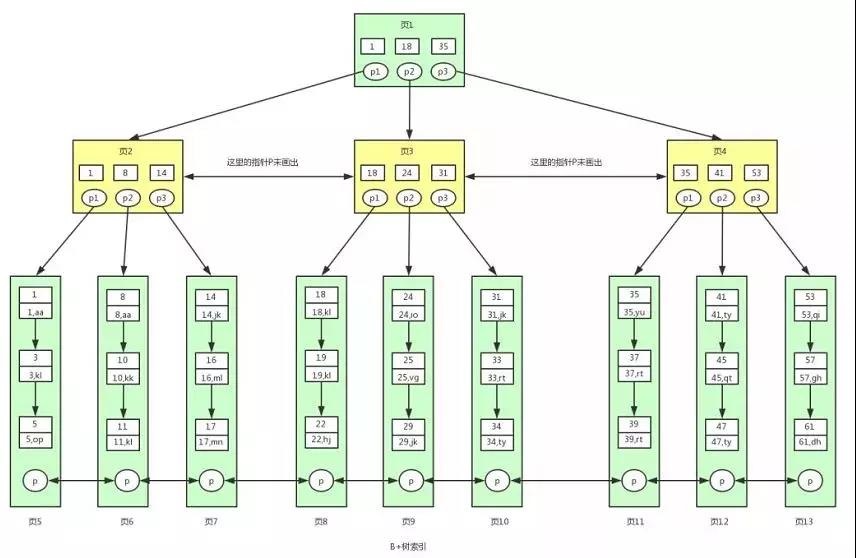
PostgresML 是 PostgreSQL 的机器学习扩展,支持生成式AI,使你能够使用 SQL 查询对文本和表格数据执行训练和推理。 借助 PostgresML,你可以将机器学习模型无缝集成到你的 PostgreSQL 数据库中,并利用尖端算法的强大功能来高效地处理数据。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
PostGresML可以处理文本数据,例如:
- 执行自然语言处理 (NLP) 任务,例如情感分析、问答、翻译、摘要和文本生成
从 🤗 HuggingFace 模型中心访问 1000 种最先进的语言模型,如 GPT-2、GPT-J、GPT-Neo - 针对不同任务在您自己的文本数据上微调大型语言模型 (LLM)
- 通过从数据库中存储的文本生成嵌入,将现有的 PostgreSQL 数据库用作矢量数据库。
使用如下SQL语句执行文本翻译:
SELECT pgml.transform(
'translation_en_to_fr',
inputs => ARRAY[
'Welcome to the future!',
'Where have you been all this time?'
]
) AS french;
结果:
french
------------------------------------------------------------
[
{"translation_text": "Bienvenue à l'avenir!"},
{"translation_text": "Où êtes-vous allé tout ce temps?"}
]
使用如下SQL语句执行文本情感分析:
SELECT pgml.transform(
task => 'text-classification',
inputs => ARRAY[
'I love how amazingly simple ML has become!',
'I hate doing mundane and thankless tasks. ☹️'
]
) AS positivity;
结果:
positivity
------------------------------------------------------
[
{"label": "POSITIVE", "score": 0.9995759129524232},
{"label": "NEGATIVE", "score": 0.9903519749641418}
]
PostgresML也可以处理表格数据,例如:
- 47 种以上的分类和回归算法
- 推理速度比基于 HTTP 的模型服务快 8 - 40 倍
- 每秒数百万笔交易
- 水平可扩展性
使用如下SQL语句训练分类模型:
SELECT * FROM pgml.train(
'Handwritten Digit Image Classifier',
algorithm => 'xgboost',
'classification',
'pgml.digits',
'target'
);
执行推理任务:
SELECT pgml.predict(
'My Classification Project',
ARRAY[0.1, 2.0, 5.0]
) AS prediction;
1、安装
PostgresML 安装由三部分组成:PostgreSQL 数据库、用于机器学习的 Postgres 扩展和仪表板应用程序。 该扩展提供了所有机器学习功能,并且可以通过任何 SQL IDE 独立使用。 仪表板应用程序提供了一个易于使用的界面,用于编写 SQL 笔记本、执行和跟踪 ML 实验和 ML 模型。
使用Docker的安装步骤如下:
第 1 步:克隆此存储库
git clone git@github.com:postgresml/postgresml.git
第 2 步:启动 dockerized 服务。 PostgresML 将在端口 5433 上运行,以防万一你已经在运行 Postgres。 可以在此处找到 Docker 安装说明。
cd postgresml
docker-compose up
第 3 步:使用 SQL IDE 或 psql 连接到 Postgres
postgres://postgres@localhost:5433/pgml_development
2、快速上手
在本地安装时,转到位于localhost的仪表板应用程序以使用 SQL 笔记本。
在托管控制台上单击“仪表板”按钮以使用 SQL 笔记本连接到你的实例。
试用预建的 SQL 笔记本
3、自然语言处理任务
PostgresML 集成了🤗 Hugging Face Transformers,将最先进的 NLP 模型带入数据层。 有数以万计的带有管道的预训练模型可以将数据库中的原始文本转化为有用的结果。 许多最先进的深度学习架构已经发布并可从 Hugging Face 模型中心获取。
可以使用以下 SQL 查询调用不同的 NLP 任务并使用它们进行自定义。
SELECT pgml.transform(
task => TEXT OR JSONB, -- Pipeline initializer arguments
inputs => TEXT[] OR BYTEA[], -- inputs for inference
args => JSONB -- (optional) arguments to the pipeline.
