1.灰色关联分析简介
灰色系统这个概念是相对于白色系统和黑色系统而言的。从控制论的知识里,颜色一般代表对于一个系统我们已知信息的多少,白色代表信息量充足,黑色代表我们其中的构造并不清楚的系统,而灰色介于两者之间,即我们对这个系统只了解其中的一部分。
灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度。
在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
灰色系统理论提出了对各子系统进行灰色关联度分析的概念,意图透过一定的方法,去寻求系统中各子系统(或因素)之间的数值关系。因此,灰色关联度分析对于一个系统发展变化态势提供了量化的度量,非常适合动态历程分析。
2.相关应用
2.1 主要作用
- 系统分析。判断影响系统发展历程中,造成某项因素变化的主要因素和次要因素。
- 综合评价分析。利用灰色关联系数,对研究对象或方案进行优劣排序。
2.2 应用场景举例
利用灰色关联分析的特点,我们可以在以下场景中进行应用:
- 复杂系统分析。对一个复杂的系统进行分析,用于判断该系统中元素之间的关联关系;
- 关联性程度探索。对某系统中多个元素与某个主元素的变化趋势进行比较,从而找出对该主元素影响较大的一些因素,以此来优化该系统;
- 多方案选择。在面临多项选择时,可以基于各元素的多个指标进行综合评价分析,基于分析的结果进行优劣排名,从而为方案选择提供依据;
- 改进预测准确率。通过对预测模型进行系统分析,找出影响预测准确率的关键因素,从而改进预测准确率;
- 对数据进行初步探查。灰色关联分析对样本量的多少(至少4个)和样本有无规律要求不大,由此,可以初步对一份不熟悉的数据进行初步研究。
3.灰色关联分析的步骤
3.1 确定分析的目标
在进行灰色关联分析时,我们要首先确定此次分析的目标。可以基于本文2.2中的场景进行参考,然后结合实际情况制定对应的分析目标。
3.2 进行数据预处理
通常在数据分析建模时,我们的数据一般是不符合分析需求的。如有缺失值、含有中文字符、数据格式异常等情况,我们要根据到手的数据情况,对数据进行相应的预处理。
3.3 数据无量纲化
数据无量纲化是通过一个合适的变量来对原有的变量进行替代,从而消除单位或数据分布情况带来的影响,以此来简化计算。无量纲化的方法比较多,如归一化(min-max、平均归一化、非线性归一化、正则归一化)、标准化、中心化等等,在这里选取一些比较常用的处理方法。
假设需要处理的某一个字段数据为x,对其无量纲化后的记为y。那么可以对其可以进行以下操作:
3.3.1 初值化
计算公式如下,用该数据列的每一个元素除以x的第一个元素
y = x x 0 y= \frac{x}{x_0} y=x0x
3.2 均值化
均值化,就是将数据序列中的每一个元素除以平均值,计算公式如下:
y
=
x
x
ˉ
y=\frac{x}{\bar{x}}
y=xˉx
3.3 百分比变化
百分比变化,就是将数据序列中的每一个元素除以元素的最大值,计算公式如下:
y
=
x
m
a
x
(
x
)
y=\frac{x}{max(x)}
y=max(x)x
3.4 倍数变化
倍数变化,就是将数据序列中的每一个元素除以元素的最小值,计算公式如下:
y
=
x
min
(
x
)
y=\frac{x}{\min(x)}
y=min(x)x
3.5 小数定标变化
小数定标变化,是指通过移动小数点的位置。小数点移动的位数取决于原始数据中的最大绝对值。计算公式如下:
x=[-23,10,345,9,-1]
x序列中最大绝对值为345,则每个元素均需要除以1000,进行变化后:
y=[-0.023,0.01,0.345,0.009,-0.001]
3.6 极差最大值变化
极差最大值变化,就是将数据序列中的每一个元素减去序列中的最小值,然后再除以元素的最大值,计算公式如下:
y
=
x
−
m
i
n
(
x
)
max
(
x
)
y=\frac{x-min(x)}{\max(x)}
y=max(x)x−min(x)
3.7 min-max变化
min-max变化,计算公式如下:
y
=
x
−
m
i
n
(
x
)
max
(
x
)
−
m
i
n
(
x
)
y=\frac{x-min(x)}{\max(x)-min(x)}
y=max(x)−min(x)x−min(x)
3.8 平均归一化
平均归一变化,计算公式如下:
y
=
x
−
m
e
a
n
(
x
)
max
(
x
)
−
m
i
n
(
x
)
y=\frac{x-mean(x)}{\max(x)-min(x)}
y=max(x)−min(x)x−mean(x)
3.4 计算灰色关联系数
可以用下面公式,分别计算每个比较序列与 参考序列 对应元素的关联系数 :
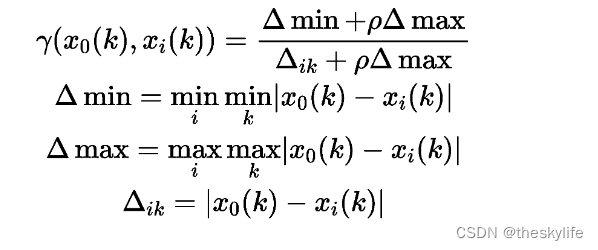
ρ
\rho
ρ的取值范围为0到1,但多数情况下,
ρ
\rho
ρ取0.5较为合适。当
ρ
\rho
ρ分辨系数越小,关联系数间差异越大 ,区分能力越强。
3.5 计算灰色关联度
分别计算其各个指标与参考序列对应元素的关联系数的加权平均值 ,以反映其他序列与参考序列间的关联关系 ,并称其为关联度 ,其计算公式如下:
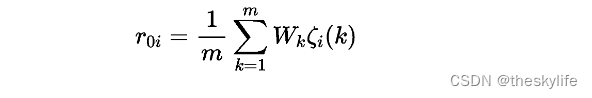
3.6 综合评价
得出灰色关联度的值,根据灰色加权关联度的大小,建立各评价对象的关联序。关联度越大,说明评价对象对评价标准的重要程度越大。
4.案例分享
4.1 关联分析
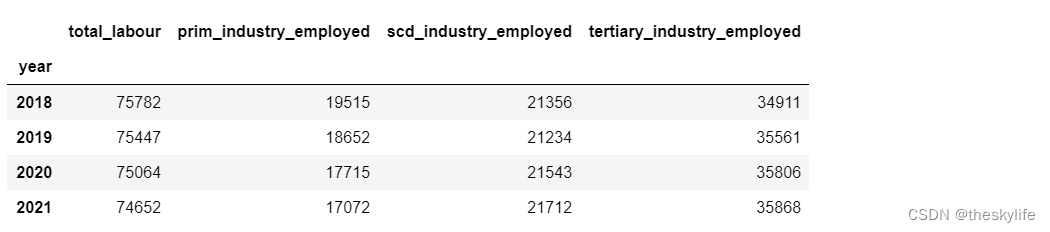
获取2018年至2021年的劳动人口数据,试分析从2018年至2031年哪个产业的劳动人口对于总劳动人口的数量影响最大。
先构建数据如下:
labour = pd.DataFrame([[2018, 75782, 19515, 21356, 34911],
[2019, 75447, 18652, 21234, 35561],
[2020, 75064, 17715, 21543, 35806],
[2021, 74652, 17072, 21712, 35868]], columns=['year', 'total_labour', 'prim_industry_employed', 'scd_industry_employed', 'tertiary_industry_employed'])
labour=data.set_index('year',drop=True)
labour
数据截图:
利用python进行灰色关联分析
def gray_rel(input_df, method='mean', par_seq_index=0, rho=0.5):
'''输入一个df,进行灰色关联分析,输出为df。其中method表示数据无量纲化方法,par_seq_index表示母序列所在的序号位置,rho为对应系数'''
# 1.进行无量纲化
if method == 'mean':
df = input_df/input_df.mean(axis=0)
elif method == 'first':
df = input_df/input_df.iloc[0, :]
