pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
一.pandas模块的安装
使用pip接口进行安装
pip install pandaspip接口详细说明可以看:【python】之pip,Python 包管理工具详解!_pip 包管理_彭彭能呀的博客-CSDN博客
二、使用步骤
pandas的数据结构:
(1)Series:类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型,由索引(index)和列组成。
(2)DataFrame:是一个表格型的数据结构,每列可以是不同的值类型(数值,字符串,布尔型值),DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典。
1.先来看看Series:
import pandas as pd ###导入pandas模块
pd.series(data,index,dtype,name,copy)参数说明:
data:一组数据(ndarray类型)
index:数据索引标签,如果不指定,默认从0开始
dtype:数据类型,默认会自己判断
name:设置名称
copy:拷贝数据,默认伟False
(1)获取一列数据
import pandas as pd
x = [3,4,5,6,7,8,9]
pd.Series(x)输出:
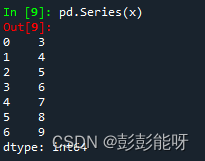
从0开始排列,dtype类型为int64。
(2)设置索引
import pandas as pd
x = [3,4,5,6]
pd.Series(x,index=['a','b','c','d'])输出如下:
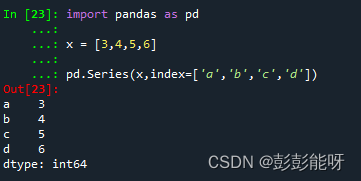
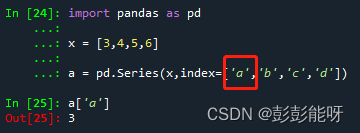
如上图1,设置索引对应列表数据,如图2直接获取a的值。
2. 接下来了解下DataFrame类型:
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)
index:数据索引标签,如果不指定,默认从0开始
columns:列索引
dtype:数据类型,默认会自己判断
copy:拷贝数据,默认伟False
(1).获取一组数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)输出:
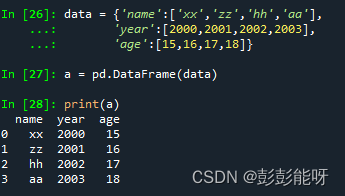
输出表格型的数据结构。
(2).设置行、列索引
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
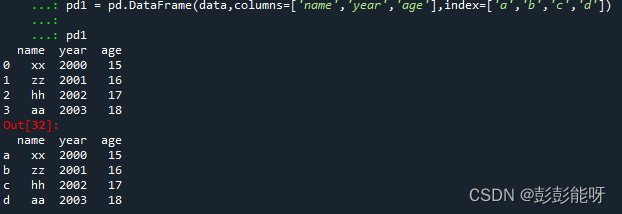
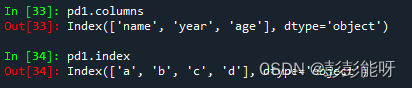
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1输出:
(3). 获取指定列信息
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
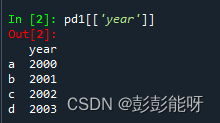
pd1[['year']]输出:
(4).切片行数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[:2]输出: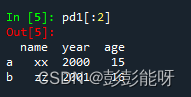
(5).条件筛选,获取满足条件的行数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[pd1['age']>15]输出:
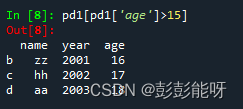
筛选出年龄大于15的同学
(6).先筛选行,在筛选列
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[:2][['name','year']]输出:

(7).删除指定行
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
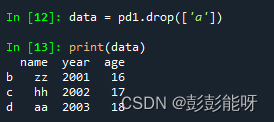
data = pd1.drop(['a'])
print(data)输出:
3.pandas文件读取和储存
pandas支持的常用文件类型包括:HDF5,CSV,SQL,XLS,JSON等
(1)读取CSV文件数据
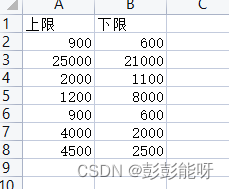
import pandas as pd
data = pd.read_csv(r"....\test.csv",encoding='gbk')
print(data)输出:
(2)读取指定列数据
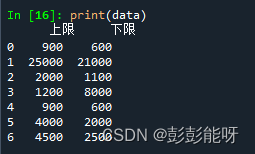
import pandas as pd
data = pd.read_csv(r"...\test.csv",usecols=['下限'],encoding='gbk')
print(data)输出:
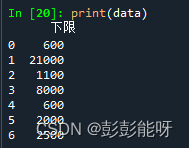
先写这么多....
@Neng



![[医学分割比赛] ISBI2023 APIS多模态医学分割比赛总结 + top3解决方案](https://img-blog.csdnimg.cn/6ace3d9f5eaa49bd8bda61be56bf443e.png)