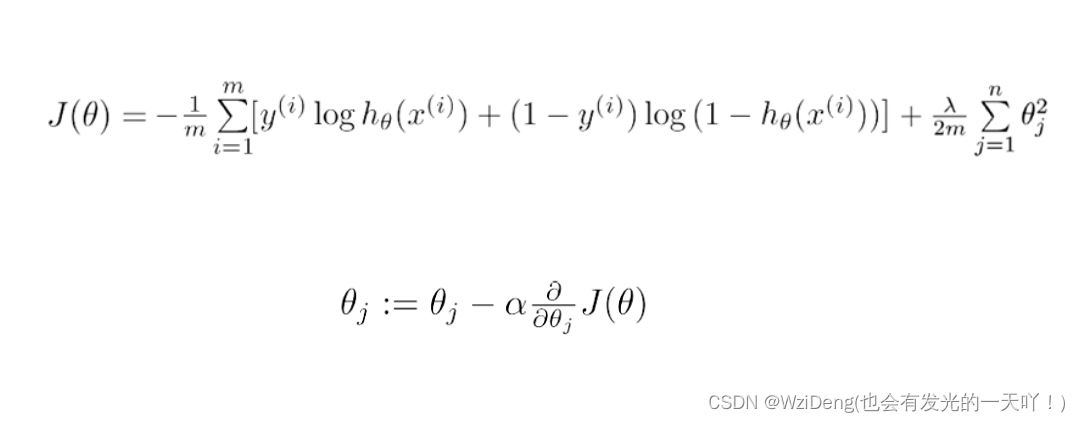带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性

1.什么是语言模型?
大家或多或少都听过 ChatGPT 是一个 LLMs,那 LLMs 是什么?LLMs 全称是 Large Language Models,中文是大语言模型。那么什么是语言模型?
语言模型简单说来,就是对人类的语言建立数学模型,注意,这里的关键是数学模型,语言模型是一个由数学公式构建的模型,并不是什么逻辑框架。这个认知非常重要。最早提出语言模型的概念的是贾里尼克博士。他是世界著名的语音识别和自然语言处理的专家,他在 IBM 实验室工作期间,提出了基于统计的语音识别的框架,这个框架结构对语音和语言处理有着深远的影响,它从根本上使得语音识别有实用的可能。在贾里尼克以前,科学家们把语音识别问题当作人工智能问题和模式匹配问题。而贾里尼克把它当成通信问题。
为何是通讯问题?为何转换成通讯问题后,就能实现语音识别?根据香农确定的现代通讯原理,所谓的通讯,也被称为信道的编码和解码,信息源先产生原始信息,然后接收方还原一个和原始信息最接近的信息。比如,你打电话的时候,问对方一句「你吃了晚饭了吗」,在传输前,通讯系统会对这句话进行编码,编成类似「100111101100000…」,但是传输过程中,一定会有信号损失,接收方收到的编码可能是「1001111011000…」,此时我们就没法解码回原来的句子了。
- 那如何解决这个问题?
我们可以把与接收到的编码「1001111011000…」类似的句子都罗列出来,可能的情况是:
- 吃了晚饭了吗
- 你吃了饭了吗
- 你吃了晚饭了吗
- 你吃了晚饭了
然后通讯系统会计算出哪一种的可能性最大,最后把它选出来。只要噪音不大,并且传输信息有冗余,那我们就能复原出原来的信息。贾里尼克博士认为让计算机理解人类的语言,不是像教人那样教它语法,而是最好能够让计算机计算出哪一种可能的语句概率最大。这种计算自然语言每个句子的概率的数学模型,就是语言模型。
2.如何计算概率?
-
第一阶段:最简单的方法,当然就是用统计学的方法去计算了,简单说来,就是靠输入的上下文进行统计,计算出后续词语的概率,比如「你吃了晚饭了吗」,「你吃了」后面按照概率,名词如「饭」或「晚饭」等概率更高,而不太可能是动词,如「睡」「睡觉」。这是语言模型的第一阶段,模型也被称为是统计语言模型(Statistical Language Model,SLM),其基本思想是基于马尔可夫假设建立词语测模型,根据最近的上下文预测下一个词。后续语言模型的发展又迭代了三个版本。
-
第二阶段是神经网络语言模型(Neural Language Model,NLM),是一个用神经网络来训练模型,学习单词之间的关联性和概率关系。它能够利用大量的数据进行深度学习,从而捕捉到词汇之间更加复杂的关系。NLM 模型采用的是分层的结构,把输入的文本数据空间投射到高维的语义空间中并进行学习。通过不断地更新神经网络模型参数,NLM 的神经网络逐渐学会了文本数据的语义并能够生成连贯自然、语义准确的文本。
与前面提到的 SLM 相比,由于深度神经网络的学习能力更强,NLM 在学习语言模型时具有更好的泛化能力和适应性。比如能生成更长的文本等。但 NLM 相对来说也比较依赖更大的数据集,并且需要花很多人力在数据标注上。
-
第三阶段是预训练语言模型(Pre-trained Language Model,PLM),是一种使用大量文本数据来训练的自然语言处理模型。相对 NLM 来说,PLM 使用无监督学习方法,因此不需要先标注数据或注明文本类型等信息。各位可能听过的 Transformer 架构就是一种预训练语言模型。
-
第四阶段是大预言模型(Large Language Model),你可以将现在的 LLM 理解为一个训练数据特别大的 PLM,比如 GPT-2 只有 1.5B 参数,GPT-3 则到了惊人 175B,尽管 LLM 只是拓展了模型的大小,但这些大尺寸的预训练语言模型表现出了与较小的预训练语言模型不同的行为,并且在解决一些复杂任务上展现了惊人的能力(俗称涌现能力,注意这个涌现能力目前还存在争议),所以学术界为这些大型预训练语言模型命名为大语言模型 LLM。
上面这四个阶段可能比较难理解,你可以简单理解:
- 语言模型本质上都是在计算自然语言每个句子的概率的数学模型。当你输入一个问题给 AI 时,AI 就是用概率算出它的回答。
- 另外,当今的语言模型,并不是一个问题对一个答案,实际上是一个问题,多个答案,然后根据答案的概率进行排序,最后返回一个最可能的答案。
3. 开发大语言模型需要什么?
了解完大语言模型的原理之后,你可能会好奇 TA 是如何开发的。开发大语言模型的关键是什么。最近看到不少文章为了流量,甚至连 5G 通讯都说成了是开发大语言模型的关键,其实从前面的原理介绍,不难看出,大语言模型的其中一个关键点是数据。
关键一:数据
训练数据主要是所谓的语料库。今天的很多语言模型的语料库主要有以下几种:
- Books:BookCorpus 是之前小语言模型如 GPT-2 常用的数据集,包括超过 11000 本电子书。主要包括小说和传记,最近更新时间是 2015 年 12 月。大一点的书籍语料库是 Gutenberg,它有 70000 本书,包括小说、散文、戏剧等作品,是目前最大的开源书籍语料库之一,最近更新时间是 2021 年 12 月。
- CommonCrawl:这个是目前最大的开源网络爬虫数据库,不过这个数据包含了大量脏数据,所以目前常用的四个数据库是 C4、CC-Stories、CC-News 和 RealNews。另外还有两个基于 CommonCrawl 提取的新闻语料库 REALNEWS 和 CC-News。
- Reddit Links:简单理解 Reddit 就是外国版本的百度贴吧 + 知乎。目前开源的数据库有 OpenWebText 和 PushShift.io。
- Wikipedia:维基百科是目前大模型广泛使用的语料库。
- Code:一般包含 GitHub 上的开源公共代码库,或者是 StackOverflow 的数据,Google 之前发布过一个叫 BigQuery 的数据集。
实际上,训练大语言模型会混合使用不同的数据,一般不会只使用单一语料库。比如 GPT-3 用的混合数据集就包括 Books、CommonCrowl、Reddit Links 和 Wikipedia。
从数据上看,你需要知道一个事实,中文语料在这上面占比很小。ChatGPT 能用中文回答你的问题,只是因为它的语料里有一些中英文对应的语料,然后模型就像是「懂中文了一样」,所以更可能的情况是,它先生成了英文内容,再翻译成中文。如果你去问 ChatGPT 3.5:请给我几个中文谐音梗,你应该就能理解我说的话了。
以下是 ChatGPT 的返回结果:
以下是一些中文谐音梗的例子:
我蒸发了,意思是我是 Vaper 了(Vaper发音接近蒸发)。
会有星期天,都得过过来,意思是星期二,星期三,星期四,星期五,星期六,都得过过来。
看到你,我的内心凉了 below zero,意思是凉了半截(below zero与半截音相近)。
蜀道难,难于上青天,赛道难,难于上488(488与“蜀道难”同音)。
洋葱姑娘,想哭却哭不出来,因为洋葱让我流泪了(洋葱和“要哭”在中文中的发音很相似)。
雨纷纷,旧故里草木深,我听闻,你始终在我身边深(“身边深”和“身边寻”谐音)。
你的车开得真快,一开就是“出租”,意思是“出祖宗”(发音类似)。
关键二:算法
有了数据之后,你还需要有算法去做计算,目前最常用的开发大语言模型的算法库有:
- Transformers:这是一个使用 Transformer 架构构建的开源 Python 库。
- DeepSpeed:是由微软开发的深度学习优化库。
- Megatron-LM:这是由 Nvidia 开发的深度学习库。
- JAX:它是由 Google 开发的用于高新能机器学习算法的 Python 库。
关键三:算力
简单理解,算力就是计算资源,或者说硬件,OpenAI 没有说它训练 GPT-3 语言模型花了多少计算资源。但 OpenAI 的 CEO 暗示硬件成本超过一亿美元,如果我们按照 1000 美元一个 GPU 计算,它大约使用了 10 万个 GPU,以 32 位运算为准,它能提供超过 100 PFLOPS 的算力,也就是每秒 10 亿亿次运算以上,这大约是阿里云最大的数据中心的四分之一的算力。
注意,这还是 GPT-3 时的花费。
另外,我还想分享一个观点,不要以为算力会随时间的前进,就能跨越。算力永远会是制约我们瓶颈,因为我们对人工智能的要求会不断的提高。
本文主要内容来自论文 A Survey of Large Language Models。
4. 大语言模型有什么缺点?
