一、前言
阅读本节需要先掌握Catalog基础知识
Spark对Hive的所有操作都是通过获取Hive元数据[metastore]帮助spark构建表信息从而调用HDFS-API对原始数据的操作,可以说Spark兼容多版本Hive就是在兼容Hive的Metastore
二、源码分析
在catalog一节中我们知道spark对hive操作是通过HiveExternalCatalog,而HiveExternalCatalog对hive的DDL、DML操作都是使用内部的HiveClient变量,如下:
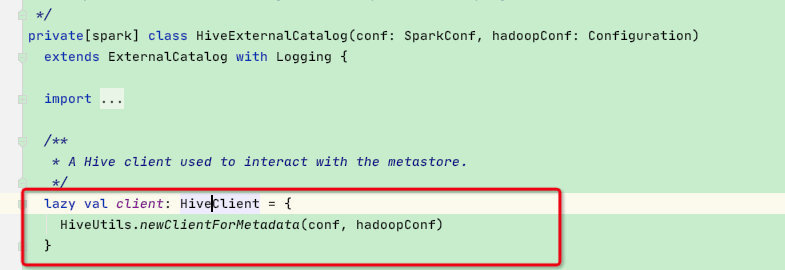

接下来我们看HiveUtils.newClientForMetadata函数:
protected[hive] def newClientForMetadata(
conf: SparkConf,
hadoopConf: Configuration): HiveClient = {
//将时间格式更改为统一的[[Long]]格式,不重要
val configurations = formatTimeVarsForHiveClient(hadoopConf)
//该函数将返回HiveClient
newClientForMetadata(conf, hadoopConf, configurations)
}
在newClientForMetadata函数中spark为我们提供了三种方式来构建HiveClient:
1、使用spark内置的hiveMetaStore相关包构建HiveClient
2、使用用户指定的hiveMetaStore相关包和version版本构建HiveClient
3、使用用户指定的hive版本去Maven仓库上下载hiveMetaStore相关包从而构建HiveClient
这里简化了部分源码,简化的部分后面会一一展开
protected[hive] def newClientForMetadata(
conf: SparkConf,
hadoopConf: Configuration,
configurations: Map[String, String]): HiveClient = {
val sqlConf = new SQLConf
sqlConf.setConf(SQLContext.getSQLProperties(conf))
// 获取hiveMetastore的版本,用户可以通过配置指定
val hiveMetastoreVersion = HiveUtils.hiveMetastoreVersion(sqlConf)
// 获取hiveMetastore的jar包路径,用户可以通过配置指定
val hiveMetastoreJars = HiveUtils.hiveMetastoreJars(sqlConf)
val hiveMetastoreSharedPrefixes = HiveUtils.hiveMetastoreSharedPrefixes(sqlConf)
val hiveMetastoreBarrierPrefixes = HiveUtils.hiveMetastoreBarrierPrefixes(sqlConf)
val metaVersion = IsolatedClientLoader.hiveVersion(hiveMetastoreVersion)
val isolatedLoader = if (hiveMetastoreJars == "builtin") {
// builtin代表使用spark内置的hiveMetaStore包
// spark2.x内置使用hive-1.2.1版本,spark3.x内置使用的是hive-2.3.7
......
} else if (hiveMetastoreJars == "maven") {
// maven代表使用用户指定的hive版本去Maven仓库上下载hiveMetaStore相关包
......
} else {
// 其他代表使用用户指定的hiveMetaStore相关包和version版本
......
}
// 构建HiveClient
isolatedLoader.createClient()
}
先来看看hiveMetastoreVersion版本如何指定:
// 调用HiveUtils.hiveMetastoreVersion函数
val hiveMetastoreVersion = HiveUtils.hiveMetastoreVersion(sqlConf)
/**
* The version of the hive client that will be used to communicate with the metastore. Note that
* this does not necessarily need to be the same version of Hive that is used internally by
* Spark SQL for execution.
*/
private def hiveMetastoreVersion(conf: SQLConf): String = {
conf.getConf(HIVE_METASTORE_VERSION)
}
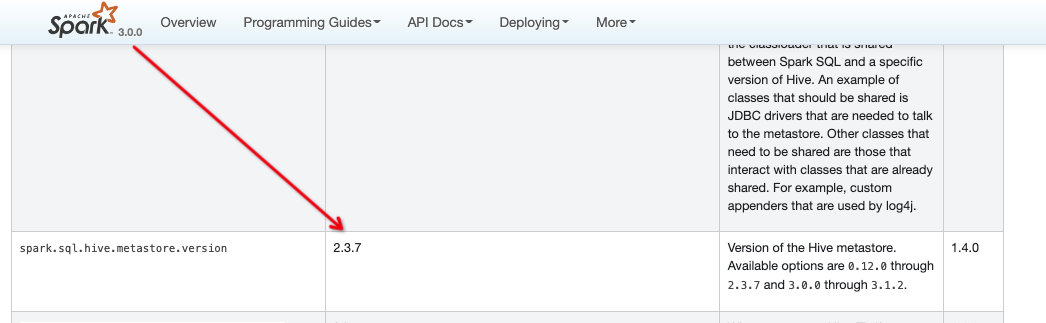
// 这可以看到是通过--conf spark.sql.hive.metastore.version=xxx 指定版本,如果不指定则默认使用builtinHiveVersion变量,spark3.0中默认即2.3.7
val HIVE_METASTORE_VERSION = buildStaticConf("spark.sql.hive.metastore.version")
.doc("Version of the Hive metastore. Available options are " +
"<code>0.12.0</code> through <code>2.3.7</code> and " +
"<code>3.0.0</code> through <code>3.1.2</code>.")
.version("1.4.0")
.stringConf
.createWithDefault(builtinHiveVersion)
/** The version of hive used internally by Spark SQL. */
val builtinHiveVersion: String = if (isHive23) hiveVersion else "1.2.1"
再看hiveMetaStore相关jar包地址如何指定:
// 调用HiveUtils.hiveMetastoreJars函数
val hiveMetastoreJars = HiveUtils.hiveMetastoreJars(sqlConf)
/**
* The location of the jars that should be used to instantiate the HiveMetastoreClient. This
* property can be one of three options:
* - a classpath in the standard format for both hive and hadoop.
* - builtin - attempt to discover the jars that were used to load Spark SQL and use those. This
* option is only valid when using the execution version of Hive.
* - maven - download the correct version of hive on demand from maven.
*/
private def hiveMetastoreJars(conf: SQLConf): String = {
conf.getConf(HIVE_METASTORE_JARS)
}
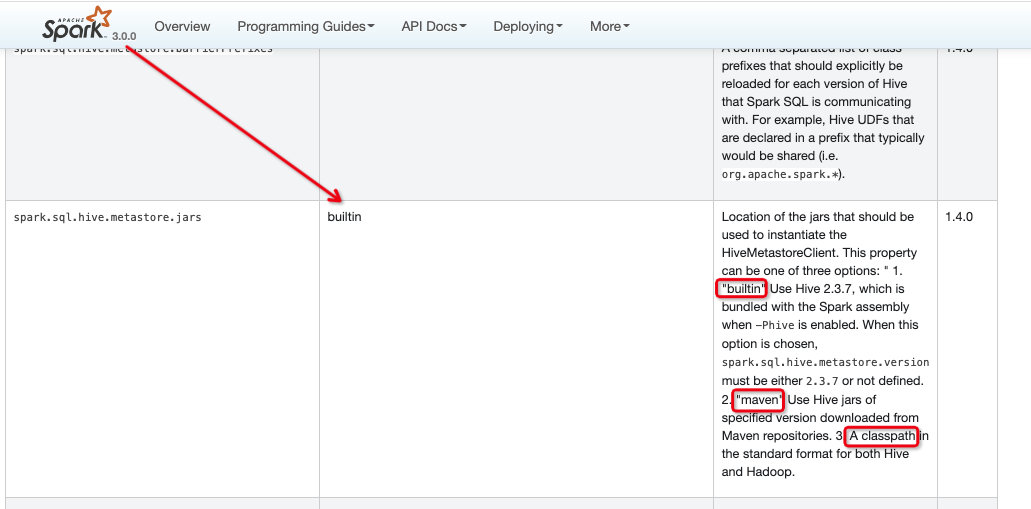
// 这可以看到是通过--conf spark.sql.hive.metastore.jars=xxx 指定jar包的classpath,如果不指定则默认返回builtin
// 这里支持三种值:1、classpath; 2、默认builtin; 3、maven; 后面会详细展开
val HIVE_METASTORE_JARS = buildStaticConf("spark.sql.hive.metastore.jars")
.doc(s"""
| Location of the jars that should be used to instantiate the HiveMetastoreClient.
