,虚线代表弱引用。如果ThreadLocal的强引用被置为null,threadLocal实例就没有一条引用链可达,那么在GC的时候肯定会被回收,这样就会出现Entry的key为null的情况。而因为还存在这样一条引用链:Current Thread Ref -> Current Thread -> Map -> Entry -> value Ref -> value Memory的引用链,这就导致value不会被回收,但是我们又没有办法通过key去获取value。所以ThreadLocalMap是可能存在内存泄漏的情况的。
接下来我们再继续通过代码来看下ThreadLocalMap是如何优化内存泄漏问题的。
3. set方法
ThreadLocalMap实际上是基于散列表实现的,将key通过散列函数映射到某个固定位置。因为ThreadLocalMap的底层实现是一个Entry数组,那么在存放键值对的时候,是有可能出现key冲突的情况的。而解决冲突的方法通常有:分离链表法、开放定址法。而在ThreadLocalMap中是采用开放定址法来实现的:
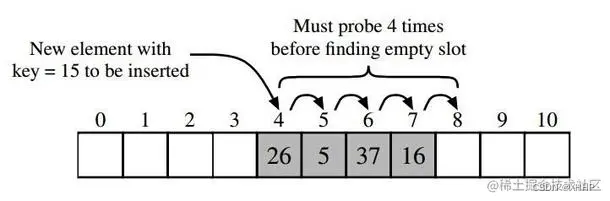
开放定址法的思想不需要创建链表,首先通过散列函数得到相应的位置,如果发现该位置被占用,就继续向后寻找。如果后面也没有位置,就从头开始寻找。直到找到一个空闲的位置,存入键值对。
接下来我们看下set方法:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table; // 获取Entry数组
int len = tab.length;
int i = key.threadLocalHashCode & (len-1); // 通过与操作获得位置
// 遍历Entry数组,直到找到一个空的位置
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get(); // 获取Entry对应的key
if (k == key) { // 如果这个key和要设置的key一样
e.value = value; // 覆盖value
return;
}
if (k == null) { // key为null,但是entry不为null,出现内存泄漏
replaceStaleEntry(key, value, i); // 清除内存泄漏
return;
}
}
tab[i] = new Entry(key, value); // 第i个位置存入新的Entry
int sz = ++size; // ThreadLocalMap中Entry个数+1
if (!cleanSomeSlots(i, sz) && sz >= threshold) // 继续清除内存泄漏
rehash(); // 如果超过阈值,就进行扩容
}
这个方法中有几个点是值得注意的,我们来一一分析:
-
ThreadLocal的散列值如何计算?
private static AtomicInteger nextHashCode = new AtomicInteger(); private static final int HASH_INCREMENT = 0x61c88647; private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); } private final int threadLocalHashCode = nextHashCode(); int i = key.threadLocalHashCode & (len-1);在计算当前ThreadLocal的散列值的时候,首先是计算threadLocalHashCode,而这个值是用一个AtomicInteger不断加上0x61c88647得来的,至于为什么用0x61c88647,是因为这个数能保证散列通均匀分布,具体可参见这篇文章。
得到了threadLocalHashCode之后,再和len-1相与,相当于取模的过程,得到Entry数组中的位置
-
如何解决hash冲突?