)
3.1 文本分类
文本分类涉及为给定文本分配标签或类别。 常见用例包括情感分析、自然语言推理和语法正确性评估。
3.2 情绪分析
情感分析是一种自然语言处理技术,涉及分析一段文本以确定其中表达的情感或情感。 它可用于将文本分类为正面、负面或中性,在市场营销、客户服务和政治分析等领域有着广泛的应用。
基本用法:
SELECT pgml.transform(
task => 'text-classification',
inputs => ARRAY[
'I love how amazingly simple ML has become!',
'I hate doing mundane and thankless tasks. ☹️'
]
) AS positivity;
结果:
[
{"label": "POSITIVE", "score": 0.9995759129524232},
{"label": "NEGATIVE", "score": 0.9903519749641418}
]
用于文本分类的默认模型是 DistilBERT-base-uncased 的微调版本,它专门针对 Stanford Sentiment Treebank 数据集 (sst2) 进行了优化。
使用特定模型
要使用 Hugging Face 上可用的 19,000 多个模型之一,请将所需模型的名称和文本分类任务作为 JSONB 对象包含在 SQL 查询中。 例如,如果你想要使用在大约 40,000 条英语推文上训练的 RoBERTa 模型,并且其类别具有 POS(正面)、NEG(负面)和 NEU(中性)标签,请在制作你的 JSONB 对象时包含此信息 询问。
SELECT pgml.transform(
inputs => ARRAY[
'I love how amazingly simple ML has become!',
'I hate doing mundane and thankless tasks. ☹️'
],
task => '{"task": "text-classification",
"model": "finiteautomata/bertweet-base-sentiment-analysis"
}'::JSONB
) AS positivity;
结果:
[
{"label": "POS", "score": 0.992932200431826},
{"label": "NEG", "score": 0.975599765777588}
]
使用行业特定模型
通过选择专为特定行业设计的模型,你可以实现更准确和相关的文本分类。 此类模型的一个示例是 FinBERT,这是一种预训练的 NLP 模型,已针对分析金融文本中的情绪进行了优化。 FinBERT 是通过在大型金融语料库上训练 BERT 语言模型,并对其进行微调以专门对金融情绪进行分类而创建的。 使用 FinBERT 时,该模型将为三种不同的标签提供 softmax 输出:正、负或中性。
SELECT pgml.transform(
inputs => ARRAY[
'Stocks rallied and the British pound gained.',
'Stocks making the biggest moves midday: Nvidia, Palantir and more'
],
task => '{"task": "text-classification",
"model": "ProsusAI/finbert"
}'::JSONB
) AS market_sentiment;
结果:
[
{"label": "positive", "score": 0.8983612656593323},
{"label": "neutral", "score": 0.8062630891799927}
]
3.3 自然语言推理 (NLI)
NLI,即自然语言推理,是一种确定两个文本之间关系的模型。 该模型将前提和假设作为输入并返回一个类,该类可以是以下三种类型之一:
- 蕴涵(Entailment):这意味着假设基于前提是正确的。
- 矛盾(Contradiction):这意味着根据前提假设是错误的。
- 中性(Neutral):这意味着假设和前提之间没有关系。
GLUE 数据集是评估 NLI 模型的基准数据集。 NLI 模型有不同的变体,例如 Multi-Genre NLI、Question NLI 和 Winograd NLI。
如果你想使用 NLI 模型,可以在 🤗 Hugging Face 模型中心找到它们。 寻找带有“mnli”的模型。
SELECT pgml.transform(
inputs => ARRAY[
'A soccer game with multiple males playing. Some men are playing a sport.'
],
task => '{"task": "text-classification",
"model": "roberta-large-mnli"
}'::JSONB
) AS nli;
结果:
[
{"label": "ENTAILMENT", "score": 0.98837411403656}
]
3.4 问题自然语言推理 (QNLI)
QNLI 任务涉及确定给定的问题是否可以通过提供的文档中的信息来回答。 如果可以在文档中找到答案,则分配的标签是“蕴含”。 反之,如果在文档中找不到答案,则打上“不蕴涵”的标签。
如果想使用 QNLI 模型,可以在 🤗 Hugging Face 模型中心找到它们。 寻找带有“qnli”的模型。
SELECT pgml.transform(
inputs => ARRAY[
'Where is the capital of France?, Paris is the capital of France.'
],
task => '{"task": "text-classification",
"model": "cross-encoder/qnli-electra-base"
}'::JSONB
) AS qnli;
结果:
[
{"label": "LABEL_0", "score": 0.9978110194206238}
]
3.5 Quora 问题对 (QQP)
Quora 问题对模型旨在评估两个给定问题是否是彼此的释义。 该模型接受两个问题并分配一个二进制值作为输出。 LABEL_0 表示问题是彼此的释义,LABEL_1 表示问题不是释义。 用于此任务的基准数据集是 GLUE 基准中的 Quora 问题对数据集,其中包含问题对及其相应标签的集合。
如果想使用 QQP 模型,可以在 🤗 Hugging Face 模型中心找到它们。 寻找带有qqp的模型。
SELECT pgml.transform(
inputs => ARRAY[
'Which city is the capital of France?, Where is the capital of France?'
],
task => '{"task": "text-classification",
"model": "textattack/bert-base-uncased-QQP"
}'::JSONB
) AS qqp;
结果:
[
{"label": "LABEL_0", "score": 0.9988721013069152}
]
3.6 语法正确性评估
语言可接受性是一项涉及评估句子语法正确性的任务。 用于此任务的模型将两个类别之一分配给句子,“可接受”或“不可接受”。 LABEL_0 表示可接受,LABEL_1 表示不可接受。 用于训练和评估此任务模型的基准数据集是语言可接受性语料库 (CoLA),它由一组文本及其相应的标签组成。
如果想使用语法正确性模型,可以在 🤗 Hugging Face 模型中心找到它们。 寻找可乐模型。
SELECT pgml.transform(
inputs => ARRAY[
'I will walk to home when I went through the bus.'
