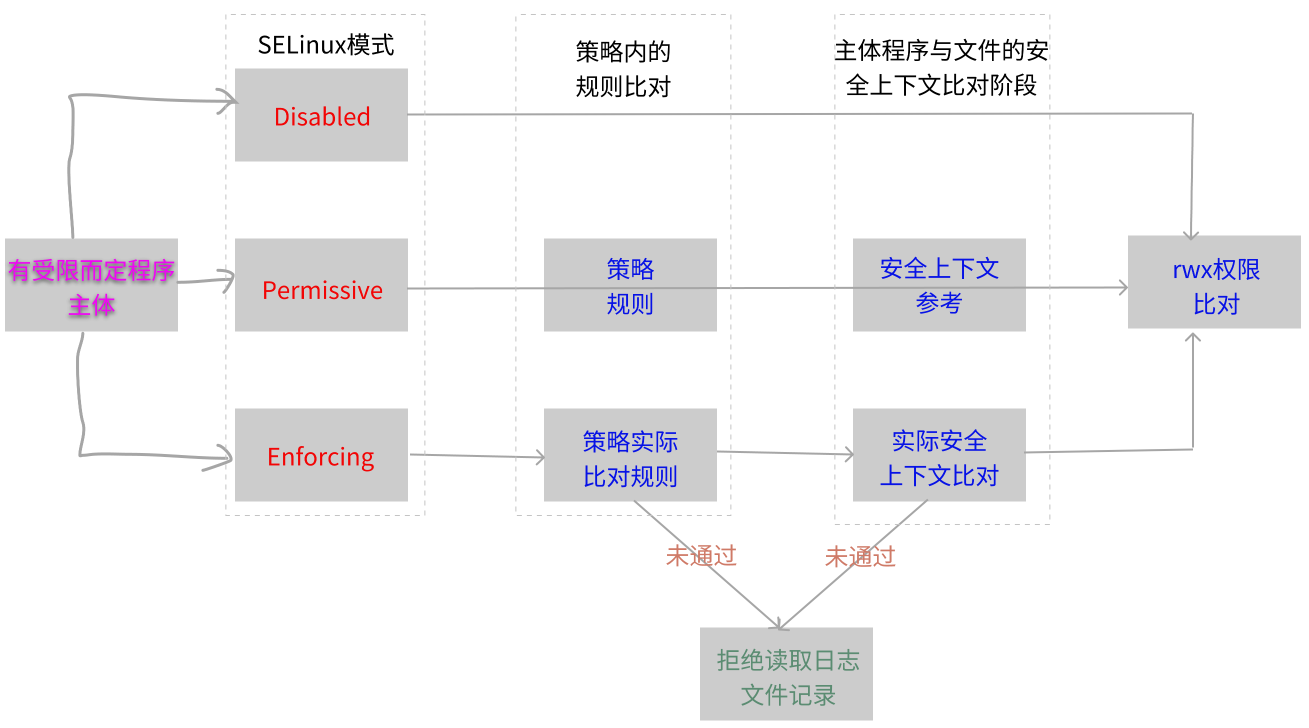
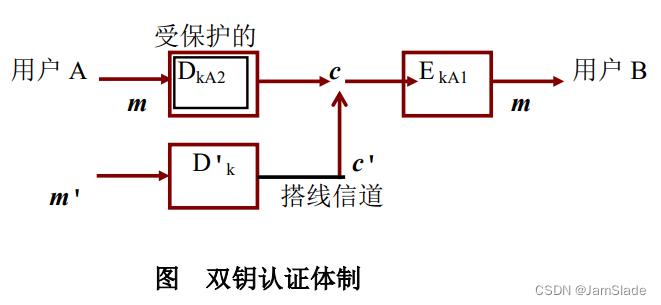
Volume Rendering of Neural Implicit Surfaces(VolSDF):神经隐式曲面的体渲染
摘要:一个神经隐式表面体积渲染框架,将体积密度建模为几何形状的函数来实现表面重建。定义的体积密度函数作为拉普拉斯的累积分布函数(CDF)应用到一个有符号的距离函数(SDF)表示。优点:1、它向在神经体绘制过程中学习的几何结构提供有用的归纳偏置。2、它有助于不透明度近似误差的界限,导致对观察光线的准确采样。3、它允许在体积绘制中有效的无监督地解除形状和外观的纠缠。
1、介绍
将密度表示为到场景表面的有符号距离的函数,首先,它保证了生成密度的明确定义的表面的存在。其次,这种密度公式允许限制沿着光线的不透明度的近似误差。NeRF,将神经隐式函数与体积渲染相结合,能够达到极佳的渲染效果。然而在场景几何体形状的表示上有所欠缺。
2、方法
利用一种新的参数化的体密度,定义为变换的SDF,可以促进体渲染过程,并且文章推导出一个边界的不透明度近似的错误,设计了一个采样过程近似的体渲染积分(公式)。
2.1密度转换为SDF
Ω
⊂
R
3
\Omega\subset\mathbb{R}^3
Ω⊂R3表示三维空间中物体占据的空间。使用
M
=
∂
Ω
\mathcal{M}=\partial\Omega
M=∂Ω表示该物体的边界曲面。用1Ω表示表示Ω指示函数,用dΩ表示到其边界M的符号距离函数(SDF)在物体内部则用负数表示距离,在物体外部用正数表示距离。

