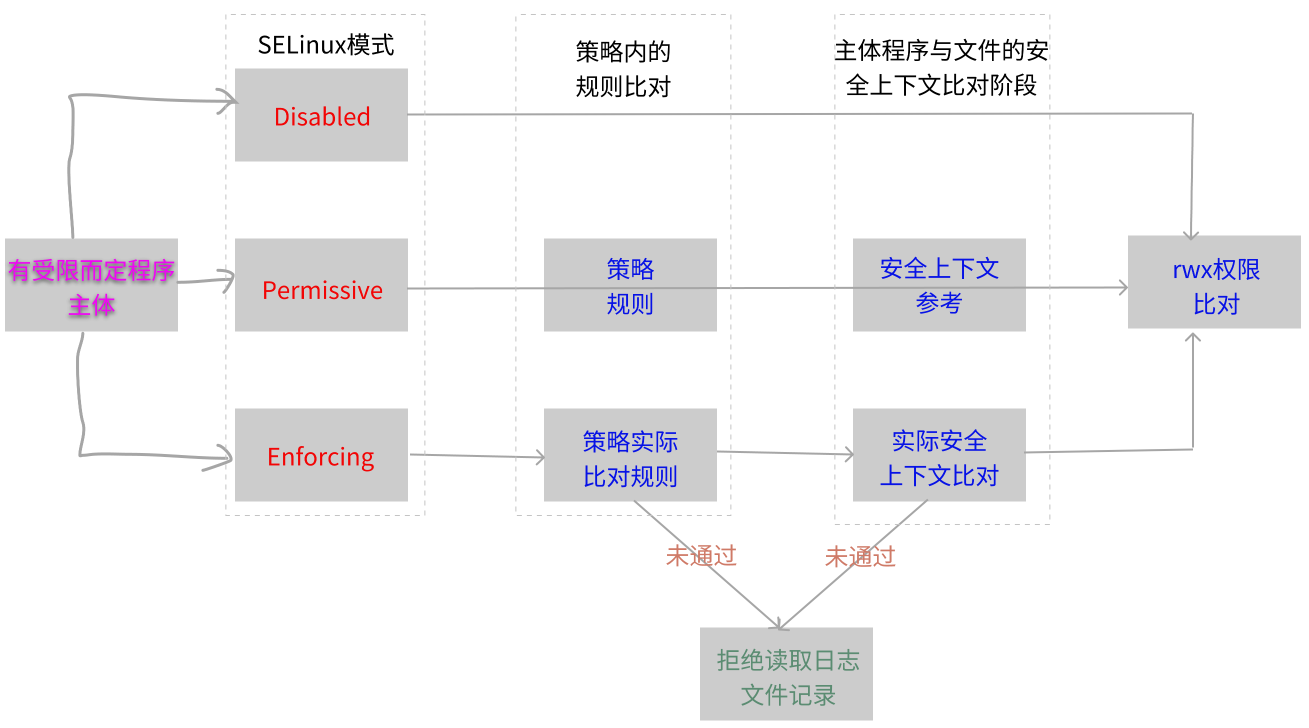
Amazon DynamoDB简介
Amazon DynamoDB是由Amazon Web Services(AWS)提供的一种快速、灵活、全托管的NoSQL数据库服务,支持文档和键/值数据模型。它具有自动扩展、低延迟、高可靠性、高吞吐量等特点,能够处理从几个字节到几TB的数据,同时还具备强大的安全和监控功能。关键是有Amazon账号就可以有免费的套餐可以使用,貌似试用期有12个月,所以今天我们来白嫖一下这个免费的产品。
DynamoDB的优势
- 快速响应:DynamoDB支持读写操作的低延迟,读取操作的平均响应时间可以在几毫秒内完成。
- 强大的可扩展性:DynamoDB是一种可水平扩展的数据库,可以根据需要自动增加或减少容量,从而满足不同的负载需求。
- 简单易用:DynamoDB使用简单的API和数据模型,易于使用和学习。
- 高可用性:DynamoDB提供了多种数据备份和复原功能,使其在遇到任何故障或灾难时都能够快速恢复。
- 灵活性:DynamoDB支持多种数据类型和数据模型,并支持多种查询和索引方式。
- 支持多种数据访问方式:DynamoDB支持RESTful API、SDK、CLI等多种访问方式。
适用场景
DynamoDB主要适用于OLTP(联机事务处理)场景,更适合处理具有以下特点的应用程序:
- 数据集比较小(每个项目小于1MB)
- 需要频繁的读写操作
- 需要高可用性和低延迟的响应
- 需要可伸缩性和弹性
免费额度
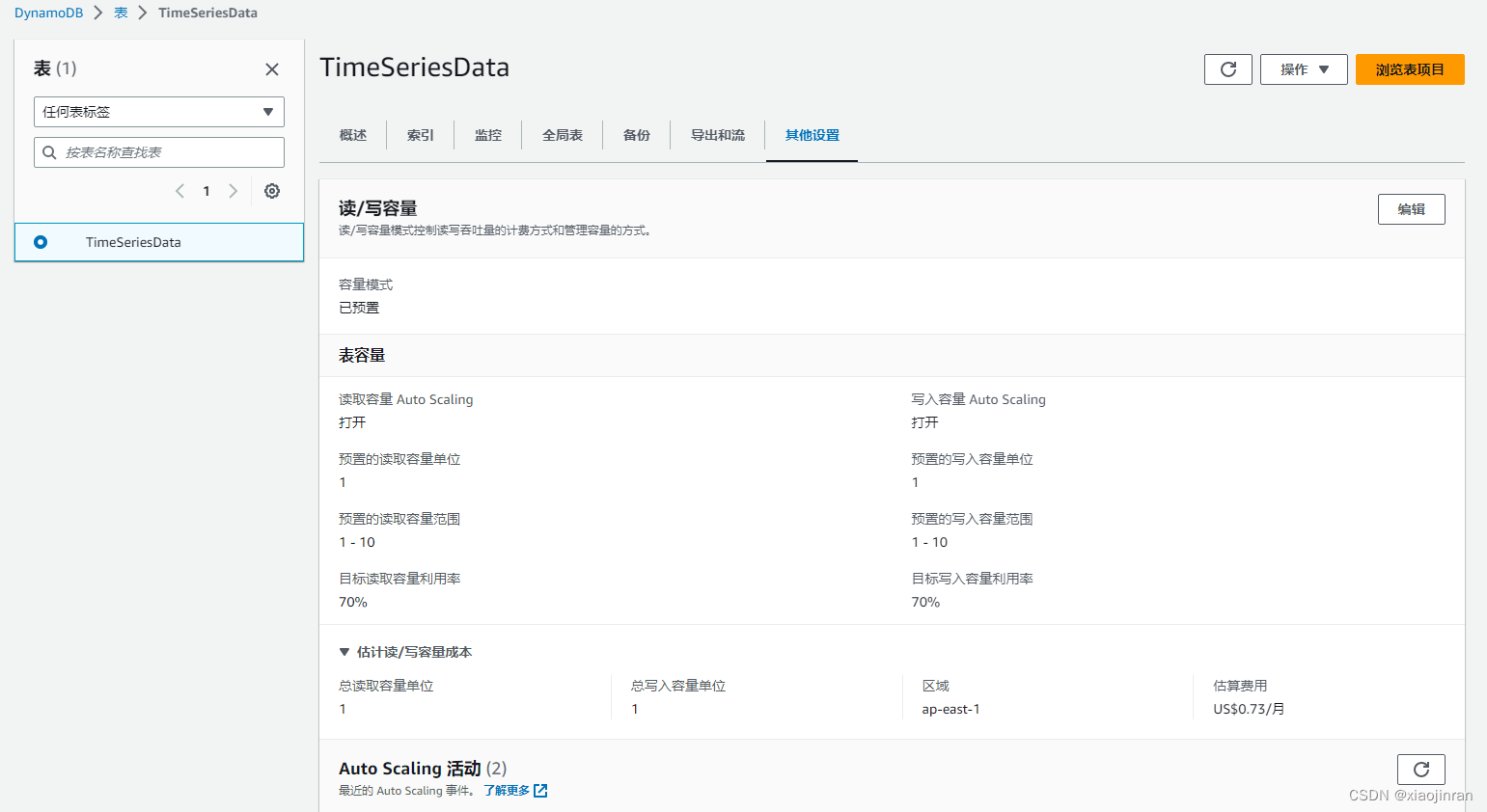
DynamoDB 的免费套餐提供 25GB 的存储空间,以及 25 个预置的写入容量单位和 25 个预置的读取容量单位 (WCU、RCU),足以处理每月 2 亿个请求
写入和读取容量单位可以通过表的其他设置选项卡中进行查看,注意不要超过免费额度,不然会产生费用。
我们这里从一个表的创建、数据的C(增加)R(查询)U(更新)D(删除)来演示DynamoDB的入门使用。
创建表
为了简单,这里直接采用控制台的方式进行创建,当然也可以用Amazon提供的SDK等方式,进入DynameDB的控制台页面,点击创建表,按照页面提示输入信息即可。
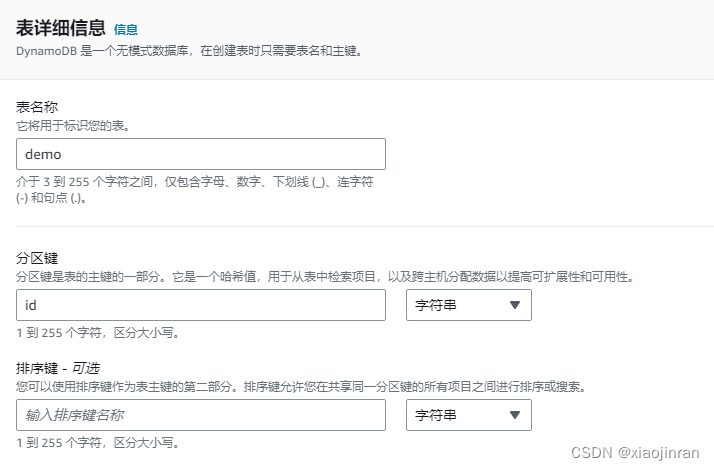
