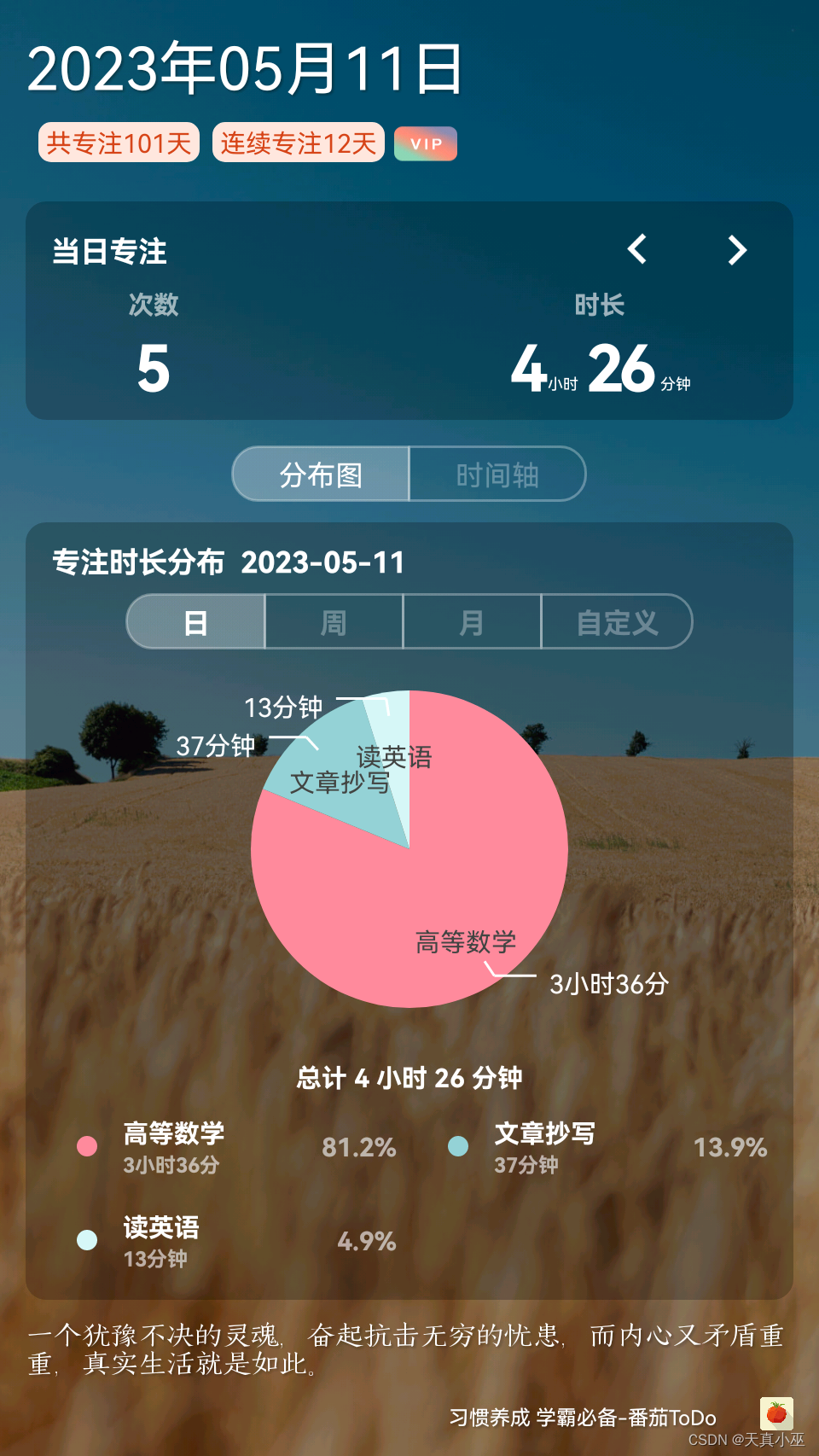
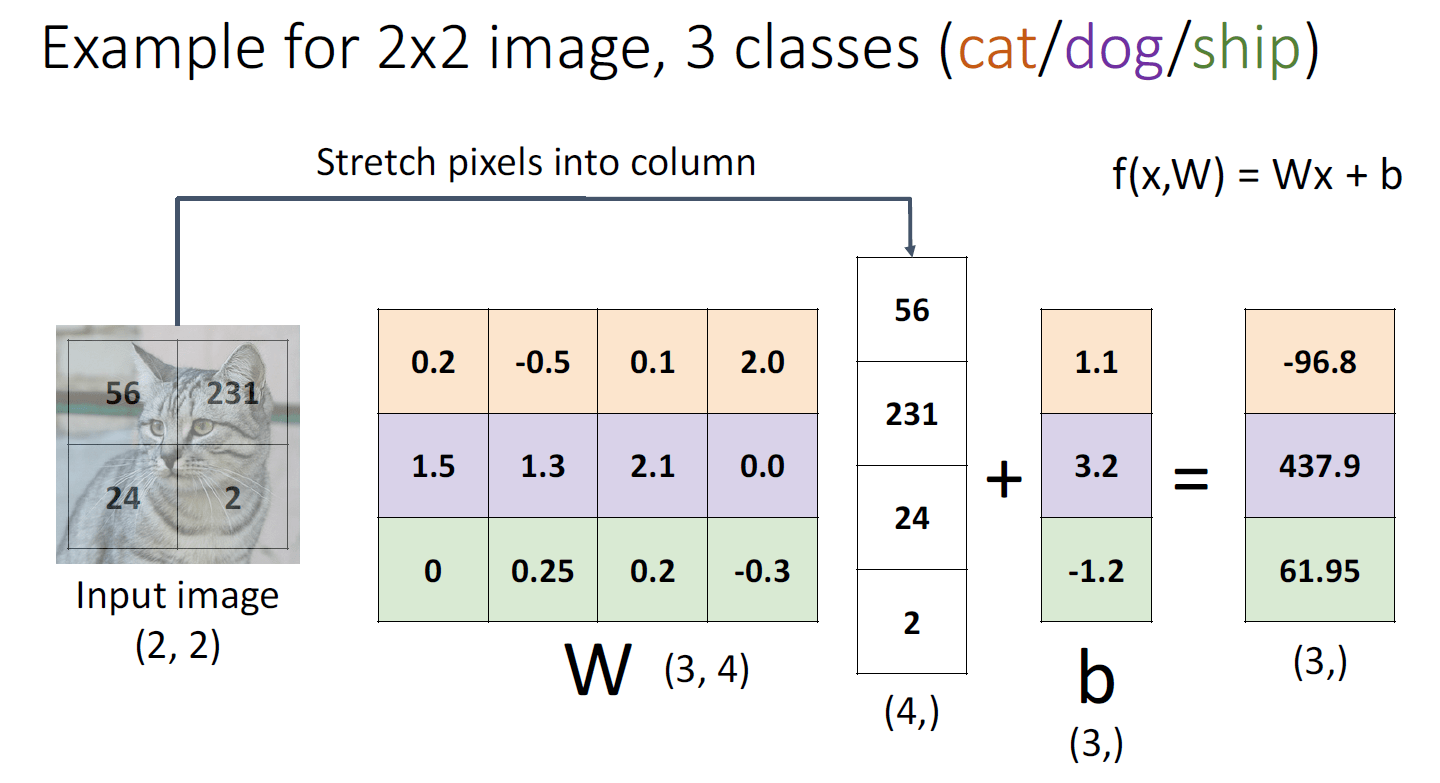
注意到每一行完成一类的分类
事先思考一下loss的可能值有助于debug。如果W随机为高斯分布,μ为0.001,那么下面sj-syi就会很小,Li的值接近C-1,C为分类数

正则化表达式:

如果score都是随机很小的数,近似意义上最后每一个类得到的
L
i
=
1
C
,
−
log
(
L
i
)
=
log
(
C
)
L_i=\frac{1}{C},-\log \left( L_i \right) =\log \left( C \right)
Li=C1,−log(Li)=log(C),在CIFAR10上有十类,所以平均来看Li约等于log(10) = 2.3。
所以如果写在C10上的线性分类器,一开始的单类loss不在2.3附近,很可能代码有bug。
所以一开始能估计出loss的大概值是很有用的。