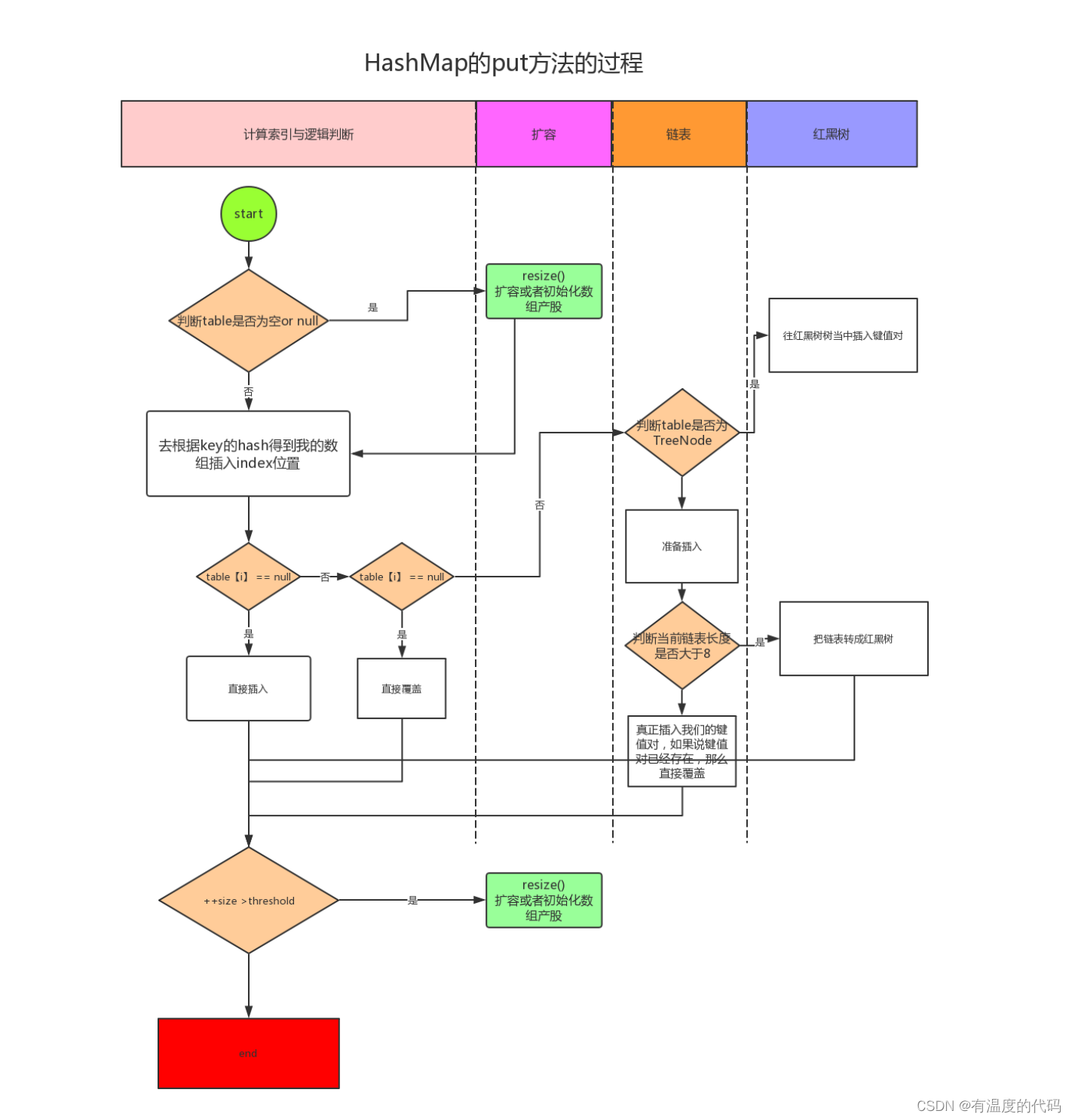
数据结构和算法的重要性不言而喻,一些优秀的开源项目的核心和灵魂就是数据结构、算法。在实际的编程中我们经常可以在各种框架、算法中看见B树、B+树的身影。特别是在数据库的数据库引擎中,它们更是占据着重要的地位。 下面我将通过简单的二叉树,到树的进化,多叉树(B树、B+树)的由来、作用、操作以及它们在实际中的应用依次进行详细说明。
B+树介绍
B+树是一种常用于数据库系统和文件系统的数据结构类型,主要用途是在磁盘上存储和索引大量的数据,以提高检索效率。B+树和B树非常相似,但有一个重要的区别:B+树只在叶节点存储数据,而非叶子节点只存储索引信息。这种结构使得B+树能够更好地适应磁盘读取方式,因为在磁盘上读取一条记录的成本非常高。B+树的叶节点形成了一个链表,可以很容易地实现范围查询。
它们旨在允许对大型数据集进行有效的搜索和索引,特别是那些存储在磁盘上的数据集。 在B+树中,数据存储在组织成树状结构的节点中。每个节点包含一系列键和指向子节点或数据记录的指针。树的根节点包含指向子节点的指针,而叶节点包含指向数据记录的指针。
B+树优点
B+树的主要优点之一是它们允许进行高效的范围查询,这在数据库应用中特别有用。这是因为每个节点中的键都是排序的,这使得遍历树以找到所需数据变得容易。
B+树被广泛应用于开源数据库项目中,如MySQL、PostgreSQL、SQLite等。其中,MySQL中的InnoDB存储引擎就使用了B+树作为索引结构。此外文件系统和键值对存储系统也常常使用B+树作为核心数据结构。
NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
B+ Tree Visualization
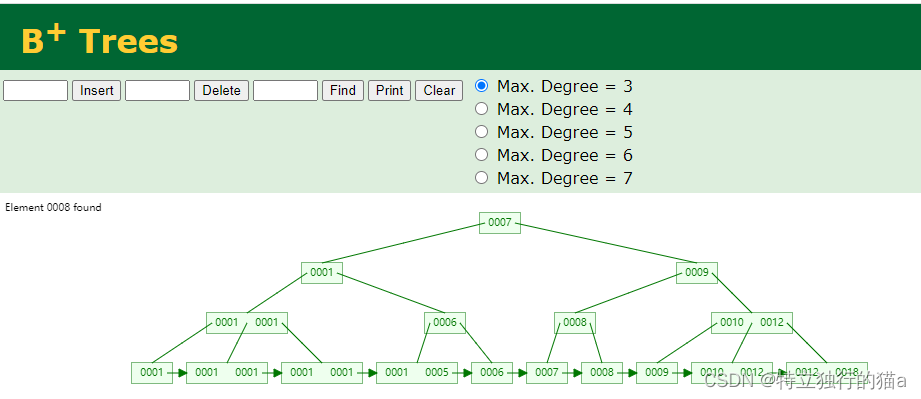
树形(4阶B+树)如下图所示:
B+树的由来
B+ 树,就是从二叉查找树,平衡二叉树和 B 树这三种数据结构演化来的。从二叉树起,看下B+树的演化由来。
二叉查找树
首先,让我们先看一张图:
编辑
从图中可以看到,我们为 user 表(用户信息表)建立了一个二叉查找树的索引。
图中的圆为二叉查找树的节点,节点中存储了键(key)和数据(data)。键对应 user 表中的 id,数据对应 user 表中的行数据。
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
如果我们需要查找 id=12 的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
- 将根节点作为当前节点,把 12 与当前节点的键值 10 比较,12 大于 10,接下来我们把当前节点>的右子节点作为当前节点。
- 继续把 12 和当前节点的键值 13 比较,发现 12 小于 13,把当前节点的左子节点作为当前节点。
- 把 12 和当前节点的键值 12 对比,12 等于 12,满足条件,我们从当前节点中取出 data,即 id=12,name=xm。
利用二叉查找树我们只需要 3 次即可找到匹配的数据。如果在表中一条条的查找的话,我们需要 6 次才能找到。
平衡二叉树
上面我们讲解了利用二叉查找树可以快速的找到数据。但是,如果上面的二叉查找树是这样的构造:
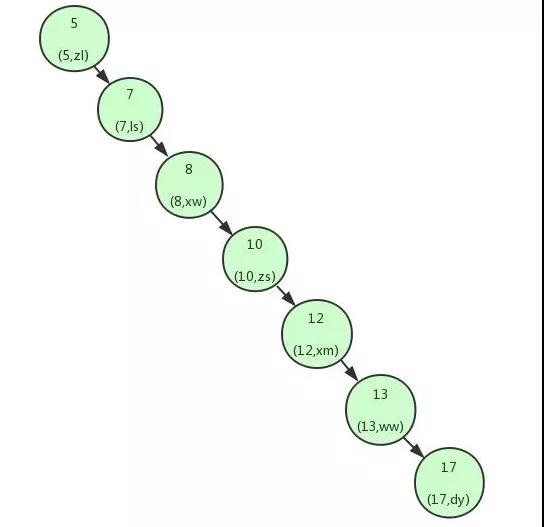
这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找 id=17 的用户信息,我们需要查找 7 次,也就相当于全表扫描了。
导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。
为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。
平衡二叉树又称 AVL 树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过 1。