输入表的名称,因为DynamoDB是一个无模式数据库,在创建表时只需要表名和主键即可,主键代表数据的唯一性,记住这两个配置项目,后面的程序代码中需要使用到。其他的配置暂时按照默认推荐的参数即可。
增加数据
增加数据,控制台页面也提供了增加的操作,但在实际应用中,一般都是由应用产生,并推送到数据库进行数据的存储,所以这里使用python,演示如何连接到DynamoDB,并且增加数据项。
import boto3
# 指定AWS访问密钥和凭证
ACCESS_KEY = 'your-access-key'
SECRET_KEY = 'your-secret-key'
REGION = 'ap-east-1'
# 创建DynamoDB客户端
dynamodb = boto3.resource('dynamodb',region_name=REGION,aws_access_key_id=ACCESS_KEY,aws_secret_access_key=SECRET_KEY)
这里需要提供Amazon的访问秘钥凭证和地区,通过boto3.resource,来创建一个DynamoDB客户端,注意需要安装boto3库。可以通过pip install boto3进行安装
# 获取DynamoDB表
table = dynamodb.Table('demo')
# 将文本内容插入到DynamoDB表中
table.put_item(
Item={
'id': '1',
'text': "HelloWorld"
}
)
这里的demo就是我们的一开始创建的表名,Item里面的id就是我们的主键,因为是无模式的数据库,后面的字段内容想如何增加就增加,支持字符串、整型、数组等常见的编程语言基本类型。
运行之后,成功的会返回http信息,格式为json,示例如下:
{'ResponseMetadata': {'RequestId': 'K02UHKKO2KQ9R2LV0T201OBDGBVV4KQNSO5AEMVJF66Q9ASUAAJG',
'HTTPStatusCode': 200,
'HTTPHeaders': {'server': 'Server',
'date': 'Wed, 10 May 2023 07:38:15 GMT',
'content-type': 'application/x-amz-json-1.0',
'content-length': '2',
'connection': 'keep-alive',