| This property can be one of three options: "
| 1. "builtin"
| Use Hive ${builtinHiveVersion}, which is bundled with the Spark assembly when
| <code>-Phive</code> is enabled. When this option is chosen,
| <code>spark.sql.hive.metastore.version</code> must be either
| <code>${builtinHiveVersion}</code> or not defined.
| 2. "maven"
| Use Hive jars of specified version downloaded from Maven repositories.
| 3. A classpath in the standard format for both Hive and Hadoop.
""".stripMargin)
.version("1.4.0")
.stringConf
.createWithDefault("builtin")
接下来展开前面省略代码部分是如何构建HiveClient:
protected[hive] def newClientForMetadata(
conf: SparkConf,
hadoopConf: Configuration,
configurations: Map[String, String]): HiveClient = {
val sqlConf = new SQLConf
sqlConf.setConf(SQLContext.getSQLProperties(conf))
// 获取hiveMetastore的版本,用户可以指定
val hiveMetastoreVersion = HiveUtils.hiveMetastoreVersion(sqlConf)
// 获取hiveMetastore的jar包路径,用户可以指定
val hiveMetastoreJars = HiveUtils.hiveMetastoreJars(sqlConf)
val hiveMetastoreSharedPrefixes = HiveUtils.hiveMetastoreSharedPrefixes(sqlConf)
val hiveMetastoreBarrierPrefixes = HiveUtils.hiveMetastoreBarrierPrefixes(sqlConf)
val metaVersion = IsolatedClientLoader.hiveVersion(hiveMetastoreVersion)
// 1.builtin模式使用内置hive
val isolatedLoader = if (hiveMetastoreJars == "builtin") {
// 内置hive版本与用户指定的hiveMetastoreVersion版本不一致则报错
if (builtinHiveVersion != hiveMetastoreVersion) {
throw new IllegalArgumentException(
"Builtin jars can only be used when hive execution version == hive metastore version. " +
s"Execution: $builtinHiveVersion != Metastore: $hiveMetastoreVersion. " +
s"Specify a valid path to the correct hive jars using ${HIVE_METASTORE_JARS.key} " +
s"or change ${HIVE_METASTORE_VERSION.key} to $builtinHiveVersion.")
}
// 函数:从传入的classLoader开始,递归查找类加载器链中的所有jars并返回
def allJars(classLoader: ClassLoader): Array[URL] = classLoader match {
case null => Array.empty[URL]
case childFirst: ChildFirstURLClassLoader =>
childFirst.getURLs() ++ allJars(Utils.getSparkClassLoader)
case urlClassLoader: URLClassLoader =>
urlClassLoader.getURLs ++ allJars(urlClassLoader.getParent)
case other => allJars(other.getParent)
}
// getContextClassLoader函数是通过Thread.currentThread().getContextClassLoader获取当前线程的classLoader
val classLoader = Utils.getContextOrSparkClassLoader
val jars: Array[URL] = if (SystemUtils.isJavaVersionAtLeast(JavaVersion.JAVA_9)) {
// 这里是兼容java9版本,不做重点
......
} else {
// 通过将当前classLoader传递给allJars函数,递归获取所有jar的url
val loadedJars = allJars(classLoader)
// 校验,不重要
if (loadedJars.length == 0) {
throw new IllegalArgumentException(
"Unable to locate hive jars to connect to metastore. " +
s"Please set ${HIVE_METASTORE_JARS.key}.")
}
loadedJars
}
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion using Spark classes.")
// 这里构建了一个IsolatedClientLoader,并将上面得到的loadedJars和version传递进去,后面会展开此类讲解
new IsolatedClientLoader(
version = metaVersion,
sparkConf = conf,
hadoopConf = hadoopConf,
execJars = jars.toSeq,
config = configurations,
isolationOn = !isCliSessionState(),
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
} else if (hiveMetastoreJars == "maven") {
// 2.maven模式代表用户指定hive版本,将调用forVersion函数,下面会展开此函数讲解
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion using maven.")
IsolatedClientLoader.forVersion(
hiveMetastoreVersion = hiveMetastoreVersion,
hadoopVersion = VersionInfo.getVersion,
sparkConf = conf,
hadoopConf = hadoopConf,
config = configurations,
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
} else {
// 3.这里说明是用户指定了hiveMetaStore的classpath路径,先将hiveMetaStoreJars路径分割后获取地址转化为url数组
val jars =
hiveMetastoreJars
.split(File.pathSeparator)
.flatMap {
case path if new File(path).getName == "*" =>
val files = new File(path).getParentFile.listFiles()
if (files == null) {
logWarning(s"Hive jar path '$path' does not exist.")
Nil
} else {
files.filter(_.getName.toLowerCase(Locale.ROOT).endsWith(".jar"))
}
case path =>
new File(path) :: Nil
}
.map(_.toURI.toURL)
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion " +
s"using ${jars.mkString(":")}")
// 这里构建了一个IsolatedClientLoader,并将jars和version传递进去,后面会展开此类讲解
new IsolatedClientLoader(
version = metaVersion,
sparkConf = conf,
hadoopConf = hadoopConf,
execJars = jars.toSeq,
config = configurations,
isolationOn = true,
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
}
// 通过三种不同方式构建成的isolatedLoader调用createClient创建hiveClient
isolatedLoader.createClient()
}
先来看一下maven模式下forVersion函数的逻辑:
def forVersion(
hiveMetastoreVersion: String,
hadoopVersion: String,
sparkConf: SparkConf,
hadoopConf: Configuration,
config: Map[String, String] = Map.empty,
ivyPath: Option[String] = None,
sharedPrefixes: Seq[String] = Seq.empty,
barrierPrefixes: Seq[String] = Seq.empty,
sharesHadoopClasses: Boolean = true): IsolatedClientLoader = synchronized {
// 通过用户传递的version版本转换成spark内部的hiveVersion静态类,下面有该函数实现
val resolvedVersion = hiveVersion(hiveMetastoreVersion)
var _sharesHadoopClasses = sharesHadoopClasses
// 先从resolvedVersions-Map中判断是否有用户指定版本的jar包,第一次默认没有
val files = if (resolvedVersions.contains((resolvedVersion, hadoopVersion))) {
resolvedVersions((resolvedVersion, hadoopVersion))
} else {
// 通过ADDITIONAL_REMOTE_REPOSITORIES获取maven远程仓库地址,下面有展开
val remoteRepos = sparkConf.get(SQLConf.ADDITIONAL_REMOTE_REPOSITORIES)
// 通过downloadVersion函数将用户指定的hiveMetastoreVersion版本相关包下载到本地并返回file的URL地址,downloadVersion函数下面有展开
val (downloadedFiles, actualHadoopVersion) =
try {
(downloadVersion(resolvedVersion, hadoopVersion, ivyPath, remoteRepos), hadoopVersion)
} catch {
case e: RuntimeException if e.getMessage.contains("hadoop") =>
// If the error message contains hadoop, it is probably because the hadoop
// version cannot be resolved.
val fallbackVersion = "2.7.4"
logWarning(s"Failed to resolve Hadoop artifacts for the version $hadoopVersion. We " +
s"will change the hadoop version from $hadoopVersion to $fallbackVersion and try " +
"again. Hadoop classes will not be shared between Spark and Hive metastore client. " +
"It is recommended to set jars used by Hive metastore client through " +
"spark.sql.hive.metastore.jars in the production environment.")
