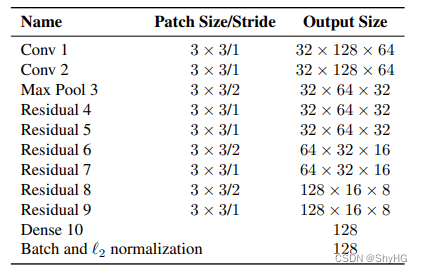
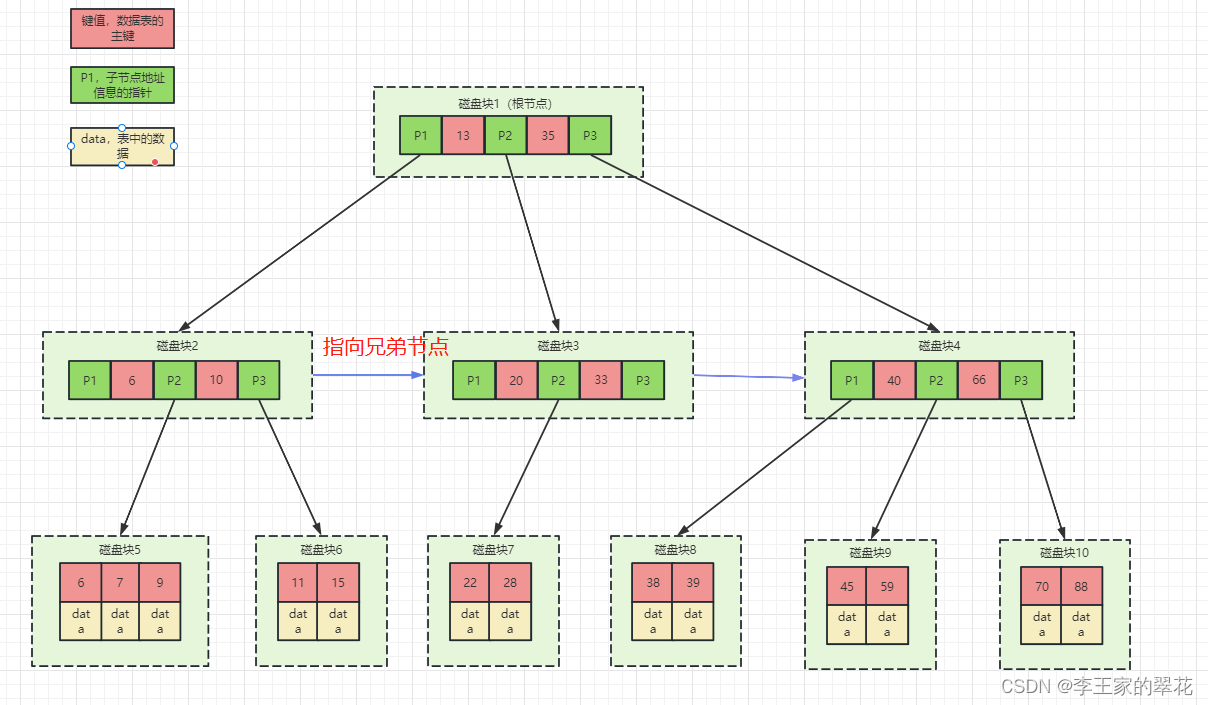
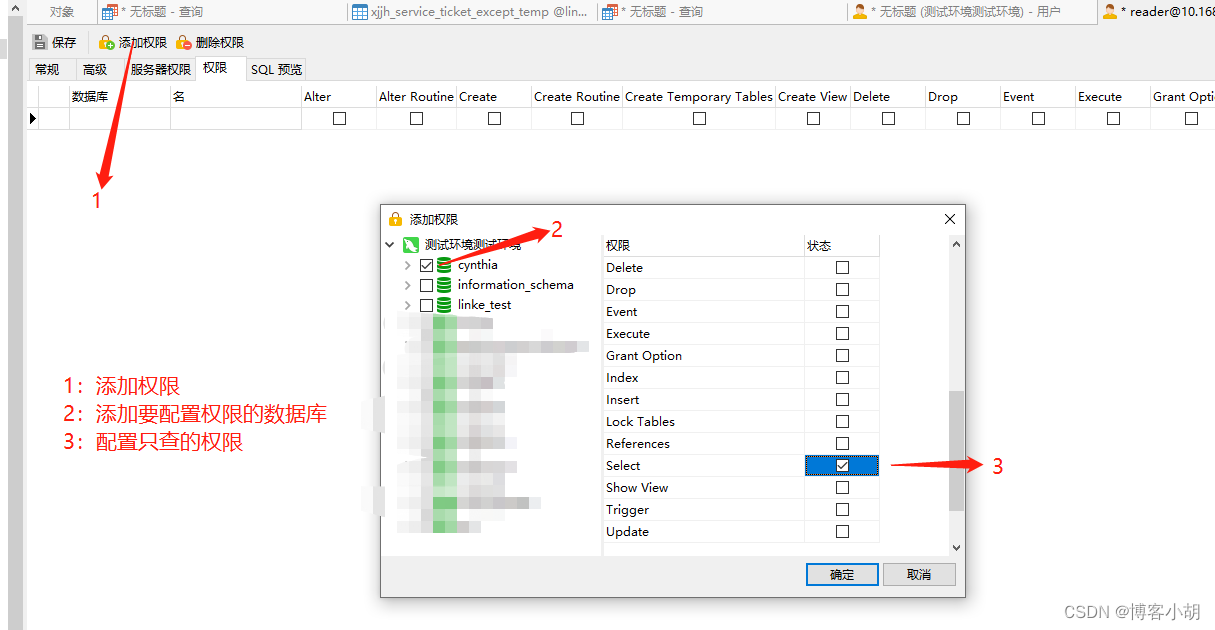
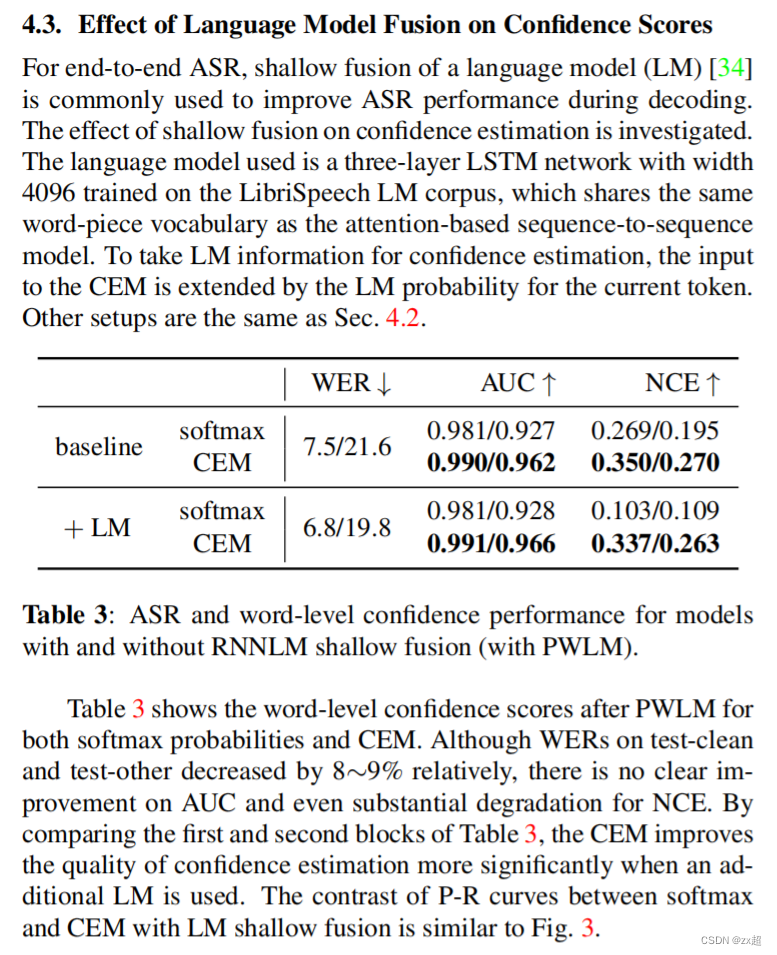
本帖介绍UDA 的一个分支:bi-classifier adversarial learning。
一、回顾
在介绍 bi-classifier adversarial learning 之前,先来回忆一下 adversarial generation framework, 因为前者是基于后者的改进。

如图1所示,左边表示的是1)对抗学习方法 adversarial generation ,右边表示的是2)双分类器对抗学习方法 bi-classifier adversarial learning。
对抗学习方法,包括domain classifier (i.e., a discriminator) and feature generator两个部分。训练域分类器网络来区分特征是源还是目标,并训练特征生成器网络来使鉴别器混淆判断。这类方法存在两个问题。
首先,域分类器只试图区分特征作为源或目标,因此不考虑类之间特定于任务的决策边界。因此,经过训练的生成器可能在类边界附近生成模棱两可的特征。
其次,这些方法的目标是完全匹配不同领域之间的特征分布,但不同域的特点不同,这个很难做到。
双分类器对抗学习方法,利用特定于任务的决策边界来对齐源和目标的分布。
首先,最大化两个分类器输出之间的差异,以检测远离源的目标样本。
然后,特征生成器学习如何将决策边界外的样本生成决策边界内的目标特征以最小化差异。
总结:
对于上图1来说,传统的对抗学习的方法只考虑了目标域的特征去迎合源域的特征的分布,但在决策边界周围会有模棱两可的特征,不利于特定任务的性能;双分类器学习方法,把特定任务分类器引入了对抗学习的过程,考虑了任务决策边界和目标样本之间的关系,使得生成器生成目标样本的判别特征。
