从组件团队到Spotify模型
Hi,我是阿昌,今天学习记录的是关于从组件团队到Spotify模型的内容。
团队结构现代化。这个方向跟管理有关,但无论掌控全局的 CTO、架构师,还是身处遗留系统一线战队的队员,都有必要了解现代化团队结构是什么样子的。这是因为遗留系统的现代化,除了技术调整,也离不开人的因素。
在维护遗留系统的团队,结构往往并不合理。直接后果就是给软件开发的质量与速度拖后腿,长远来看,还会让我们的架构规划无法落地,回到满是泥潭的老路上。
一、遗留系统中的团队结构
对照一下所在的开发团队,看看跟后面的情况是否类似。
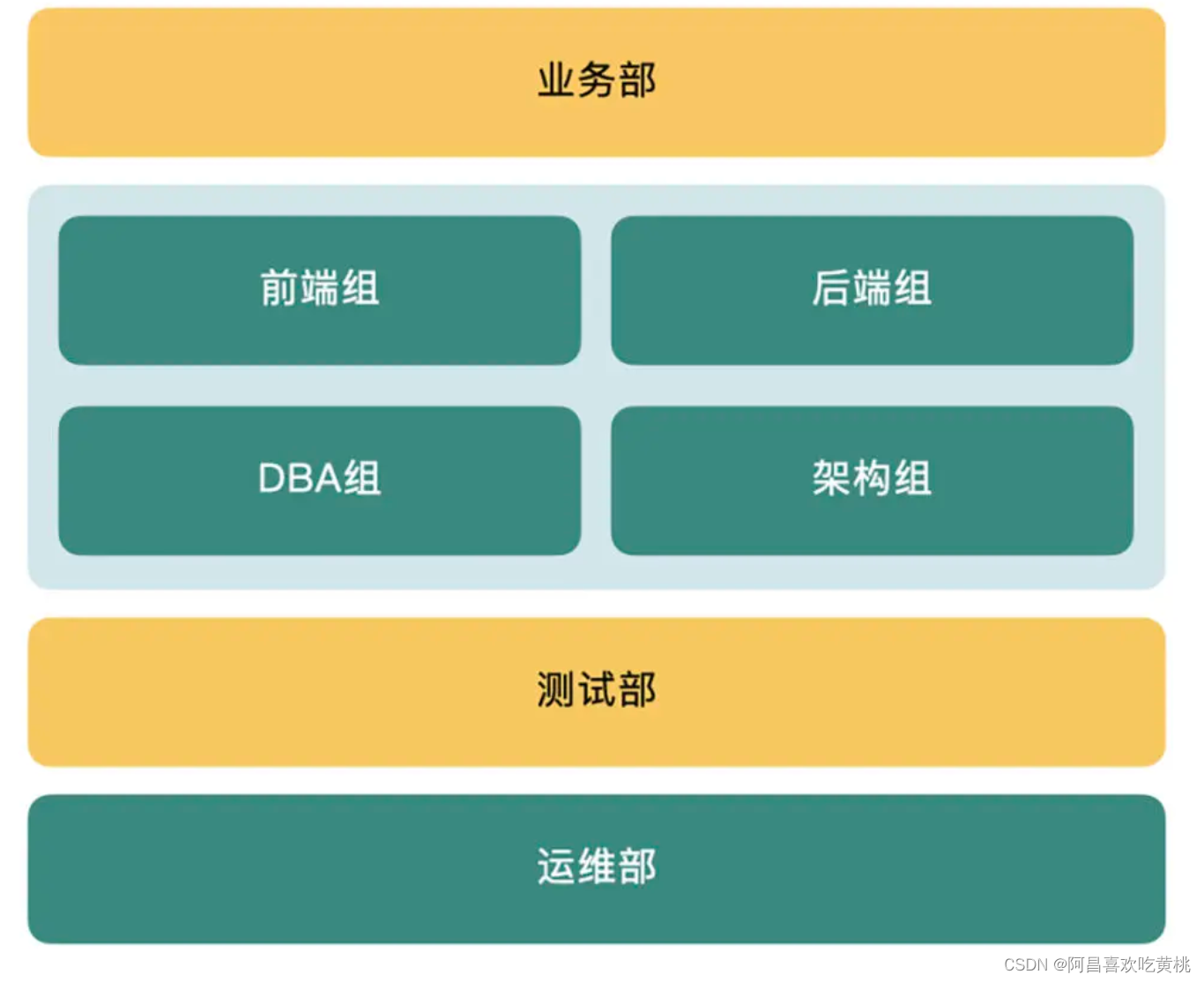
整个研发部门大体分为业务部、开发部、测试部和运维部。
开发部门又可以细分成前端组、后端组、DBA 组和架构组,不同部门或小组分别向不同的领导汇报。
除了这些常规、稳定的配置,还有一些为了灵活应变才组建的部门。
比如本来没有 DBA,但因为某段时间频繁产生数据库性能问题,而临时起意组建了一支 DBA 小组。
开发部内部也经常因为要开发新的项目,从各个组成抽调成员,而当项目完成之后,团队就原地解散。
总之,你会发现每个小组团队人员十分不稳定:有可能某个开发人员上个星期还在开发 A 模块,而这个星期就被分配去开发 B 模块了;
有可能某个测试人员昨天还在测系统 C,而今天则去测以前从来没接触过的系统 D。
这些现象或多或少都见过,甚至都习以为常了。
那这样的团队规划有什么问题吗?当然有。
首先,按照技术或职能(functional)来划分团队或部门,无形中增加了组织壁垒,造成了不必要的沟通成本。因为一个围绕用户构建的需求,必然是跨越多个技术组件的。一个本来完整的端到端的需求,因为团队按技术分组,不得不被分为前端部分、后端部分、数据库部分,一个小需求的联调和验收就要涉及到三个部门、五个不同团队的人。这种不能促进工作的顺利展开,反而使参与者需要付出额外脑力劳动的现象叫什么来着?没错,这就是外在认知负载(可以回看第三节课),是我们一定要降低的。
其次,随意的团队划分看似合理,但仔细琢磨一下,不难发现实际是目的合理,手段存疑。因为目的是解决研发痛点问题(比如前面说的数据库问题),这个目标成立,但组建 DBA 团队这个手段会造成额外的沟通成本,在看似解决了一个问题的同时,又带来了新问题。