我们可以在for循环的条件部分看到nextIndex函数,它实际就是用来实现开放定址法的。且利用e!=null作为循环条件,找到第一个空位:private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0); }
我们可以看到上面的流程就是寻找到空的位置进行写入键值对。如果碰到相同的key,就进行覆盖。在查找的过程中,还会利用replaceStaleEntry(key, value, i)和cleanSomeSlots(i, sz)函数清除出现内存泄漏的位置,我们先来看下cleanSomeSlots(i, sz)函数:
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false; // 标记是否删除
Entry[] tab = table; // 获取Entry数组
int len = tab.length; // 数组的长度
do {
i = nextIndex(i, len); // i指向下一个位置
Entry e = tab[i]; // 获得i位置上的Entry
if (e != null && e.get() == null) { // 如果发生内存泄漏
n = len; // 更新n
removed = true; // 标记发现了内存泄漏
i = expungeStaleEntry(i); // 处理内存泄漏的位置
}
} while ( (n >>>= 1) != 0); // n除以2
return removed;
}
这个函数,我们要从入参看起,在set方法进入到cleanSomeSlots,是给i赋值为新Entry插入的位置,n赋值为ThreadLocalMap中Entry的实际个数。因为i位置刚插入新Entry,所以肯定不会内存泄漏,所以一上来就调用nextIndex方法。而参数n的作用则是用来控制扫描趟数的。在扫描过程中,如果没有遇到内存泄漏,那这个过程将持续log2(n)次,因为每次循环都会执行n>>>=1,也就是n右移一位,相当于处于2。如果碰到内存泄漏,就又会将n赋值为len,继续扫描log2(n)次。总结说一句话就是:当碰到内存泄漏,就会增大搜索的范围。如下图所示:
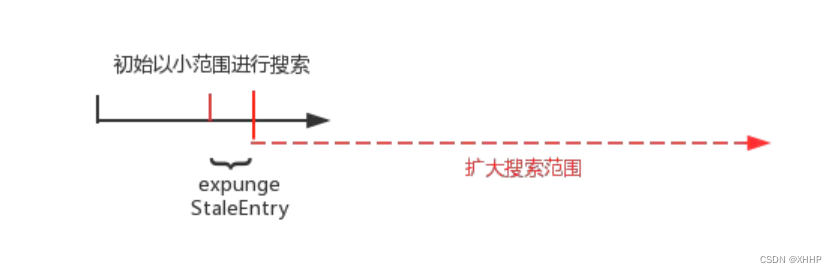
图中的黑线是没有碰到内存泄漏会搜索的范围。当碰到内存泄露了,就会扩大搜索范围,编程红线的范围。这种方式是为了时间和效率上的平衡。
当发现了内存泄漏,cleanSomeSlots又会进一步进入到expungeStaleEntry(i)函数处理内存泄漏:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table; // 获得Entry数组
int len = tab.length; // 数组的长度
tab[staleSlot].value = null; // 将内存泄漏位置的value设置为null
tab[staleSlot] = null; // 将Entry数组中内存泄漏的位置设置为null
size--; // 实际存储个数-1
// 删除掉Entry之后,需要重新进行hash
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null; // 继续查找内存泄漏,直到发现为null即停止
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get(); // 获得Entry中的key
if (k == null) { // 如果是内存泄漏
e.value = null; // 清除
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1); // 重新hash