二、主要思想

2.1 符号系统
带标签的源图像{xs, ys}
未标记的目标图像xt
特征生成器网络g,它接受输入xs或xt
分类器网络h1和h2,它们从g中获取特征
h1和h2将样本分为K类,输出一个K维的logits向量,对向量应用softmax函数来获得类概率。符号p1(y|x), p2(y|x)来表示分别由h1和h2获得的输入x的k维概率输出。
2.2 基本思想
利用特定于任务的分类器作为判别器来对齐源和目标特征,以便考虑类边界和目标样本之间的关系。为了实现这一目标,我们必须在远离源支持的地方检测目标样本。
问题是如何检测远离支持点的目标样本。这些目标样本很可能被从源样本中学习到的分类器误分类,因为它们靠近类边界。然后,为了检测这些目标样本,我们提出利用两种分类器在目标样本预测上的分歧。考虑两个分类器(h1和h2),它们在图2的最左侧具有不同的特征。我们假设这两个分类器可以正确地对源样本进行分类。这个假设是现实的,因为我们可以在UDA的设置中访问标记的源样本。此外,请注意,h1和h2的初始化方式不同,以便从训练开始时获得不同的分类器。(如何保证获得的分类器不同?)
在这里,我们有一个关键的直觉,即源支持之外的目标样本可能会被两个不同的分类器分类。该区域在图2(差异区)的最左侧用黑线表示。相反,如果我们可以度量两个分类器之间的分歧,并训练生成器使分歧最小化,则生成器将避免生成源支持之外的目标特征。在这里,我们考虑使用以下方程来测量目标样本的差异,d(p1(y|xt), p2(y|xt)),其中d表示测量两个概率输出之间散度的函数。这个术语表明两个分类器在预测上是如何不一致的,以后我们称这个术语为差异。我们的目标是获得一个可以最小化目标样本差异的特征生成器。
