目录
一、正则表达式的介绍
1)正则表达式的组成
2)正则表达式和通配符的区别
二、基础正则表达式
1)转义字符的运用
将特殊含义的字符转换为普通字符的含义
将普通字符转换为特殊作用的字符
2)基础正则表达式实际应用
查看以xxx为开头 和查看以xxx为结尾的文件内容
匹配单个任意字符或者多个任意字符
匹配列表内容和匹配非列表中的内容
对子表达式进行多次或者限定次数的匹配
三、拓展正则表达式
1)拓展正则表达式的基本用法
2)拓展正则表达式的实际运用
四、正则表达式的组合筛查运用
1)按要求匹配输出规定的电话号码
2)按照要求匹配出规定格式的邮箱
一、正则表达式的介绍
1)正则表达式的组成
正则表达式是由普通字符与元字符组成:
-
普通字符 包括大小写字母、数字、标点符号及一些其他符号
-
元字符 是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
2)正则表达式和通配符的区别
通配符:在Linux中,一般配合find命令用于对文件目录,文件名的查找
正则表达式:匹配文件内容,用于精确筛选信息,可以配合grep,egrep,awk,sed命令进行搭配使用,查找时,也比通配符更加精确
二、基础正则表达式
适合awk,sed,grep,egrep等文本工具使用
| 元字符 | 作用 |
| \ | 转义字符,用于取消特殊符号的含义 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结束的位置 |
| . | 匹配除\n之外的任意的单个字符 |
| * | 匹配前面子表达式0次或者多次 |
| [list] | 匹配list列表中的一个字符(列表中只要有一个符合即可) |
| [^list] | 匹配任意非list列表中的一个字符 |
| \ {n\ } | 匹配前面的子表达式n次 |
| \ {n,\ } | 匹配前面的子表达式不少于n次 |
| \ {n,m\ } | 匹配前面的子表达式n到m次(m必须大于n,不然会报错) |
注意:egrep、 awk使用{n}、{n,}、{n, m}匹配时 "{ }" 前不用加" \ "
1)转义字符的运用
将特殊含义的字符转换为普通字符的含义
| 被转义的特殊字符 | 转义前的含义作用 |
