背景:记录一下hive创建数据库,建表,添加数据,创建分区等的语句吧,省得总百度,😄
第一步:hive的建库语句
create database pdata_dynamic;
查看是否创建成功了
show databases;
显示如下,则表示创建成功了
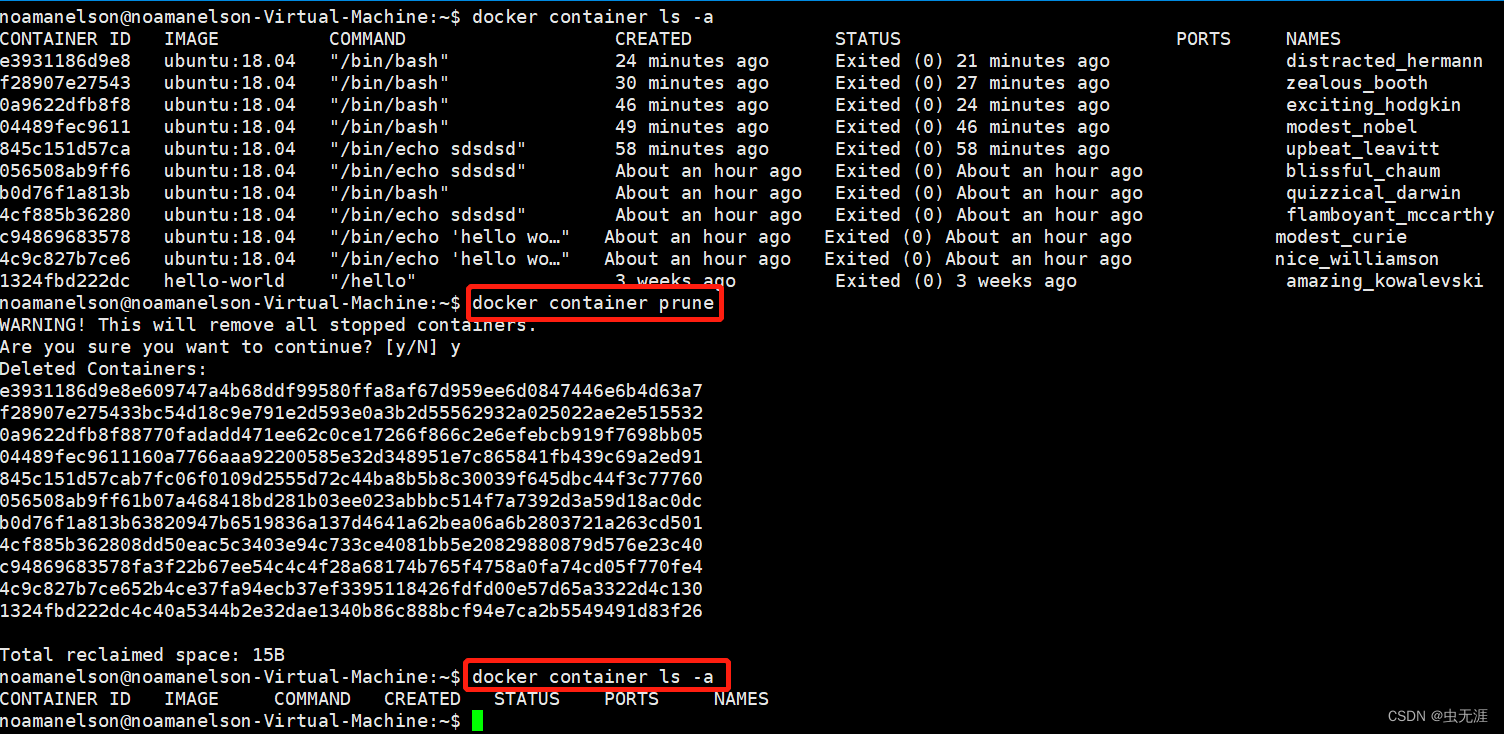
hive> show databases;
OK
default
pdata_dynamic
Time taken: 0.297 seconds, Fetched: 2 row(s)
第二步:hive的建表语句
一、创建内部表
create table student(id int,name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' //以逗号进行分隔
STORED AS TEXTFILE //存储格式为TEXTFILE
LOCATION '/user/hive/warehouse/pdata_dynamic/student'; //数据文件在HDFS上的存储位置
查看建表语句:show create table student;
显示如下;
CREATE TABLE `student`(
`id` int,
`name` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/user/hive/warehouse/pdata_dynamic/student'
引入下一个话题,向表中添加数据,向表中添加数据其实有好几种方式
1> 直接用insert语句
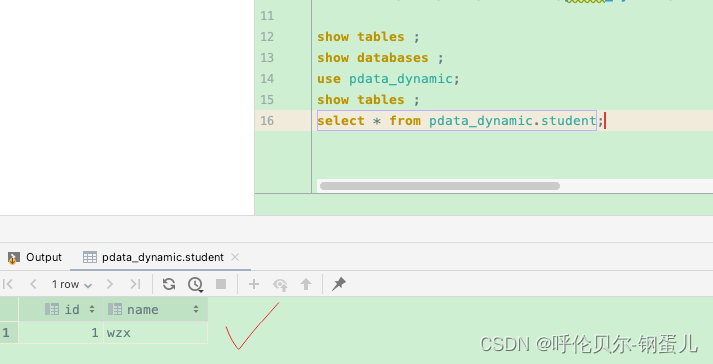
insert into student values ('1','wzx');
然后去数据库中查询,显示如下,则表示添加成功了
2>从其它表中添加
a.使用追加的方式从其他表查询相应数据并插入到Hive表中
注意:1.这里student_bak表可以是多个列的表,抽取一个或者两个字段添加到目标表都可以
2.也可以是多表关联,筛选出来的字段满足student表的字段规则就可以了
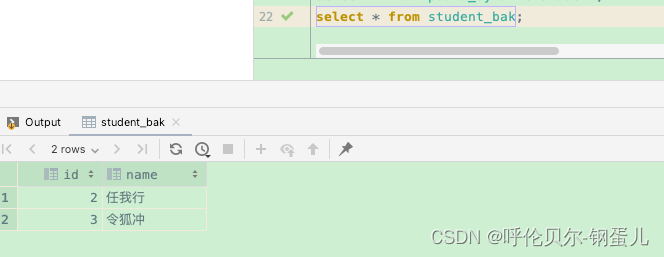
INSERT INTO student SELECT id,name from student_bak;
原表中数据如下;
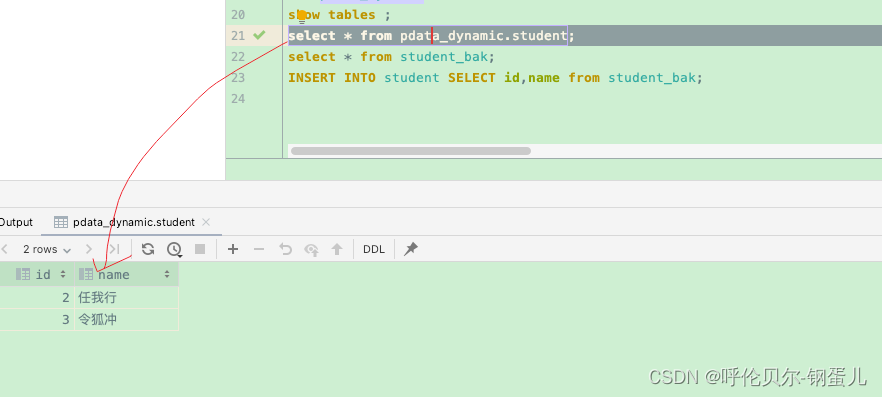
执行完添加语句后,进入到目标表进行查询