_sharesHadoopClasses = false
(downloadVersion(
resolvedVersion, fallbackVersion, ivyPath, remoteRepos), fallbackVersion)
}
// 将下载好的jar包地址存储至resolvedVersions-Map缓存
resolvedVersions.put((resolvedVersion, actualHadoopVersion), downloadedFiles)
resolvedVersions((resolvedVersion, actualHadoopVersion))
}
// 构建了一个IsolatedClientLoader,并将jars和version传递进去,后面会展开此类
new IsolatedClientLoader(
hiveVersion(hiveMetastoreVersion),
sparkConf,
execJars = files,
hadoopConf = hadoopConf,
config = config,
sharesHadoopClasses = _sharesHadoopClasses,
sharedPrefixes = sharedPrefixes,
barrierPrefixes = barrierPrefixes)
}
// 将字符串版本转换成内置静态类
def hiveVersion(version: String): HiveVersion = version match {
case "12" | "0.12" | "0.12.0" => hive.v12
case "13" | "0.13" | "0.13.0" | "0.13.1" => hive.v13
case "14" | "0.14" | "0.14.0" => hive.v14
case "1.0" | "1.0.0" | "1.0.1" => hive.v1_0
case "1.1" | "1.1.0" | "1.1.1" => hive.v1_1
case "1.2" | "1.2.0" | "1.2.1" | "1.2.2" => hive.v1_2
case "2.0" | "2.0.0" | "2.0.1" => hive.v2_0
case "2.1" | "2.1.0" | "2.1.1" => hive.v2_1
case "2.2" | "2.2.0" => hive.v2_2
case "2.3" | "2.3.0" | "2.3.1" | "2.3.2" | "2.3.3" | "2.3.4" | "2.3.5" | "2.3.6" | "2.3.7" =>
hive.v2_3
case "3.0" | "3.0.0" => hive.v3_0
case "3.1" | "3.1.0" | "3.1.1" | "3.1.2" => hive.v3_1
case version =>
throw new UnsupportedOperationException(s"Unsupported Hive Metastore version ($version). " +
s"Please set ${HiveUtils.HIVE_METASTORE_VERSION.key} with a valid version.")
}
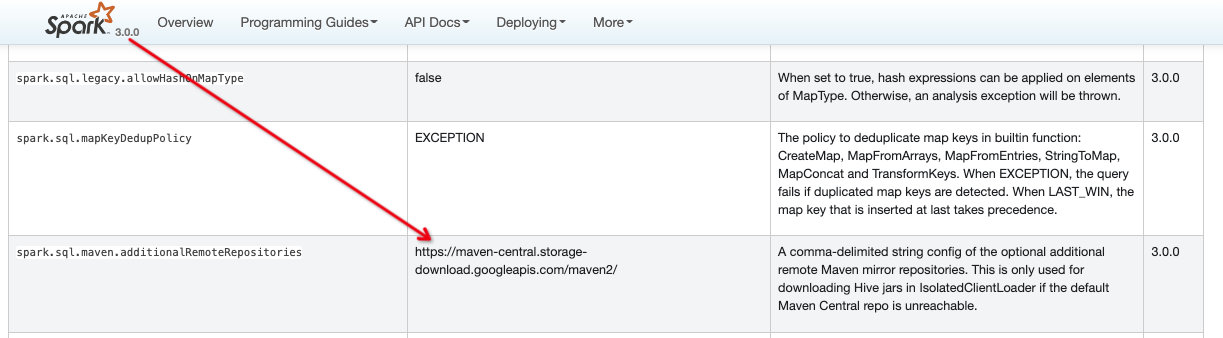
// spark下载的maven包的远程仓库地址,用户可以指定地址,比如cdh的远程仓库地址
val ADDITIONAL_REMOTE_REPOSITORIES =
buildConf("spark.sql.maven.additionalRemoteRepositories")
.doc("A comma-delimited string config of the optional additional remote Maven mirror " +
"repositories. This is only used for downloading Hive jars in IsolatedClientLoader " +
"if the default Maven Central repo is unreachable.")
.version("3.0.0")
.stringConf
.createWithDefault(
"https://maven-central.storage-download.googleapis.com/maven2/")
// 该函数将会去maven仓库下载相关版本jar包存储在tmp目录下,并返回file的URL路径
private def downloadVersion(
version: HiveVersion,
hadoopVersion: String,
ivyPath: Option[String],
remoteRepos: String): Seq[URL] = {
// 从这里可以发现spark下载hive相关包有哪些,这是因为hive-metaStore包中依赖了hive的其他包,如exec、common包等,故这里需要下载多个包
// 从这里也可以看出如果我们要自己指定hive的jars,不仅仅要指定hive-metaStore.jar,还需要将相关包地址的指定。
val hiveArtifacts = version.extraDeps ++
Seq("hive-metastore", "hive-exec", "hive-common", "hive-serde")
.map(a => s"org.apache.hive:$a:${version.fullVersion}") ++
Seq("com.google.guava:guava:14.0.1",
s"org.apache.hadoop:hadoop-client:$hadoopVersion")
val classpath = quietly {
SparkSubmitUtils.resolveMavenCoordinates( // 给定maven工件的jar的逗号分隔路径,包括它们的传递依赖项
hiveArtifacts.mkString(","),
SparkSubmitUtils.buildIvySettings(
Some(remoteRepos),
ivyPath),
exclusions = version.exclusions)
}
val allFiles = classpath.split(",").map(new File(_)).toSet
// 创建临时存放jar包的路径,默认是在/tmp路径下
val tempDir = Utils.createTempDir(namePrefix = s"hive-${version}")
allFiles.foreach(f => FileUtils.copyFileToDirectory(f, tempDir))
logInfo(s"Downloaded metastore jars to ${tempDir.getCanonicalPath}")
// 最终将下载好的jar包file转换成url数组返回
tempDir.listFiles().map(_.toURI.toURL)
}
至此可以看出spark兼容hiveMetaStore所提供的三种模式都是先构建一个IsolatedClientLoader类,IsolatedClientLoader类是用来构造HiveClient背后具体的不同的Hive版本的工厂类,每一个IsolatedClientLoader对象,都封装了某个版本的HiveClient的实现,包括:版本号,对应版本的相关jars。
在IsolatedClientLoader类中有一个classLoader变量,该变量通过创建类加载器来实现不同hive版本的隔离!因为在一个JVM中一个类加载器不能存在两个一模一样的类,如果想实现此功能则需要创建新的classLoader,所以这里spark才会将jars路径传递进去;
关于classLoader相关知识不作为本节重点,感兴趣的小伙伴可以看这篇文章:老大难的 Java ClassLoader 再不理解就老了
接下来看一下IsolatedClientLoader的classLoader属性:
/**
* The classloader that is used to load an isolated version of Hive.
* This classloader is a special URLClassLoader that exposes the addURL method.
* So, when we add jar, we can add this new jar directly through the addURL method
* instead of stacking a new URLClassLoader on top of it.