了解完原理后,我觉得有必要跟大家聊聊大语言模型的缺点,这样大家才能知道 AI 的边界在哪里,并在可控的边界内进行创新。
缺点一:结果高度依赖训练语料
正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。
那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的结果,高度依赖训练语料。
那会导致怎样的后果?
- 如果语料的内容是有偏的(比如带有种族歧视、性别歧视的内容),甚至是错误的,那大语言模型的生成的结果也会是错误的。
- 如果该领域语料很少,大语言模型生成的结果准确率就很低。甚至有可能会出现幻觉(这个是第二个缺点)。
当然面对这个缺点,有什么方法规避?
第一种方法就是在语料大、且错误率低的领域使用 LLMs。
比如语言学领域,像翻译、或者文案生成这种场景。即使语法错误了,但语料里存在大量的相同用法,那某种程度上来说,模型给的答案也算是对的,有点类似古代的通假字,或者现代的很多流行语。
第二种就是用人工干预。
简单说来就是人工将语料里的内容剔除,或者对其进行人类反馈强化学习。但人工干预并不意味着就没有问题了,这种方法有可能导致新的问题出现,比如将人的主观好恶加入到模型中,或者有可能伪造一些信息,加入到模型中。
缺点二:Hallucinations
这个可以直译成「幻觉」,简单说来,就是会说胡话。有些问题因为语聊很少,计算概率后,会吐出一些很奇怪的内容,比如这个例子,我让 AI 介绍一个世界上不存在的品牌 Boie 的智能牙刷:
Tell me about AeroGlide UltraSlim Smart Toothbrush by Boie
AI 的回答是,你可以看到 AI 就是在一本正经地说胡话:
The AeroGlide UltraSlim Smart Toothbrush by Boie is a high-tech toothbrush that uses advanced sonic technology to provide a deep and thorough clean. It features a slim and sleek design that makes it easy to hold and maneuver, and it comes with a range of smart features that help you optimize your brushing routine.
One of the key features of the AeroGlide UltraSlim Smart Toothbrush is its advanced sonic technology, which uses high-frequency vibrations to break up plaque and bacteria on your teeth and gums. This technology is highly effective at removing even the toughest stains and buildup, leaving your teeth feeling clean and refreshed.
In addition to its sonic technology, the AeroGlide UltraSlim Smart Toothbrush also comes with a range of smart features that help you optimize your brushing routine. These include a built-in timer that ensures you brush for the recommended two minutes, as well as a pressure sensor that alerts you if you're brushing too hard.
Overall, the AeroGlide UltraSlim Smart Toothbrush by Boie is a highly advanced and effective toothbrush that is perfect for anyone looking to take their oral hygiene to the next level. With its advanced sonic technology and smart features, it provides a deep and thorough clean that leaves your teeth feeling fresh and healthy.
缺点三:暂时只能解决数学问题
我解释下,这里提到的数学问题,并不仅仅指的是数学运算这种数学问题,而是能通过数学解决的问题。比如我们可以研发无人驾驶汽车,当它遇到行人突然横穿马路时,能自己刹车停下来,这就是一个数学问题,它通过计算识别行人,并进行刹车。
但如果这辆无人车在一个单行道的巷子里遇到一辆堵在巷子的汽车,它就没有办法了,只能报警,让司机过来挪车,这就是一个数学无法解决的问题。
暂时来看目前大多数的 LLMs 都只能解决数学问题,有些不可计算的问题,暂时都没法解决。特别像是需要自己实操进行实验的问题。
当然我这里也只是称其为「暂时」,因为可能未来机器人 + LLMs 有可能会将可计算的范围拓展宽一点。
参考链接:https://github.com/thinkingjimmy/Learning-Prompt