'x-amzn-requestid': 'K02UHKKO2KQ9R2LV0T201OBDGBVV4KQNSO5AEMVJF66Q9ASUAAJG',
'x-amz-crc32': '2745614147'},
'RetryAttempts': 0}}
查询数据
查询数据支持整表扫描,加条件,支持结果分页,这里以整表扫描为例
table = dynamodb.Table('demo')
response = table.scan()
items = response['Items']
print(items)
查询结果如下:
[{'id': '1', 'text': 'HelloWorld'}]
可以看到数据已经插入到Dynamodb中了。
这个例子使用了 scan 方法来查询整个表,因为没有指定查询条件。在 DynamoDB 中,scan 方法可以用来查询整个表或者一个表中的部分数据。需要注意的是,scan 方法会扫描整个表,可能会比较慢,而且可能会消耗较多的读取容量单位(RCUs)和查询容量单位(WCUs),因此需要谨慎使用。如果你的表中有很多数据,最好使用查询条件来缩小查询范围。
更新数据
# 定义要更新的项的主键
key = {'id': '1'}
# 更新数组,追加一个新的整数
table.update_item(
Key=key,
UpdateExpression='SET #attrName = :attrValue',
ExpressionAttributeNames={'#attrName': 'text'},
ExpressionAttributeValues={':attrValue': 'HelloWorld updated!'}
)
更新成功后,同样也会返回http信息,格式为json。
{'ResponseMetadata': {'RequestId': 'FG893L8TT0CNB6JFEIMS85K2INVV4KQNSO5AEMVJF66Q9ASUAAJG',
'HTTPStatusCode': 200,
'HTTPHeaders': {'server': 'Server',
'date': 'Wed, 10 May 2023 07:47:26 GMT',
'content-type': 'application/x-amz-json-1.0',
'content-length': '2',
'connection': 'keep-alive',