下面是平衡二叉树和非平衡二叉树的对比:
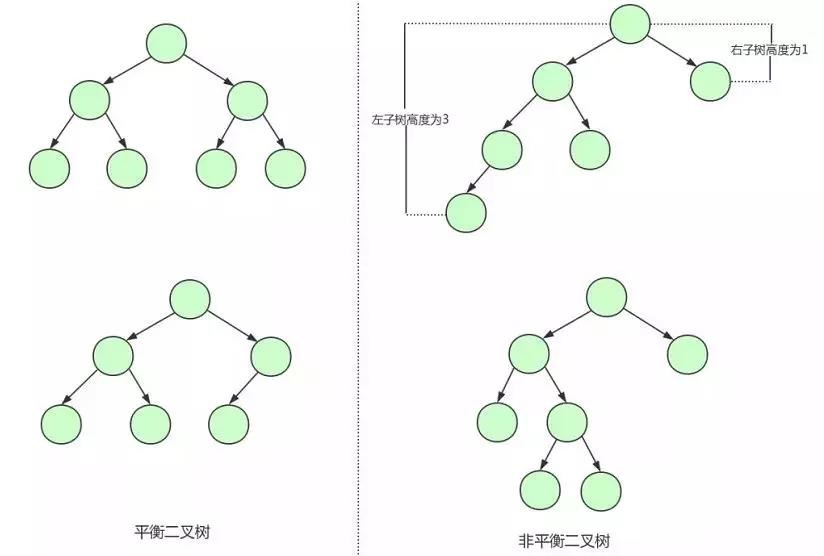
由平衡二叉树的构造我们可以发现第一张图中的二叉树其实就是一棵平衡二叉树。
平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。具体的调整方式这里就不介绍了。
平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
B 树
因为内存的易失性。一般情况下,我们都会选择将 user 表中的数据和索引存储在磁盘这种外围设备中。
但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数。
另外,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。
如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。
如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块。
我们都知道平衡二叉树可是每个节点只存储一个键值和数据的。那说明什么?说明每个磁盘块仅仅存储一个键值和数据!那如果我们要存储海量的数据呢?
可以想象到二叉树的节点将会非常多,高度也会极其高,我们查找数据时也会进行很多次磁盘 IO,我们查找数据的效率将会极低!
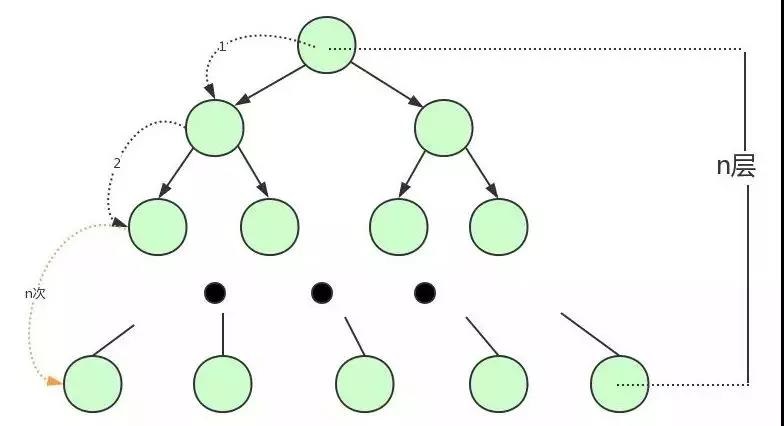
为了解决平衡二叉树的这个弊端,我们应该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的 B 树。
B 树(Balance Tree)即为平衡树的意思,下图即是一棵 B 树:
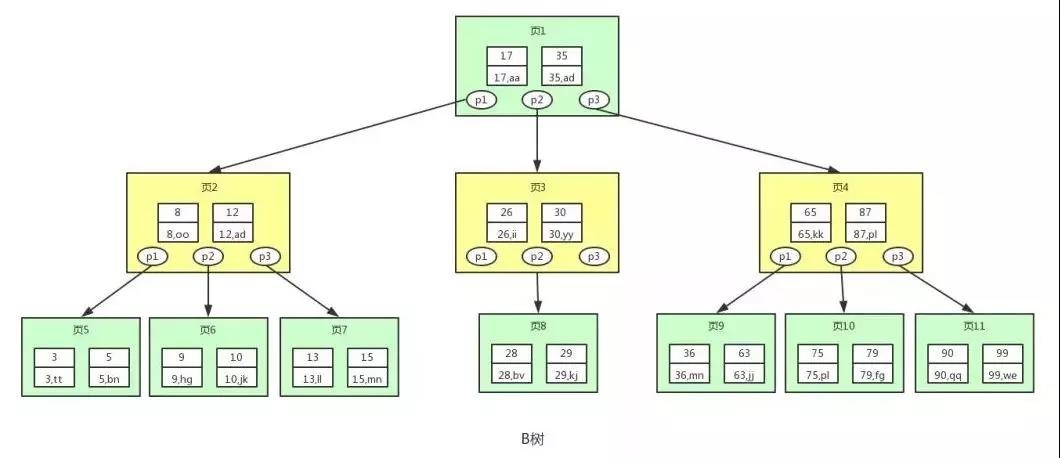
图中的 p 节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,因为图的美观性,被省略了。
图中的每个节点称为页,页就是我们上面说的磁盘块,在 MySQL 中数据读取的基本单位都是页,所以我们这里叫做页更符合 MySQL 中索引的底层数据结构。
从上图可以看出,B 树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的 B 树为 3 阶 B 树,高度也会很低。
基于这个特性,B 树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
假如我们要查找 id=28 的用户信息,那么我们在上图 B 树中查找的流程如下:
- 先找到根节点也就是页 1,判断 28 在键值 17 和 35 之间,那么我们根据页 1 中的指针 p2 找到页 3。
- 将 28 和页 3 中的键值相比较,28 在 26 和 30 之间,我们根据页 3 中的指针 p2 找到页 8。
- 将 28 和页 8 中的键值相比较,发现有匹配的键值 28,键值 28 对应的用户信息为(28,bv)。
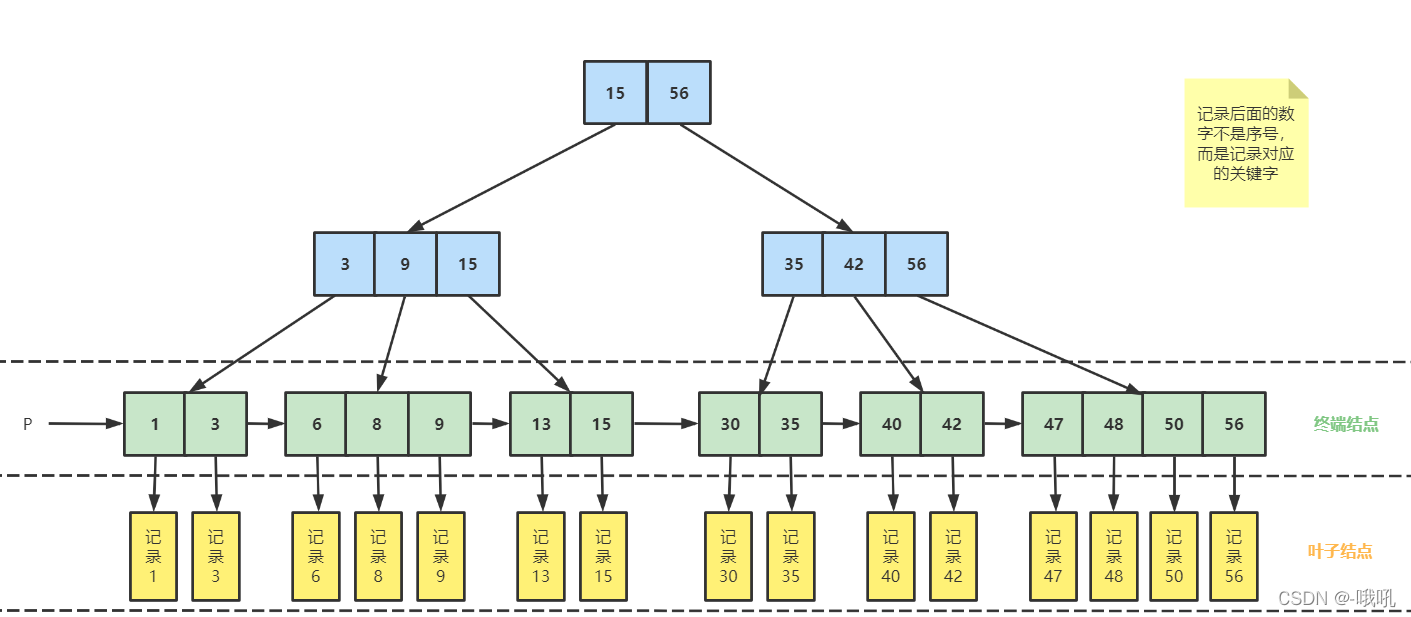
B+树
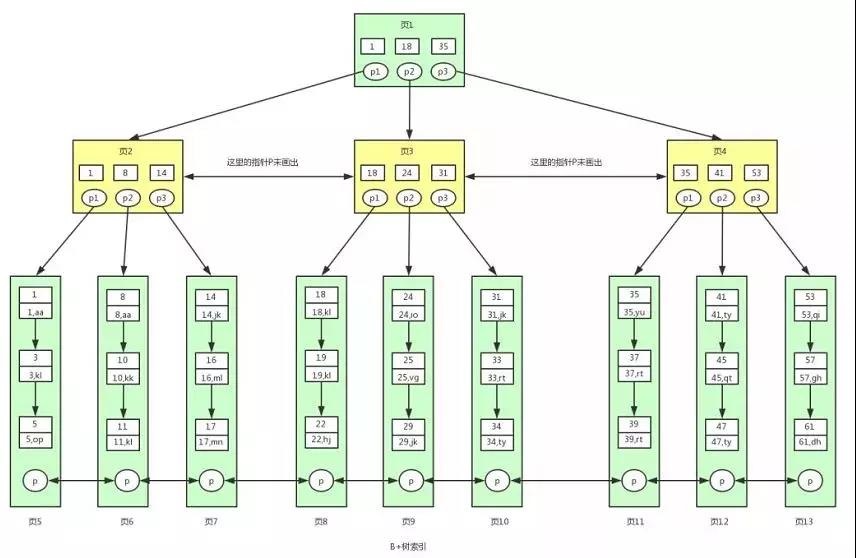
根据上图我们来看下 B+ 树和 B 树有什么不同:
①B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据。
之所以这么做是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是 16KB。
如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快。
另外,B+ 树的阶数是等于键值的数量的,如果我们的 B+ 树一个节点可以存储 1000 个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。