第三,频繁地变换团队成员,知识就得不到沉淀,对系统和人都是如此。系统频繁变换维护者,所以没有人对这个系统熟悉,也没有人愿意为它付出更多的努力,因为所有人都知道过不了多久就会离开这个项目;人频繁变换系统,导致团队成员对每个系统都是浅尝辄止,没法深入研究,更不要说偿还技术债了。像测试人员频繁变换所测试的系统这种事情,在拥有独立测试团队的组织中是十分常见的,因为需要为不同的项目调配测试资源。但实际上测试人员应该是最了解系统的那个人,频繁变化系统会使他们丧失这种能力。
二、组件团队
组织壁垒导致沟通成本上升,频繁变换团队造成知识流失,那什么样的组织结构才适合软件开发呢?
为了解决人员频繁变动和知识流失问题,很多组织自发地形成了组件团队(Component Team)我们。
即一个固定的团队负责维护一个组件,在团队内部可以形成关于该组件的知识闭环。
组件团队又分为两种,一种是技术组件团队,一种是业务组件团队。
-
前者按照前端、后端、数据端这样不同的技术来划分,而后者则是按照不同的业务模块来划分。技术组件团队显然无法做到业务知识的沉淀和传递,而且需求又是以业务的形式展示给开发团队的。因此,要完成一个需求,必然涉及到不同技术组件团队之间的频繁沟通。前面提到的遗留系统中的团队结构,大多都是这种技术组件团队。
-
业务组件团队相对来说比较内聚,团队成员包括前后端和 DBA,可以很好地在组内协作,完成一个针对该业务组件的需求。我们后面提到组件团队,都是指这种业务组件团队。因为组件团队是长期存在的,这就可以解决知识沉淀的问题,团队成员也更容易形成默契,减少沟通成本。组件团队也是跨职能的,而不是单一职能。跨职能是指,业务分析人员、前端开发人员、后端开发人员、DBA、架构师和测试人员等不同职能角色都在同一团队中(有些角色可以兼任)。这进一步解决了沟通问题,同时跨职能的人组成的单个团队,不同身份的团队成员之间不再对立,而是共同为该组件负责。如果你的遗留系统还是按照技术组件来划分,建议你推动变革,先想办法让它按业务组件划分。
三、特性团队
不过即使已经按业务组件划分了,遇到一个稍微大一点的需求,也可能横跨多个业务组件,还是会导致多组件团队的沟通协作。
有时候业务分析师会把这样的需求按业务组件拆分,但最终的集成和联调仍然是比较头疼的问题。
为了解决这一问题,Jeff De Luca 等人提出了特性团队(Feature Team)的概念。