使用可学习的符号距离函数dΩ的变换来建模密度这一性质。α、β > 0是可学习参数,并且Ψβ是具有零均值和β尺度参数的拉普拉斯分布的累积分布函数(CDF)

拉普拉斯分布

直观地,密度σ对具有恒定密度α的均匀对象进行建模,该恒定密度α在对象的边界附近平滑地减小,其中平滑量由β控制。
将体积密度函数转换为SDF有两个好处。首先,它为表面几何提供了有用的归纳偏差,并为重建表面提供了一种原则性方法。这与以前的工作形成鲜明对比,即重建被选为学习密度的任意级别集。其次,有助于约束渲染体积的不透明度误差,这是体积渲染管线中的关键组成部分。这与以前的方法再次相反,在以前的方法中,很难为一般的MLP密度设计这样的边界。
2.2 σ的体渲染
首先回顾体渲染中的积分,每条射线有一组S个采样点, 在体渲染中,考虑从相机位置c∈R3 沿方向v∈R3 发出的射线x:x(t)= c + tv,t ≥ 0。体积渲染是所有关于近似于沿着这一射线到达相机的集成光辐射。其中有两个重要的参数:透明度T和光场L
透明度T定义如下公式,表示一个光粒子成功穿过段[c, x(t)]而不反弹的概率

不透明度O是互补概率O(t) = 1 −T(t),O是单调递增函数,O(0)=0,假设每条射线最终被遮挡即O(∞)=1,所以可以将O看作是拉普拉斯累积分布函数(CDF),即

从而得到概率密度函数(Probability Density Function, PDF)

L(x,n,v)是辐射场,即在方向v上从点x发出的光线,辐射场同样受到法线的影响
n
(
t
)
=
∇
x
d
Ω
(
x
(
t
)
)
\boldsymbol{n}(t)=\nabla_{\boldsymbol{x}}d_\Omega(\boldsymbol{x}(t))
n(t)=∇xdΩ(x(t))
。使用法线是根据BRDF计算颜色中的法线。
解纠缠,接下来就是一系列的采样
S
=
{
s
i
}
i
=
1
m
,
0
=
s
1
<
s
2
<
⋯
<
s
m
=
M
;
{\cal S}=\{s_{i}\}_{i=1}^{m},0=s_{1}<s_{2}<\cdots<s_{m}=M;
S={si}i=1m,0=s1<s2<⋯<sm=M; 累加估计这个积分(离散值),ti表示间距乘以PDF,Li表示采样的辐射场。