一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
②因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。
有心的读者可能还发现上图 B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
其实上面的 B 树我们也可以对各个节点加上链表。这些不是它们之前的区别,是因为在 MySQL 的 InnoDB 存储引擎中,索引就是这样存储的。
也就是说上图中的 B+ 树索引就是 InnoDB 中 B+ 树索引真正的实现方式,准确的说应该是聚集索引(聚集索引和非聚集索引下面会讲到)。
通过上图可以看到,在 InnoDB 中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
MyISAM 中的 B+ 树索引实现与 InnoDB 中的略有不同。在 MyISAM 中,B+ 树索引的叶子节点并不存储数据,而是存储数据的文件地址。
C++实现的B+树
C++实现B+树的例子:
#include<iostream>
#include<cstring>
#include<vector>
using namespace std;
const int M = 4; // B+树的阶数
const int MM = 2 * M;
const int L = 5; // 叶节点能容纳的最大键值对数
struct Node {
bool leaf; // 是否为叶节点
Node* parent; // 父节点
Node* children[MM + 1]; // 子节点
int values[MM]; // 记录值
int cnt; // 子节点数或者键值对数
};
class BPlusTree {
public:
BPlusTree();
~BPlusTree();
void insert(int value); // 插入记录
void show(); // 显示整棵B+树
private:
void split(Node* x, int idx); // 对满节点分裂
void insertNonfull(Node* x, int value); // 插入到非满节点
void show(Node* x, int num); // 递归显示某个节点及其子树
Node* root; // 根节点
};
BPlusTree::BPlusTree() {
root = NULL;
}
BPlusTree::~BPlusTree() {
// TODO
}
void BPlusTree::split(Node* x, int idx) {
Node* y = new Node();
Node* z = x->children[idx];
y->leaf = z->leaf;
y->cnt = L;
z->cnt = L;
// 将z节点的后L个值移动到y节点
memcpy(y->values, z->values + L, sizeof(int) * L);
if(!y->leaf) {
memcpy(y->children, z->children + L, sizeof(Node*) * (L + 1));
for(int i = L; i < MM; i++) {
z->children[i] = NULL;
}
}
z->cnt = L;
// 为父节点x插入键值,并将y节点加入到x的子节点中
for(int i = x->cnt + 1; i > idx + 1; i--) {
x->children[i] = x->children[i - 1];
}
x->children[idx + 1] = y;
for(int i = x->cnt; i > idx; i--) {
x->values[i] = x->values[i - 1];
}
