前文:
《Tomcat源码:启动类Bootstrap与Catalina的加载》
《Tomcat源码:容器的生命周期管理与事件监听》
《Tomcat源码:StandardServer与StandardService》
《Tomcat源码:Container接口》
《Tomcat源码:StandardEngine、StandardHost、StandardContext、StandardWrapper》
《Tomcat源码:Pipeline与Valve》
写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。
前言
在前面得文章中,我们介绍了Tomcat中得容器是如何从service启动到具体得servlet包装类wrapper得。servlet容器启动后就可以为我们提供访问服务了吗?答案是否定得,因为servlet只规定了如何处理请求,但没有实现请求得分发,这个功能是由tomcat得另一部分连接器来完成得。
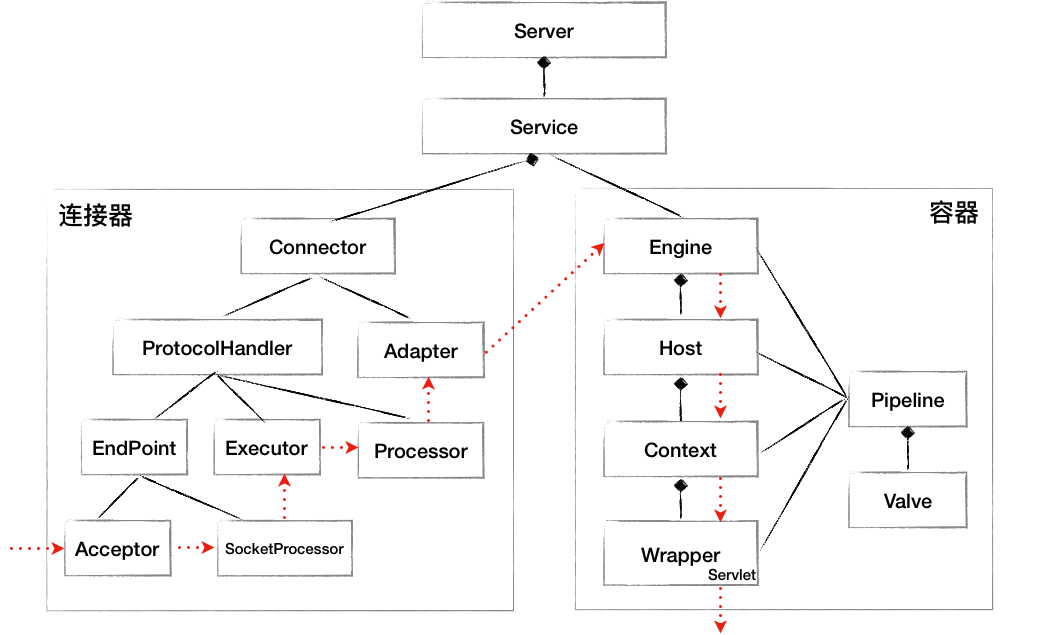
(图片来源《Tomcat连接器》,左侧为连接器,右侧为容器)
连接器的启动点为connector组件,在前文《Tomcat源码:StandardServer与StandardService》中,我们介绍了StandardService的生命周期方法initInternal、startInternal,在启动了子容器engine后就会启动executor、mapperlistener以及connector。
本文我们就来介绍下executor与connector。
#initInternal
engine.init()
executor.init
mapperListener.init()
connector.init()
#startInternal
engine.start();
executor.start();
mapperListener.start();
connector.start();
目录
前言
一、连接器
连接器的作用
连接器的组成
ProtocolHandler 组件
EndPoint
Processor
Adapter
二、Executor
1、Executor组件介绍
2、线程池与任务队列
2.1、JUC中得ThreadPoolExecutor
2.2、线程池ThreadPoolExecutor
2.3、任务队列
3、Executor参数
三、connector
1、构造方法
2、生命周期方法
3、connector与Executor得关联
4、connector参数
一、连接器
连接器的作用
Tomcat 要实现 2 个核心功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及处理具体的 Request 请求。
为此,Tomcat 设计了两个核心组件连接器(负责和外部通信)与容器(负责内部业务),容器我们之前得文章已经做了介绍,下面我们来介绍下连接器得内容。
连接器的主要功能是:
- 网络通信
- 应用层协议解析
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化
Tomcat 设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和 Adapter。

组件间通过抽象接口交互。这样做的好处是封装变化。封装是面向对象设计的精髓,将系统中经常变化的部分和稳定的部分隔离,有助于增加复用性,并降低系统耦合度。网络通信的 I/O 模型是变化的,可能是非阻塞 I/O、异步 I/O 或者 APR。应用层协议也是变化的,可能是 HTTP、HTTPS、AJP。浏览器端发送的请求信息也是变化的。但是整体的处理逻辑是不变的,EndPoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。
如果要支持新的 I/O 方案、新的应用层协议,只需要实现相关的具体子类,上层通用的处理逻辑是不变的。由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO2 + AJP。Tomcat 的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点。各种协议和通信模型的组合有相应的具体实现类。比如:Http11NioProtocol 和 AjpNioProtocol。

连接器的组成
ProtocolHandler 组件
连接器用 ProtocolHandler 接口来封装通信协议和 I/O 模型的差异。ProtocolHandler 内部又分为 EndPoint 和 Processor 模块,EndPoint 负责底层 Socket 通信,Proccesor 负责应用层协议解析。
EndPoint
EndPoint 是通信端点,即通信监听的接口,是具体的 Socket 接收和发送处理器,是对传输层的抽象,因此 EndPoint 是用来实现 TCP/IP 协议的。
EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件:Acceptor 和 SocketProcessor。