为了有效地检测源支持之外的目标样本,我们提出训练判别器(h1和h2)来最大化给定目标特征的差异(图2中的最大化差异)。如果不进行此操作,两个分类器可能非常相似,无法检测源支持之外的目标样本。然后,我们训练生成器来欺骗鉴别器,即通过最小化差异(图2中的最小化差异)。该操作鼓励在源的支持范围内生成目标样本。这种对抗性学习步骤在我们的方法中是重复的。
2.3 步骤
第一步,基于标记的源样本训练特征提取器g和两个分类器 h1和 h2,使模型拟合源域的分布;
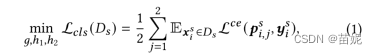
第二步,冻结特征提取器g,通过最大化未标记的目标样本的预测差异来寻找源分布支持之外的目标样本,同时最小化标记的源样本的交叉熵来更新两个分类器;
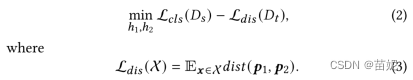
第三步,更新特征提取器푔,通过最小化未标记目标样本与固定两个分类器的预测差异来对齐两个域之间的分布;
![]()
这三个步骤在我们的方法中重复。这三个步骤的顺序并不重要。主要关注的是在分类器和生成器能够正确分类源样本的条件下,以对抗的方式训练它们。
2.4 补充说明
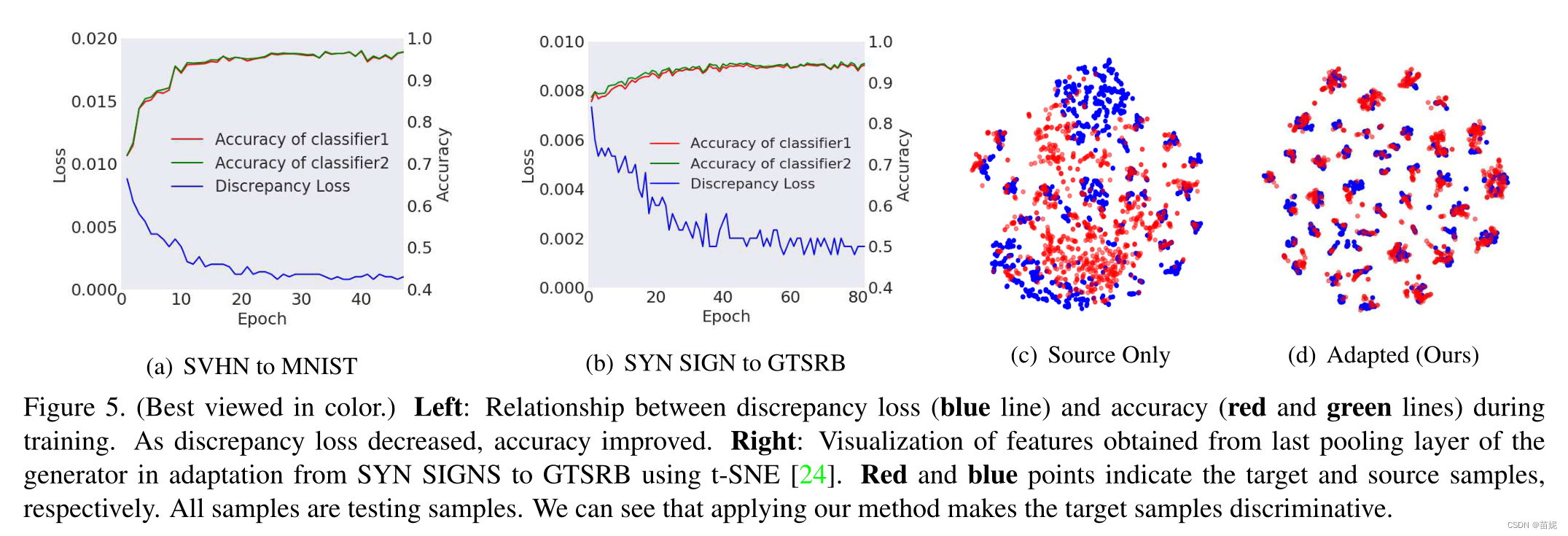
在这里我想补充一下对双分类器的理解,本来目标样本是没有标签的,那怎么用没有标签的样本来提高特定任务在目标域的性能呢? 传统的对抗学习的做法,是直接让目标域数据的特征向源域靠近,那无论做什么任务,都可以达到 不错的效果!双分类器对抗学习认为,既然要提高某个具体任务在目标域上的准确率,为什么不结合具体任务来处理,因此这里的分类器不再是域分类器,而是特定任务分类器; 但由于目标域没有标签,训练的时候没有办法测试特定任务分类器在目标域的性能呀?于是,就设计了两个分类器,如果两个分类器预测出来的差异很大,就说明分类器不好或者是特征提取器提取的特征不够关键,在这里是利用两个分类器预测结果的差异来表明分类器性能的好坏。而当分类器性能最差的时候是什么时候呀,当然是两个分类器在目标域上预测差异最大的时候,也就是散度最大的时候。