一.简历文本标注数据的准备
目标:把原始数据集转换为PaddleNLP支持的文本/文档抽取标注格式,为后续的模型微调做好准备。
工具:Label Studio
使用手册:
applications/information_extraction/label_studio_text.md · PaddlePaddle/PaddleNLP - Gitee.com![]() https://gitee.com/paddlepaddle/PaddleNLP/blob/develop/applications/information_extraction/label_studio_text.mdLabel Studio是一个开源的数据标注工具,用于创建、管理和维护各种类型的机器学习数据集。它提供了一个基于Web的用户界面,可以让用户轻松地创建自定义的数据标注任务,并邀请其他用户来共同完成标注工作。Label Studio支持多种数据类型和标注类型,包括文本、图像、音频、视频和其他自定义数据类型。
https://gitee.com/paddlepaddle/PaddleNLP/blob/develop/applications/information_extraction/label_studio_text.mdLabel Studio是一个开源的数据标注工具,用于创建、管理和维护各种类型的机器学习数据集。它提供了一个基于Web的用户界面,可以让用户轻松地创建自定义的数据标注任务,并邀请其他用户来共同完成标注工作。Label Studio支持多种数据类型和标注类型,包括文本、图像、音频、视频和其他自定义数据类型。
环境配置参看:
简历信息提取(三):文本抽取的UIE格式转换与微调训练 - 飞桨AI Studio (baidu.com)![]() https://aistudio.baidu.com/aistudio/projectdetail/5418951?channelType=0&channel=0数据集的准备:
https://aistudio.baidu.com/aistudio/projectdetail/5418951?channelType=0&channel=0数据集的准备:
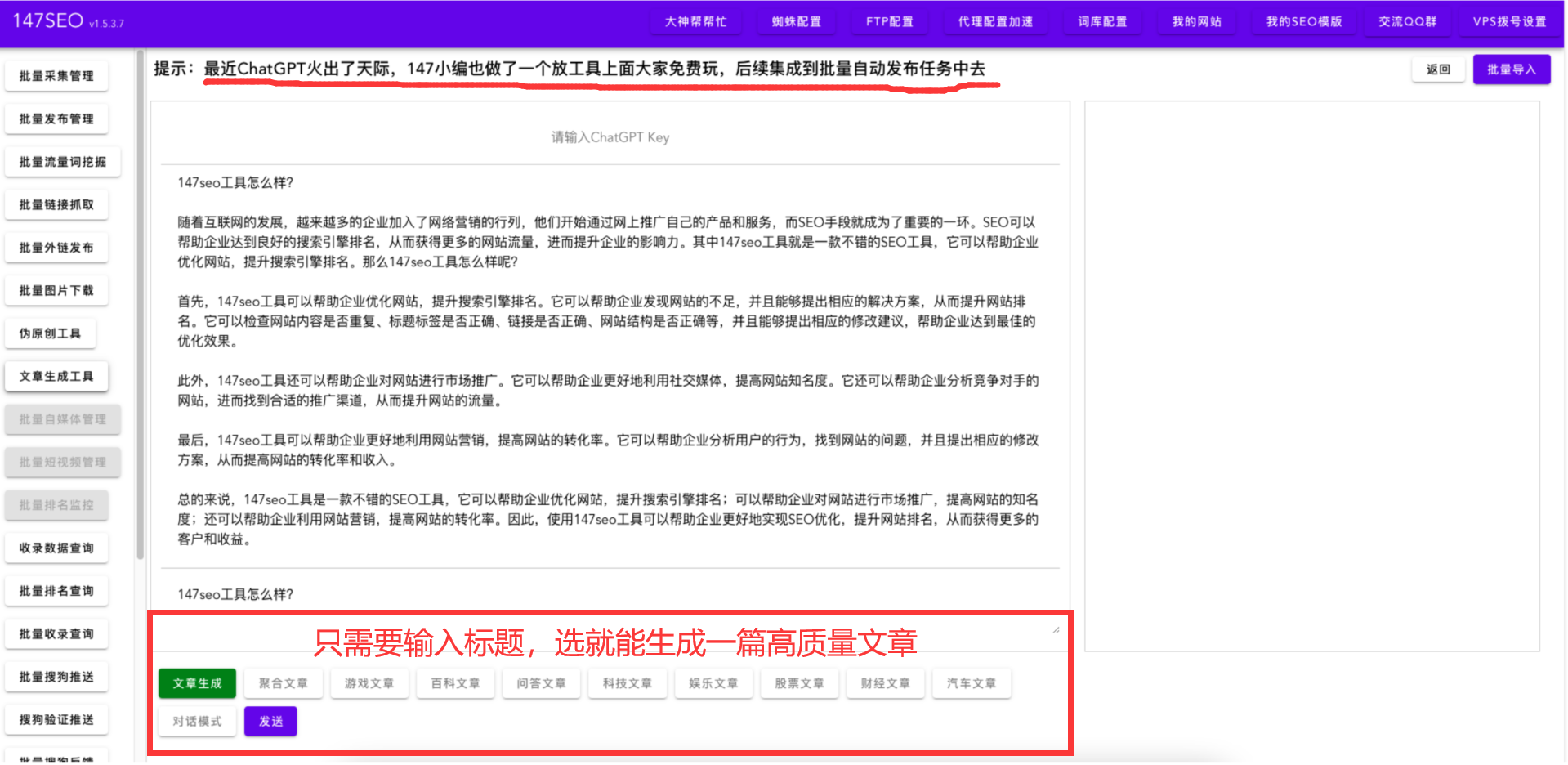
1.数据导入
Label Studio在NER任务中只支持txt文档导入,但是简历都是word文件,所以我们的目的是把多word中的简历内容存入一个txt文件中,每行是一个简历的内容。