'x-amzn-requestid': 'FG893L8TT0CNB6JFEIMS85K2INVV4KQNSO5AEMVJF66Q9ASUAAJG',
'x-amz-crc32': '2745614147'},
'RetryAttempts': 0}}
删除数据
删除数据可以使用delete_item方法,将主键传进去即可。
# 定义需要删除的数据的主键
item_key = {'id': '1'}
# 删除数据
response = table.delete_item(Key=item_key)
同样也会返回http信息,格式为json。
{'ResponseMetadata': {'RequestId': 'URK27CJH123CVJSP970M635AAFVV4KQNSO5AEMVJF66Q9ASUAAJG',
'HTTPStatusCode': 200,
'HTTPHeaders': {'server': 'Server',
'date': 'Wed, 10 May 2023 08:02:11 GMT',
'content-type': 'application/x-amz-json-1.0',
'content-length': '2',
'connection': 'keep-alive',
'x-amzn-requestid': 'URK27CJH123CVJSP970M635AAFVV4KQNSO5AEMVJF66Q9ASUAAJG',
'x-amz-crc32': '2745614147'},
'RetryAttempts': 0}}
总结
以上演示了对DynamoDB的入门基本使用,由于是Amazon的免费试用的产品,就闲下来研究了下,还没有进行过线上产品的实战,请有需要的小伙伴可以进行尝试,可以用来自有博客数据的存储,物联网采集数据存储场景,相信是一个非常不错的NoSQL数据库的替代。
我这里有一个分享的notebook文件,有需要的测试验证的,可以用我的notebook进行线上测试体验。
https://colab.research.google.com/drive/1Bk5Jj8DZqQJ2i5X2bUbuM5qJOLLx6-df?usp=sharing










![[Java基础练习-002]综合应用(基础进阶),如果你会做,那说明你java入门了,](https://img-blog.csdnimg.cn/ea68ec2aa1874ef3b06fdc00d81c5960.png)