b.使用覆盖的方式从student_bak表查询相应数据并插入到student表中
INSERT OVERWRITE table student SELECT id,name from student_bak;
执行完语句后,再去目标表中进行查询,发现已经覆盖成功了
3>在终端下执行load命令加载本地数据
a.追加的方式,加载本地数据到student表中
先造两条数据在本地
cat e.txt
4,任盈盈
5,左冷禅
在终端下执行命令如下;
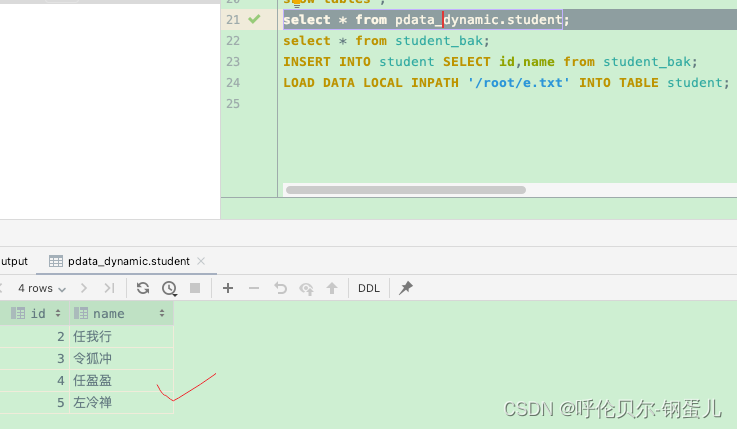
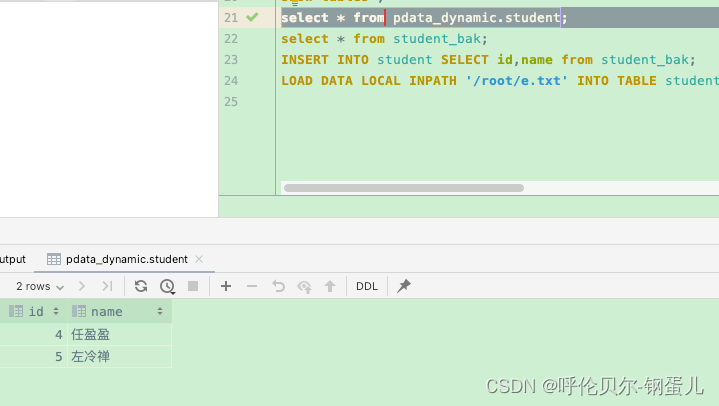
hive> LOAD DATA LOCAL INPATH '/root/e.txt' INTO TABLE student;
Loading data to table pdata_dynamic.student
OK
Time taken: 0.334 seconds
hive>
然后去表中进行查询,已经成功追加进来了
b.覆盖的方式,添加数据到student表中
LOAD DATA LOCAL INPATH '/root/e.txt' OVERWRITE INTO TABLE student;
然后去表中进行查询,已经覆盖成功了
4>加载HDFS上的数据到hive表
a.先把数据文件put到HDFS上,文件路径正好是student表的建表路径
CREATE TABLE `student`(
`id` int,
`name` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/user/hive/warehouse/pdata_dynamic/student';
再造几条数据
cat f.txt
6,东方不败
7,方正大师
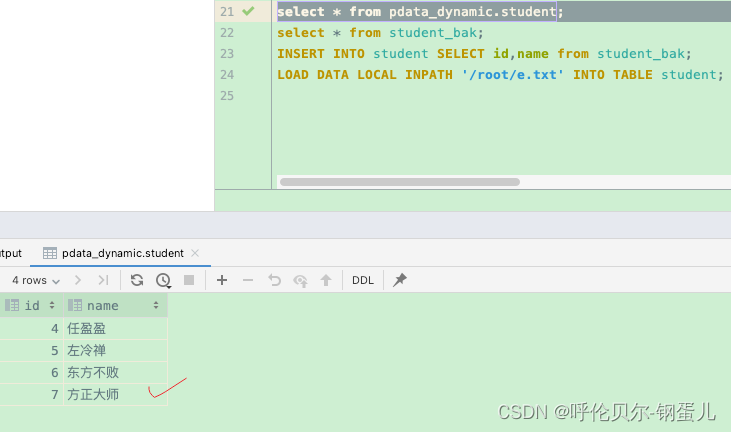
put命令如下;
hadoop fs -put f.txt /user/hive/warehouse/pdata_dynamic/student;
执行完查看student表中的数据,已经成功加载进来了
b.先把数据文件put到HDFS上,文件路径不是student表的建表路径
aa.用load命令来将HDFS上的数据加载到hive表中(追加)
HDFS上新建目录data
hadoop fs -mkdir /data //新建目录命令
再造两条数据如下;
cat g.txt
8,依琳
9,田伯光
将这个数据文件加载到data目录下
