最近我在学习一个手写公式识别的网络,这个网络的backbone使用的是DenseNet,我想将其换成ResNet
至于为什么要换呢,因为我还没换过骨干网络,就像单纯拿来练练手,增加我对网络的熟悉程度,至于会不会对模型的性能有所提升,这我不知道。废话不多说,直接开干
这个网络中使用的是DenseNet-100,这里的100是这么来的
100=(16+16+16)2+1(77的卷积)+3(transition layer)
论文中给出的DenseNet代码如下
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from thop import profile
# DenseNet-B
#Bottleneck又称为瓶颈层,因为其长得像一个瓶子,两头大中间细,其主要目的是为了减少计算量
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate, use_dropout):
super(Bottleneck, self).__init__()
interChannels = 4 * growthRate
self.bn1 = nn.BatchNorm2d(interChannels)#对输入的数据进行批量标准化
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1, bias=False)#一层1*1的卷积层,nChannels为输入通道数,interChannels为输出通道数
self.bn2 = nn.BatchNorm2d(growthRate)#归一化
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3, padding=1, bias=False)#一层3*3的卷积层
self.use_dropout = use_dropout#每次训练时随机丢掉一些神经元防止过拟合
self.dropout = nn.Dropout(p=0.2)#20%的神经元被丢弃
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)), inplace=True)#对第一层的卷积进行relu操作
if self.use_dropout:
out = self.dropout(out)#20%不更新
out = F.relu(self.bn2(self.conv2(out)), inplace=True)#对第二层的卷积进行relu操作
if self.use_dropout:
out = self.dropout(out)##20%不更新
out = torch.cat((x, out), 1)#将输入的初始量和经过特征提取的量相加
# print(out.shape)
return out
# single layer 进行了一层3*3的特征提取,并与初始量进行相加
#这段代码没用上-----------------------------------------------------------------------
class SingleLayer(nn.Module):
def __init__(self, nChannels, growthRate, use_dropout):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3, padding=1, bias=False)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
out = self.conv1(F.relu(x, inplace=True))
if self.use_dropout:
out = self.dropout(out)
out = torch.cat((x, out), 1)
return out
# ----------------------------------------------------------------------------------
# transition layer
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels, use_dropout):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nOutChannels)#标准化
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1, bias=False)#1*1卷积,调整维度
self.use_dropout = use_dropout
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)), inplace=True)
# print('relu:')
# print(out.shape)
if self.use_dropout:
out = self.dropout(out)
out = F.avg_pool2d(out, 2, ceil_mode=True)#平局池化,使用2*2的核图像变小一般,奇数进一
# print('pool')
# print(out.shape)
return out
class DenseNet(nn.Module):
def __init__(self, params):
super(DenseNet, self).__init__()
growthRate = params['densenet']['growthRate']#获取字典中densenet-growthRate的值(论文配置为24)
reduction = params['densenet']['reduction']#论文为0.5
bottleneck = params['densenet']['bottleneck']#使用瓶颈层
use_dropout = params['densenet']['use_dropout']#使用正则化
nDenseBlocks = 16
nChannels = 2 * growthRate
self.conv1 = nn.Conv2d(params['encoder']['input_channel'], nChannels, kernel_size=7, padding=3, stride=2, bias=False)#densenet的第一层*7*7的卷积核,输入通道数为1,输出通道数为48
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)#相当于使用了48个7*7的卷积核来学习特征,那么自然有48个通道
nChannels += nDenseBlocks * growthRate#densenet输入通道等于块数乘每个块的输入通道数
nOutChannels = int(math.floor(nChannels * reduction))#输出通道数每次是输入通道数的一半
self.trans1 = Transition(nChannels, nOutChannels, use_dropout)
nChannels = nOutChannels
self.dense2 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)#第二层densenet