elif method == 'max':
df = input_df/input_df.max()
elif method == 'min':
df = input_df/input_df.min()
x = df.drop(input_df.columns[par_seq_index], axis=1)
y = df.iloc[:, par_seq_index]
# 2.求解系数
abs_xik = abs(x.sub(y, axis=0))
a = abs_xik.min().min()
b = abs_xik.max().max()
coef = (a + rho * b) / (abs_xik + rho * b)
coef_m = coef.mean()
result = pd.DataFrame(coef.mean(), columns=[
'w']).sort_values('w', ascending=False)
return result
#调用上述函数,使用默认值
gray_rel(labour)
分析结果如下:
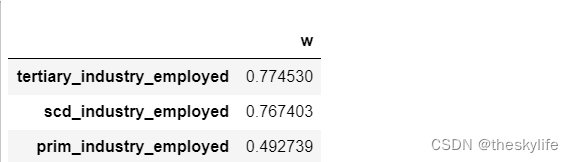
根据以上分析结果可以得出,2018年至2021年对劳动总人口影响较大的是第三产业的劳动人口。
4.2 综合评价分析
假设现在有10家医院,现要根据现有指标对医院进行排名,采用灰色关联进行分析。
4.1 构建数据
#对医院进行综合分析
data=pd.DataFrame({
'医院':['医院1', '医院2', '医院3', '医院4', '医院5', '医院6', '医院7', '医院8', '医院9', '医院10'],
'门诊人数':[368107, 215654, 344914, 284220, 216042, 339841, 225785, 337457, 282917, 303455],
'病床使用率%':[99.646, 101.961, 90.353, 80.39, 91.114, 98.766, 95.227, 88.157, 99.709, 101.392],
'病死率%':[1.512, 1.574, 1.556, 1.739, 1.37, 1.205, 1.947, 1.848, 1.141, 1.308],
'确诊符合率%':[99.108, 98.009, 99.226, 99.55, 99.411, 99.315, 99.397, 99.044, 98.889, 98.715],
'平均住院日':[11.709, 11.24, 10.362, 12, 10.437, 10.929, 10.521, 11.363, 11.629, 11.328],
'抢救成功率%':[86.657, 81.575, 79.79, 80.872, 76.024, 88.672, 87.369, 75.77, 78.589, 83.072]
})
data.set_index("医院",inplace=True)
r_n,c_n=data.shape
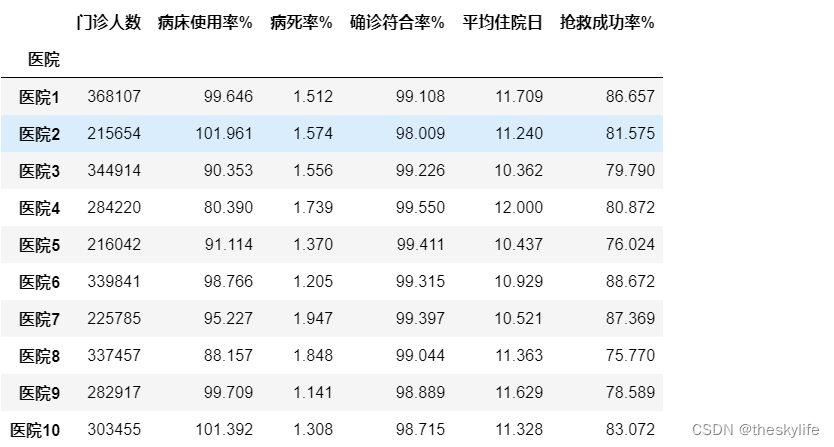
data
数据截图如下:
4.2 进行数据归一化
对数据进行归一化处理
def min_max_deal(data,method='p',feature_range=(0, 1)):
'''min-max归一化,data为需要进行处理的dataframe;如果method为p则为正向,为n则为逆向;设置归一化后的最小最大值'''
y_min,y_max=feature_range
arr=[]
