大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目6-无监督学习之文本聚类分析,将任意文本分类。当今互联网上的数据量越来越大,机器学习技术越来越成熟。在这种情况下,将文本按其主题或者意义进行分类是一项重要任务,这就需要用到文本聚类分析技术。文本聚类分析是指将一组文档(或句子、单词等)根据它们之间的相似性进行分类,形成若干个簇(Cluster)。它是文本挖掘中的重要技术之一,可以用于文本分类、信息检索、智能推荐等领域。
一、聚类原理:相似度计算
余弦相似度:该方法基于向量空间模型,将每个文档表示为一个向量,并计算两个向量之间的余弦值作为它们的相似度。
欧氏距离:该方法采用欧式距离作为度量标准,即计算两个向量之间的距离,距离越近则相似度越高。
曼哈顿距离:该方法也是一种距离度量方法,计算两个向量之间的曼哈顿距离,即两点在坐标系上的横纵坐标距离之和。
皮尔逊相关系数:该方法用于度量两个变量之间的线性相关性,可用于计算文档之间的相似度。
二、聚类方法
基于原型的聚类(Prototype-based Clustering):该方法将每个簇表示为一个原型或代表性对象,并将其他文档分配到与其最相似的簇中。常见的原型包括均值向量、中心点或者某个随机样本。
层次聚类(Hierarchical Clustering):该方法将所有文档看作一个大的簇,然后逐步划分子簇,直到达到停止条件。可以分为自下而上的聚合和自上而下的分裂两种方式。
密度聚类(Density-based Clustering):该方法将簇定义为密度高、密度低的区域,通过寻找局部密度峰值来识别簇。常用的密度聚类算法包括 DBSCAN 和 OPTICS 等。
三、文本预处理
在进行文本聚类前,需要对文本进行预处理,包括分词、去停用词、词干提取等。这些预处理步骤可以减少不必要的噪声和冗余信息,提高聚类效果。
四、实现代码
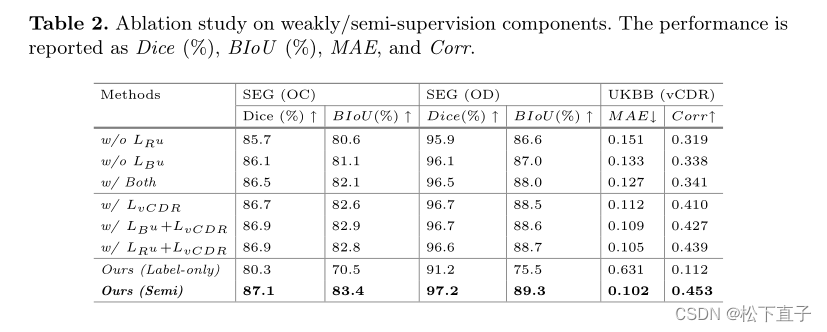
本文采用K-means聚类算法实现文本的聚类分析,数据data.csv样例:
text,label
文本1,类别1
文本2,类别1
文本3,类别1
文本4,类别1
文本5,类别2
文本6,类别2
文本7,类别2
文本8,类别3
文本9,类别3
文本10,类别3
引入KMeans聚类分析模型,导入数据继续训练聚类分析,代码如下:
#coding utf-8
import csv
import jieba
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import os
import re
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 对中文文本进行分词
def tokenize_text(text):
return " ".join(jieba.cut(text))
# 去除标点符号
def remove_punctuation(text):
punctuation = '!"#,。、$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
text = re.sub(r'[{}]+'.format(punctuation), '', text)
return text
# 将分词后的文本转化为tf-idf矩阵
def text_to_tfidf_matrix(texts):
tokenized_texts = [tokenize_text(remove_punctuation(text)) for text in texts]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(tokenized_texts)
return tfidf_matrix
# 聚类函数
def cluster_texts(tfidf_matrix, n_clusters):
kmeans = KMeans(n_clusters=n_clusters)
kmeans.fit(tfidf_matrix)
return kmeans.labels_
# 保存聚类结果到新的CSV文件
def save_clusters_to_csv(filename, texts, labels):
base_filename, ext = os.path.splitext(filename)