hadoop fs -put g.txt /data
查看HDFS上data路径下的文件如下,已经put成功了

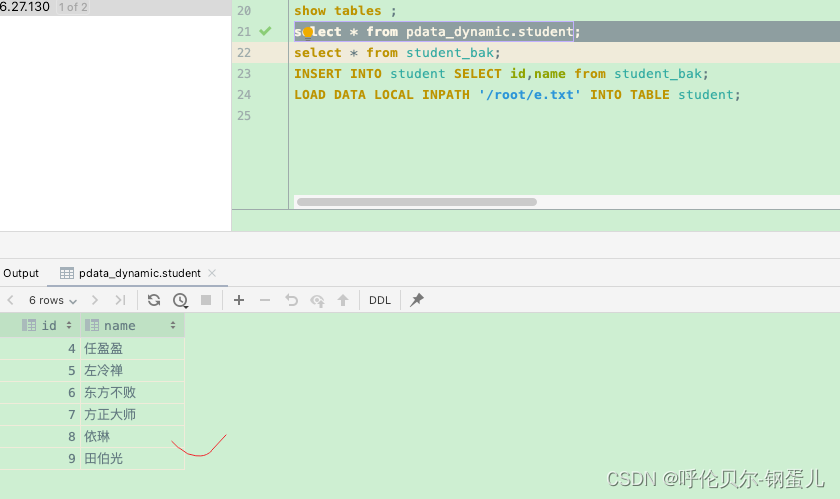
执行加载的命令如下
LOAD DATA INPATH '/data/g.txt' INTO TABLE student;
执行完查看student表中的数据,已经成功加载进来了
bb.用load命令来将HDFS上的数据加载到hive表中(覆盖)
再造两条数据如下
cat h.txt
10,定逸师太
11,岳不群
将这个数据文件加载到data目录下
hadoop fs -put h.txt /data
查看HDFS上data路径下的文件如下,已经put成功了

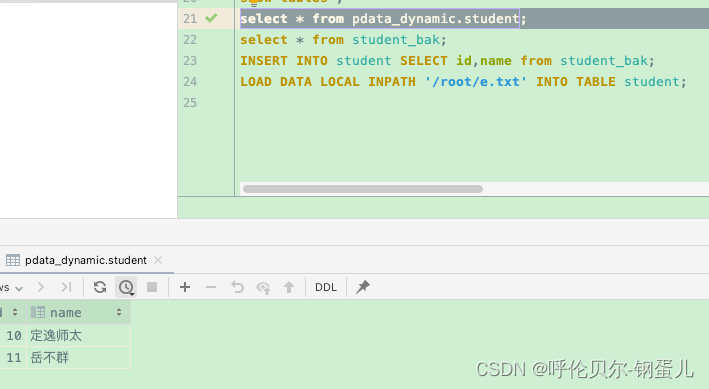
执行加载的命令如下
LOAD DATA INPATH '/data/h.txt' OVERWRITE INTO TABLE student;
执行完查看student表中的数据,已经覆盖成功了
二、创建外部表
说明:EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
create EXTERNAL table student_out(id int,name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/pdata_dynamic/student_out';
三、创建分区表(实际生产中用外部表多一些,中间的临时表用内部表多一些)
首先,区分动态分区和静态分区
创建一个带年,月,日,省份的分区表
create EXTERNAL table gsgl
(car_plate string comment '1',
car_color string comment '2',
in_toll_station string comment '3',
in_date string comment '4',
in_province_code string comment '5',
in_city_code string comment '6',
in_county_code string comment '7',
out_toll_station string comment '8',
out_date string comment '9',
out_province_code string comment '10',
out_city_code string comment '11',
