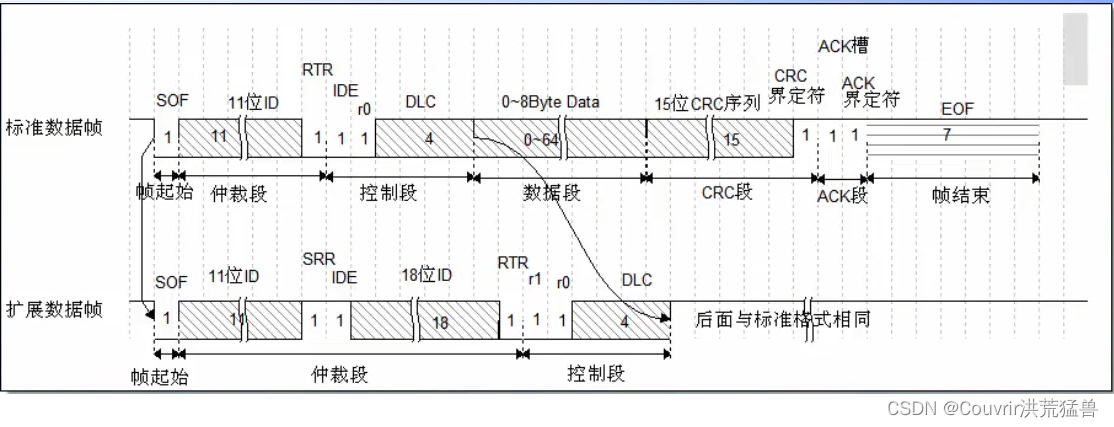
《自然语言处理》课程报告
摘 要
宋词是一种相对于古体诗的新体诗歌之一,为宋代儒客文人智慧精华,标志宋代文学的最高成就。宋词生成属于自然语言处理领域的文本生成模块,当前文本生成领域主要包括基于语言模型的自然语言生成和使用深度学习方法的自然语言生成。本项目基于深度学习的tensorflow框架,构建了不同的宋词生成模型,并对其进行训练和评估,通过比较得出结论。
首先,在github上收集了5000首宋词作为数据集,然后对数据集进行预处理,包括缺失值处理,异常符号处理,建立词典。接着,以字为粒度,使用滑动窗口方法生成训练集和测试集。以所有宋词为文本数据使用word2Vec模型,进行无监督学习,得到每个字的词向量,用于后面神经网络embedding层权重的初始化工作。然后使用TextCNN、LSTM、Attention、Transformer等网络结构和方法建、立宋词生成模型,本项目共实现六种模型,分别为:TextCNN 、BiLSTM、BiLSTM+Attention、CNN+BiLSTM+Attention、Tex-tCNN+BiLSTM+Attention和Transformer模型,最后,对模型进行训练,上述模型在测试集上的准确率分别为:0.63、0.68、0.73、0.81、0.69、0.85。其中,Transformer模型的效果最佳,准确率达到了85%,以“晚风轻拂”为输入,得到输出宋词为: 晚风轻拂楚乡,月当门,凉心在。千仙隔画迷津,白发漫回,休的人高处。流红千浪,缺月孤楼,总难留燕。试挑灯欲写,还依不忍。可以看出,生成的宋词效果较好。最后,针对上述模型的结果,结合其原理进行了总结与分析。
1.项目简介
宋词是一种相对于古体诗的新体诗歌之一,为宋代儒客文人智慧精华,标志宋代文学的最高成就。宋词生成属于自然语言处理领域的文本生成模块,当前文本生成领域主要包括基于语言模型的自然语言生成和使用深度学习方法的自然语言生成。文本生成技术的应用前景广阔,本项目使用了word2Vec、TextCNN、LSTM、Attention、Transformer等网络结构和方法建立宋词生成模型,并对各种模型的效果进行了对比和分析。
2.项目实现方案
本项目以word2Vec、TextCNN、LSTM、Attention、Transformer等网络和机制为基础,通过改变网络结构,实现了项目整体流程图,如图1所示。
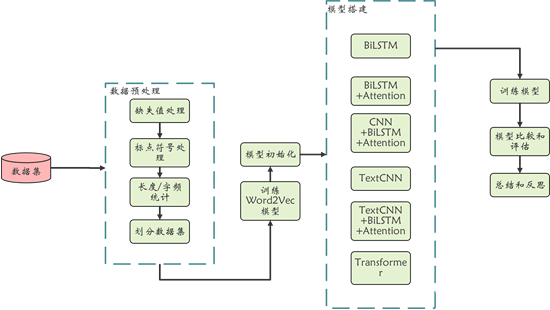
2.1前期准备
2.1.1数据集来源
数据来源:chinese-poetry/chinese-poetry: The most comprehensive database of Chinese poetry 最全中华古诗词数据库, 唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。 (github.com),本项目选取了5000首宋词作为数据集,数据集格式为json格式,包含5个json文件,每个文件中包含1000首宋词。

2.1.2 数据预处理
拿到数据之后,首先进行了缺失值处理,对于没有内容的字段,将其删除,然后去除了部分错误的标准符号,将数据进行了整体的清洗工作。处理完成后,对宋词长度进行了统计,如图3,从图中可以看出,大部分宋词长度处于50-100个字符之间。少部分超过150个字符。