if (h != i) {
tab[i] = null; // 移动到重新计算后的位置
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
从expungeStaleEntry函数中可以看到,就是将内存泄漏的地方置为null,并且还会继续往前找,直到发现Entry为null,返回i到cleanSomeSlots,cleanSomeSlots又继续从i位置继续寻找。我们再从直观上面来看下cleanSomeSlots函数:
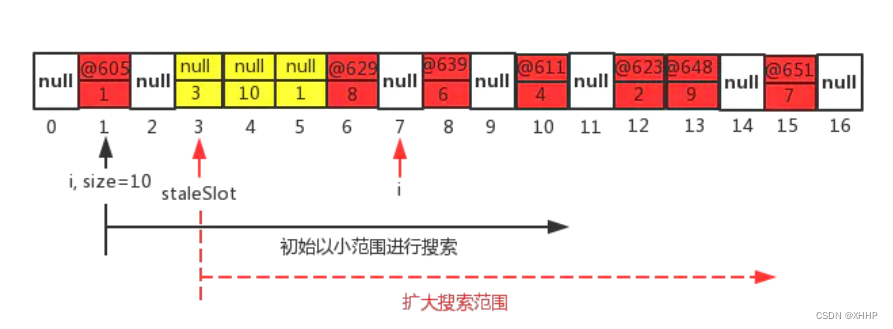
最开始的时候是位于i=1的位置,往右寻找,到i=3的位置发现内存泄漏,就会扩大搜索范围,并且进入到expungeStaleEntry函数清理并继续搜索,继续寻找到i=7位置发现Entry为null,就停止,退出回到cleanSomeSlots函数。
看完了set方法中的cleanSomeSlots函数,我们再来看下另外一个清理内存泄漏的函数replaceStaleEntry:
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table; //获取Entry数组
int len = tab.length; // 数组的长度
Entry e;
int slotToExpunge = staleSlot; // slotToExpunge用来记录最左边出现内存泄漏的位置
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len)) // 向左遍历寻找
if (e.get() == null) // 如果出现内存泄漏
slotToExpunge = i; // 设置slotToExpunge
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) { // 向右遍历寻找
ThreadLocal<?> k = e.get();
if (k == key) { // 寻找过程中发现了与当前需要设置的key一样
e.value = value; // 更新i位置上的value
tab[i] = tab[staleSlot]; // 将内存泄漏的位置移动到i位置
tab[staleSlot] = e; // 将entry移动到原来内存泄漏的位置
if (slotToExpunge == staleSlot) // 如果向左遍历寻找时没有发现内存泄漏
slotToExpunge = i; // 将slotToExpunge设置为i
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); // 清理内存泄漏
return;
}
// 如果向右寻找的过程中发现内存泄漏,且向左寻找时没有发现内存泄漏
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i; // 将slotToExpunge设置i
}
// 没有找到相同的key
tab[staleSlot].value = null; // 讲原来内存泄漏位置的value设置为null
tab[staleSlot] = new Entry(key, value); // 放入新的Entry
if (slotToExpunge != staleSlot) // 发现内存泄漏
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); // 就直接清除
}
在上面的代码中,我们可以看到是先进行前向寻找,再进行后向寻找的。可能代码看起来比较复杂。我们通过图示的方法来分析各种情况:
-
前向寻找发现内存泄漏
- 后向寻找找到相同的key
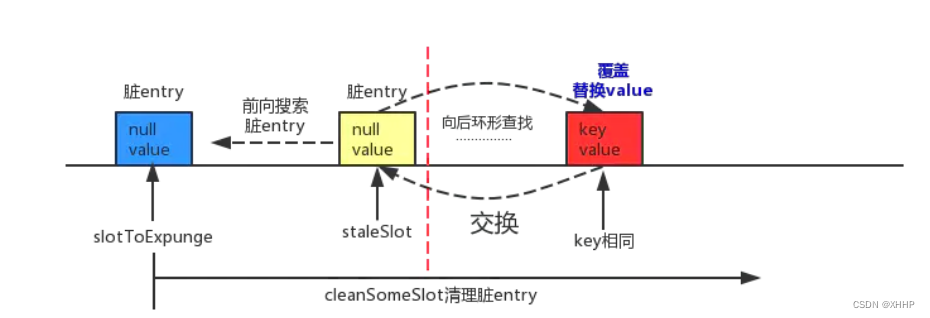
会将slotToExpunge设置为前向寻找发现的内存泄漏位置,并且互换内存泄漏的位置和重复的key的位置。
2. 后向寻找没有找到相同的key
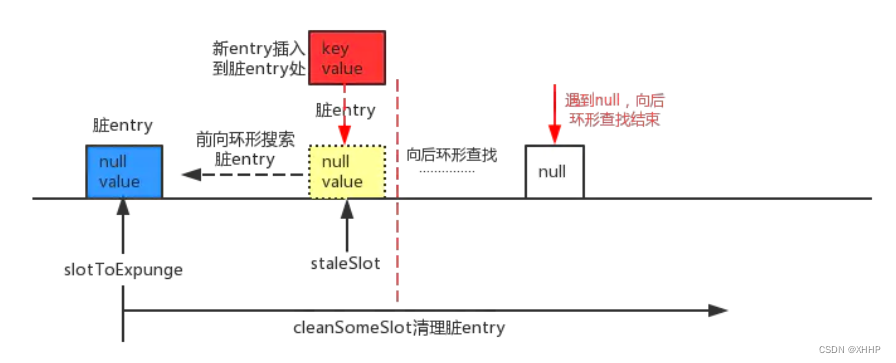
会将slotToExpunge设置为前向寻找发现的内存泄漏位置,在最初发现内存泄漏的位置填补上新entry。
- 后向寻找找到相同的key
-
前向寻找没有发现内存泄漏
- 后向寻找找到相同的key
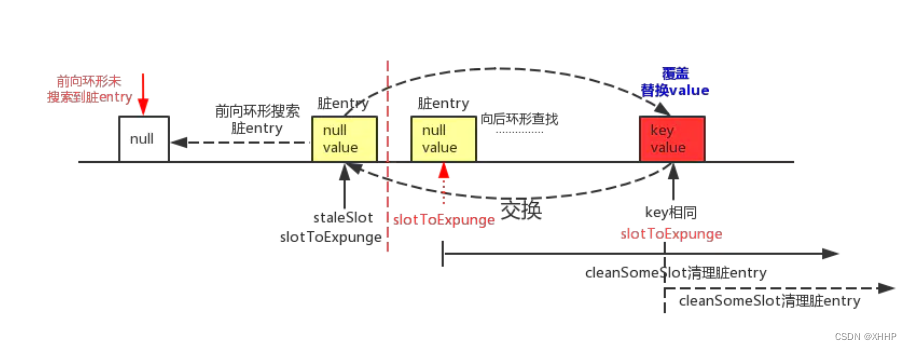
互换内存泄漏的位置和重复的key的位置,会将slotToExpunge设置为后向寻找发现的内存泄漏位置,
2. 后向寻找没有找到相同的key
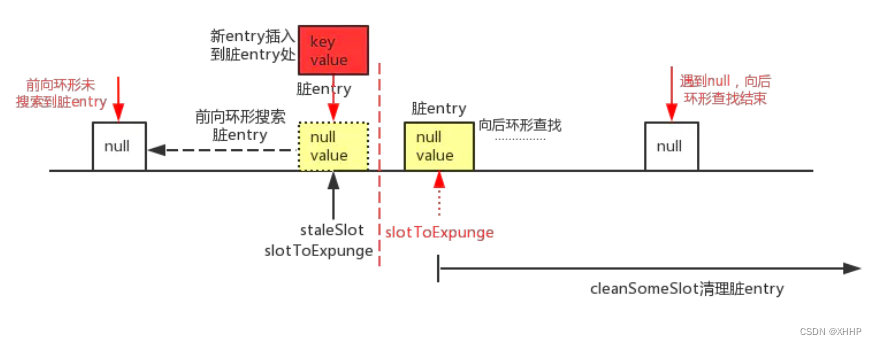
在最初发现内存泄漏的位置填补上新entry,会将slotToExpunge设置为后向寻找发现的内存泄漏位置,
- 后向寻找找到相同的key
至此,set方法中比较重要的处理内存泄漏的三个方法我们就过了一遍了。在set函数处理完内存泄露后,还会调用rehash()方法进行扩容,我们放到一个完整章节来讲解。
4. rehash方法
我们回到set方法的最后:
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
可以看到当entry数组存储的个数大于某个阈值的时候,就会调用rehash方法
private int threshold;
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
private static final int INITIAL_CAPACITY = 16;
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY); // 初始设定阈值为默认容量*2/3
}
这个阈值我们从上面的代码可以看到是通过setThreshold函数来设定的,具体为entry数组长度的2/3。也就是说当entry数组中元素的个数大于2/3时,就会调用rehash函数:
private void rehash() {
expungeStaleEntries(); // 清除内存泄漏
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
我们可以看到,当个数大于0.75*threahold时就会调用resize函数进行扩容:
private void resize() {
Entry[] oldTab = table; // 旧的entry数组
int oldLen = oldTab.length; // 旧的长度
int newLen = oldLen * 2; // 扩容成原来长度的2倍
Entry[] newTab = new Entry[newLen]; // 创建新的entry数组
int count = 0;
for (int j = 0; j < oldLen; ++j) { // 遍历旧的entry数组
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get(); // 获得entry的key
if (k == null) { // 如果出现内存泄漏
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1); // 重新计算位置
while (newTab[h] != null)