此外差异最大的时候,可以保证在源域上分类效果好且分类的边界是清晰的,效果差的那些目标域样本被挑了出来。那如何去解决分类器分类效果差呀?丢锅给了特征提取器,一定是特征提取器没有提到和任务相关的关键特征,如下图所示,经过特征提取提取器提取的特征源域和目标域更相似(有种聚类的效果),因此继续训练特征提取器,直到两个任务分类器分出近乎一致的结果。
在这类方法里,不同的学者在度量分类器预测结果差异上采用了不同的方式。
这里我的疑问是,为甚么是双分类器,三分类器呢?效果会不会更好~
而且这里有点勉强的是为啥,两个任务分类器最差的时候,仅仅靠调节特征生成器就可以让目标分布靠近源分布?
最终结论,深度学习赢得就是这么粗鲁,因为双分类器给了一个更明确的导向,就是从具体任务(也就是评价指标)入手!干的漂亮!
2.5 实验结果

三、参考文献
[1] Saito K, Watanabe K, Ushiku Y, et al. Maximum classifier discrepancy for unsupervised domain adaptation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3723-3732.
[2] Lee C Y, Batra T, Baig M H, et al. Sliced wasserstein discrepancy for unsupervised domain adaptation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 10285-10295.
[3] Li S, Lv F, Xie B, et al. Bi-classifier determinacy maximization for unsupervised domain adaptation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(10): 8455-8464.