文章目录
- Tuple类型
- Array类型
- Nested类型
- 使用示例
- 单独使用Tuple
- 数组嵌套 Array(Tuple)
- Nested类型
- 生产使用:分组查询
Tuple类型
Tuple是ClickHouse数据库中的一种数据类型,它允许在一个字段中存储由不同数据类型组成的元组(tuple)。- 元组可以包含任意数量的值,并且每个值可以是不同的数据类型,如
int、float、string、date等。 - 例如,以下是一个
clickhouse Tuple类型的例子:
(1, 'John', 12.5, Date('2021-01-01'))
该元组包含四个值,分别是整数1,字符串’John’,浮点数12.5和日期型数据’2021-01-01’。这些值可以通过索引或字段名来访问。
Tuple类型可以用于存储数据结构复杂的数据,如JSON和XML数据。- 此外,
clickhouse的Tuple类型还可以用于支持复杂的查询和分析操作,例如在SELECT语句中使用子查询或嵌套查询,或在JOIN运算中使用多个字段来匹配复杂的条件等。
Array类型
Array类型表示一个包含多个相同类型元素的数组,可以通过索引访问其中的元素Array类型就不详细讲了,之前写过一篇文章,有兴趣的可以点击看下- 当需要处理数组结构时,可以使用
Array类型,而当需要处理更复杂的数据结构时,可以使用Nested类型 - 通常,
Nested类型比Array类型更加灵活,但是在性能方面可能会稍微慢一些。
Nested类型
ClickHouse中的Nested类型指的是复杂数据类型,它允许将多个数据类型组合成一种数据类型Nested类型支持结构化数组、嵌套映射(Map)和嵌套集合(Set),可以方便地处理非标量类型的数据Nested类型可以用于存储和查询具有嵌套结构的数据,例如JSON和XML格式的数据。它能够支持高效的查询和聚合操作,如对嵌套数组进行平均、求和、最大、最小等操作,对于分析大量结构化数据非常有效。- 在使用
Nested类型时,需要注意其与普通数据类型的不同之处,在查询语句中需要使用嵌套函数或语法。同时需要进行适当的数据类型转换和格式化操作,以确保数据的准确性和一致性。
使用示例
单独使用Tuple
- 具体
SQL如下,包括建表、插入数据、查询 - 需要注意的点:
- 字段为
Tuple类型时,里面要直接是数据类型,即tuple_col Tuple(String, UInt8) - 插入时,只能是单个Tuple数据,不能为复数个,即
(1, ('Alice', 20))
- 字段为
-- 建表
drop table if exists my_table_tuple;
CREATE TABLE my_table_tuple (
id Int32,
tuple_col Tuple(String, UInt8)
) ENGINE = MergeTree ORDER BY id;
-- 插入数据
INSERT INTO my_table_tuple VALUES
(1, ('Alice', 20)),(2, ('Bob', 35)),(3, ('Charlie', 40)),(4, ('David', 45));
-- 查询数据
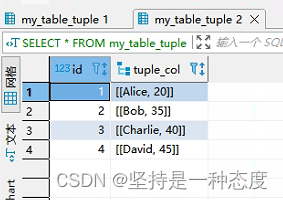
SELECT * FROM my_table_tuple;
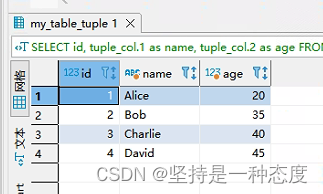
SELECT id, tuple_col.1 as name, tuple_col.2 as age FROM my_table_tuple;
-- 注意,Tuple无法使用ARRAY JOIN,会执行报错
SELECT * FROM my_table_tuple ARRAY JOIN tuple_col;
- 下面2个截图,为上面2个可以执行成功的
SQL的查询结果
数组嵌套 Array(Tuple)
- 数组类型,数组内为
Tuple - 具体
SQL如下,包括建表、插入数据、查询 - 需要注意的点:
- 此时的
Tuple允许定义字段名称,即Tuple( name String, age UInt8) - 插入时,可以是单个Tuple数据,也可以是复数个,即
(1, ['Alice','Bob'], [20, 35]) - 需要注意的是,不能像单个Tuple类型使用时写的
('Bob', 35),而是每个Tuple嵌套类型里的字段,都是一个数组,要作为数组插入 - 插入时,行和行之间的属性的个数可以不一致 ,但是当前行的Nested类型中的字段对应的数组内的数量要一致
- 此时的
-- 新建表
DROP table if exists my_table_array_tuple;
CREATE TABLE my_table_array_tuple (
id Int32,