*/
private[hive] val classLoader: MutableURLClassLoader = {
val isolatedClassLoader =
// isolationOn变量意思是是否开启隔离,三种模式中只有buildin模式时该参数为false; maven和用户指定classpath时该值为true; 即需要隔离时才会自使用新的类加载器
if (isolationOn) {
if (allJars.isEmpty) {
// See HiveUtils; this is the Java 9+ + builtin mode scenario
baseClassLoader
} else {
// 获取父类加载器,默认null,不做重点
val rootClassLoader: ClassLoader = ......
// 重点:构建一个URLClassLoader加载器,并将传递来的allJars地址传入
new URLClassLoader(allJars, rootClassLoader) {
// 重写ClassLoader的loadClass函数
override def loadClass(name: String, resolve: Boolean): Class[_] = {
// 判断当前这个classLoader对象是否已经加载了这个class对象,如果已经加载了,则直接返回
val loaded = findLoadedClass(name)
// 没加载调用doLoadClass函数
if (loaded == null) doLoadClass(name, resolve) else loaded
}
// 构建函数,核心是转化成bytes数组,不做重点
def doLoadClass(name: String, resolve: Boolean): Class[_] = {
......
}
}
}
} else {
baseClassLoader
}
// 最终将isolatedClassLoader作为父加载器从而构建出NonClosableMutableURLClassLoader加载器返回
new NonClosableMutableURLClassLoader(isolatedClassLoader)
}
// NonClosableMutableURLClassLoader加载器继承MutableURLClassLoader
public class NonClosableMutableURLClassLoader extends MutableURLClassLoader {
static {
ClassLoader.registerAsParallelCapable();
}
public NonClosableMutableURLClassLoader(ClassLoader parent) {
super(new URL[]{}, parent);
}
@Override
public void close() {}
}
// MutableURLClassLoader加载器继承子java的URLClassLoader
public class MutableURLClassLoader extends URLClassLoader {
......
}
可以看到spark通过提供自定义的独立的ClassLoader, 用来支持在同一个jvm 中同时使用多个不同版本的HiveMetastore,这是由于Spark本身默认绑定的built-in的hive 版本是1.2.1,因此,如果我们需要使用其他高版本的HiveClient,就有可能存在同一个Spark JVM里面并存多个不同版本的hive client,这需要使用不同的ClassLoader对象来实现, 每一个IsolatedClientLoader负责一个hive version.
接下来看一下IsolatedClientLoader的createClient函数:
private[hive] def createClient(): HiveClient = synchronized {
val warehouseDir = Option(hadoopConf.get(ConfVars.METASTOREWAREHOUSE.varname))
// 判断是否开启隔离,三种模式中只有buildin模式时该参数为false; maven和用户指定classpath时该值为true
if (!isolationOn) {
// 既然是默认模式,直接使用当前线程的上下文创建HiveClientImpl,该类后面会详细展开讲解
return new HiveClientImpl(version, warehouseDir, sparkConf, hadoopConf, config,
baseClassLoader, this)
}
// Pre-reflective instantiation setup.
logDebug("Initializing the logger to avoid disaster...")
// 保存当前线程的上下文
val origLoader = Thread.currentThread().getContextClassLoader