x->values[idx] = z->values[L];
x->cnt++;
}
void BPlusTree::insertNonfull(Node* x, int value) {
int i = x->cnt - 1;
if(x->leaf) {
while(i >= 0 && value < x->values[i]) {
x->values[i + 1] = x->values[i];
i--;
}
x->values[i + 1] = value;
x->cnt++;
}
else {
while(i >= 0 && value < x->values[i]) {
i--;
}
i++;
if(x->children[i]->cnt == MM) {
split(x, i);
if(value > x->values[i]) {
i++;
}
}
insertNonfull(x->children[i], value);
}
}
void BPlusTree::insert(int value) {
if(root == NULL) {
root = new Node();
root->leaf = true;
root->cnt = 1;
root->values[0] = value;
}
else {
if(root->cnt == MM) {
Node* s = new Node();
s->leaf = false;
s->children[0] = root;
split(s, 0);
root = s;
if(value > root->values[0]) {
insertNonfull(root->children[1], value);
}
else {
insertNonfull(root->children[0], value);
}
}
else {
insertNonfull(root, value);
}
}
}
void BPlusTree::show() {
if(root != NULL) {
show(root, 0);
}
}
void BPlusTree::show(Node* x, int num) {
cout << "(" << num << ")";
for(int i = 0; i < x->cnt; i++) {
cout << x->values[i] << " ";
}
cout << endl;
if(!x->leaf) {
for(int i = 0; i <= x->cnt; i++) {
if(x->children[i] != NULL) {
show(x->children[i], num + 1);
}
}
}
}
int main() {
BPlusTree tree;
for(int i = 0; i < 20; i++) {
tree.insert(i);
}
tree.show();
return 0;
}SQLite中B+树相关源码
1.B+树节点的结构定义:
typedef struct MemPage MemPage;
typedef struct BtShared BtShared;
typedef struct BtCursor BtCursor;
/* Page type flags */
#define PTF_LEAF 0x01
#define PTF_INTKEY 0x02
#define PTF_DATA 0x04
#define PTF_MKDUP 0x08
#define PTF_SQLITE_MASTER 0x10
#define PTF_ZERODATA 0x20 /* Leaf data is zeroed */
/* Masks used for by various routines to inspect fields of the MemPage