],
task => '{"task": "text-classification",
"model": "textattack/distilbert-base-uncased-CoLA"
}'::JSONB
) AS grammatical_correctness;
结果:
[
{"label": "LABEL_1", "score": 0.9576480388641356}
]
3.7 零样本分类
零样本分类是一项任务,其中模型预测它在训练阶段未见过的类。 此任务利用预训练的语言模型,是一种迁移学习。 迁移学习涉及使用最初针对不同应用程序中的一项任务进行训练的模型。 当缺乏可用于手头特定任务的标记数据时,零样本分类特别有用。
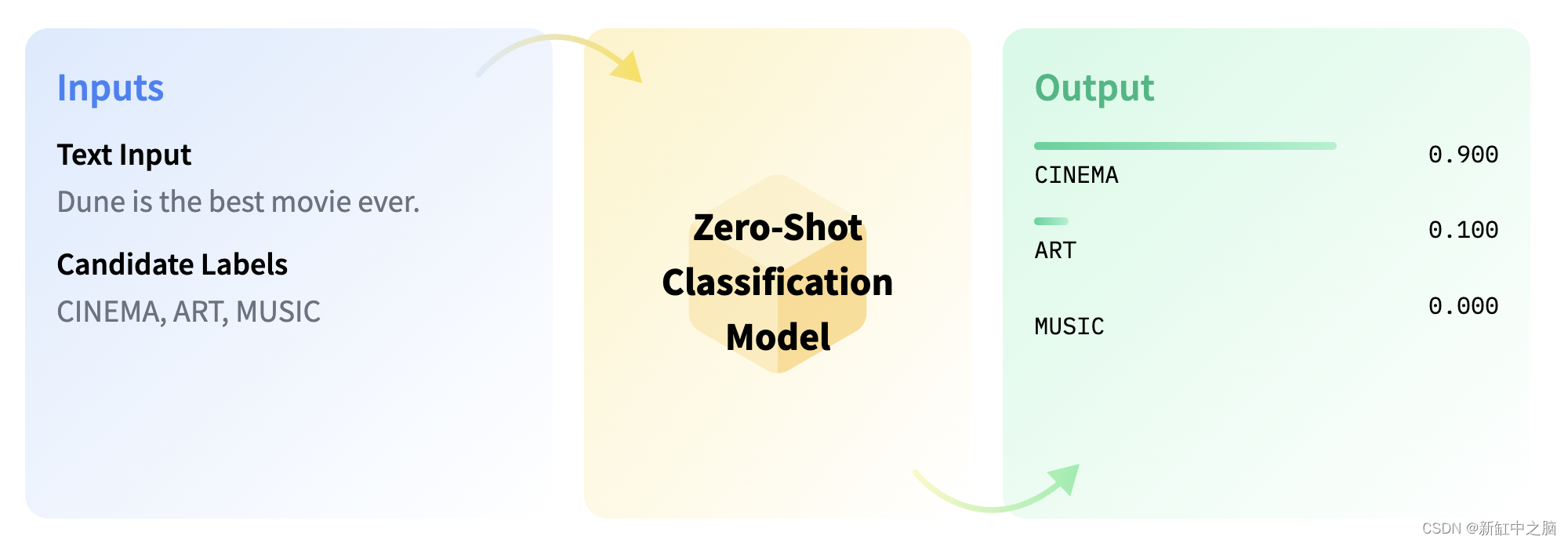
在下面提供的示例中,我们将演示如何将给定句子分类到模型之前未遇到过的类别中。 为此,我们在 SQL 查询中使用了 args,它允许我们提供 candidate_labels。 您可以自定义这些标签以适合您的任务上下文。 我们将使用 facebook/bart-large-mnli 模型。
在 🤗 Hugging Face 模型中心寻找具有 mnli 的模型以使用零样本分类模型。
SELECT pgml.transform(
inputs => ARRAY[
'I have a problem with my iphone that needs to be resolved asap!!'
],
task => '{
"task": "zero-shot-classification",
"model": "facebook/bart-large-mnli"
}'::JSONB,
args => '{
"candidate_labels": ["urgent", "not urgent", "phone", "tablet", "computer"]
}'::JSONB
) AS zero_shot;
结果:
[
{
"labels": ["urgent", "phone", "computer", "not urgent", "tablet"],
"scores": [0.503635, 0.47879, 0.012600, 0.002655, 0.002308],
"sequence": "I have a problem with my iphone that needs to be resolved asap!!"
}
]
3.8 Token分类
Token分类是自然语言理解中的一项任务,其中将标签分配给文本中的某些标记。 令牌分类的一些流行子任务包括命名实体识别 (NER) 和词性 (PoS) 标记。 可以训练 NER 模型来识别文本中的特定实体,例如个人、地点和日期。 另一方面,词性标注用于识别文本中不同的词性,例如名词、动词和标点符号。
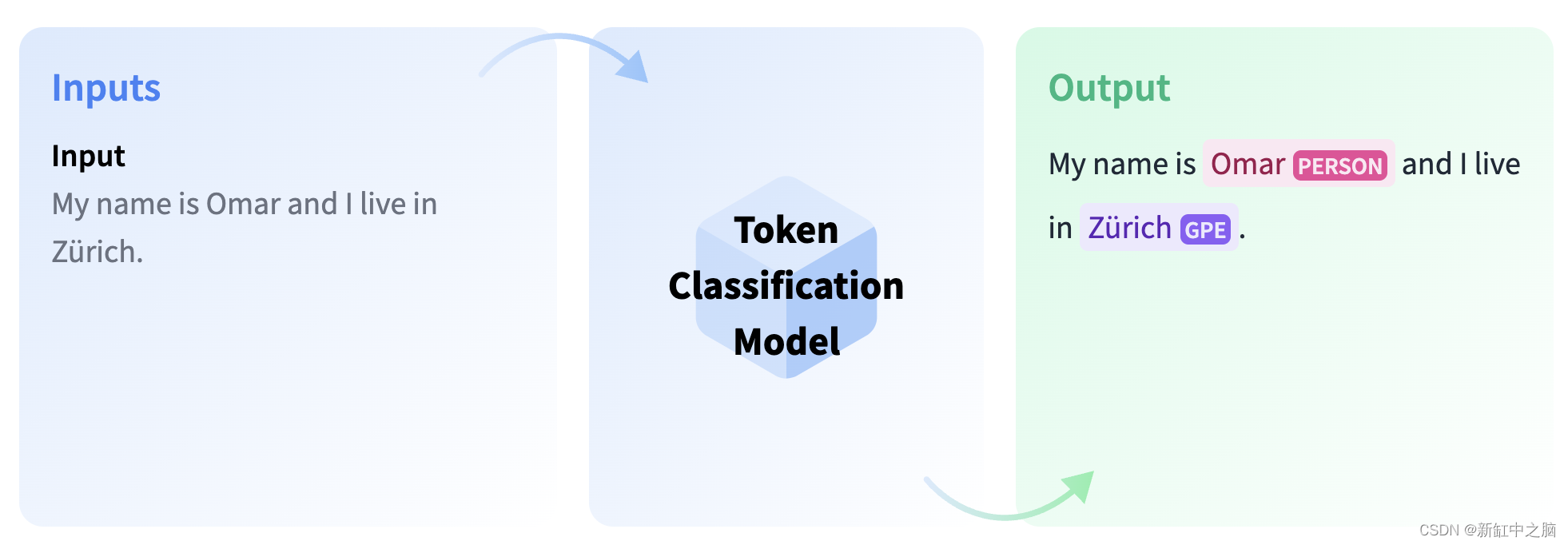
3.9 命名实体识别
命名实体识别 (NER) 是一项涉及识别文本中命名实体的任务。 这些实体可以包括人名、地点或组织的名称。 该任务是通过为每个命名实体标记一个类和为不包含任何实体的标记标记一个名为“0”的类来完成的。 在此任务中,输入是文本,输出是带有命名实体的注释文本。
SELECT pgml.transform(
inputs => ARRAY[
'I am Omar and I live in New York City.'