// 给当前线程设置应该隔离的classLoader上下文,实现隔离
Thread.currentThread.setContextClassLoader(classLoader)
try {
// 从classLoader加载器中构建HiveClientImpl类,并将classLoader变量和自身[this]作为参数传递[后面有大用],HiveClientImpl类后面会展开
classLoader
.loadClass(classOf[HiveClientImpl].getName)
.getConstructors.head
.newInstance(version, warehouseDir, sparkConf, hadoopConf, config, classLoader, this)
.asInstanceOf[HiveClient]
} catch {
case e: InvocationTargetException =>
if (e.getCause().isInstanceOf[NoClassDefFoundError]) {
val cnf = e.getCause().asInstanceOf[NoClassDefFoundError]
throw new ClassNotFoundException(
s"$cnf when creating Hive client using classpath: ${execJars.mkString(", ")}\n" +
"Please make sure that jars for your version of hive and hadoop are included in the " +
s"paths passed to ${HiveUtils.HIVE_METASTORE_JARS.key}.", e)
} else {
throw e
}
} finally {
// 最终都会恢复当前线程之前的classLoader上下文
Thread.currentThread.setContextClassLoader(origLoader)
}
}
接下来我们看一下HiveClientImpl类的实现,首先HiveClientImpl类是HiveClient的子类,HiveClient对外提供了诸多接口供spark使用
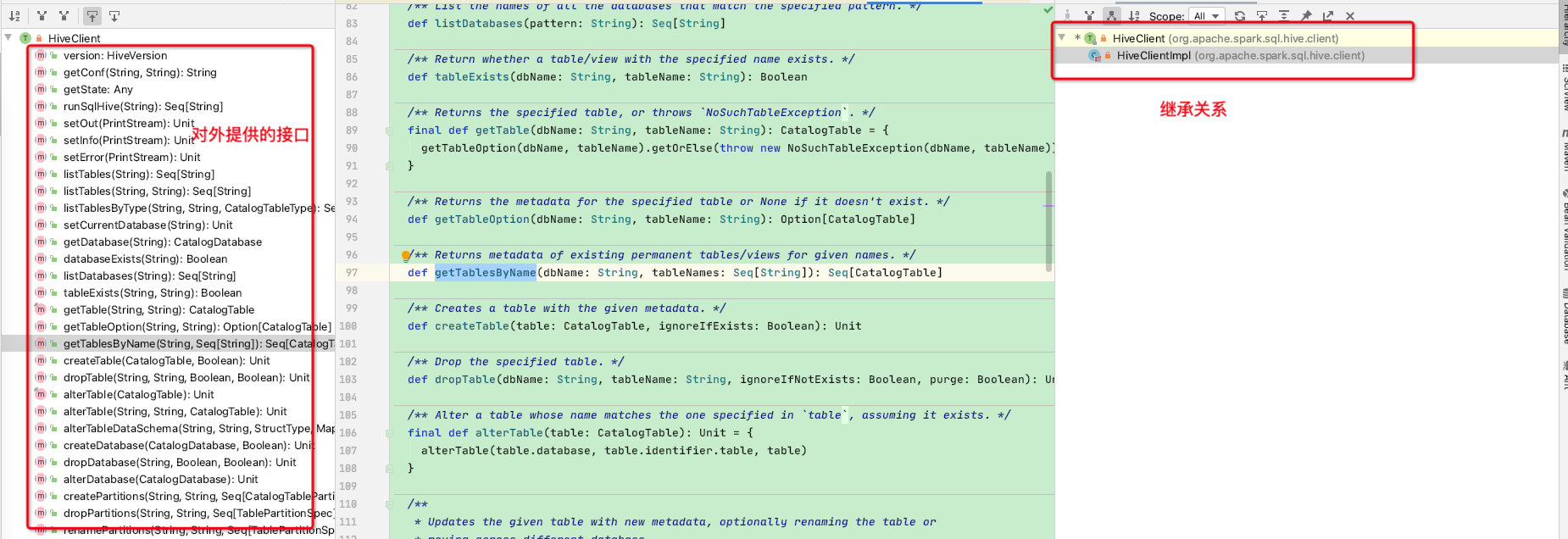
HiveClientImpl有一个非常重要的变量shim寓意垫子,也是各个hive版本API兼容的关键,shim会根据version来创建不同hive版本的shim
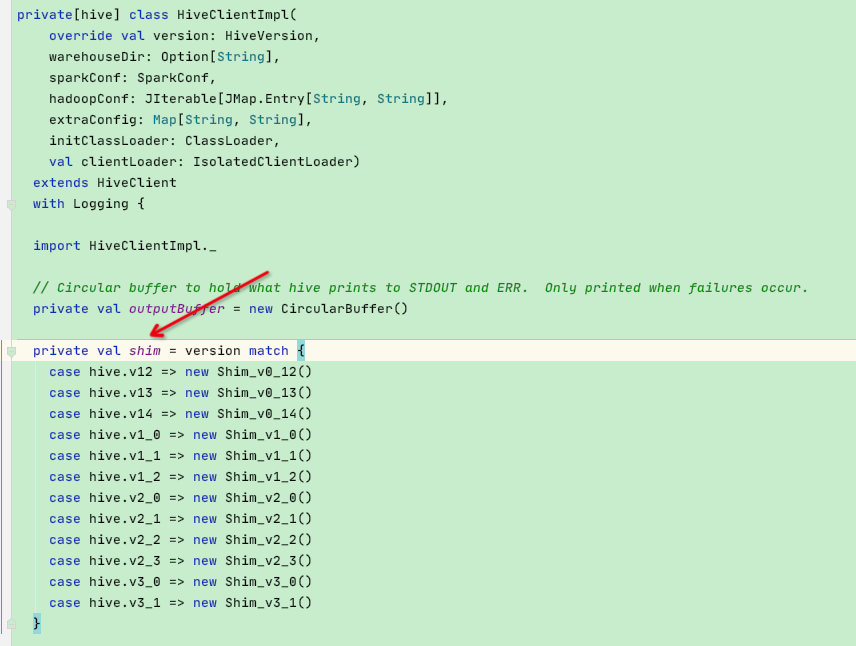
先来了解一下shim的继承关系:shim接口对外提供的接口是hive各个版本之间api冲突的接口,这里说的冲突是指api冲突,即hive不同版本中相同函数但定义不同的冲突,下面会详细讲解
shim接口是从Shim_v0_12开始实现接口,所有子类以塔型结构继承,高版本hive遇到api冲突重新实现接口即可,不冲突的api也可以直接复用低版本的api
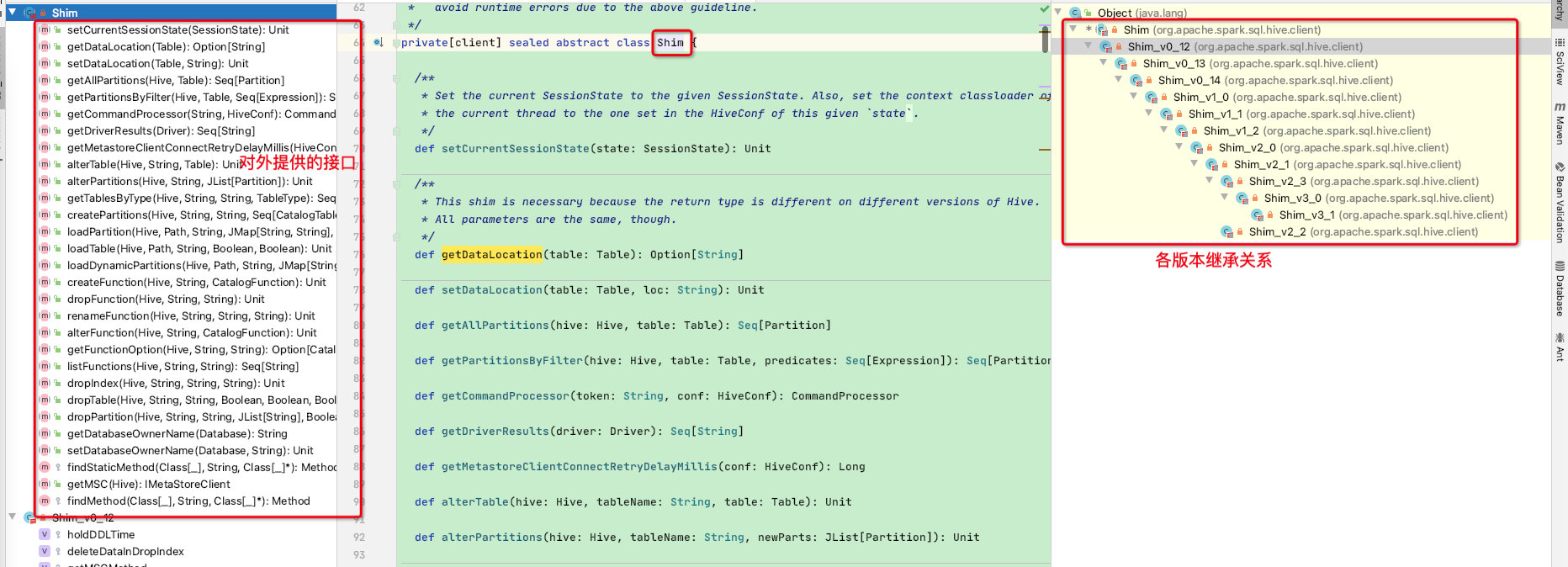
我们举一个hive-api冲突的例子,就拿loadPartition函数为例,在hive-0.12版本和hive-2.0版本该函数的参数个数不同
hive-0.12-loadPartition源码
public void loadPartition(Path loadPath, String tableName,
Map<String, String> partSpec, boolean replace, boolean holdDDLTime,
boolean inheritTableSpecs, boolean isSkewedStoreAsSubdir)
throws HiveException {
......
}
hive-2.0-loadPartition源码
public void loadPartition(Path loadPath, String tableName,
Map<String, String> partSpec, boolean replace, boolean inheritTableSpecs,
boolean isSkewedStoreAsSubdir, boolean isSrcLocal,
boolean isAcid) throws HiveException { // 2.0版本多了一个boolean类型的参数
Table tbl = getTable(tableName);
loadPartition(loadPath, tbl, partSpec, replace, inheritTableSpecs,
isSkewedStoreAsSubdir, isSrcLocal, isAcid);
}
可以看出在两个不同版本的hive中loadPartition函数定义发生变化,那么shim是如何兼容的呢?
首先在shim顶级接口中定义了loadPartition函数所需的核心参数,至于不同版本hive的loadPartition实现则是通过反射来实现!
Shim_v0_12:
// 0_12版本中率先实现了loadPartition函数,而执行的关键则是调用loadPartitionMethod,通过反射的方式调用
override def loadPartition(
hive: Hive,
loadPath: Path,
tableName: String,
partSpec: JMap[String, String],
replace: Boolean,
inheritTableSpecs: Boolean,
isSkewedStoreAsSubdir: Boolean,
isSrcLocal: Boolean): Unit = {
loadPartitionMethod.invoke(hive, loadPath, tableName, partSpec, replace: JBoolean,
JBoolean.FALSE, inheritTableSpecs: JBoolean, isSkewedStoreAsSubdir: JBoolean)
}
// 可以看到在0_12版本中是定义了loadPartition函数的Method
private lazy val loadPartitionMethod =
findMethod(
classOf[Hive],
"loadPartition",
classOf[Path],
classOf[String],
classOf[JMap[String, String]],
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE)
Shim_v2_0:
// 2_0版本中重写了loadPartition函数,因其调用的是自身的loadPartitionMethod,同样也是通过反射的方式调用
override def loadPartition(
hive: Hive,
loadPath: Path,
tableName: String,
partSpec: JMap[String, String],
replace: Boolean,
inheritTableSpecs: Boolean,
isSkewedStoreAsSubdir: Boolean,
isSrcLocal: Boolean): Unit = {
loadPartitionMethod.invoke(hive, loadPath, tableName, partSpec, replace: JBoolean,
inheritTableSpecs: JBoolean, isSkewedStoreAsSubdir: JBoolean,
isSrcLocal: JBoolean, isAcid)
}
// 2_0版本的loadPartitionMethod,可以看到定义的loadPartitionMethod中多了一个参数,以此兼容hive2.0版本的loadPartition函数
private lazy val loadPartitionMethod =
findMethod(
classOf[Hive],
"loadPartition",
classOf[Path],
classOf[String],
classOf[JMap[String, String]],
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE)
再看HiveClientImpl是怎么使用loadPartition函数:是调用了shim变量,而shim变量又会根据version创建不同版本的shim, 最终会调用不同版本shim中的loadPartition函数,进而调用loadPartitionMethod.invoke进行反射
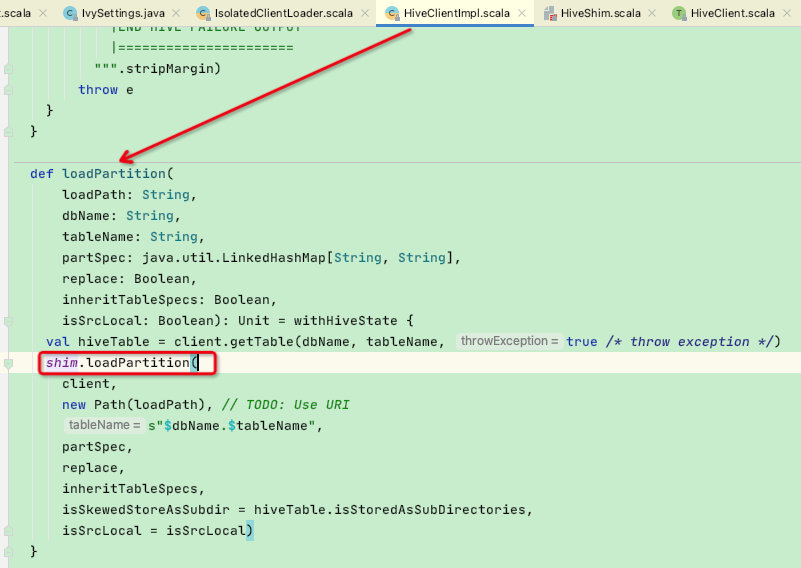
这里有一个隐藏知识点,既然是反射调用就需要在invoke时传递调用该函数的实体类,也就是上图中shim.loadPartition函数中第一个参数client,如下:
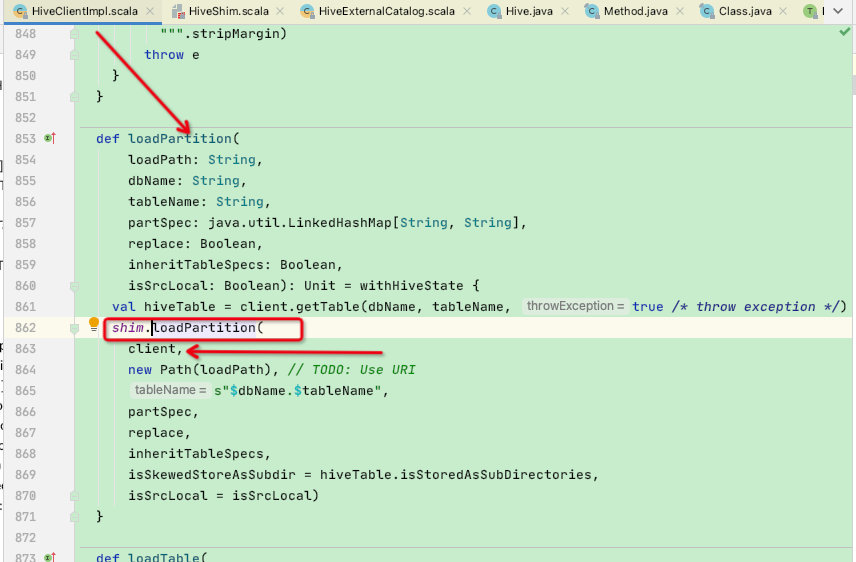
将HiveClientImpl类中的client参数传递给shim的loadPartition函数,loadPartitionMethod.invoke随后反射调用
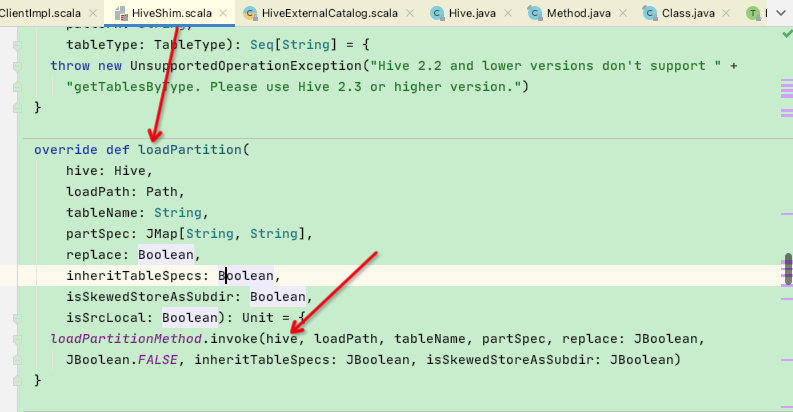
看一下HiveClientImpl类中的client是什么:
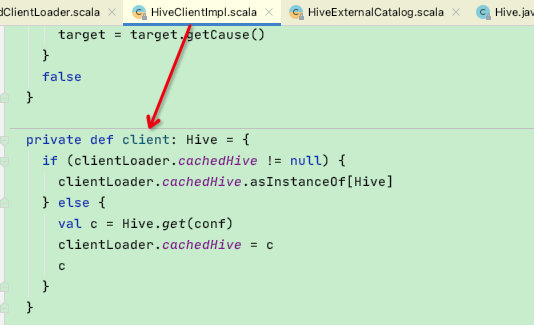
private def client: Hive = {
// 第一次默认是null
if (clientLoader.cachedHive != null) {
clientLoader.cachedHive.asInstanceOf[Hive]
} else {
// 这里通过调用的Hive类是org.apache.hadoop.hive.ql.metadata.Hive
val c = Hive.get(conf)
// 保存进clientLoader中,供后续使用
clientLoader.cachedHive = c
c
}
}
那么这里就会产生一个疑惑,当外部spark程序第一次调用client函数时的类加载是谁?我们先回到HiveExternalCatalog构建HiveClient阶段:在这个阶段中已经构建好了spark所需要的hiveClient,并且当前线程的类加载器也恢复成最初的加载器[参考createClient函数最后的finally]
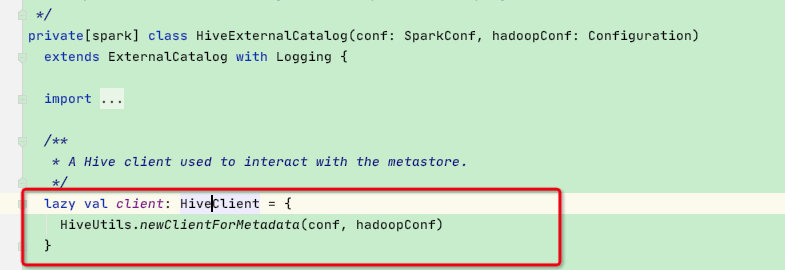
假设spark正在运行用户程序的时候需要获取hive表的分区信息,此时spark-driver线程将调用HiveExternalCatalog的loadPartition函数
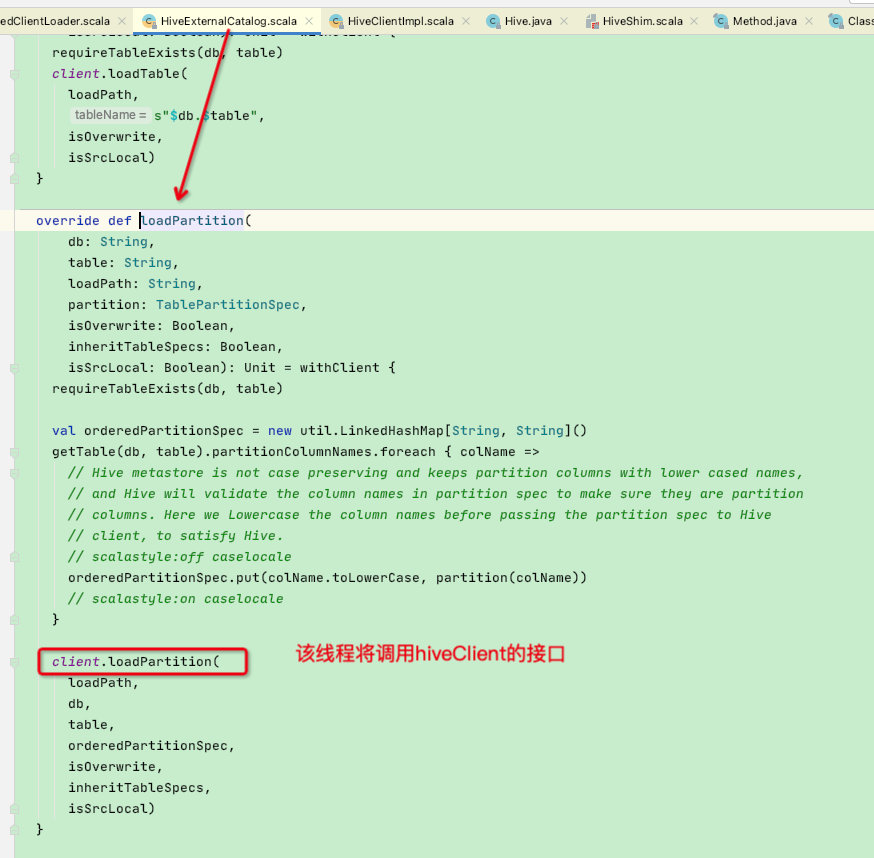
再调用HiveClientImpl的loadPartition函数,注意,走到这一步的当前线程是不包含用户指定版本hive的classLoader!那么此时shim.loadPartition函数中的client【Hive】将会是spark内置hive-2.3.7版本的org.apache.hadoop.hive.ql.metadata.Hive;
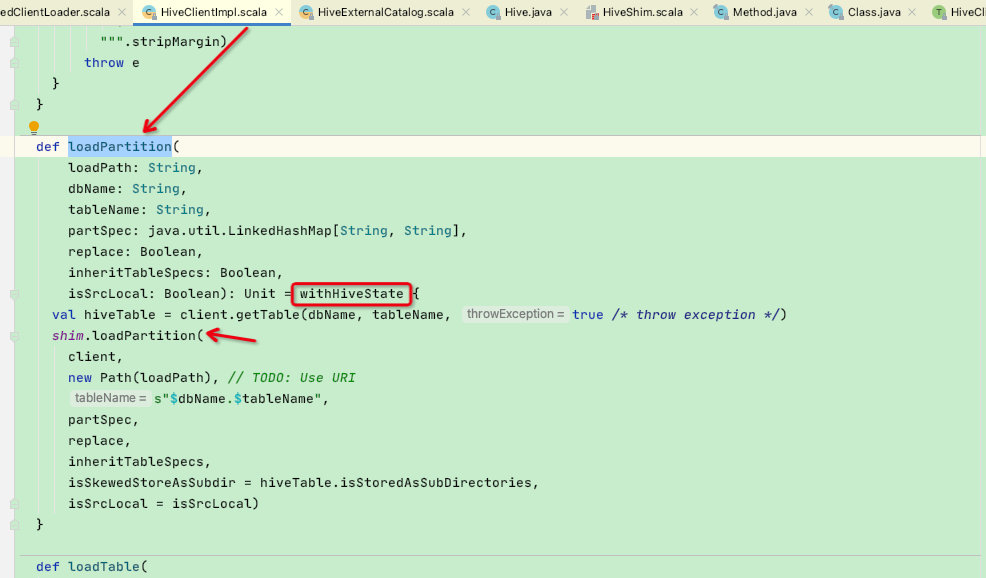
这个问题其实是通过withHiveState函数解决的:在该函数中会切换当前线程的classLoader,将IsolatedClientLoader中的classloader传入当前线程后再调用传入的f函数,假设此时的f函数是上面的shim.loadPartition(),那么当线程执行到loadPartition的client函数时所加载的org.apache.hadoop.hive.ql.metadata.Hive便是不同版本的Hive
def withHiveState[A](f: => A): A = retryLocked {
// 保留当前线程的classLoader
val original = Thread.currentThread().getContextClassLoader
val originalConfLoader = state.getConf.getClassLoader
// 设置当前现成的clientLoader,该参数是构建HiveClientImpl时传入的clientLoader【即IsolatedClientLoader】
Thread.currentThread().setContextClassLoader(clientLoader.classLoader)
state.getConf.setClassLoader(clientLoader.classLoader)
// Set the thread local metastore client to the client associated with this HiveClientImpl.
Hive.set(client)
// Replace conf in the thread local Hive with current conf
Hive.get(conf)
// setCurrentSessionState will use the classLoader associated
// with the HiveConf in `state` to override the context class loader of the current
// thread.