| \ = | 具有赋值的作用,或则进行字符判断 |
| \ ! | 有取反的作用(除了。。。。) |
| \ & | 单个&符可以将命令挂在后台上,两个是逻辑符号且的作用 |
| \ $ | 取值变量的作用 |
将普通字符转换为特殊作用的字符
| 被赋予新含义的普通字符 | 现在拥有的作用 |
| \n | 拥有换行的作用 |
| \t | 转化为制表符(能让输出结果呈现表格的格式) |
| \w(小写) | 匹配包括下划线的任何单词字符 |
| \W(大写) | 匹配任何非单词字符。等通于"[^A-Za-z0-9_]" |
| \r | 转换后是回车符 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \s(小写) | 空白符 |
| \S(大写) | 非空白符 |
2)基础正则表达式实际应用
查看以xxx为开头 和查看以xxx为结尾的文件内容
[root@localhost tr]#grep '^1' math.txt
[root@localhost tr]#grep '3$' math.txt 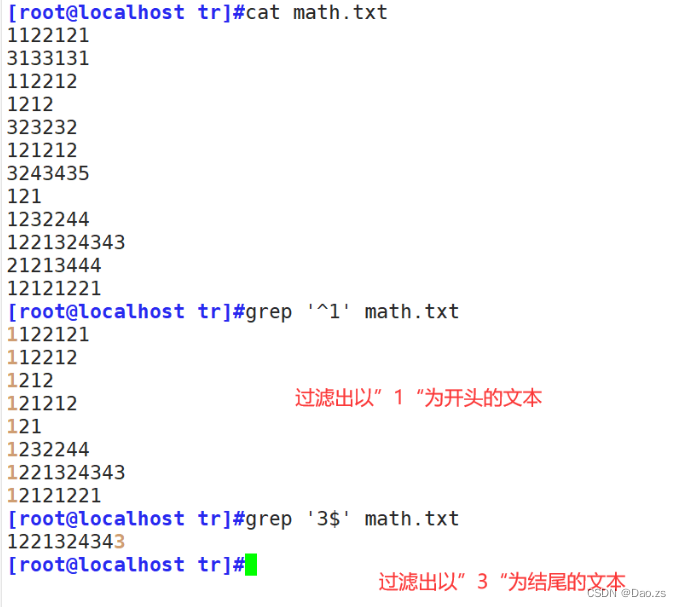
匹配单个任意字符或者多个任意字符
[root@localhost tr]#grep 'g.d' english.txt
[root@localhost tr]#grep 'g.*d' english.txt 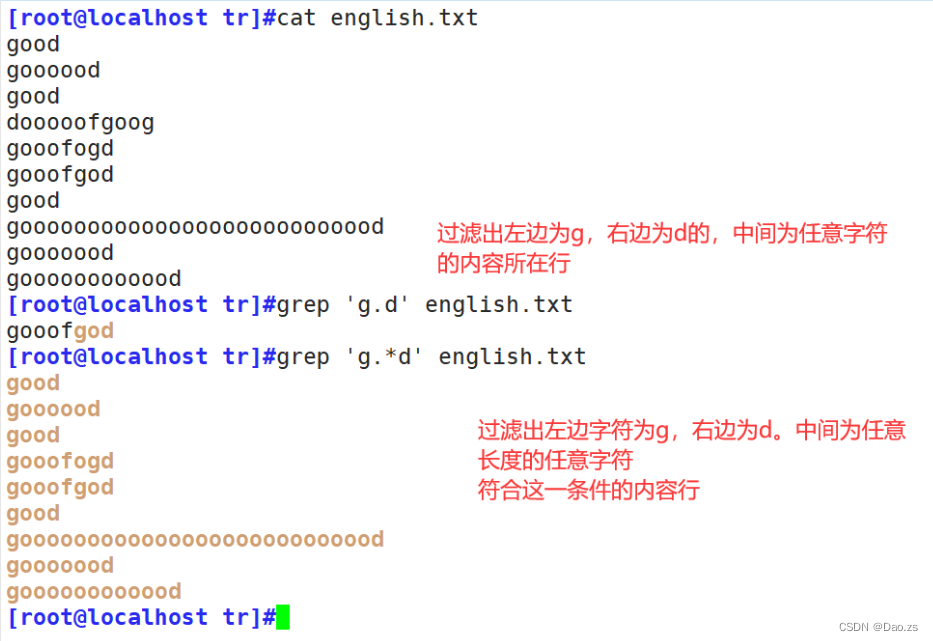
匹配列表内容和匹配非列表中的内容
[root@localhost tr]#head -n10 /etc/passwd |grep '[root]'
[root@localhost tr]#head -n10 /etc/passwd |grep '[^root]'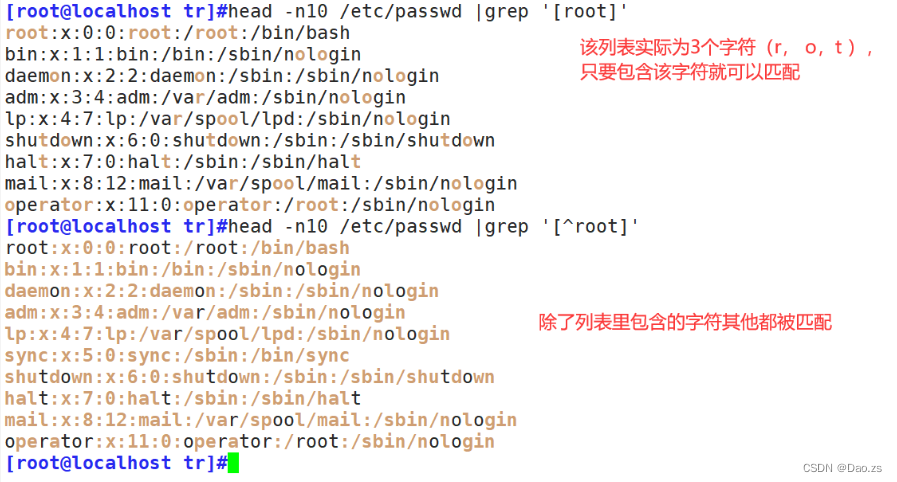
对子表达式进行多次或者限定次数的匹配
[root@localhost tr]#grep "go\{1\}" english.txt
[root@localhost tr]#egrep "go{2,}" english.txt