array_tuple Array(
Tuple( name String, age UInt8)
)
) ENGINE = MergeTree ORDER BY id;
-- 插入数据
INSERT INTO my_table_array_tuple VALUES
(1, ['Alice','Bob'], [20, 35]),
(2, ['Charlie', 'David', 'Tom'], [40, 45, 34]);
-- 这个插入数据的SQL执行失败,无法类似这样插入
INSERT INTO my_table_array_tuple VALUES
(3, [('Alice', 20),('Bob', 35)]),
(4, [('Charlie', 40),('David', 45)]);
-- 查询
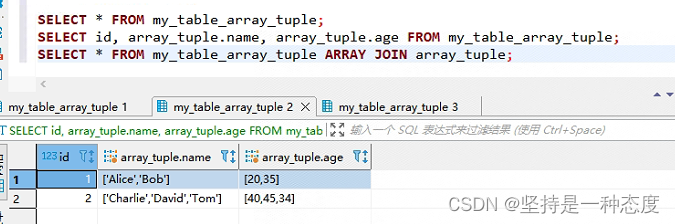
SELECT * FROM my_table_array_tuple;
SELECT id, array_tuple.name, array_tuple.age FROM my_table_array_tuple;
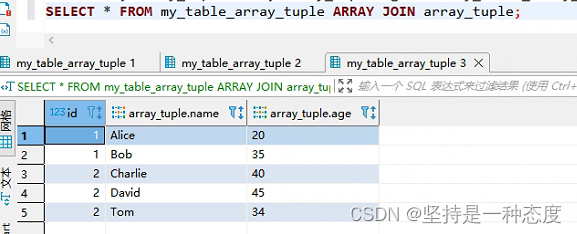
SELECT * FROM my_table_array_tuple ARRAY JOIN array_tuple;
- 上面三个查询SQL的查询结果,截图如下,其中前两个
SQL执行结果一致
- 前两个查询结果为啥一致,为什么插入的时候是插入多个数组,看下
create table执行后的表ddl就很明确了
-- `default`.my_table_array_tuple definition
CREATE TABLE default.my_table_array_tuple
(
`id` Int32,
`array_tuple.name` Array(String),
`array_tuple.age` Array(UInt8)
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 8192;
- 第三条
SQL是使用了ARRAY JOIN,分行展开们我们需要的样子
Nested类型
- 类似
Tuple,但是不一样,Tuple一次只能插入一个元祖,但Nested类型既可以插入一个Nested类型数据,也可以插入多个,用起来感觉类似Array(Tuple) - 具体
SQL如下,包括建表、插入数据、查询 - 需要注意的点:
- 与
Array(Tuple)一样,此时的Nested也允许定义字段名称,即Nested( name String, age UInt8) - 插入数据时,也需要遵循“嵌套类型里的每一个字段对应一个数组”
- 插入数据时,也需要遵循“单条记录内,嵌套类型每一个字段对应的值数量相同”,不同记录数量没有要求
- 与
-- 创建表
drop table if exists movies;
CREATE TABLE movies (
title String,
actors Nested(
name String,
age UInt8
)
) ENGINE = MergeTree()
ORDER BY title;
-- 插入数据
INSERT INTO movies VALUES('Interstellar', ['Matthew McConaughey', 'Anne Hathaway'], [50, 38]);
INSERT INTO movies VALUES('The Dark Knight', ['Christian Bale', 'Heath Ledger', 'Aaron Eckhart'], [47, 28, 52]);
-- 查询
SELECT * FROM movies;
SELECT * FROM movies ARRAY JOIN actors;
-- 查询并求平均年龄
SELECT
title,
avg(actor.age) AS avg_age
FROM
movies
ARRAY JOIN actors AS actor
GROUP BY
title
ORDER BY
title;
- 第一条
SQL的执行结果如下:

- 这里看下使用
Nested类型创建之后表的DDL,可以发现与Tuple没啥区别
-- `default`.movies definition
CREATE TABLE default.movies
(
`title` String,
`actors.name` Array(String),
`actors.age` Array(UInt8)
)
ENGINE = MergeTree
ORDER BY title
SETTINGS index_granularity = 8192;
- 第二条
SQL也是使用了ARRAY JOIN,执行结果如下:
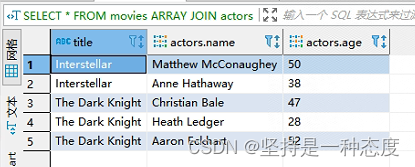
- 第三条
SQL,是查询评价年龄,是对嵌套类型里的一个字段进行运算。除了求平均,其他的函数运算也可以,聚合分组也可以
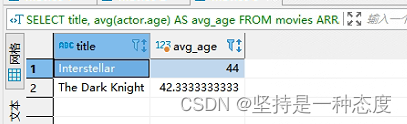
生产使用:分组查询
- 我们的安全指标表,需要存储道路级别安全指标和进口级别安全指标,建表语句(部分)如下:
-- radar.index_cycle_security definition
DROP table if exists radar.index_cycle_security;
CREATE TABLE radar.index_cycle_security
(
`time_stamp` DateTime COMMENT '时间',
`intersection_number` Int32 COMMENT '交叉口编号',
`safety_factor` Float64 COMMENT '安全系数(根据下面4个安全评价参数加权计算,只计算整个路口的)',
`phase_clearance_rate` Float64 COMMENT '相位清空率(路口)',
`pedestrian_time_guarantee_rate` Float64 COMMENT '行人过街时间保障率(路口)',
`pedestrian_illegal_rate` Float64 COMMENT '行人闯红灯违法率(路口)',
`traffic_conflict` Int16 COMMENT '交通冲突次数(车道/方向)',
`approach_index` Array(
Tuple(
`approach` String,
`pedestrian_time_guarantee_rate` Float64,
`pedestrian_illegal_rate` Float64
)
)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(time_stamp)
PRIMARY KEY time_stamp
ORDER BY (time_stamp, intersection_number)
SETTINGS index_granularity = 8192,
old_parts_lifetime = 300,
max_suspicious_broken_parts = 1000;
-- 显示表结构
desc radar.index_cycle_security;
- 现在我的业务查询需求,需要根据进口按列返回,
SQL如下:
SELECT
time_stamp ,
approach_index.approach as approach,
approach_index.pedestrian_time_guarantee_rate as pedestrian_time_guarantee_rate,
approach_index.pedestrian_illegal_rate as pedestrian_illegal_rate
FROM
index_cycle_security ARRAY JOIN approach_index
where time_stamp = '2023-05-09 14:05:52'
order by time_stamp
- 查询时,使用
ARRAY JOIN将嵌套结构分成一个个列,查询结果如下:
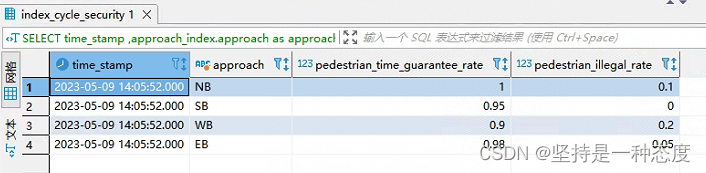
- 我也可以按照时间粒度聚合(使用
toStartOfInterval),之后求平均值,SQL如下:
SELECT
toStartOfInterval(time_stamp , INTERVAL 1 HOUR) as time_stamp2 ,
approach_index.approach as approach,
round(avg(approach_index.pedestrian_time_guarantee_rate), 2) as pedestrianTimeGuaranteeRate,
round(avg(approach_index.pedestrian_illegal_rate), 2) as pedestrianIllegalRate
FROM
index_cycle_security ARRAY JOIN approach_index
where time_stamp > '2023-05-09 14:05:52'
GROUP BY time_stamp2, approach
order by time_stamp2
limit 0,20
- 查询结果如下(由于都是测试数据,结果一样了,结构是可以看的):
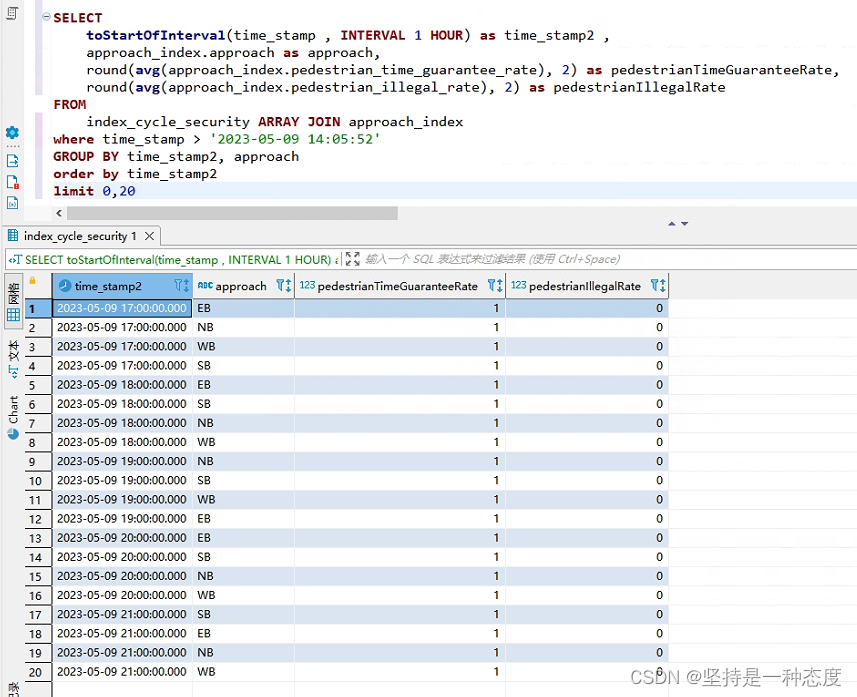
- 看到最后的小伙伴,欢迎评论交流,给个点赞也行