特性团队 是指一个长期存在的、跨职能的团队,团队成员一起完成多个端到端的用户特性。
特性团队和组件团队一样,也是长期存在且跨职能的,因此容易形成知识沉淀,也不会出现组织壁垒。
由于一个特性(即需求)会横跨多个业务模块,他们也不像组件团队那样需要横向沟通,自己在组内就能完成这个需求。
通过下面这张图,可以直观对比一下组件团队和特性团队:

可以看到,组件团队虽然只需要维护自己的组件,但对于每一个特性,都需要跨团队沟通;
特性团队虽然每次都要修改多个组件,但却不需要团队之间的沟通和协作。
对于前者,这种沟通带来的成本就是外在认知负载,而对于后者,这种了解多个组件的上下文就是内在认知负载。
外在认知负载要尽量减少,而内在认知负载只需要一次性掌握,就能长期受益。
在实际操作层面,一个特性团队所完成的特性,常常都属于同一个业务领域或模块,这时就接近组件团队了。
他们同时也具备跨越多个组件来完成需求的能力,不需要从业务端进行拆分。
随着时间的推移,特性团队这项实践也被吸收到其他敏捷方法论中,现在也叫全职能团队或跨职能团队,名字虽然不一样,但意思都差不多。如果你的项目还不是特性团队,建议最好想办法先让它按特性来分组。
四、康威定律
如果组件团队和特性团队长期聚焦于某一业务领域,这样的领域演进成一个模块或者独立服务的可能性就会大大提升。
背后其实是康威定律(Conway’s Law)在起作用。
康威定律的意思是,一个组织所设计的软件系统的结构,与组织的沟通结构是完全一致的。
也就是说,如果按技术组件来划分团队边界,完成沟通协作,就会出现 UI 层、业务逻辑层和数据库层这样的技术分层结构。
如果按业务领域划分,那么就会出现按业务来划分的模块或服务,比如订单服务、库存服务、用户中心等。
多年以来,康威定律一直在默默起着作用,如果团队按技术分组,却希望设计一个微服务架构,最终都会走向无尽的深渊。
遗留系统中的那种团队结构,必然会导致大泥球架构。
五、Spotify 模型
特性团队并不是终点,我们继续推演未来可能的发展。
由于特性团队内部是全职能的,时间长了就会越来越自治,关于当前特性或模块的很多架构决策,团队都能自行讨论决定。
特性团队也存在一些问题。当项目越来越大,规模化的特性团队如何组织,就变得十分棘手了;
且特性团队数量变多后,不同团队对相同技术栈的使用规范和最佳实践也会不同,这也给技术管理带来了一定的挑战;