[root@localhost tr]#egrep "go{5,8}" english.txt 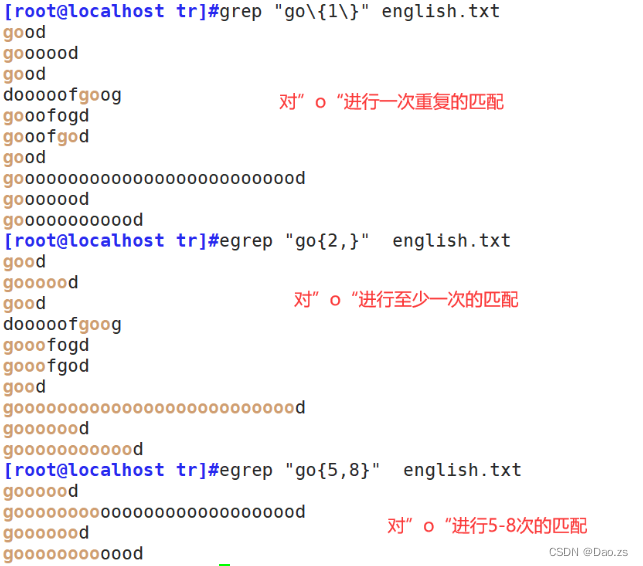
三、拓展正则表达式
1)拓展正则表达式的基本用法
支持awk和egrep使用,如果grep和sed想要正常使用(grep -E sed -r)
| 元字符 | 作用含义 |
| + | 匹配前面子表达式1次及以上 |
| ? | 匹配前面子表达式0次或者1次 |
| () | 将括号中的字符串作为一个整体 |
| | | 以"或"的方式匹配字符串 |
2)拓展正则表达式的实际运用
[root@localhost tr]#egrep 'go+d' english.txt
[root@localhost tr]#egrep 'go?d' english.txt
[root@localhost tr]#egrep '(good)' english.txt
[root@localhost tr]#egrep 'good|fgod' english.txt 
四、正则表达式的组合筛查运用
1)按要求匹配输出规定的电话号码
匹配要求:
- 匹配 025 开头的区号
- 区号与后面的号码以"-"或则空格或则没有
- 电话号码要5 或者 8开头的八位数
[root@localhost ~]#egrep "^(025)[- ]?[58][0-9]{7}$" phone.txt

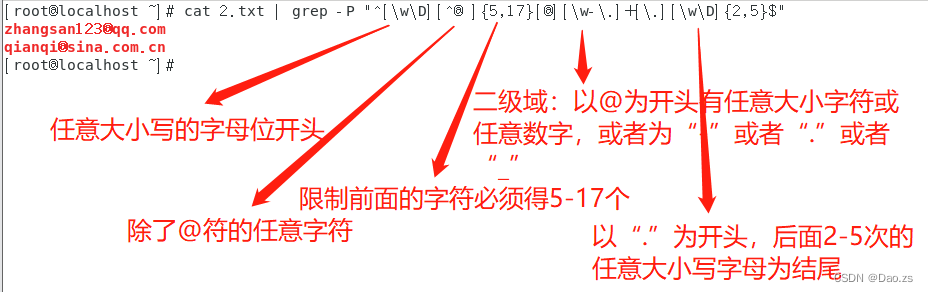
2)按照要求匹配出规定格式的邮箱
匹配要求:
- 用户名@的长度为6-18位,任意大小写的英文字母,任意数字,除了@和空格以外的任意符号,开头只能是_或者英文字母
- 子域名(二级域):任意长度,符号只能使用"-"或者"_"或者"."
- 顶级域:长度位2-5,任意大小写的英文
[root@localhost ~]# cat 2.txt | grep -P "^[\w\D][^@ ]{5,17}[@][\w-\.]+[\.][\w\D]{2,5}$"








![[答疑]事件和其影响的属性的对应是多样的](https://img-blog.csdnimg.cn/img_convert/c442021617b693d2f4a78c88d94f1f41.png)