],
task => 'token-classification'
) as ner;
结果:
[[
{"end": 9, "word": "Omar", "index": 3, "score": 0.997110, "start": 5, "entity": "I-PER"},
{"end": 27, "word": "New", "index": 8, "score": 0.999372, "start": 24, "entity": "I-LOC"},
{"end": 32, "word": "York", "index": 9, "score": 0.999355, "start": 28, "entity": "I-LOC"},
{"end": 37, "word": "City", "index": 10, "score": 0.999431, "start": 33, "entity": "I-LOC"}
]]
3.10 词性 (PoS) 标注
词性标注是一项涉及识别给定文本中词性的任务,例如名词、代词、形容词或动词。 在此任务中,模型用特定的词性标记每个单词。
在 🤗 Hugging Face 模型中心寻找具有 pos 的模型以使用零样本分类模型。
select pgml.transform(
inputs => array [
'I live in Amsterdam.'
],
task => '{"task": "token-classification",
"model": "vblagoje/bert-english-uncased-finetuned-pos"
}'::JSONB
) as pos;
结果:
[[
{"end": 1, "word": "i", "index": 1, "score": 0.999, "start": 0, "entity": "PRON"},
{"end": 6, "word": "live", "index": 2, "score": 0.998, "start": 2, "entity": "VERB"},
{"end": 9, "word": "in", "index": 3, "score": 0.999, "start": 7, "entity": "ADP"},
{"end": 19, "word": "amsterdam", "index": 4, "score": 0.998, "start": 10, "entity": "PROPN"},
{"end": 20, "word": ".", "index": 5, "score": 0.999, "start": 19, "entity": "PUNCT"}
]]
3.11 翻译
翻译是将用一种语言编写的文本转换成另一种语言的任务
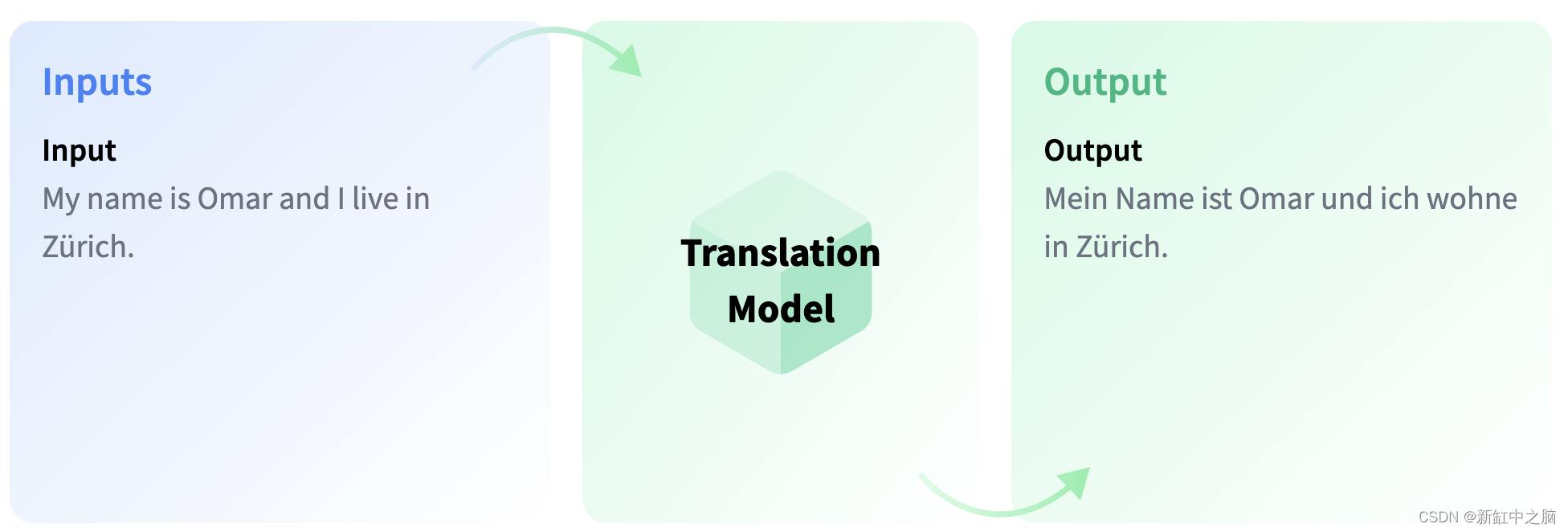
可以选择从 Hugging Face 中心提供的 2000 多个模型中进行选择以进行翻译。
select pgml.transform(
inputs => array[
'How are you?'