shim.setCurrentSessionState(state)
val ret = try {
f //调用函数f
} catch {
case e: NoClassDefFoundError
if HiveUtils.isHive23 && e.getMessage.contains("org/apache/hadoop/hive/serde2/SerDe") =>
throw new ClassNotFoundException("The SerDe interface removed since Hive 2.3(HIVE-15167)." +
" Please migrate your custom SerDes to Hive 2.3 or build your own Spark with" +
" hive-1.2 profile. See HIVE-15167 for more details.", e)
} finally {
// 最终将恢复线程classLoader
state.getConf.setClassLoader(originalConfLoader)
Thread.currentThread().setContextClassLoader(original)
HiveCatalogMetrics.incrementHiveClientCalls(1)
}
ret
}
HiveClientImpl中需要用到shim来解决冲突的函数都会使用withHiveState
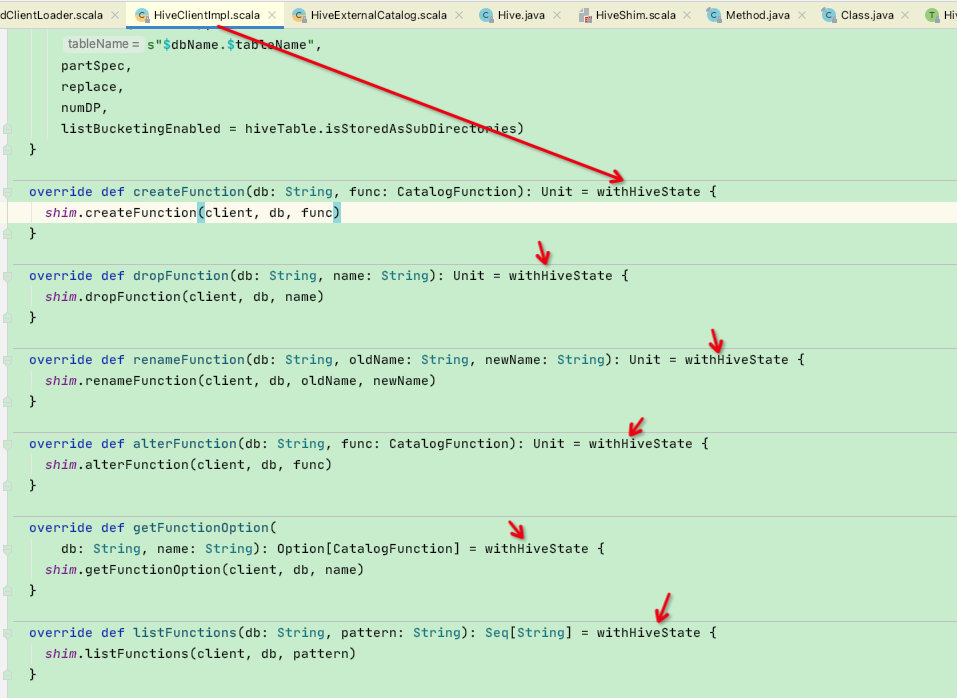
为了方便理解,这里看一下HiveClientImpl相关类图: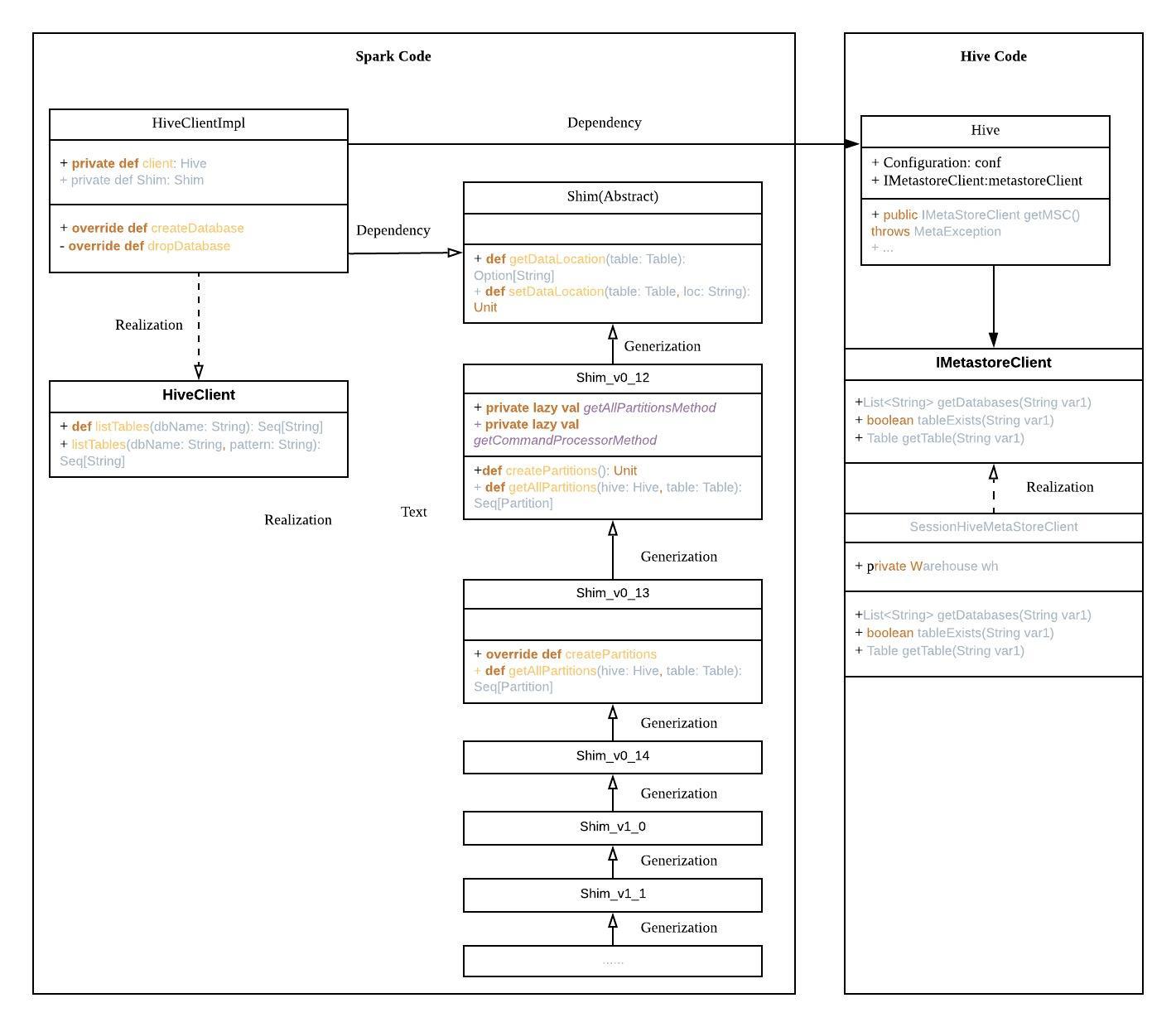
至此spark兼容多版本Hive的源码就讲解完了,接下来说一下如何使用
三、使用
1、前提
当spark内置的hiveMetaStore相关包不足以支撑用户需求,此时需要使用另外两种模式来手动配置
spark2.x版本默认的hive是1.2.1版本
spark3.x版本默认的hive是2.3.7版本
一般来说hive的这两个版本向下兼容性较好,只不过不支持一些高版本hive-API
2、maven模式
适用场景
1、用户服务器上没有hiveMetaStore相关的classPath
2、用户自己配置的hiveMetaStore相关classPath不全、缺包、报错,因此想让spark自行下载【省事】
注意事项
1、该模式需要同时配置spark.sql.hive.metastore.jars 和 spark.sql.hive.metastore.version
2、如果是一些特殊hiveMetaStore包而maven远程仓库没有,则需要手动指定远程仓库,配置: --conf spark.sql.maven.additionalRemoteRepositories=xxxx
3、不要指定当前spark版本中还没有适配的hive,比如用户使用的是spark-2.4版本,此时shim中还没有适配hive_3.0的api,而用户设置hive版本却是hive-3.0;
使用
spark-submit xxxx --conf spark.sql.hive.metastore.jars=maven --conf spark.sql.hive.metastore.version=hive版本
3、用户模式
适用场景
1、该模式需要同时配置spark.sql.hive.metastore.jars 和 spark.sql.hive.metastore.version
2、用户服务器上有hiveMetaStore相关的classPath
注意事项
1、该模式需要同时配置spark.sql.hive.metastore.jars 和 spark.sql.hive.metastore.version
2、spark.sql.hive.metastore.jars指定的classpath 要和 spark.sql.hive.metastore.version版本对应上
3、不要指定当前spark版本中还没有适配的hive,比如用户使用的是spark-2.4版本,此时shim中还没有适配hive_3.0的api,而用户设置hive版本却是hive-3.0;
使用
spark-submit xxxx --conf spark.sql.hive.metastore.jars=xxxx --conf spark.sql.hive.metastore.version=hive版本
四、尾声
至此spark兼容多版本hive的源码就分析完了,Spark对Hive版本的兼容以及通过多ClassLoader加载不同版本hive的设计思想非常经典,建议大家边看源码边学习
![[附源码]计算机毕业设计springboot青栞系统](https://img-blog.csdnimg.cn/24cd620699b34fde958ed69f48a0fa9b.png)
![[附源码]JAVA毕业设计工程车辆动力电池管理系统(系统+LW)](https://img-blog.csdnimg.cn/223111ab239c4149aa7e6a35f7e035f9.png)
![[附源码]JAVA毕业设计个人信息管理系统(系统+LW)](https://img-blog.csdnimg.cn/f3ed4c3b1c9e462883690461440f89b8.png)



![[附源码]计算机毕业设计JAVA校园环境保护监督系统](https://img-blog.csdnimg.cn/a7c5433087ce4b9f835f0ccf4fc46806.png)