其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 Run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器(Executor)。
Processor
如果说 EndPoint 是用来实现 TCP/IP 协议的,那么 Processor 用来实现 HTTP 协议,Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和 Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽象。
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、HTTP11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式。
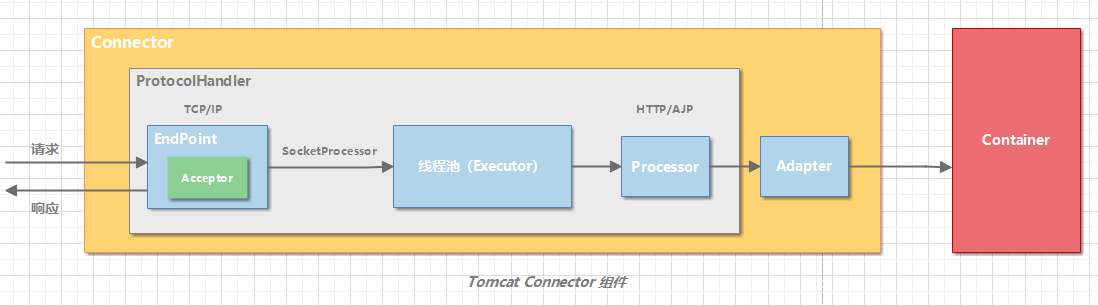
从图中我们看到,EndPoint 接收到 Socket 连接后,生成一个 SocketProcessor 任务提交到线程池去处理,SocketProcessor 的 Run 方法会调用 Processor 组件去解析应用层协议,Processor 通过解析生成 Request 对象后,会调用 Adapter 的 Service 方法。
Adapter
连接器通过适配器 Adapter 调用容器。由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己的 Request 类来适配这些请求信息。
ProtocolHandler 接口负责解析请求并生成 Tomcat Request 类。但是这个 Request 对象不是标准的 ServletRequest,也就意味着,不能用 Tomcat Request 作为参数来调用容器。Tomcat 的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,连接器调用 CoyoteAdapter 的 Sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 Service 方法。
二、Executor
1、Executor组件介绍
注意:下文只会简略的介绍下tomcat中得线程池,不会太多涉及线程相关知识点。
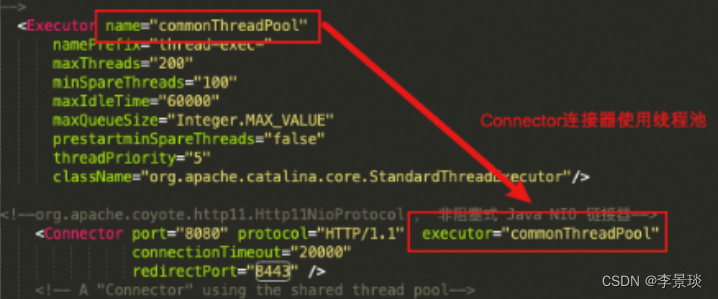
首先来看下Executor组件,这是一个tomcat内部自定义的线程池管理组件,作用是帮助connector连接器实现并发,读取的是server.xml中的Executor的配置。
<Service name="Catalina">
<!-- 1. 属性说明
name:Service的名称
-->
<!--2. 一个或多个excecutors -->
<!--
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="150" minSpareThreads="4"/>
-->
<!--
3.Connector元素:
由Connector接口定义.<Connector>元素代表与客户程序实际交互的组件,它负责接收客户请求,以及向客户返回响应结果.
-->
<Connector port="80" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
</Service> 如果未显示的申明Executor的话StandardService则会创建一个默认对象。
protected void initInternal() throws LifecycleException {
// ...
for (Executor executor : findExecutors()) {
if (executor instanceof JmxEnabled) {
((JmxEnabled) executor).setDomain(getDomain());
}
executor.init();
}
// ...
}
protected void startInternal() throws LifecycleException {
// ...
synchronized (executors) {
for (Executor executor : executors) {
executor.start();
}
}
// ...
}
public Executor[] findExecutors() {
synchronized (executors) {
return executors.toArray(new Executor[0]);
}
}Executor的实现类为StandardThreadExecutor,也继承了Lifecycle接口,因此同样具有生命周期方法。
startInternal方法中会创建任务队列TaskQueue 与连接池ThreadPoolExecutor,并将连接池与任务队列关联起来。