],
task => '{"task": "translation",
"model": "Helsinki-NLP/opus-mt-en-fr"
}'::JSONB
);
结果:
[
{"translation_text": "Comment allez-vous ?"}
]
3.12 总结摘要
摘要涉及创建文档的压缩版本,其中包含重要信息,同时减少其长度。 不同的模型可以用于此任务,一些模型从原始文档中提取最相关的文本,而其他模型生成全新的文本,捕捉原始内容的本质。
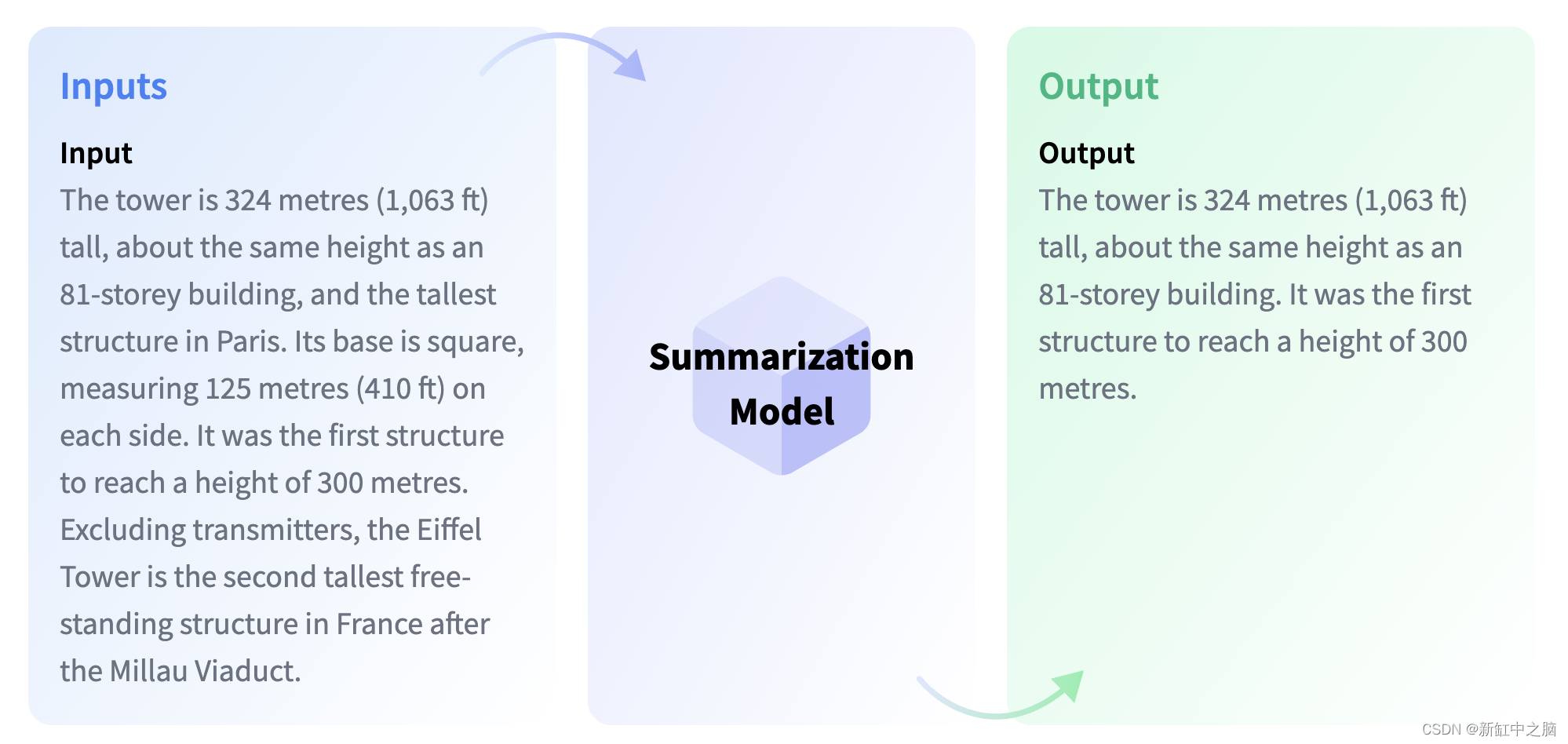
select pgml.transform(
task => '{"task": "summarization",
"model": "sshleifer/distilbart-cnn-12-6"
}'::JSONB,
inputs => array[
'Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.'
]
);
结果:
[
{"summary_text": " Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018 . The city is the centre and seat of government of the region and province of Île-de-France, or Paris Region . Paris Region has an estimated 18 percent of the population of France as of 2017 ."}
]
你可以通过将 min_length 和 max_length 作为参数传递给 SQL 查询来控制 summary_text 的长度。
select pgml.transform(
task => '{"task": "summarization",
"model": "sshleifer/distilbart-cnn-12-6"
}'::JSONB,
inputs => array[
'Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.'
],
args => '{
"min_length" : 20,
"max_length" : 70
}'::JSONB
);
结果:
[
{"summary_text": " Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018 . City of Paris is centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated 12,174,880, or about 18 percent"
}
]
3.13 问答
问答模型旨在从给定文本中检索问题的答案,这对于在文档中搜索信息特别有用。 值得注意的是,一些问答模型即使没有任何上下文信息也能够生成答案。
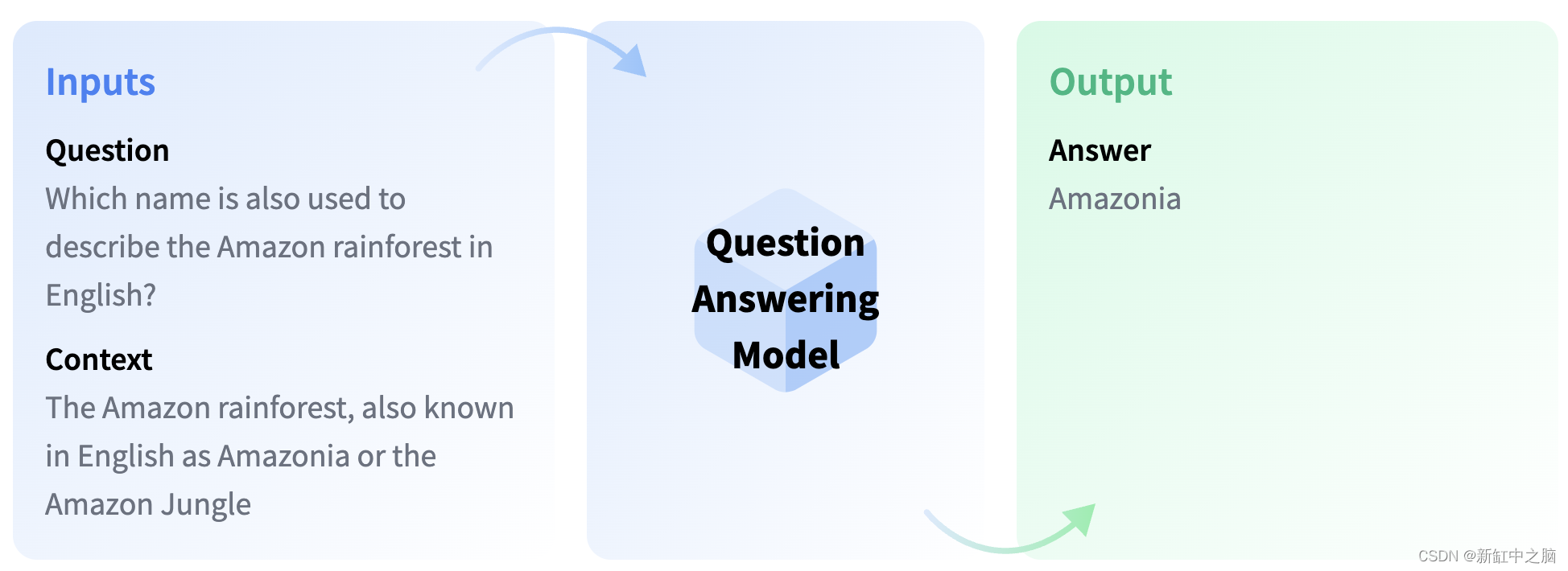
SELECT pgml.transform(
'question-answering',
inputs => ARRAY[
'{
"question": "Where do I live?",
"context": "My name is Merve and I live in İstanbul."