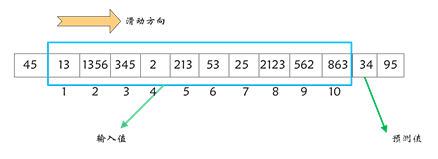
由于宋词属于古代文章,不适合用现代分词工具,强行使用分词工具后会导致效果不理想,故本项目以字为粒度,使用keras.preprocessing.text中的 Tokenizer工具,对宋词文档进行预处理,生成词典及其每个字对应的索引,统计后共有4394个字。然后,对每一篇宋词使用texts_to_sequences工具,将对应的字转化为词典索引下标。下面通过滑动窗口的方式生成训练集和测试集。以10为窗口,对每一篇宋词从头开始以此向右滑动,前10个词为输入值,后1一个词为预测值,进行采样,采样方式如图4,最终得到74693条样本数据,以8:2划分训练集和测试集,得到59754条训练集数据,14939条测试集数据。
2.1.3 环境搭建
本项目使用Tensorflow,Keras和Keras_transformer框架
版本:Python3.6.3 Tensorflow2.6.2 Keras2.6.0 keras_transformer0.40.0
下面是用到的一些包
import numpy
from keras import backend as K
from keras import activations
from gensim.models import word2vec
from keras.layers import layer
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.models import Model
from keras.layers import Input, Dense, embedding, LSTM, Bidirectional, MaxPooling1D,Flatten,concatenate,Conv1D
from tensorflow.keras.utils import tocategorical
import tensorflow as tf
from keras.preprocessing.sequence import padsequences
from keras.layers import embedding, LSTM, Dense, Dropout
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from keras.models import Sequential
import keras.utils as ku
from sklearn.modelselection import traintestsplit
from tensorflow.keras.utils import tocategorical
2.3 模型准备
2.2.1 Word2vec
Word2vec是google在2013年推出的一个NLP工具,它的特点是能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,所以速度更快通用性很强,可以用在各种 NLP 任务中。下图为Word2vec结构图。
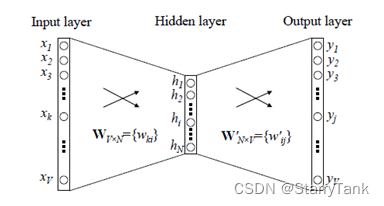
Word2Vec的训练模型本质上是只具有一个隐含层的神经元网络,它的输入是采用One-Hot编码的词汇表向量,它的输出也是One-Hot编码的词汇表向量。使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用Distributed Representation的词向量。网络以词表现,并且需猜测相邻位置的输入词,训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。在本项目中,首先使用Word2vec对所有宋词进行训练,窗口大小设置为5,词向量维度设置为100,对所有词都考虑,将训练好的权重作为后续神经网络中embedding层的初始化权重值。
2.2.2 CNN和TextCNN
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它由若干卷积层和池化层组成。CNN的基本结构由输入层、卷积层(convolutional layer)、池化层(pooling layer)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层。卷积神经网络由多层感知机(MLP)演变而来,对于高维输入,将所有神经元与前一层的神经元实现全连接是不实际的,于是采用部分连接(局部感知)。由下图可知,连接数成倍的减少,参数也成倍的减少。
在2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型textCNN。与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化(甚至更加简单了), 从图6可以看出textCNN 其实只有一层卷积,一层max-pooling, 最后将输出外接softmax 来n分类。TextCNN最大优势网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。 textCNN的缺点:模型可解释型不强,在调优模型的时候,很难根据训练的结果去针对性的调整具体的特征,因为在textCNN中没有类似gbdt模型中特征重要度(feature importance)的概念, 所以很难去评估每个特征的重要度。
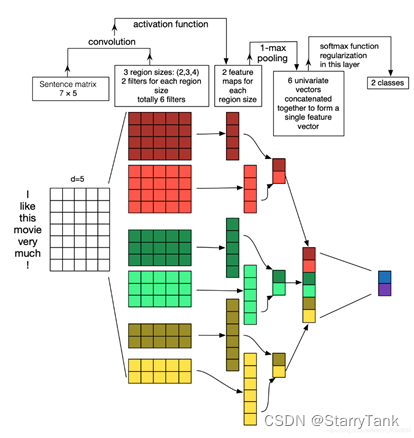
在本项目中,使用部分句子预测下一个单词,本质上属于分类任务,故尝试使用TextCNN来提取文本特征,对下一个词进行预测,并且还使用了CNN和BiLSTM结合的模型来对下一个词进行预测。
2.2.3 LSTM和BiLSTM
LSTM的全称是Long Short-Term Memory,它是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!所有 RNN 都具有一种重复神经网络模块的链式的形式,LSTM结构如图7所示。
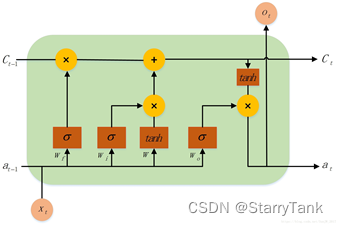
LSTM只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。BiLSTM有两个LSTM上下叠加在一起组成的,输出由这两个LSTM的状态共同决定,如图8。
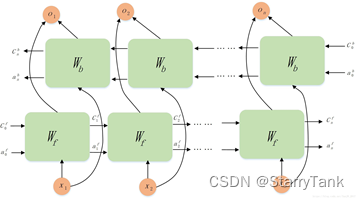
2.2.4 Attention机制
attention机制最早是应用于图像领域的,随后Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制就被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。attention机制的本质是从人类视觉注意力机制中获得灵感,大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。
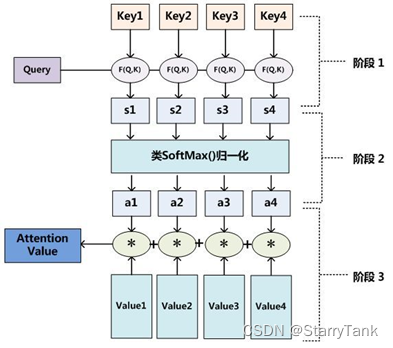
attention函数共有三步完成得到attention value。Q与K进行相似度计算得到权值对上部权值归一化,用归一化的权值与V加权求和上面从attention函数得到了attention机制工作过程。现在换一个角度来理解,我们将attention机制看做软寻址。就是说序列中每一个元素都由key(地址)和value(元素)数据对存储在存储器里,当有query=key的查询时,需要取出元素的value值(也即query查询的attention值),与传统的寻址不一样,它不是按照地址取出值的,它是通过计算key与query的相似度来完成寻址。这就是所谓的软寻址,它可能会把所有地址(key)的值(value)取出来,上步计算出的相似度决定了取出来值的重要程度,然后按重要程度合并value值得到attention值。
attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。并行计算减少模型训练时间attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。模型复杂度小,参数少。
2.2.5 Transformer
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
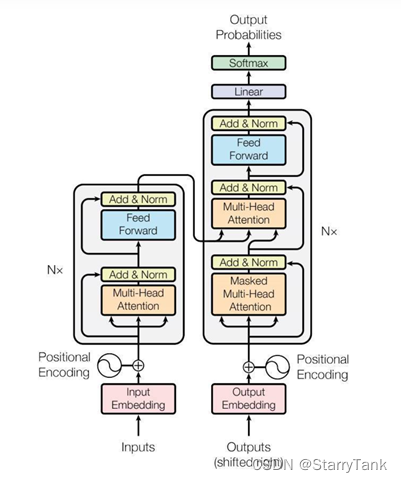
Transformer 与 RNN 不同,可以比较好地并行训练。Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
2.4模型搭建
2.4.1 TextCNN
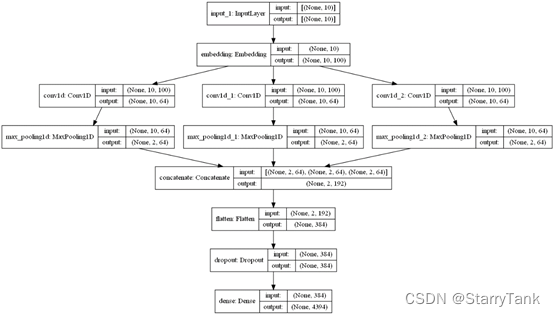
TextCNN模型用作宋词生成,其中模型第一层为输入层,第二层为embedding层,embedding层的权重矩阵初始值由word2Vec预训练而来,引入三个卷积核,卷积核的长度与字的维度相同,卷积核的宽度分别设置为3,4,5,采用等宽卷积,channel设置为64,而后,分别对三个卷积之后的矩阵进行最大池化,然后将池化后的矩阵通过concatenate层拼接在一起,再加一层Flatten层进行展平,最后Dropout后,连接全连接层 ,softmax多分类,预测下一个词,网络结构见图11。
2.4.2 BiLSTM
BiLSTM模型用于宋词生成,模型第一层为输入层,第二层为embedding层,embedding层的权重矩阵初始值由word2Vec预训练而来,第三层为双向LSTM,维度为128,之后通过展平层对输出向量进行展平,最后Dropout后,接全连接层分类,具体网络结构见图12。
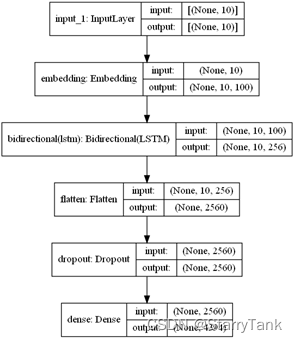
2.4.3 BiLSTM+Attention
在BiLSTM的结构中,双向LSTM层后加入attention层,通过attention层操作,将10x256维向量,转化为1x256维向量,后面直接连接全连接层进行分类,预测下一个词,具体网络结构见图13。
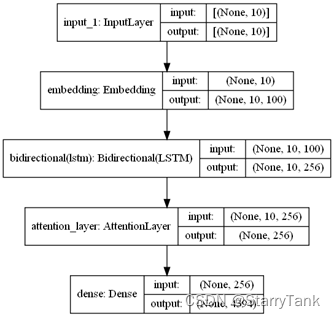
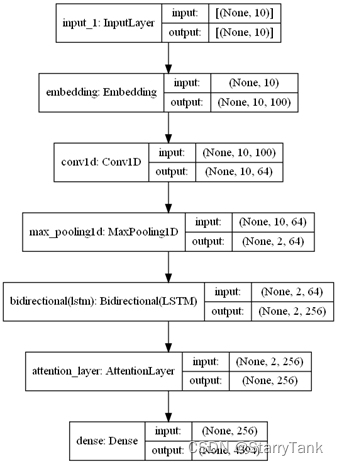
2.4.4 CNN+BiLSTM+Attention
将CNN与BiLSTM和Attention结合,在embedding层后增加一层卷积和一层池化,然后连接双向LSTM,后续结构与2.4.3相同,具体网络结构见图14。
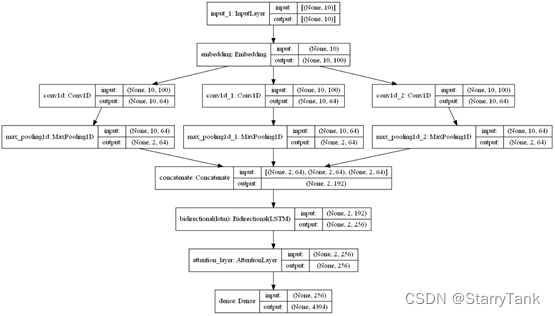
2.4.5 TextCNN+BiLSTM+Attention
将TextCNN与BiLSTM和Attention结合,与2.4.4不同的是,TextCNN有多个卷积核,卷积核的结构与2.4.1相同,通过concatnate层拼接各个卷积之后的向量,然后输入BiLSTM+ Attention网络,具体网络结构见图15。
2.4.6 Transformer
本模型通过使用keras_transformer 中的 get_model模块,搭建transformer模型其中get_model中的参数设置如下:token_num=10000,embed_dim=128,en-codernum=3,decoder_num=2,head_num=4,hidden_dim=256, attention_activ-ation=‘relu’,feed_forward_activation=‘relu’,dropout_rate=0.1。使用交叉熵损失函数,优化器为adam。由于transformer全部网络结果过于庞大,故展示大致结构,见图16。
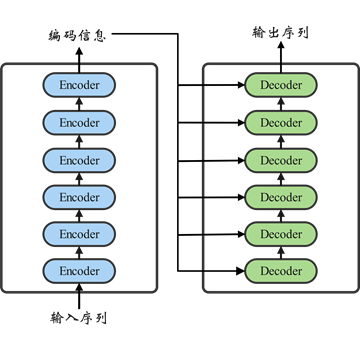
3.实验结果
对上述模型进行训练,得到结果见表1
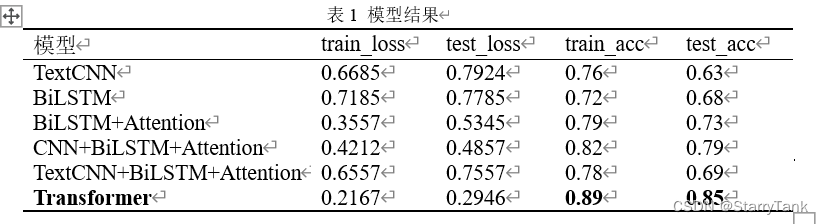
从上表可以看出,Transformer模型在测试集上的准确率最高,其次是CNN+BiLSTM+Attention模型,最低的是TextCNN模型。然后,以“晚 风 轻 拂”为模型输入,分别对应用上述模型生成宋词,结果见表2。
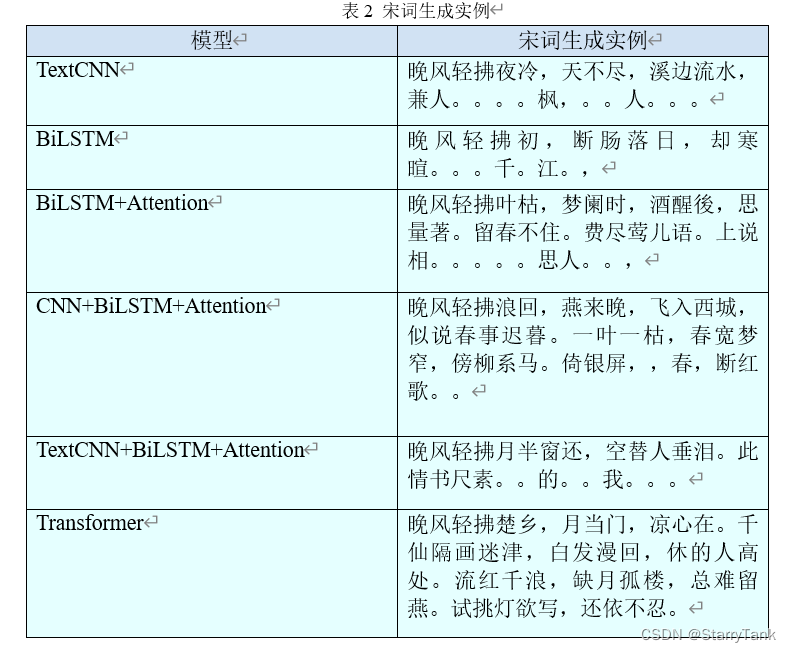
从上表可以看出,Transformer生成的宋词,句式较为规整,TextCNN和BiLSTM当句子过长时,无法正确生成宋词。而加入Attention机制后,宋词生成的效果有提高,这可能与其不能捕捉较长信息有关,而Attention机制可以改善当序列过长无法记住前面信息的特点,使编码更加全面。
4.项目总结
4.1项目评价与创新
本次项目分别使用了TextCNN、BiLSTM、 BiLSTM+Attention、CNN+BiLSTM+Attention、TextCNN+BiLSTM+Attention和Transformer共六种模型,其中Transformer与CNN+BiLSTM+Attention效果最好。本项目创新点在于将CNN与BiLSTM+Attention相结合,取得了不错的效果,在一些任务当中,在CNN后加上一层BiLSTM,能增强模型对语义的理解。CNN负责提取文本的特征,而BiLSTM负责理解句子的语义信息。当CNN融合了循环神经网络时,就是结合了这两者的功能,往往效果会有所提升。当输入的文本非常长的时候,双向长短期记忆模型也难以对文本有一个很好的向量表达。所以,这个时候就可以考虑使用注意力机制,来尝试抓住文本的重点。具体来讲,Attention机制就是通过保留BiLSTM编码器对输入序列的中间输出结果,再训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。本项目中,在模型后引入Attention模块能提升模型的效果。
TextCNN+BiLSTM+Attention在本项目中表现效果不佳,查阅相关资料后发现,一般不要拿TextCNN去融合BiLSTM, TextCNN本身就是一个非常优秀的模型了,在TextCNN后面加上一层循环神经网络,往往只是带来了更多的计算时间,其本身对于语义的理解,并没有什么帮助,甚至有可能对结果进行干扰。Transformer模型在本项目中表现最佳,于其本身模型架构有很大联系,Transformer摒弃传统CNN与RNN模式,使用Self-Attention模块,模型的解码能力要相对Seq2Seq等模型更强。
4.2 心得体会
在项目进行的过程中我遇到了很多困难,比如:环境配置问题,tensorflow与keras版本不匹配,导致后期代码总是报错,有些库函数也用不了,建议使用anaconda,方便管理各种包。Transformer在使用的过程中,对参数不理解,经常报错。
本次课程虽然短暂,但是学到了很多,许多之前自己在网上找资料,看视频没有搞清楚的东西,在课堂上通过老师的讲解也恍然大悟了。现在回想起综合实训时做的项目,当时一些理论知识没搞明白,报错后不知所以。但是经过本次课程学习,自己的理论知识更加地扎实,也逐步在脑海中形成了nlp框架,对nlp任务的整个处理流程和模型有了全面的认识。虽然自然语言处理课程结束了,但是对nlp的学习和探索道路还没有结束。不仅巩固了自己在课堂上学习的知识,而且加强了自己的自学能力以及积累了项目经验。这对后面的学习和科研都有很大的帮助。
参考文献
[1]梁骁. 结合注意力机制和条件变分自编码器的诗词生成方法研究[D].桂林电子科技大学,2021.DOI:10.27049/d.cnki.ggldc.2021.000874.
[2]https://zhuanlan.zhihu.com/p/162035103
[3]肖奕飞. 基于深度学习的长文本自动生成研究[D].江南大学,2022.DOI:10.27169/d.cnki.gwqgu.2022.001020.
[4]张晨阳,杜义华.短文本自动生成技术研究进展[J].数据与计算发展前沿,2021,3(03):111-125.
[5]高天. 基于seq2seq框架的文本生成算法研究[D].青岛科技大学,2021.DOI:10.27264/d.cnki.gqdhc.2021.000987.