private TaskQueue taskqueue = null;
protected ThreadPoolExecutor executor = null;
protected void startInternal() throws LifecycleException {
taskqueue = new TaskQueue(maxQueueSize);
TaskThreadFactory tf = new TaskThreadFactory(namePrefix, daemon, getThreadPriority());
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), maxIdleTime, TimeUnit.MILLISECONDS,
taskqueue, tf);
executor.setThreadRenewalDelay(threadRenewalDelay);
taskqueue.setParent(executor);
setState(LifecycleState.STARTING);
}StandardThreadExecutor通过execute方法调用ThreadPoolExecutor的execute方法来执行并发任务。
public void execute(Runnable command) {
if (executor != null) {
executor.execute(command);
} else {
throw new IllegalStateException(sm.getString("standardThreadExecutor.notStarted"));
}
}2、线程池与任务队列
首先来了解下线程池,由于线程的创建销毁都比较消耗资源,因此JDK采取了池化技术(类似数据库连接池),帮助我们在并发的环境下管理线程。
2.1、JUC中得ThreadPoolExecutor
JUC包中的ThreadPoolExecutor,其由一个线程集合workerSet和一个阻塞队列workQueue组成,workQueue用来临时存储接收到的任务,当workerSet有空闲线程时就会从workQueue中取出待执行的任务来执行。
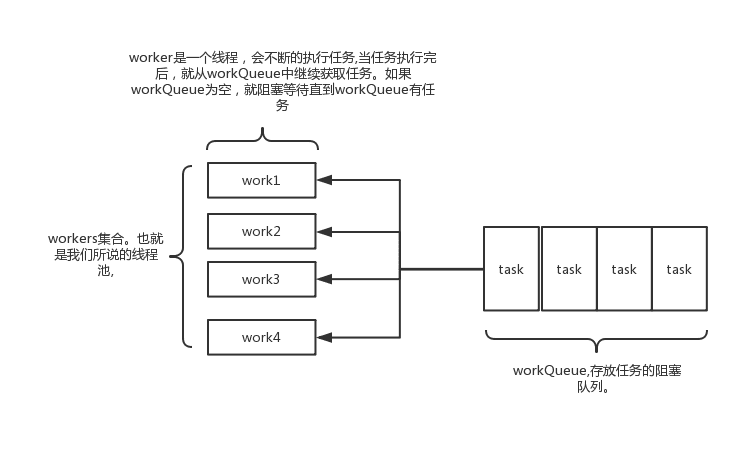
workerSet有2个核心变量corePoolSize与maximumPoolSize分别表示线程集合的初始线程数和最大线程数,workQueue会根据这两个值得大小判断是否接收线程,其运行逻辑如下:
- 当前线程数小于corePoolSize时,线程池为每个新任务创建线程。
- 线程数大于等于corePoolSize时,尝试将任务添加到任务队列中。
- 入队失败再尝试创建新得线程,如果总线程数达到 maximumPoolSize,执行拒绝策略。
private final BlockingQueue<Runnable> workQueue;
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 判断当前线程数是否小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 创建新的线程,并启动里面的Thread
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果线程池处于RUNNING态,将任务放入队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 其余内容
}
// 往线程池中创建新的线程,如果失败则拒绝任务
else if (!addWorker(command, false))
reject(command);
}
这里得入队方法通过workQueue得offer方法实现,在tomcat得定制化线程池中就是有一块重要内容就是重写了offer方法。
2.2、线程池ThreadPoolExecutor
tomcat中用来实现线程池的类是ThreadPoolExecutor,类名与JUC中的线程池管理类ThreadPoolExecutor一致,但却是两个不同的类。
// Tomcat中的ThreadPoolExecutor
org.apache.tomcat.util.threads.ThreadPoolExecutor
// JUC中的ThreadPoolExecutor
java.util.concurrent.ThreadPoolExecutortomcat得线程池中得对新线程得处理略有不同,我们直接来看源码,execute方法内部首先会使submittedCount变量加1来记录接收到得任务(任务执行完后会自动减1),然后调用executeInternal方法,而该方法得内容与JUC中得实现是一致得。
接下来是最大得区别,那就是该execute方法会捕捉executeInternal抛出得RejectedExecutionException异常,然后尝试调用任务队列得force方法将任务强制加入到队列中,如果还是不行才拒绝该任务。