** structure. These #defines are not an internationally recognized
** standard, but are used here to make the code easier to read. */
#define PGNO(x) ((x)->pgno)
#define HASPTRMAP(x) ((x)->nFree>0)
#define ISLEAF(x) ((x)->flags & PTF_LEAF)
#define ISINTKEY(x) ((x)->flags & PTF_INTKEY)
#define ISDATA(x) ((x)->flags & PTF_DATA)
#define ISNOERROR(x) ((x)->errCode==0)
#define CellSize(p, i) ((p)->cellOffset[(i)+1]-(p)->cellOffset[i])
/* Handle to a database */
struct sqlite3 {
sqlite3_mutex *mutex; /* Connection mutex */
sqlite3_vfs *pVfs; /* OS Interface */
struct Vdbe *pVdbe; /* List of active virtual machines */
CollSeq *pDfltColl; /* Default collating sequence (BINARY) */
int nCollNeeded; /* Collating sequences needed to reparse SQL */
CollSeq **apCollNeeded; /* Collating sequence needed to compile SQL */
int nVdbeActive; /* Number of VDBEs currently executing */
int nVdbeRead; /* Number of active VDBEs that read or write */
int nVdbeWrite; /* Number of active VDBEs that write */
int nErr; /* Number of errors encountered */
int errCode; /* Most recent error code (SQLITE_*) */
sqlite3_vfs *pVfs2; /* Secondary VFS */
int activeVdbeCnt; /* Number of VDBEs currently executing - VDBEs with sqlite3_stmt.nResColumn>0 or holding a lock */
u32 writeVdbeCnt; /* Counter incremented each time a VDBE writes */
int (*xTrace)(u32,void*,void*,void*); /* Trace function */
void *pTraceArg; /* Argument to the trace function */
void (*xProfile)(void*,const char*,u64); /* Profiling function */
void *pProfileArg; /* Argument to profile function */
void *pCommitArg; /* Argument to xCommitCallback() */
int (*xCommitCallback)(void*); /* Invoked at every commit. */
void *pRollbackArg; /* Argument to xRollbackCallback() */
void (*xRollbackCallback)(void*); /* Invoked at every commit. */