h = nextIndex(h, newLen); // 开放定址法
newTab[h] = e; // 插入到新的entry数组
count++;
}
}
}
setThreshold(newLen); // 重新设置阈值
size = count;
table = newTab;
}
从resize函数可以看到,新的entry数组长度为原来的2倍,会将原来的entry移动到新位置上面。
5. getEntry方法
聊完了set方法,我们肯定要聊一下get方法了,所以我们进入到getEntry函数中:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);// 计算位置
Entry e = table[i];
if (e != null && e.get() == key) // 如果发现了一样的key,就直接返回
return e;
else
return getEntryAfterMiss(key, i, e); // 没有发现就进入getEntryAfterMiss函数继续寻找
}
如果没有在该有的位置找到对应的entry,就会进入getEntryAfterMiss继续寻找:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table; // 获取entry数组
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get(); // 获取entry
if (k == key) // 找到了就直接返回
return e;
if (k == null) // 发现内存泄漏
expungeStaleEntry(i); // 清理内存泄漏
else
i = nextIndex(i, len); // 下一个位置
e = tab[i];
}
return null; // 没找到就返回null
}
可以看到,getEntryAfterMiss就是不断通过向后查询,找到想要的entry,期间还会不断清理内存泄漏。
6. remove方法
private void remove(ThreadLocal<?> key) {
Entry[] tab = table; // 获得entry数组
int len = tab.length;
int i = key.threadLocalHashCode & (len-1); // 计算本来该在的位置
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) { // 向后寻找
if (e.get() == key) { // 如果发现了
e.clear(); // 清除
expungeStaleEntry(i); // 清理内存泄漏
return;
}
}
}
remove方法很简单,就是向后寻找,发现了就直接清理。
7. ThreadLocal使用场景
ThreadLocal不是用来解决共享对象的多线程访问问题,而是每个线程拥有自己的专属容器,各个线程之间不会相互影响。由于SimpleDateFormat在共享对象的情况下是会出现安全问题,具体原因可以参考:SimpleDateFormat线程不安全及解决办法。这里我们利用ThreadLocal来解决这个问题:
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadLocalDemo {
public static ThreadLocal<SimpleDateFormat> threadLocal = new ThreadLocal<SimpleDateFormat>();
static class TestSimpleDateFormat implements Runnable{