原生实现中我们知道任务队列满员后才会创建新得线程,而从下文中catch块得处理逻辑可以推断当出现RejectedExecutionException异常时队列并不一定是满得,这实际上是通过重写任务队列得offer方法实现得。
private final AtomicInteger submittedCount = new AtomicInteger(0);
public void execute(Runnable command, long timeout, TimeUnit unit) {
submittedCount.incrementAndGet();
try {
// executeInternal内容与JUC中线程池的execute的内容一致
executeInternal(command);
} catch (RejectedExecutionException rx) {
// 如果总线程数达到 maximumPoolSize,抛出RejectedExecutionException异常
if (getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue) getQueue();
try {
// 继续尝试把任务放到任务队列中去
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
// 如果缓冲队列也满了,插入失败,执行拒绝策略
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
private void executeInternal(Runnable command) {
if (command == null) {
throw new NullPointerException();
}
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) {
return;
}
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
// 其他内容
}
else if (!addWorker(command, false)) {
reject(command);
}
}2.3、任务队列
在StandardThreadExecutor中为线程池创建了任务队列,可以看到默认长度为Integer.MAX_VALUE。
// StandardThreadExecutor.java
protected int maxQueueSize = Integer.MAX_VALUE;
protected void startInternal() throws LifecycleException {
// 其余代码
taskqueue = new TaskQueue(maxQueueSize);
}
// TaskQueue.java
public TaskQueue(int capacity) {
super(capacity);
}offer方法是任务队列得核心,原生实现中该方法是将任务直接入队,而这里会做具体得判断决定是入队还是创建新得线程。
第一步是判断当前线程数是否已经达到了最大线程数,如果是得话那处理方案只能是入队。
第二步判断已提交得任务数(上文中得submittedCount)与线程池得大小,即整个线程池接收到得但还未执行完得任务是否小于等于当前线程池中得线程数,如果小于得话说明有空闲线程,不用再创建,因此直接入队。
第三步判断已提交得任务数是否小于最大线程数(注意上一步已经判断了和当前线程数得关系),如果小于则说明线程不够用了,此时选择创建新得线程。
public boolean offer(Runnable o) {
// 如果线程数已经到了最大值,不能创建新线程了,只能把任务添加到任务队列。
if (parent.getPoolSizeNoLock() == parent.getMaximumPoolSize()) {
return super.offer(o);
}
// 如果已提交的任务数小于等于当前线程数,表示还有空闲线程,无需创建新线程
if (parent.getSubmittedCount() <= parent.getPoolSizeNoLock()) {
return super.offer(o);
}
// 如果已提交的任务数大于当前线程数,线程不够用了,返回 false 去创建新线程
if (parent.getPoolSizeNoLock() < parent.getMaximumPoolSize()) {
return false;
}
// 默认情况下总是把任务添加到任务队列
return super.offer(o);
}而force则是调用父类方法,即直接入队。
public boolean force(Runnable o) {
if (parent == null || parent.isShutdown()) {
throw new RejectedExecutionException(sm.getString("taskQueue.notRunning"));