void *pUpdateArg; /* Argument to xUpdateCallback() */
void (*xUpdateCallback)(void*,int, const char*,const char*,sqlite_int64);
int nTransaction; /* Transaction count. 0 means no transaction */
int nStmtDefrag; /* Number of previously allocated VDBE statements */
struct Stmt *pStmtDefrag; /* Compacting statement */
FuncDefHash aFuncDef; /* Hash table of connection functions */
Hash aCollSeq; /* All collating sequences */
BusyHandler busyHandler; /* Busy callback */
Db aDbStatic[2]; /* Static space for the 2 default backends */
Savepoint *pSavepoint; /* List of active savepoints */
int busyTimeout; /* Busy handler timeout, in msec */
int nSavepoint; /* Number of non-transaction savepoints */
int *pnBytesFreed; /* If not NULL, increment this in DbFree() */
void **apSqlFuncArg; /* Accumulated function args */
int nSqlFuncArg; /* Number of entries in apSqlFuncArg */
VTable **pVTab; /* Virtual tables with open transactions */
int nVTab; /* Number of virtual tables with open transactions */
KeyInfo *aKeyStat; /* Statistics on index heights */
char *zProfile; /* Output of profiling */
u32 u1; /* Unsigned integer value */
u32 u2; /* Unsigned integer value */
int lastRowid; /* ROWID of most recent insert (see above) */
int nChange; /* Value returned by sqlite3_changes() */
int nTotalChange; /* Value returned by sqlite3_total_changes() */
int aLimit[SQLITE_N_LIMIT]; /* Limits */
int nMaxSorterMmap; /* Maximum size of regions mapped by sorter */
int iPrngState; /* PRNG running state */
sqlite3_int64 counters[3];
unsigned char *aCollNeeded[2]; /* Collating sequences required by current SQL */
Lookaside lookaside; /* Lookaside malloc configuration */
int szMmap; /* mmap() limit */
int bBenignMalloc; /* Do not enforce malloc limits if true */
};