String date;
public TestSimpleDateFormat(String date){
this.date = date;
}
@Override
public void run() {
if(threadLocal.get()==null){
threadLocal.set(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
}else{
try{
Date date = threadLocal.get().parse(this.date);
System.out.println(date);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
final ExecutorService executorService = Executors.newFixedThreadPool(10);
for(int i=0;i<100;i++){
executorService.execute(new TestSimpleDateFormat("2022-12-01 15:30:"+i%60));
}
}
}
上面的代码中,本质实际上是多个线程之间共享同一个ThreadLocal。但是在每个线程又会单独执行set方法,也就是为每个线程的ThreadLocalMap中的threadlocal对象分别创建SimpleDateFormat。对应关系如下图所示:
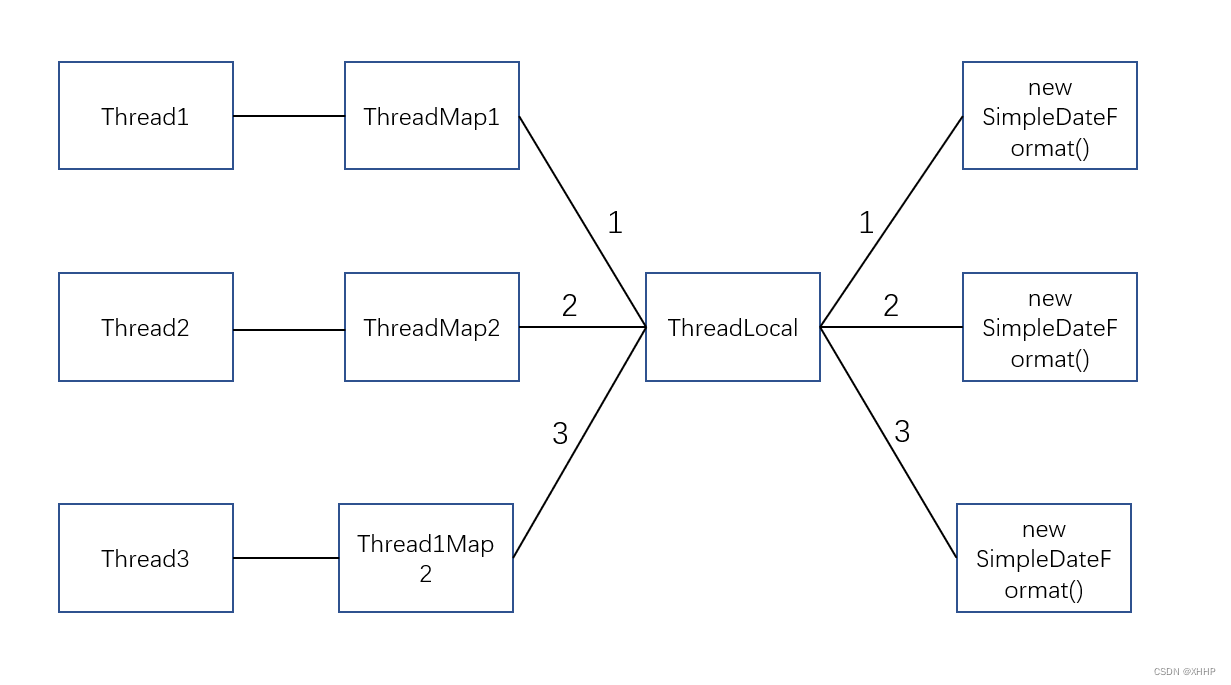
所以这里就能体现空间换时间的思想了
8. 为什么使用弱引用
通过前面的学习,我们知道ThreadLocalMap和ThreadLocal之间的关系是弱引用的,那为什么要使用弱引用呢?
如果使用强引用,假设业务代码想要让threadlocal被gc掉,所以代码中写入threadlocalInstance=null,按常理来说是能够被回收了。但是因为ThreadLocalMap和ThreadLocal之间为强引用,所以在gc的时候不会被回收,就出现了逻辑问题。
如果使用弱引用,就不会出现刚刚强引用的问题。虽然会出现内存泄漏的问题,但是在ThreadLocalMap的get、set、remove方法中都有内存泄漏回收机制,这在一定程度上可以缓解这个问题。并且,当线程结束时,也会将threadLocals置为null,进行回收掉。如下:
private void exit() {
if (threadLocals != null && TerminatingThreadLocal.REGISTRY.isPresent()) {
TerminatingThreadLocal.threadTerminated();
}
if (group != null) {
group.threadTerminated(this);
group = null;
}
/* Aggressively null out all reference fields: see bug 4006245 */
target = null;
/* Speed the release of some of these resources */
threadLocals = null;
inheritableThreadLocals = null;
inheritedAccessControlContext = null;
blocker = null;
uncaughtExceptionHandler = null;
}
参考文章:
强软弱虚引用,只有体会过了,才能记住
并发容器之ThreadLocal
一篇文章,从源码深入详解ThreadLocal内存泄漏问题
SimpleDateFormat线程不安全及解决办法