}
return super.offer(o);
}从上面的代码我们看到,如果当前线程数大于核心线程数、小于最大线程数,并且已提交的任务个数大于当前线程数时,也就是说线程不够用了,但是线程数又没达到极限,会去创建新的线程。
与JUC中得实现方式相比,tomcat中得实现在面对线程数不足时更倾向于创建线程而非入队,同时由于StandardThreadExecutor继承了Lifecycle接口,因此也被纳入了生命周期管理。
3、Executor参数
经过了上文得介绍,我们再来看下Executor提供得可选配置参数
| 属性 | 描述 | 备注 |
|---|---|---|
| className | 这个类必须实现org.apache.catalina.Executor接口。 | 默认 org.apache.catalina.core.StandardThreadExecutor |
| name | 线程池名称。 | 要求唯一, 供 Connector 元素的 executor 属性使用 |
| namePrefix | 线程名称前缀。 | |
| maxThreads | 最大活跃线程数。 | 默认 200 |
| minSpareThreads | 最小活跃线程数。 | 默认 25 |
| maxIdleTime | 当前活跃线程大于 minSpareThreads 时,空闲线程关闭的等待最大时间。 | 默认 60000ms |
| maxQueueSize | 线程池满情况下的请求排队大小。 | 默认 Integer.MAX_VALUE |
三、connector
1、构造方法
connector得构造方法会使用反射创建一个protocolHandler对象,默认实现类为Http11NioProtocol。protocolHandler相关内容我们会在后续介绍,这里只需要知道protocolHandler负责为connector实现具体得连接处理。
protected String protocolHandlerClassName = "org.apache.coyote.http11.Http11NioProtocol";
public Connector() {
this(null);
}
public Connector(String protocol) {
setProtocol(protocol);
ProtocolHandler p = null;
try {
Class<?> clazz = Class.forName(protocolHandlerClassName);
p = (ProtocolHandler) clazz.getConstructor().newInstance();
} catch (Exception e) {
log.error(sm.getString("coyoteConnector.protocolHandlerInstantiationFailed"), e);
} finally {
this.protocolHandler = p;
}
// 其余代码
}2、生命周期方法
connector也同样继承了Lifecycle接口,因此也具有了生命周期方法。
首先来看 initInternal,这里会创建一个CoyoteAdapter,该类负责将网络请求从连接器传递到容器中,然后关联CoyoteAdapter与protocolHandler,最后调用protocolHandler得init方法。
protected void initInternal() throws LifecycleException {
super.initInternal();
adapter = new CoyoteAdapter(this);
protocolHandler.setAdapter(adapter);
// 其余代码
try {
protocolHandler.init();
} catch (Exception e) {
throw new LifecycleException(sm.getString("coyoteConnector.protocolHandlerInitializationFailed"), e);
}
}startInternal方法也很简单,调用protocolHandler得start方法就没了。
protected void startInternal() throws LifecycleException {
// 其余代码
try {
protocolHandler.start();
} catch (Exception e) {
throw new LifecycleException(sm.getString("coyoteConnector.protocolHandlerStartFailed"), e);
}
}3、connector与Executor得关联
前文中我们介绍过,server.xml在解析时会创建一些监听规则,这里就有一个关于connector得规则ConnectorCreateRule。
protected Digester createStartDigester(){
//...