VolSDF的采样方案: 使用单个密度σ,并且通过基于不透明度近似的误差界的采样算法来计算采样S。
2.3 不透明度近似误差的界限
使用矩形规则开发不透明度近似误差的界限,对于一组样本
T
=
{
t
i
}
i
=
1
n
,
0
=
t
1
<
t
2
<
⋯
<
t
n
=
M
\mathcal{T}=\{t_i\}_{i=1}^n,0=t_1<t_2<\cdots<t_n=M
T={ti}i=1n,0=t1<t2<⋯<tn=M,令
δ
i
=
t
t
+
1
−
t
i
\delta_{i}=t_{t+1}-t_{i}
δi=tt+1−ti且
σ
i
=
σ
(
x
(
t
i
)
)
\sigma_i=\sigma(\boldsymbol{x}(t_i))
σi=σ(x(ti)),给定某个t ∈(0,M],假设t ∈ [tk,tk+1],并应用矩形规则(即,左黎曼和)以得到近似:

并且E(t)表示该近似中的误差。不透明度函数(等式5)的对应近似为,可以得到计算不透明度的近似公式
O
^
(
t
)
=
1
−
exp
(
−
R
^
(
t
)
)
\widehat{O}(t)=1-\exp(-\widehat{R}(t))
O
(t)=1−exp(−R
(t))
目标是导出[0,M]上近似为
O
^
≈
O
.
\widehat{O}\approx O.
O
≈O.的一致界,关键是沿着射线x(t)的区间内密度o的导数的下界
Theorem 1.
密度σ在[ti,ti+1]段内的导数满足


该定理的好处是它允许仅基于区间端点处的无符号距离|di|,|di+1|和密度参数α,β来约束每个区间[ti,ti−1]中的密度导数。此界限可用于导出矩形规则的不透明度近似值的误差界限

Theorem 2
对于t ∈ [0,M],近似不透明度O的误差可以有界如下:

可以通过注意
E
^
(
t
)
\widehat{E}(t)
E
(t),以及exp(
E
^
(
t
)
\widehat{E}(t)
E
(t))在t中单调递增,而exp(−
R
^
(
t
)
\widehat{R}(t)
R
(t))在t中单调递减,来约束t∈[tk,tk+1]的不透明度误差限制t ∈ [tk,tk+1]的不透明度误差,通过

取所有区间上的最大值提供了作为T和β的函数的界BT,β

Lemma 1
固定β > 0。对于任何 ϵ \epsilon ϵ> 0,足够密集的采样T将使得BT,β < ϵ \epsilon ϵ。
其次,对于固定数量的样本,我们可以设置β,使得误差界低于 ϵ \epsilon ϵ:
Lemma 2
固定n > 0。对于任何
ϵ
\epsilon
ϵ> 0,一个足够大的β满足

将保证BT,β ≤
ϵ
\epsilon
ϵ。
这部分主要对不透明做了一个约束,让他的误差足够小。
2.4 采样算法
需要一些算法采样确定一组采样点使得近似结果与实际结果足够接近,即保证BT,β ≤
ϵ
\epsilon
ϵ
对于lemma1,选择足够大的采样点是可以保证误差足够小,但是采样点会很大,主要是用lemma2的方法,选择一个β+ >β,使得BT,β+ ≤
ϵ
\epsilon
ϵ,在保证该前提的情况下不断增加采样数,同时减小β+,这样的策略不保证收敛,然而实践表明有85%的概率可以收敛,即使不收敛也会保证小于误差

使用逆变换采样(11行)返回一组新的m = 64个样本(O)
2.5 损失计算
系统的输入是一系列图片以及对应的相机参数,模型对每一个具体的像素点p进行处理学习。每一个像素点p对应一个三元组
(
I
p
,
c
p
,
v
p
)
(I_{p},\boldsymbol{c}_{p},\boldsymbol{v}_{p})
(Ip,cp,vp),
I
p
I_{p}
Ip代表RGB颜色,
c
p
\boldsymbol{c}_{p}
cp为相机位置,
v
p
\boldsymbol{v}_{p}
vp为射线方向,损失函数由两部分组成


总结
VolSDF将体积密度表示为可学习的表面几何形状的符号距离函数的变换版本,提供了有用的归纳偏置,允许几何结构的解纠缠(密度)和辐射场,并且相对于先前的神经体绘制技术改进了几何近似。此外,它允许限制不透明度近似误差,从而导致体绘制积分的高保真度采样。

![[Java基础练习-002]综合应用(基础进阶),如果你会做,那说明你java入门了,](https://img-blog.csdnimg.cn/ea68ec2aa1874ef3b06fdc00d81c5960.png)