此外,技术人员还是更倾向于聚在一起更有利于个人成长,如果一个特性团队只有一到两名前端开发人员,他们自然会觉得成长受限。
差不多十年前,Spotify 公司推出的Spotify 模型成功支撑了上百人的规模化敏捷团队,受到各大公司的效仿。
简单介绍一下。
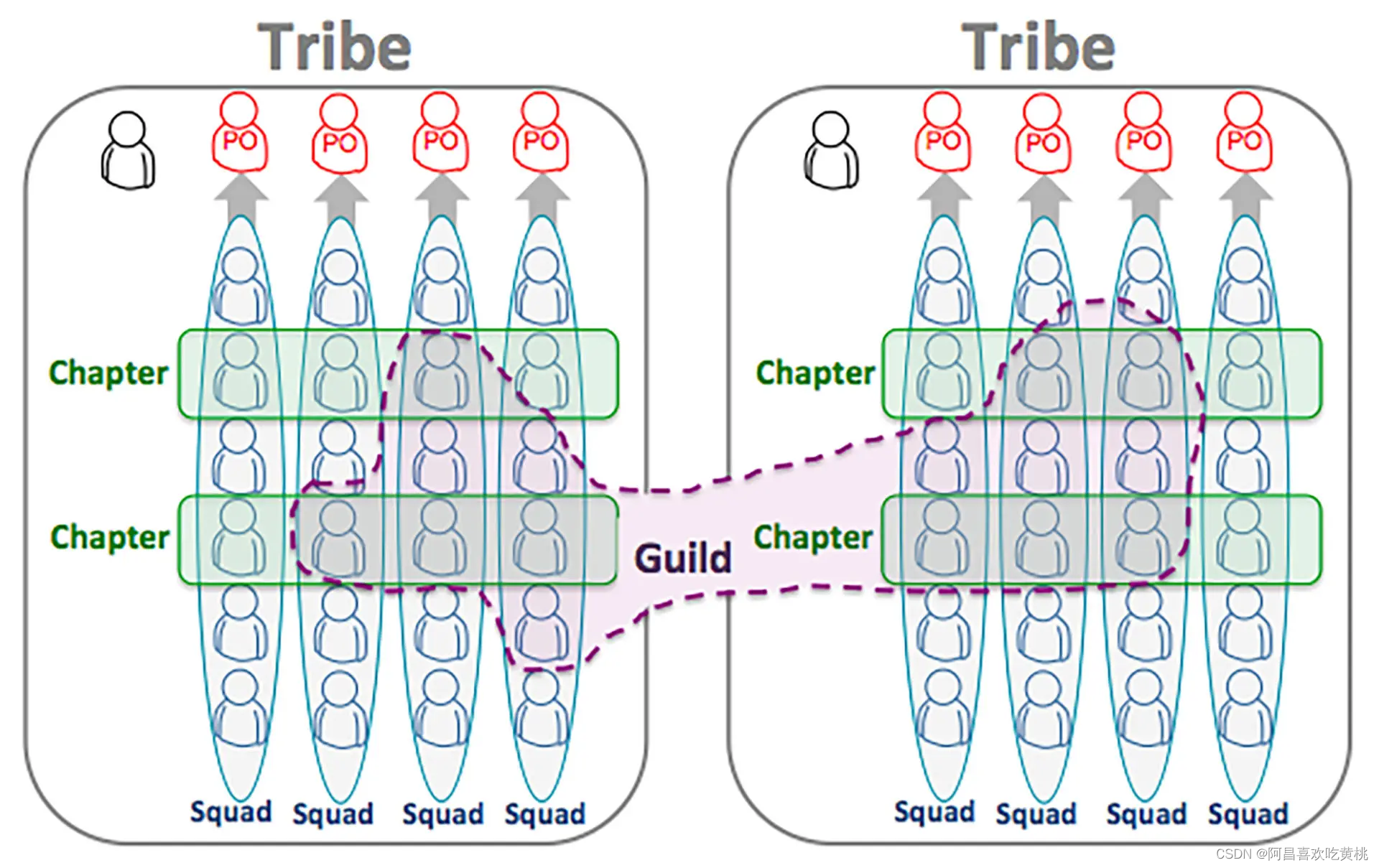
Spotify 模型中的基本开发单元是小队(Squad),它类似于特性团队,也是跨职能、自治的开发小组,由 6~12 人组成。
当小队越来越多时,负责同一个业务模块的小队就组成了一个部落(Tribe),人数通常不超过邓巴数。
部落首领(Tribe Lead)负责协调各个小队以保持一致。虽然小队和部落是自治的,但不同小队和部落之间保持技术的一致性也很重要,这可以在公司内部就某一技术达成规范。这时,专注于不同技术的人可以跨小队来组成分会(Chapter),如测试分会、架构分会、前端分会等。分会成员会定期凑在一起,讨论专业领域的知识和近期遇到的挑战。
除了分会,Spotify 模型中还有一个更松散的组织,即协会(Guild)。它更像是一个兴趣小组,聚集了一些热爱分享的人,可能讨论的内容与当前工作并没有直接关系。分会和协会有助于团队成为一个技术氛围浓厚的学习型组织。
因为有了分会和协会,小队成员在技术上就不会觉得孤立无援了。而且一个优秀的小队成员,既可以在小队内部起作用,也有机会通过分会、协会建立跨团队的影响力。Spotify 模型固然美好,但并不是所有公司都能效仿的,搞不好很可能东施效颦。
最尴尬的是,连 Spotify 都声称他们并没有很好地落地 Spotify 模型。但确实在一个 80 人左右的项目中亲身实践过,当时整个团队分为 8 个小队、3 个部落,还有前端分会、性能分会、架构分会、测试分会、DevOps 分会,以及数据协会、开源协会等自组织的技术社区。
当时整个团队士气高涨、战斗力极强,每个成员既有归属感,也每天都在成长,真是十分美好的旧时光。










![[学习笔记] [机器学习] 4. [下]线性回归(正规方程、梯度下降、岭回归)](https://img-blog.csdnimg.cn/bc773cd7b94f4a9f93a484e5e7c7ce0c.png#pic_center)