nChannels += nDenseBlocks * growthRate
nOutChannels = int(math.floor(nChannels * reduction))
self.trans2 = Transition(nChannels, nOutChannels, use_dropout)
nChannels = nOutChannels
self.dense3 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout):
layers = []
for i in range(int(nDenseBlocks)):#这是一个包含16个块的densenet网络
if bottleneck:#使用的均是瓶颈层
layers.append(Bottleneck(nChannels, growthRate, use_dropout))
else:
layers.append(SingleLayer(nChannels, growthRate, use_dropout))
nChannels += growthRate#输出通道数增加
return nn.Sequential(*layers)#将多个层按顺序连起来
def forward(self, x):
# print('原始')#torch.Size([4, 1, 128, 316])
# print(x.shape)
out = self.conv1(x)#经过一个7*7的卷积核,输出从1通道变为48通道,图片大小减半
# print('经过7*7卷积')#torch.Size([4, 48, 64, 158])
# print(out.shape)
out = F.relu(out, inplace=True)
# print('RELU')#torch.Size([4, 48, 64, 158])
# print(out.shape)
out = F.max_pool2d(out, 2, ceil_mode=True)#维数不变,尺寸减半
# print('池化')#torch.Size([4, 48, 32, 79])
# print(out.shape)
out = self.dense1(out)#维数增加,尺寸减半
# print('dense1层')#torch.Size([4, 432, 32, 79])
# print(out.shape)
out = self.trans1(out)#通道数、feature map均减半
# print('tramns1层')#torch.Size([4, 216, 16, 40])
# print(out.shape)
out = self.dense2(out)
# print('dense2层')#torch.Size([4, 600, 16, 40])
# print(out.shape)
out = self.trans2(out)
# print('tramns2层')#torch.Size([4, 300, 8, 20])
# print(out.shape)
out = self.dense3(out)
# print('dense3层')#torch.Size([4, 684, 8, 20])
# print(out.shape)
return out
这里我就在想将其换成resnet看看效果如何,这里我首先将其换成resnet50
这里更换非常值得一提,更换骨干网络,说简单非常简单,只要把resnet和densenet想象成两个黑盒子,只要输入和输出的维数一样就算更换成功,但是必须对两个网络有一个大致的了解才能进行更换
这里resnet个densenet的输入是相同的(因为就是直接输入图片,不需要进行其他处理),那就需要将输出的维度弄相同即可,这里我将我的代码densenet输入和输出维度打印在终端上,可以看出来,这里这四个维度分别是:[batch_size,通道数,图片宽度,图片高度]

由此可以看出,输入张量经过densenet网络后,通道数从1变为684,图片的宽高变缩小了16倍(向上取整)
那么接下来要做的事情就简单了,我只需将resnet对输入张量的操作也变为通道数从1变为684,图片的宽高变缩小了16倍即可
首先我运行resnet50的代码将张量通过resnet50的输入输出信息打印到终端上,看一下张量进入resnet后维度进行了怎样的变化
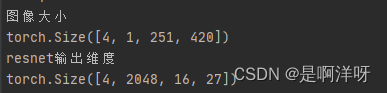
这里发现resnet-50将张量的通道数从1变为2048,图片的宽高变缩小了32倍
那么只需要将通道数从2048变为684,让图片的宽高缩小为16倍即可达到目的
这里我对resnet的代码做了如下修改
1.首先修改输出通道数
我在resnet输出的最后,加入了一个1*1的卷积层,将通道数从2048降到了684
self.layer5 = nn.Conv2d(2048, 684, kernel_size=1, bias=False)
self.mybn1 = nn.BatchNorm2d(684) # 标准化
2.修改特征图宽高
将第二个卷积层的步长从2变为1,这样feature map的宽高就少进行了一次缩小操作,即可将缩小32倍修改为缩小16倍
#self.layer2 = self._make_layer(block, 128, layers[1], stride=2)修改前
self.layer2 = self._make_layer(block, 128, layers[1], stride=1)#修改后
再次运行代码,即可变为将通道数从1变为684,图片的宽高变缩小了16倍的操作了,也就是成功将骨干网络将Densenet换成resnet-50,这里我的的手写公式的代码就可以正常训练了
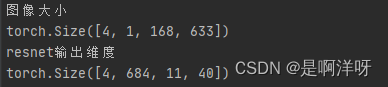
最后给出完整版的修改后的resnet-50的代码
import torch.nn as nn
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
out = self.dropout(out) ##20%不更新
return out
class ResNet50(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet50, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=1)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
self.layer5 = nn.Conv2d(2048, 684, kernel_size=1, bias=False)
self.mybn1 = nn.BatchNorm2d(684) # 标准化
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x= self.layer5(x)
x=self.mybn1(x)
# print('###############')
# print(x.shape)
return x
总结:
更换骨干网络其实挺简单的,说白了就是将两个网络的输入维数和输出维数调成一样的即可,但是想要调成一样的,要求对两个骨干网络的代码和原理都比较熟悉才行,我这里更换骨干网络花了接近2整天才完成,前一天半主要是学习resnet和densnet的代码和原理,最后半天进行代码的修改。