}'
]
) AS answer;
结果:
{
"end" : 39,
"score" : 0.9538117051124572,
"start" : 31,
"answer": "İstanbul"
}
3.14 文本生成
文本生成是生成新文本的任务,例如填充不完整的句子或释义现有文本。 它有各种用例,包括代码生成和故事生成。 完成生成模型可以预测文本序列中的下一个单词,而文本到文本生成模型被训练来学习文本对之间的映射,例如语言之间的翻译。 流行的文本生成模型包括基于 GPT 的模型、T5、T0 和 BART。 可以训练这些模型来完成范围广泛的任务,包括文本分类、摘要和翻译。
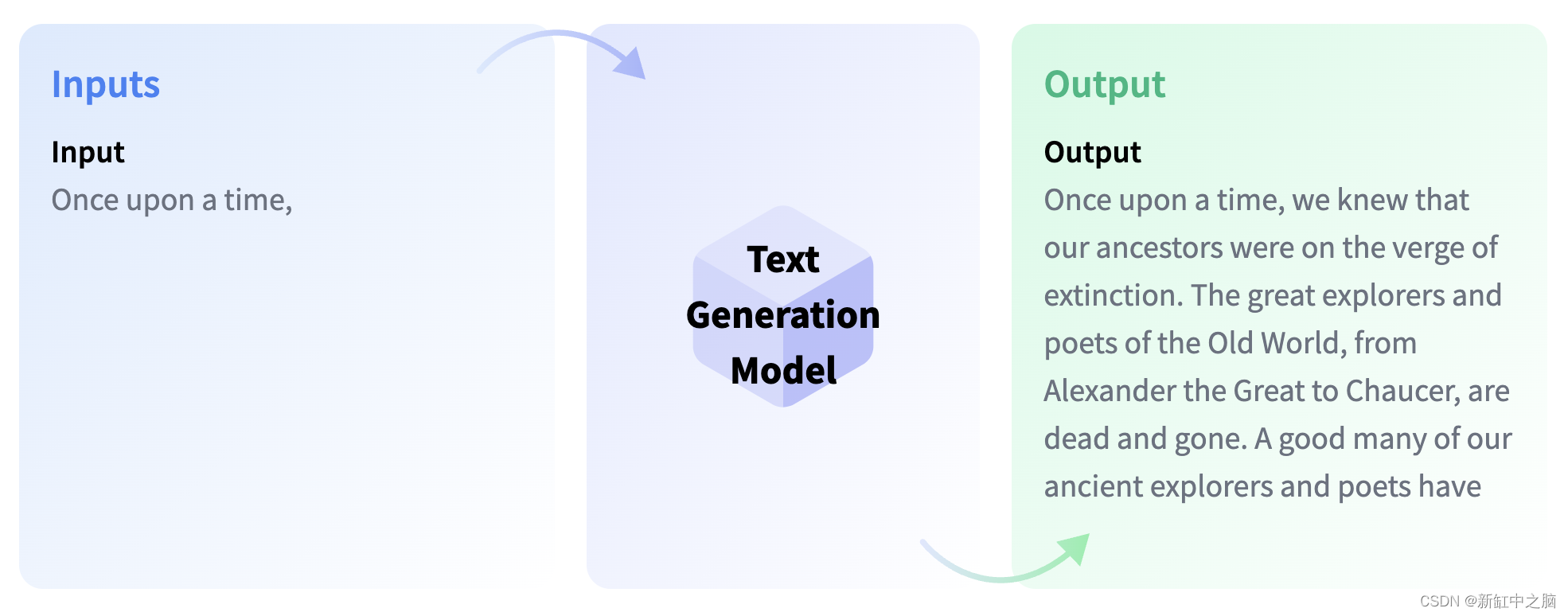
SELECT pgml.transform(
task => 'text-generation',
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
]
) AS answer;
结果:
[
[
{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, and eight for the Dragon-lords in their halls of blood.\n\nEach of the guild-building systems is one-man"}
]
]
要使用 🤗 模型中心的特定模型,请在任务中传递模型名称和任务名称。
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
]
) AS answer;
结果:
[
[{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone.\n\nThis place has a deep connection to the lore of ancient Elven civilization. It is home to the most ancient of artifacts,"}]
]
要使生成的文本更长,可以包含参数 max_length 并指定所需的最大文本长度。
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
],
args => '{
"max_length" : 200
}'::JSONB
) AS answer;
结果:
[
[{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Three for the Dwarfs and the Elves, One for the Gnomes of the Mines, and Two for the Elves of Dross.\"\n\nHobbits: The Fellowship is the first book of J.R.R. Tolkien's story-cycle, and began with his second novel - The Two Towers - and ends in The Lord of the Rings.\n\n\nIt is a non-fiction novel, so there is no copyright claim on some parts of the story but the actual text of the book is copyrighted by author J.R.R. Tolkien.\n\n\nThe book has been classified into two types: fantasy novels and children's books\n\nHobbits: The Fellowship is the first book of J.R.R. Tolkien's story-cycle, and began with his second novel - The Two Towers - and ends in The Lord of the Rings.It"}]
]
如果你希望模型生成多个输出,可以通过在参数中包含参数 num_return_sequences 来指定所需输出序列的数量。
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
],
args => '{
"num_return_sequences" : 3
}'::JSONB
) AS answer;
结果:
[
[
{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, and Thirteen for the human-men in their hall of fire.\n\nAll of us, our families, and our people"},
{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, and the tenth for a King! As each of these has its own special story, so I have written them into the game."},
{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone… What's left in the end is your heart's desire after all!\n\nHans: (Trying to be brave)"}
]
]