struct MemPage {
u32 isInit:1; /* True if previously initialized. MUST BE FIRST! */
u32 nFree:15; /* Number of free bytes on the page */
u32 intKey:1; /* True if the page contains integer keys */
u32 intKeyLeaf:1; /* True if the leaf of intKey table */
u32 noPayload:1; /* True if this page has no payload */
u32 leaf:1; /* True if this is a leaf page*/
u32 hasData:1; /* True if this page carries data */
u32 hdrOffset:11; /* Offset to the start of the page header */
u16 maxLocal; /* Copy of Btree.pageSize. Max local payload size */
u16 minLocal; /* Copy of Btree.usableSize. Min local payload size */
u16 cellOffset[1]; /* Array of cell offsets. Negative offsets indicate
** unused slots. Positive offsets are offsets from the
** beginning of the page to the cell content. */
/* u8 aData[minLocal];*/ /* Beginning of payload area */
};2. B+树的关键函数实现
/*
** Get a page from the pager. Initialize the MemPage.pBt and
** MemPage.aData elements if needed.
**
** If the noContent flag is set, it means that we do not care about
** the content of the page at this time. So do not go to any extra
** effort to read or write the content. Just fill in the content
** size fields and return.
*/
static int getAndInitPage(
BtShared *pBt, /* The BTree that this page is part of */
Pgno pgno, /* Number of the page to get */
MemPage **ppPage, /* Write the page pointer here */
int noContent /* Do not load page content if true */
){
MemPage *pPage = 0; /* Page to return */
int rc; /* Return Code */
u8 eLock; /* Lock to obtain on page */
u8 intKey; /* True if the btree is an int-key btree */
int pgsz; /* Size of a database page */
Pager *pPager; /* The pager from which to get the page */
DbPage *pDbPage = 0; /* Pager page handle */
unsigned char *aData; /* Data for the page */
int usableSize; /* Number of usable bytes on each page */
u8 hdr[sizeof(MemPage)];/* Page One header content */
assert( sqlite3_mutex_held(pBt->mutex) );
pPager = pBt->pPager;
usableSize = pBt->usableSize;
pgsz = sqlite3PagerPageSize(pPager);
if( pgno==1 ){
rc = sqlite3PagerRead(pPager, 1, (void*)hdr);
if( rc!=SQLITE_OK ) return rc;
if( memcmp(hdr, zMagicHeader, sizeof(zMagicHeader))!=0 ){
if( memcmp(hdr, zLegacyHeader, sizeof(zLegacyHeader))==0 ){
return SQLITE_READONLY_RECOVERY;
}
return SQLITE_NOTADB;
}
pBt->pageSize = (hdr[16]<<8) | (hdr[17]<<16);;
pBt->usableSize = usableSize = (hdr[20]<<8) | (hdr[21]<<16);;
pBt->maxEmbedFrac = hdr[22];
pBt->minEmbedFrac = hdr[23];
pBt->minLeafFrac = hdr[24];
pBt->pageSizeFixed = ((hdr[27]&0x02)!=0);
if( !pBt->pageSizeFixed){
assert( PENDING_BYTE_PAGE(pBt)==BTREE_PAGENO(pBt,1) );
assert( sqlite3PagerRefcount(pPager, PENDING_BYTE_PAGE(pBt))==1 );
rc = sqlite3PagerWrite(pPager, PENDING_BYTE_PAGE(pBt));
if( rc ) return rc;
memset(aData = sqlite3PagerGetData(pPage->pDbPage), 0, pgsz);
aData[PENDING_BYTE_OFFSET(pBt)] = TRANS_WRITE;
pBt->needSave = 1;
if( pBt->inTransaction==TRANS_NONE ){
assert( !pBt->readOnly );
rc = sqlite3PagerBegin(pPager, 2, 0);
if( rc!=SQLITE_OK ){
return rc;
}
pBt->inTransaction = TRANS_WRITE;
}
}
if( pBt->pageSize<512 || sqlite3BitvecSize((pBt->pageSize-1)/8+1)<=0 ){
return SQLITE_CORRUPT_BKPT;
}
if( !pBt->btsFlags ){
assert( sqlite3PagerRefcount(pPager, PENDING_BYTE_PAGE(pBt))==1 );
rc = sqlite3PagerWrite(pPager, PENDING_BYTE_PAGE(pBt));
if( rc ) return rc;
aData = sqlite3PagerGetData(pDbPage);
aData[PENDING_BYTE_OFFSET(pBt)] = TRANS_WRITE;
pBt->inTransaction = TRANS_WRITE;
rc = sqlite3PagerCommitPhaseOne(pPager, zMasterJournal, 0);
if( rc ) return rc;
pBt->btsFlags |= BTS_INITIALLY_EMPTY;
}
}
if( pgno>btreePagecount(pBt) ){
if( noContent ){
*ppPage = 0;
return SQLITE_OK;
}
rc = sqlite3PagerWrite(pPager, pgno);
if( rc ) return rc;
if( pBt->btsFlags & BTS_READ_ONLY ){
return SQLITE_READONLY;
}
pDbPage = 0;
rc = allocateBtreePage(pBt, &pDbPage, &pgno, 0, 1);
if( rc!=SQLITE_OK ){
return rc;