首先研究如何解析多个简历文件:
可以使用glob模块来获取指定目录下的所有符合特定条件的文件名,然后在for循环中遍历这些文件,并对每个文件执行相同的解析操作。下面是一个示例代码,可以实现这个功能:
import glob
import os
# 获取指定目录下所有的Word文件名
dir_path = 'path/to/directory'
file_pattern = '*.docx' # 或者是 '*.doc',具体根据您的文件类型来定
file_names = glob.glob(os.path.join(dir_path, file_pattern))
# 循环遍历每个Word文件,执行相同的解析操作
for file_name in file_names:
# 执行解析操作,例如使用python-docx库来读取Word文件
# ...根据这段代码改写内容提取代码:
dir_path = '../ResumeFiles/resume' //存放简历文件的文件夹的相对路径
file_pattern = '*.docx' # 或者是 '*.doc',具体根据您的文件类型来定
file_names = glob.glob(os.path.join(dir_path, file_pattern))
for file_name in file_names:
print("---------------------“简历{}”------------------------".format(file_name))
document = ZipFile(file_name)
xml = document.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
texts = wordObj.findAll("w:t")
paragraphs_text = ""
for text in texts:
# print(text.text)
paragraphs_text += text.text
print(ie(paragraphs_text)) //ie函数的功能是将文本进行信息提取,然后返回提取结果打印结果:
[2023-05-11 17:54:30,441] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'C:\Users\ysy2001 0615\.paddlenlp\taskflow\information_extraction\uie-base'.