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
//...
}在ConnectorCreateRule中得begin方法调用setExecutor,会为Connector中得ProtocolHandler对象设置Executor,使得连接器中得组件能够使用我们上文创建得连接池。
public void begin(String namespace, String name, Attributes attributes)
throws Exception {
Service svc = (Service)digester.peek();
Executor ex = null;
// 获取配置中得Executor 与Connector
if ( attributes.getValue("executor")!=null ) {
ex = svc.getExecutor(attributes.getValue("executor"));
}
Connector con = new Connector(attributes.getValue("protocol"));
if (ex != null) {
// 调用setExecutor方法
setExecutor(con, ex);
}
// ...
digester.push(con);
}
private static void setExecutor(Connector con, Executor ex) throws Exception {
// 获取Connector中得ProtocolHandler,调用其setExecutor方法
Method m = IntrospectionUtils.findMethod(con.getProtocolHandler().getClass(),"setExecutor",new Class[] {java.util.concurrent.Executor.class});
if (m!=null) {
m.invoke(con.getProtocolHandler(), new Object[] {ex});
}else {
log.warn(sm.getString("connector.noSetExecutor", con));
}
}4、connector参数
注意这里得maxConnections、acceptCount与Executor 中属性 maxQueueSize 的区别。
| 属性 | 说明 | 备注 |
|---|---|---|
| acceptCount | 当最大请求连接 maxConnections 满时的最大排队大小 | 默认 100,注意此属性和 Executor 中属性 maxQueueSize 的区别.这个指的是请求连接满时的堆栈大小,Executor 的 maxQueueSize 指的是处理线程满时的堆栈大小 |
| connectionTimeout | 请求连接超时 | 默认 60000ms |
| executor | 指定配置的线程池名称 | |
| keepAliveTimeout | keeAlive 超时时间 | 默认值为 connectionTimeout 配置值.-1 表示不超时 |
| maxConnections | 最大连接数 | 连接满时后续连接放入最大为 acceptCount 的队列中. 对 NIO 和 NIO2 连接,默认值为 10000;对 APR/native,默认值为 8192 |
| maxThreads | 如果指定了 Executor, 此属性忽略;否则为 Connector 创建的内部线程池最大值 | 默认 200 |
| minSpareThreads | 如果指定了 Executor, 此属性忽略;否则为 Connector 创建线程池的最小活跃线程数 | 默认 10 |
| processorCache | 协议处理器缓存 Processor 对象的大小 | -1 表示不限制.当不使用 servlet3.0 的异步处理情况下: 如果配置 Executor,配置为 Executor 的 maxThreads;否则配置为 Connnector 的 maxThreads. 如果使用 Serlvet3.0 异步处理, 取 maxThreads 和 maxConnections 的最大值 |