}
/* If the database supports shared cache AND the page is not the
** first page of a new database file, mark the page as an
** int-cells page. There are two exceptions:
**
** * If we are creating a new file and the user has configured the
** system to use 8+ byte cell overflows (see below), the call to
** allocateBtreePage() will have already marked the page as an
** int-cells page.
**
** * If the page being requested is a leaf-data page, the
** allocateBtreePage() call always marked the page as a
** leaf-data page. This takes priority over the setting below.
**
** The calling function is responsible for setting pPage->intKey
** and pPage->intKeyLeaf appropriately.
*/
if( ISAUTOVACUUM ){
if( pgno>2 || (pgno==2 && (pBt->btsFlags & BTS_FIRST_KV_PAGE)==0) ){
pDbPage->aData[0] = (u8)0x02;
}
}
}else{
rc = sqlite3PagerAcquire(pPager, pgno, &pDbPage, noContent);
if( rc ) return rc;
}
aData = sqlite3PagerGetData(pDbPage);
eLock = (noContent ? EXCLUSIVE_LOCK : pBt->inTransaction>TRANS_NONE);
rc = sqlite3PagerSharedLock(pPager);
if( rc!=SQLITE_OK ){
sqlite3PagerUnref(pDbPage);
return rc;
}
rc = btreeInitPage(pDbPage, eLock, pBt->pageSize);
if( rc!=SQLITE_OK ){
sqlite3PagerUnref(pDbPage);
return rc;
}
if( pgno==1 ){
memcpy(aData, hdr, pgsz);
if( !pBt->pageSizeFixed ){
aData[16] = (u8)(pBt->pageSize>>8);
aData[17] = (u8)(pBt->pageSize>>16);
aData[20] = (u8)(pBt->usableSize>>8);
aData[21] = (u8)(pBt->usableSize>>16);
}
}
pPage = new MemPage;
if( !pPage ){
rc = SQLITE_NOMEM;
sqlite3PagerUnref(pDbPage);
return rc;
}
pPage->aData = aData;
pPage->pBt = pBt;
pPage->pDbPage = pDbPage;
pPage->pgno = pgno;
pPage->usableSize = usableSize;
if( pBt->btsFlags & BTS_READ_ONLY ){
pPage->flags |= PAGER_GET_READONLY;
}
if( pgno==1 ){
pPage->isInit = 1;
pPage->nFree = usableSize
- ((36+sqlite3GetNameSize(&pBt->zFilename[1])+7)&~7)
- 100;
}
*ppPage = pPage;
return SQLITE_OK;
}
/*
** Read a 32-bit integer from a page and return its value.
** The value is stored in big-endian format.
*/
u32 get4byte(const void *pBuf){
const u8 *p = (const u8*)pBuf;
return ((u32)p[0]<<24) | (p[1]<<16) | (p[2]<<8) | p[3];
}
/* The various locking operations are numbered so that we can test
** for locks in a bitvector
*/
#define READ_LOCK 0x01 /* Shared lock */
#define WRITE_LOCK 0x02 /* Exclusive lock */
/* Return TRUE if the BtShared mutex is held by this thread at the point
** this routine is called. This is used only assert() statements and
** testcase() macros.
*/
static int heldMutexSanityCheck(BtShared *pBt){
#ifndef SQLITE_DEBUG
UNUSED_PARAMETER(pBt);
return 1;
#else其他资源
Data Structure Visualization
理解B+树_什么是b+树_波波仔86的博客-CSDN博客
B树和B+树详解_小肖同学哦的博客-CSDN博客
B+树真的不难,楼下菜大爷都能学得会的B+树!(数据结构可视化神器推荐)_bplustree visualization_菜菜bu菜的博客-CSDN博客
b+树详解_源头源脑的博客-CSDN博客
二叉树编程题集合(leetcode)_我要学习java和python的博客-CSDN博客
B树和B+树详解_小肖同学哦的博客-CSDN博客
https://huaweicloud.csdn.net/637ef533df016f70ae4ca698.html