out_county_code string comment '12',
axle_number string comment '13',
total_weight string comment '14',
mileage string comment '15')
PARTITIONED BY (sfdm string comment '省份代码',
year string comment '年',
month string comment '月',
day string comment '日'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/pdata_dynamic/gsgl';
创建分区
alter table gsgl add partition(sfdm='11',year='2021',month='01',day='20210101');
查看分区是否建立
hive> show partitions gsgl;
OK
sfdm=11/year=2021/month=01/day=20210101
Time taken: 0.264 seconds, Fetched: 1 row(s)
向分区表中添加数据(实际工作中不是这么玩的,这里只是做演示)
insert into table gsgl partition(sfdm='11',year='2021',month='01',day='20210101')
values('1','2','3','4','5','6','7','8','9','10','11','12','13','14','15');
去表中进行查询

实际工作中的两种导入数据的方式
采用 insert into的方式
insert into table gsgl
partition(sfdm='11',year='2021',month='01',day='20210101') select xxx,xxx,...... from
gsgl_temp;
采用load的方式
load data local inpath '本地文件路径' into table gsgl partition
(sfdm='11',year='2021',month='01',day='20210101');










![[JAVA数据结构]堆](https://img-blog.csdnimg.cn/d397a5a0e2444038bf048690b33f674c.png)