output_filename = f"{base_filename}_clusters{ext}"
with open(output_filename, "w", encoding="utf-8", newline="") as csvfile:
csvwriter = csv.writer(csvfile)
for text, label in zip(texts, labels):
csvwriter.writerow([text, label])
return output_filename
# 输出聚类结果
def print_cluster_result(texts, labels):
clusters = {}
for i, label in enumerate(labels):
if label not in clusters:
clusters[label] = []
clusters[label].append(texts[i])
for label, text_list in clusters.items():
print(f"Cluster {label}:")
for text in text_list:
print(f" {text}")
def text_KMeans(filename,n_clusters):
df = pd.read_csv(filename, encoding='utf-8') # 读取csv文件
texts = df['text'].tolist() # 提取文本数据为列表格
print(df.iloc[:, [0, -1]])
# 将文本转化为tf-idf矩阵
tfidf_matrix = text_to_tfidf_matrix(texts)
# 进行聚类
labels = cluster_texts(tfidf_matrix, n_clusters)
clusters = []
for i, label in enumerate(labels):
clusters.append(label)
df['cluster'] = clusters
output = 'data_clustered.csv'
df.to_csv('data_clustered.csv', index=False, encoding='utf-8')
return output,labels,tfidf_matrix
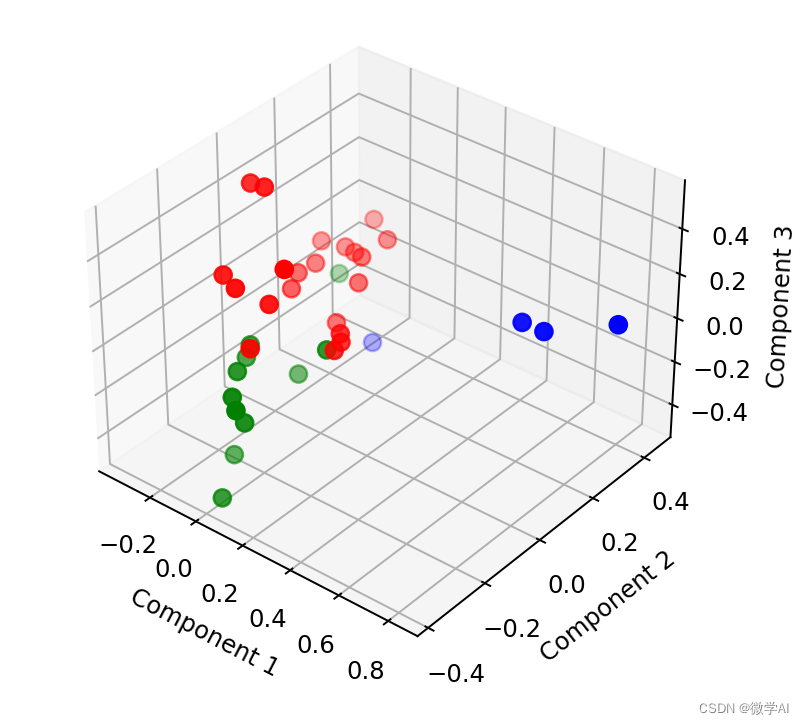
def pca_picture(labels,tfidf_matrix):
# 进行降维操作并将结果保存到DataFrame中
pca = PCA(n_components=3)
result = pca.fit_transform(tfidf_matrix.toarray())
result_df = pd.DataFrame(result, columns=['Component1', 'Component2', 'Component3'])
# 将聚类结果添加到DataFrame中
result_df['cluster'] = labels
# 绘制聚类图形
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
colors = ['red', 'blue', 'green']
for i in range(3):
subset = result_df[result_df['cluster'] == i]
ax.scatter(subset['Component1'], subset['Component2'], subset['Component3'], color=colors[i], s=50)
ax.set_xlabel("Component 1")
ax.set_ylabel("Component 2")
ax.set_zlabel("Component 3")
plt.show()
if __name__ == "__main__":
# 加载中文文本
filename = "data.csv"
n_clusters =3
output,labels,tfidf_matrix = text_KMeans(filename, n_clusters)
pca_picture(labels, tfidf_matrix)运行结果:
运行后可以生成新的文件,并将文本聚类后的标签添上了。