文本生成通常使用贪婪搜索算法,该算法选择概率最高的词作为序列中的下一个词。 然而,可以使用一种称为波束搜索的替代方法,其目的是最大限度地减少忽略隐藏的高概率单词组合的可能性。 Beam search 通过在每一步保留 num_beams 个最有可能的假设并最终选择具有最高总体概率的假设来实现这一点。 我们设置 num_beams > 1 和 early_stopping=True 以便在所有光束假设达到 EOS 令牌时完成生成。
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
],
args => '{
"num_beams" : 5,
"early_stopping" : true
}'::JSONB
) AS answer;
结果:
[[
{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Nine for the Dwarves in their caverns of ice, Ten for the Elves in their caverns of fire, Eleven for the"}
]]
抽样方法涉及从一组可能的候选词中随机选择下一个词或词序列,根据语言模型按它们的概率加权。 这可以产生更加多样化和创造性的文本,并避免重复的模式。 在最基本的形式中,抽样意味着随机选择下一个单词
根据其条件概率分布:
w
t
≈
P
(
w
t
∣
w
1
:
t
−
1
)
w_t \approx P(w_t|w_{1:t-1})
wt≈P(wt∣w1:t−1)
但是,采样方法的随机性也会导致文本连贯性降低或不一致,具体取决于模型的质量和所选的采样参数,例如温度、top-k 或 top-p。 因此,选择合适的采样方法和参数对于在生成的文本中实现创造性和连贯性之间的理想平衡至关重要。
可以在参数中传递 do_sample = True 以使用采样方法。 建议改变 temperature 或 top_p 但不能同时改变两者。
温度:
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
],
args => '{
"do_sample" : true,
"temperature" : 0.9
}'::JSONB
) AS answer;
结果:
[[{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, and Thirteen for the Giants and Men of S.A.\n\nThe First Seven-Year Time-Traveling Trilogy is"}]]
top n:
SELECT pgml.transform(
task => '{
"task" : "text-generation",
"model" : "gpt2-medium"
}'::JSONB,
inputs => ARRAY[
'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone'
],
args => '{
"do_sample" : true,
"top_p" : 0.8
}'::JSONB
) AS answer;
结果:
[[{"generated_text": "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Four for the Elves of the forests and fields, and Three for the Dwarfs and their warriors.\" ―Lord Rohan [src"}]]
3.15 文本到文本生成
文本到文本生成方法,例如 T5,是一种神经网络架构,旨在执行各种自然语言处理任务,包括摘要、翻译和问答。 T5 是一种基于转换器的架构,使用去噪自动编码对大量文本数据进行预训练。 这个预训练过程使模型能够学习通用语言模式和不同任务之间的关系,可以针对特定的下游任务进行微调。 在微调期间,T5 模型在特定任务的数据集上进行训练,以学习如何执行特定任务。
翻译:
SELECT pgml.transform(
task => '{
"task" : "text2text-generation"
}'::JSONB,
inputs => ARRAY[
'translate from English to French: I''m very happy'
]
) AS answer;
结果:
[
{"generated_text": "Je suis très heureux"}
]
与其他任务类似,我们可以为文本到文本的生成指定一个模型。
SELECT pgml.transform(
task => '{
"task" : "text2text-generation",
"model" : "bigscience/T0"
}'::JSONB,
inputs => ARRAY[
'Is the word ''table'' used in the same meaning in the two previous sentences? Sentence A: you can leave the books on the table over there. Sentence B: the tables in this book are very hard to read.'
]
) AS answer;
3.17 填充掩码
Fill-mask 是指隐藏或“屏蔽”句子中的某些单词的任务,其目的是预测哪些单词应该填充那些屏蔽的位置。 当我们想要获得有关用于训练模型的语言的统计见解时,此类模型很有价值。
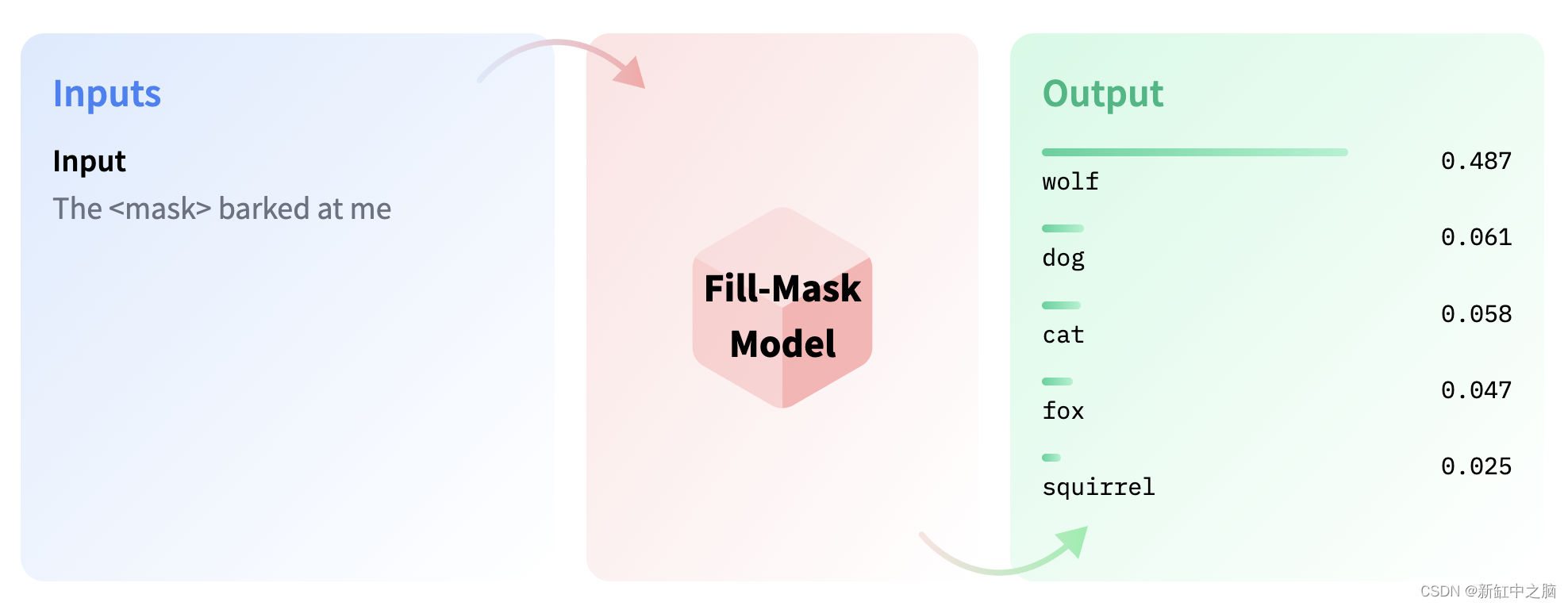
SELECT pgml.transform(
task => '{
"task" : "fill-mask"
}'::JSONB,
inputs => ARRAY[
'Paris is the <mask> of France.'