for col in data.columns:
#进行归一化处理
c_max=data[col].max()
c_min=data[col].min()
if method == 'n':
s=(y_max-y_min)*(c_max-data[col])/(c_max-c_min)+y_min
elif method=='p':
s=(y_max-y_min)*(data[col]-c_min)/(c_max-c_min)+y_min
s=s.values
arr.append(s)
result=np.stack(arr).T
result=pd.DataFrame(result,columns=data.columns)
return result
#正向指标标准化
p_cols=['门诊人数','病床使用率%','确诊符合率%','抢救成功率%']
p_df=min_max_deal(data[p_cols],'p',(0.002,1))
#负向指标标准化
n_cols=['病死率%','平均住院日']
n_df=min_max_deal(data[n_cols],'n',(0.002,1))
#进行数据合并,并将顺序与原来保持一致
normal_df=p_df.join(n_df)
normal_df=normal_df[data.columns]
normal_df.index=data.index
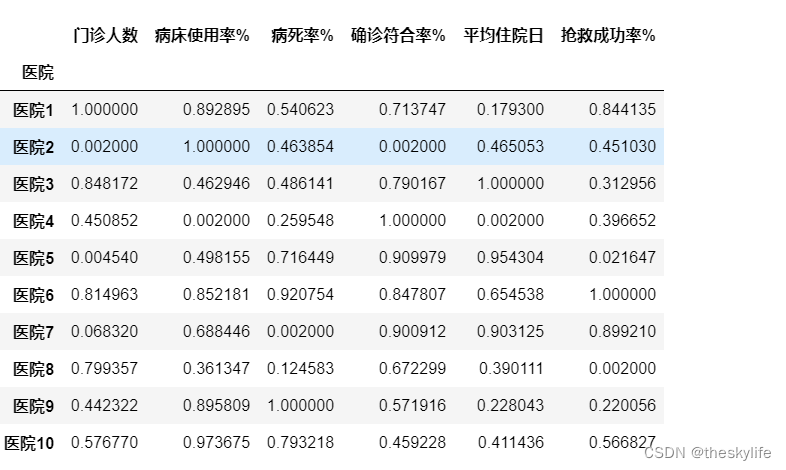
normal_df
归一化后,结果如下:
4.3 计算得分
利用灰色关联分析求出得分
def gray_weight(input_df, rho=0.5):
'''输入一个df,进行灰色关联分析,输出为df。其中method表示数据无量纲化方法,par_seq_index表示母序列所在的序号位置,rho为对应系数'''
x = input_df
# 获取每行的最大值作为母序列,以此为基准
y = input_df.max(axis=1)
# 2.求解系数
abs_xik = abs(x.sub(y, axis=0))
a = abs_xik.min().min()
b = abs_xik.max().max()
coef = (a + rho * b) / (abs_xik + rho * b)
coef_m = coef.mean()
# 3.求权重
weight=pd.DataFrame(coef_m,columns=['r'])
#求出最后的权重
weight['w']=weight['r']/weight['r'].sum()
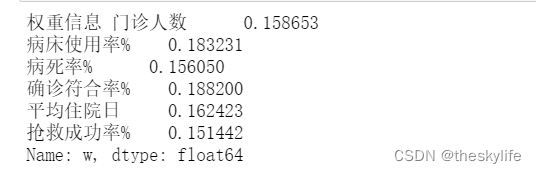
print("权重信息",weight['w'])
#4.计算得分
s=np.dot(input_df.values,weight['w'].values)
score=s*100/max(s)
result=pd.DataFrame(score.T,columns=['score'])
result.index=input_df.index
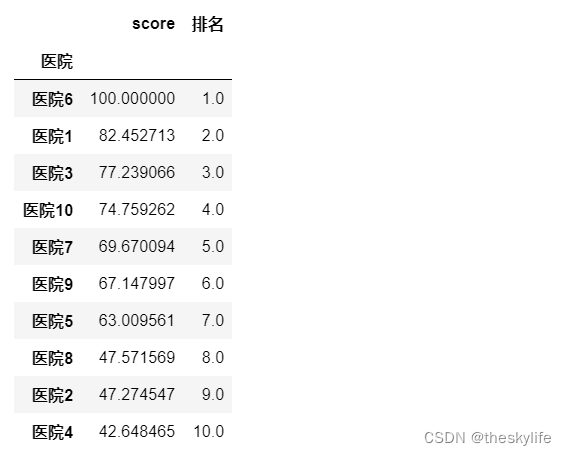
result['排名']=result['score'].rank(ascending=False)
result=result.sort_values('score',ascending=False)
return result
#调用函数求结果
out_df=gray_weight(normal_df)
out_df
运行上述代码后,结果如下: