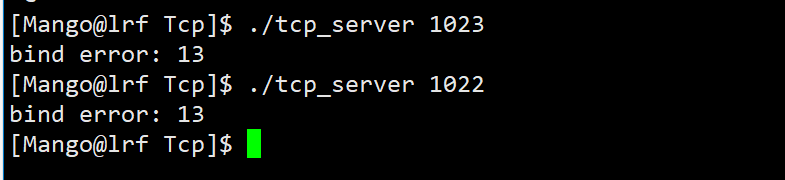
y_true = [1, 1, 1, 1, 1, 0, 0, 0, 0, 2]
y_pred = [1, 1, 0, 1, 1, 1, 0, 1, 0, 2]
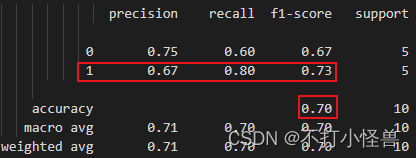
以上述类别 1 为例:
准确率 accuracy
总体概念,指所有样本中预测正确的比例:7/10 = 0.7
精确率 precision
预测标签为 1 的样本中确实为 1 的比例:4/6 = 0.67
召回率 recall
标签为 1 的样本中被预测为 1 的比例:4/5 = 0.8
F1得分 f1-score
综合考虑精确率 p 和召回率 r :f1 = 2pr/(p+r)= 0.73
在python中,可以通过 sklearn.metrics 库直接生成指标报告:
from sklearn.metrics import classification_report
y_true = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
y_pred = [1, 1, 0, 1, 1, 1, 0, 1, 0, 0]
report = classification_report(y_true, y_pred)
print(report)