---------------------“简历../ResumeFiles/resume\1.docx”------------------------
[{'姓名': [{'text': '张吉惟', 'start': 0, 'end': 3, 'probability': 0.9939343973137511}], '出生日期': [{'text': '1998.11', 'start': 51, 'end': 58, 'probability': 0.9982788171921086}]}]
---------------------“简历../ResumeFiles/resume\2.docx”------------------------
[{'姓名': [{'text': '林国瑞', 'start': 402, 'end': 405, 'probability': 0.9860693449614004}], '出生日期': [{'text': '1990.2.8', 'start': 1101, 'end': 1109, 'probability': 0.9969562203449982}], '电话': [{'text': '138 3108 8888', 'start': 985, 'end': 998, 'probability': 0.40060286240933607}]}]
---------------------“简历../ResumeFiles/resume\3.docx”------------------------
[{'姓名': [{'text': '林玟书', 'start': 0, 'end': 3, 'probability': 0.9931329291108639}], '出生日期': [{'text': '1996.05', 'start': 18, 'end': 25, 'probability': 0.9974436452829565}], '电话': [{'text': '13801138023', 'start': 43, 'end': 54, 'probability': 0.9825973998539936}]}]
---------------------“简历../ResumeFiles/resume\4.docx”------------------------
[{'姓名': [{'text': '林雅南', 'start': 0, 'end': 3, 'probability': 0.9905885262895744}, {'text': '伊淼', 'start': 2026, 'end': 2028, 'probability': 0.8292328175251846}, {'text': '罗嘉良', 'start': 2889, 'end': 2892, 'probability': 0.7978081125050949}, {'text': '罗嘉良', 'start': 3220, 'end': 3223, 'probability': 0.9071803656674007}, {'text': '吕良伟', 'start': 3740, 'end': 3743, 'probability': 0.7161086518860031}, {'text': '罗嘉良', 'start': 3818, 'end': 3821, 'probability': 0.42471927022469913}, {'text': '罗嘉良', 'start': 4134, 'end': 4137, 'probability': 0.303645922465833}, {'text': '吕良伟', 'start': 4056, 'end': 4059, 'probability': 0.9645008868973619}], '出生日期': [{'text': '1996.05', 'start': 41, 'end': 48, 'probability': 0.9984617729245855}], '电话': [{'text': '13801138823', 'start': 51, 'end': 62, 'probability': 0.9902135906254692}]}]
---------------------“简历../ResumeFiles/resume\5.docx”------------------------
[{'姓名': [{'text': '江奕云', 'start': 112, 'end': 115, 'probability': 0.9881768328965066}, {'text': '罗嘉良', 'start': 2947, 'end': 2950, 'probability': 0.7255947350980705}, {'text': '罗嘉良', 'start': 3272, 'end': 3275, 'probability': 0.887640133829251}], '出生日期': [{'text': '1996.05', 'start': 3, 'end': 10, 'probability': 0.9960509002566198}], '电话': [{'text': '13812138123', 'start': 25, 'end': 36, 'probability': 0.9519620354312615}]}]Process finished with exit code 0
上述代码可以实现抽取多文件内容打印输出。
下面将其存入一个txt文件并实现分行:
with open('../ResumeFiles/resume/sample.txt', 'a', encoding='utf-8') as f:
paragraphs_text = paragraphs_text + "\n"
f.write(paragraphs_text)使用Python内置的open()函数创建一个新的文本文件对象sample,并将paragraphs_text中的所有字符串使用'\n'作为分隔符进行连接并写入到sample.txt这个文件中。
然后,使用'a '模式打开这个输出文件,并设置编码格式为utf-8。
注意:
a模式是append,代表追加的意思。 w模式是write,如果设置成w模式,会发生覆盖,最后文件里只有最后一条简历的内容。
需要注意的是,使用with语句打开文件可以确保在文件操作完成后自动关闭文件,从而避免了资源泄漏和其他错误。
小插曲:
在写代码的过程中,误将 paragraphs_text = paragraphs_text + "\n"写成了:
paragraphs_text += paragraphs_text + "\n"结果就是程序不报错,没有任何输出,计算机内存占满,电脑风扇运转声音很大,页面的一些普通操作都会发生卡顿。
强制结束后,报出错误:
Traceback (most recent call last):
File "D:\pycharm\5.4\recognition_model\extraction.py", line 25, in <module>
paragraphs_text += text.text
MemoryError
MemoryError,内存错误。
Python尝试使用的内存超出了系统可用内存的限制。这条语句会将文本内容累加到一个字符串变量paragraphs_text中,在处理大量文本时,这个变量占用了过多的内存。
错误改正之后,运行程序,会在../ResumeFiles/resume下生成一个sample.txt文件:

文件内容:
 已经实现把多文件转换成单txt文件,一行就是一份简历的目的。
已经实现把多文件转换成单txt文件,一行就是一份简历的目的。
2023.5.11
未完待续。。。
![[答疑]事件和其影响的属性的对应是多样的](https://img-blog.csdnimg.cn/img_convert/c442021617b693d2f4a78c88d94f1f41.png)