问题描述
在使用face_recognition时,在对np.array格式图片使用形如`new_img = img[x:y, a:b]``进行裁剪后,因为是软拷贝,导致前后图片其实引用了同一个face_locations, 从而导致莫名其妙的错误。
问题代码
检测一张照片里的人脸,并进行encode:
image = face_recognition.load_image_file("Keanu Reeves.jpg")
face_locations = face_recognition.face_locations(image)
top, right, bottom, left= face_locations[0]
face_image = image[top:bottom, left:right] # 不知道什么原因,改变尺寸后导致无法编码
face_encoding = face_recognition.face_encodings(face_image)
运行结果:
compute_face_descriptor(): incompatible function arguments. The following argument types are supported:
1. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], face: _dlib_pybind11.full_object_detection, num_jitters: int = 0, padding: float = 0.25) -> _dlib_pybind11.vector
2. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], num_jitters: int = 0) -> _dlib_pybind11.vector
3. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], faces: _dlib_pybind11.full_object_detections, num_jitters: int = 0, padding: float = 0.25) -> _dlib_pybind11.vectors
...
在上面的例子中,直接将改变尺寸后的图片face_image 进行编码,是无法编码的。
但是如果将其保存成图片,然后再打开,就可以编码了:
image = face_recognition.load_image_file("Keanu Reeves.jpg")
face_locations = face_recognition.face_locations(image)
top, right, bottom, left= face_locations[0]
face_image = image[top:bottom, left:right]
old_image = face_image[:] # 不保存为图片,只是保存在内存里
cv2.imwrite("new.jpg", face_image) # 保存为图片
face_image = face_recognition.load_image_file("new.jpg") # 打开保存的图片,进行编码就可以
face_encoding = face_recognition.face_encodings(face_image)
plt.imshow(face_image)
按照上面的方式又能够成功。难道保存在内存里的值和重新打开图片的值,不一样吗?
face_image == old_image
运行结果:
array([[[False, True, False],
[False, False, False],
[False, False, False],
...,
[False, False, False],
[False, False, False],
[False, False, False]],
[[False, True, False],
[False, True, False],
[False, True, False],
...,
[False, False, False],
[False, False, False],
[False, False, False]],
[[False, True, False],
[False, False, False],
[False, True, False],
...,
可以看出,两者的数据确实是不一样的。这是为什么呢?
还有一个更奇葩的
如果这里只是将top, right, bottom, left的值换一下,就又可以进行编码了!
image = face_recognition.load_image_file("Keanu Reeves.jpg")
face_locations = face_recognition.face_locations(image)
top, right, bottom, left= face_locations[0]
# face_image = image[top:bottom, left:right] # 不知道什么原因,改变尺寸后导致无法编码
face_image = image[0:100,0:100] # 在这里,将值调大调小都可以,只要不用原始face_locations的值
# face_image = face_image[:, :, ::-1]
face_encoding = face_recognition.face_encodings(face_image)
plt.imshow(face_image)
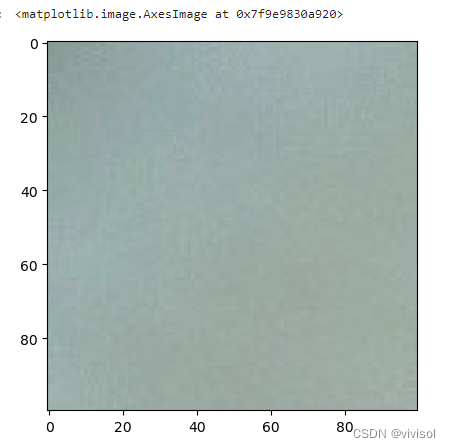
原因分析
**在图片裁剪时,使用的是地址引用的方式(软拷贝),而不是硬拷贝,导致裁剪前后的image其实共用了一个face_locations。**裁剪完后,只需要硬拷贝一次,形成新的image的地址,就可以解决。
因为在上面执行face_locations时,已经为image创建了一个内部的实例,
并且这个实例,关联到了之前的face_locations值, 如果是软拷贝的话,裁剪后的face_image与之前image指向了同一个地址。
这样直接传入给face_encodings()时,会将其一个optional的参数face_locations按照image的关联值带入,导致错误;
换不同尺寸去裁剪时,因为Python的动态内存机制,有可能Python会给face_image分配一个新的内存,只有分配一个新的内存情况,在下一步的face_encodings(new)中,才会将其当做一个新的图片处理,而不报错。
如果碰巧,裁剪的尺寸如果和face_locations接近时,就不会分配新的内存空间,在执行face-encodings()时带入旧的face_locations的值,而导致错误
软拷贝的情况:
硬拷贝的情况:
解决办法
from PIL import Image, ImageDraw
import face_recognition
import matplotlib.pyplot as plt
image = face_recognition.load_image_file("Keanu Reeves.jpg")
face_locations = face_recognition.face_locations(image)
top, right, bottom, left= face_locations[0]
print(top, bottom, left, right)
face_image = image[top:bottom, left:right] # 不知道什么原因,改变尺寸后导致无法编码
# face_image = image[750:1682, 800:1575]
# new = face_image[:] # 这种软拷贝方式是不行的
'''
只能用下面这种硬拷贝方式才可以,因为在上面执行face_locations时,已经为image创建了一个内部的实例,
并且这个实例,关联到了之前的face_locations值, 如果是软拷贝的话,裁剪后的face_image与之前image指向了同一个地址。
这样直接传入给face_encodings()时,会将其一个optional的参数face_locations按照image的关联值带入,导致错误;
换不同尺寸去裁剪时,如果可能导致Python给face_image分配一个新的内存,只有分配一个新的内存,在下一步的face_encodings(new)中,才会
将其当做一个新的图片处理,而不报错。
如果碰巧,裁剪的尺寸如果和face_locations接近时,就不会分配新的内存空间,在执行face-encodings()时带入旧的face_locations的值,而导致错误
'''
new = face_image.copy()
face_encoding = face_recognition.face_encodings(new)
plt.imshow(face_image)
运行结果:











![[CSDN] 512创作纪念日,大处着眼,小处着手,乐观进取](https://img-blog.csdnimg.cn/df15cb28a234421995ee271a2cb742a4.png)