]
) AS answer;
结果:
[
{"score": 0.679, "token": 812, "sequence": "Paris is the capital of France.", "token_str": " capital"},
{"score": 0.051, "token": 32357, "sequence": "Paris is the birthplace of France.", "token_str": " birthplace"},
{"score": 0.038, "token": 1144, "sequence": "Paris is the heart of France.", "token_str": " heart"},
{"score": 0.024, "token": 29778, "sequence": "Paris is the envy of France.", "token_str": " envy"},
{"score": 0.022, "token": 1867, "sequence": "Paris is the Capital of France.", "token_str": " Capital"}]
4、矢量数据库
矢量数据库是一种存储和管理矢量的数据库,矢量是多维空间中数据点的数学表示。 矢量可用于表示范围广泛的数据类型,包括图像、文本、音频和数字数据。 它旨在使用最近邻搜索、聚类和索引等方法支持高效的向量搜索和检索。 这些方法使应用程序能够找到与给定查询向量相似的向量,这对于图像搜索、推荐系统和自然语言处理等任务很有用。
PostgresML 通过从存储在表中的文本生成嵌入来增强现有的 PostgreSQL 数据库以用作矢量数据库。 要生成嵌入,可以使用 pgml.embed 函数,该函数将转换器名称和文本值作为输入。 此功能会自动下载并缓存转换器以备将来重用,从而节省时间和资源。
使用矢量数据库涉及三个关键步骤:创建嵌入、使用不同算法为嵌入建立索引以及使用嵌入查询索引。 让我们更详细地分解每个步骤。
4.1 使用转换器创建嵌入
要为你的数据创建嵌入,首先需要选择一个可以从你的输入数据生成嵌入的转换器。 一些流行的钻换器选项包括 BERT、GPT-2 和 T5。 选择转换器后,可以使用它为数据生成嵌入。
在下一节中,我们将演示如何使用 PostgresML 为情感分析中常用的推文数据集生成嵌入。 为了生成嵌入,我们将使用 pgml.embed 函数,该函数将为数据集中的每条推文生成一个嵌入。 然后,这些嵌入将被插入到名为 tweet_embeddings 的表中。
SELECT pgml.load_dataset('tweet_eval', 'sentiment');
SELECT *
FROM pgml.tweet_eval
LIMIT 10;
CREATE TABLE tweet_embeddings AS
SELECT text, pgml.embed('distilbert-base-uncased', text) AS embedding
FROM pgml.tweet_eval;
SELECT * from tweet_embeddings limit 2;
结果:
| text | embedding |
|---|---|
| “QT @user In the original draft of the 7th book, Remus Lupin survived the Battle of Hogwarts. #HappyBirthdayRemusLupin” | {-0.1567948312,-0.3149209619,0.2163394839,…} |
| “Ben Smith / Smith (concussion) remains out of the lineup Thursday, Curtis #NHL #SJ” | {-0.0701668188,-0.012231146,0.1304316372,… } |
4.2 使用不同的算法对嵌入进行索引
为数据创建嵌入后,需要使用一种或多种索引算法对它们进行索引。 有几种不同类型的索引算法可用,包括 B 树、k 最近邻 (KNN) 和近似最近邻 (ANN)。 你选择的具体索引算法类型将取决于你的用例和性能要求。 例如,B 树是范围查询的不错选择,而 KNN 和 ANN 算法对于相似性搜索更有效。
在小型数据集(<100k 行)上,将每一行与查询进行比较的线性搜索将给出亚秒级结果,这对于你的用例来说可能足够快。 对于较大的数据集,你可能需要考虑其他扩展提供的各种索引策略。
Cube 是一个内置扩展,它提供了一种用于查找相似向量的快速索引策略。 默认情况下,它有 100 个维度的任意限制,除非 Postgres 以更大的尺寸编译。
PgVector 支持开箱即用的高达 2000 维的嵌入,并提供用于查找相似向量的快速索引策略。
在为你的嵌入编制索引时,重要的是要考虑准确性和速度之间的权衡。 像 B 树这样的精确索引算法可以提供精确的结果,但可能不如像 KNN 和 ANN 这样的近似索引算法那么快。 同样,某些索引算法可能需要比其他算法更多的内存或磁盘空间。
在下文中,我们使用 ivfflat 算法在 tweet_embeddings 表上创建索引以进行索引。 ivfflat 算法是一种混合索引,它结合了倒排文件 (IVF) 索引和平面 (FLAT) 索引。
索引是在 tweet_embeddings 表的嵌入列上创建的,该列包含从原始推文数据集生成的向量嵌入。 vector_cosine_ops 参数指定用于嵌入的索引操作。 在这种情况下,它使用余弦相似性运算,这是衡量向量之间相似性的常用方法。
通过在嵌入列上创建索引,数据库可以快速搜索和检索与给定查询向量相似的记录。 这对于各种机器学习应用程序很有用,例如相似性搜索或推荐系统。
CREATE INDEX ON tweet_embeddings USING ivfflat (embedding vector_cosine_ops);
4.3 使用查询的嵌入来查询索引
一旦你的嵌入被索引,就可以使用它们对您的数据库执行查询。 为此,你需要提供一个查询嵌入来表示要执行的查询。 然后,索引将根据查询嵌入和存储的嵌入之间的相似性,从你的数据库中返回最接近匹配的嵌入。
WITH query AS (
SELECT pgml.embed('distilbert-base-uncased', 'Star Wars christmas special is on Disney')::vector AS embedding
)
SELECT * FROM items, query ORDER BY items.embedding <-> query.embedding LIMIT 5;
结果:
| text |
|---|
| Happy Friday with Batman animated Series 90S forever! |
| “Fri Oct 17, Sonic Highways is on HBO tonight, Also new episode of Girl Meets World on Disney” |
| tfw the 2nd The Hunger Games movie is on Amazon Prime but not the 1st one I didn’t watch |
| 5 RT’s if you want the next episode of twilight princess tomorrow |
| Jurassic Park is BACK! New Trailer for the 4th Movie, Jurassic World - |
原文链接:PostgresML快速入门 — BimAnt