MoreKey案例
大批量往redis里面插入2000W测试数据key
Linux Bash下面执行,插入100W

# 生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;
通过redis提供的管道--pipe命令插入100W大批量数据
结合自己机器的地址:
cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
可通过数据插入测试机器的性能,本次测试100w数据插入redis花费5.8秒左右
某快递巨头真实生产案例新闻
新闻

keys * 你试试100W花费多少秒遍历查询
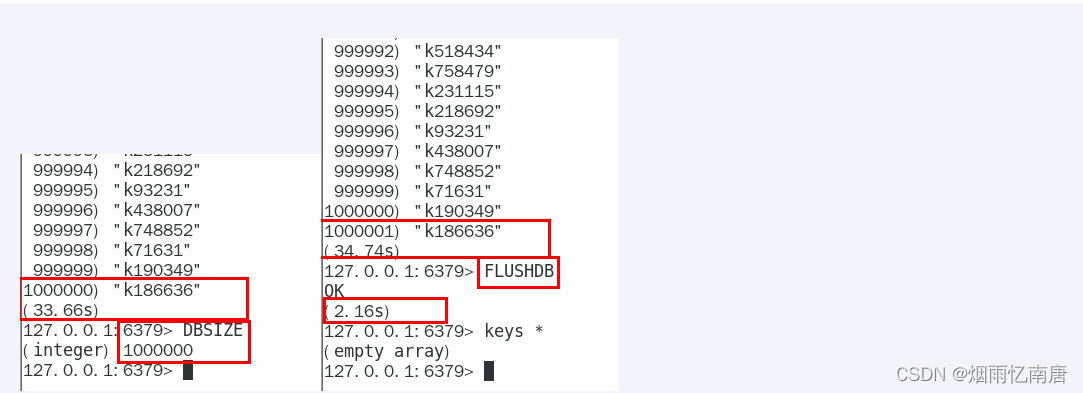
key * 这个指令有致命的弊端,在实际环境中最好不要使用

生产上限制keys */flushdb/flushall等危险命令以防止误删误用?
通过配置设置禁用这些命令,redis.conf在SECURITY这一项中
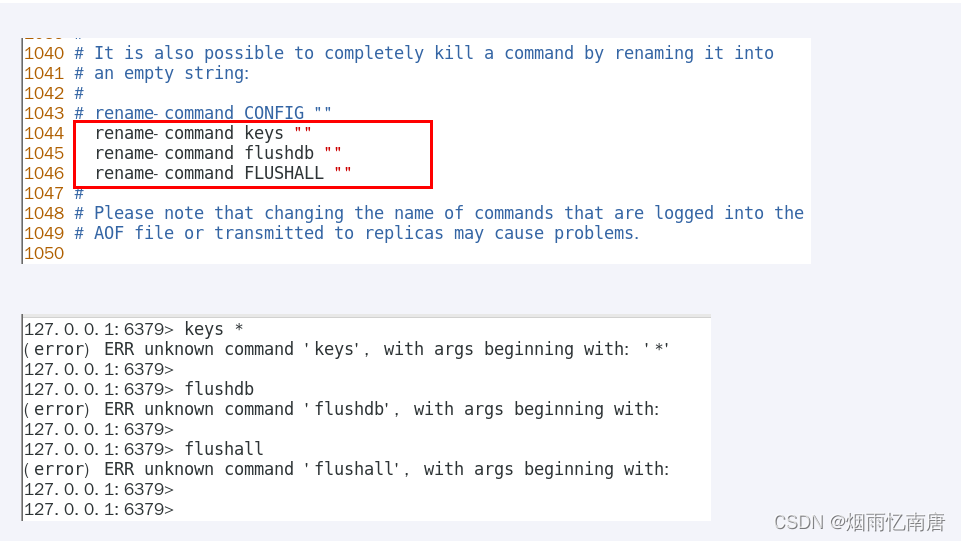
不用keys *避免卡顿,那该用什么
scan命令登场
英文官网
中文官网
一句话,类似mysql limit,但不完全相同
Scan 命令用于迭代数据库中的数据库键
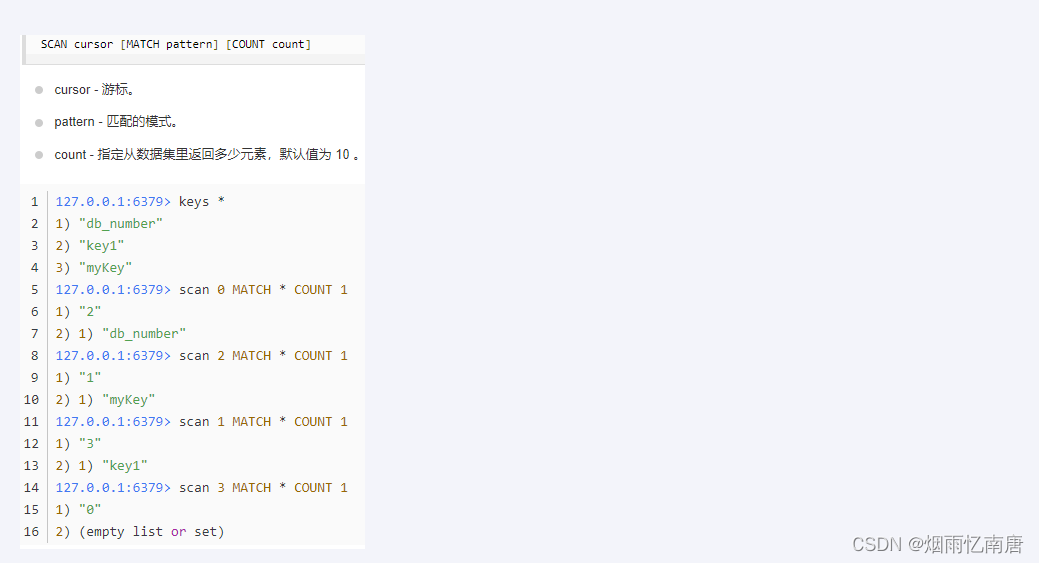
语法

特点

SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组,
第一个元素是用于进行下一次迭代的新游标,
第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
使用
BigKey案例
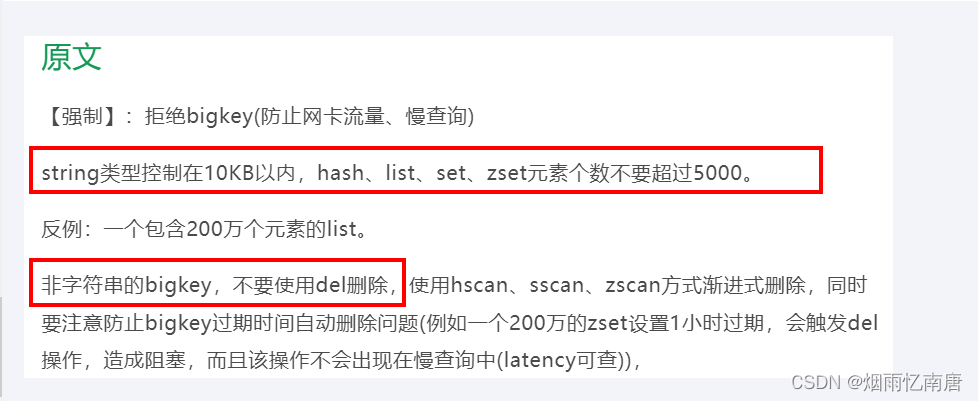
多大算Big
参考《阿里云Redis开发规范》
string和二级结构
string是value,最大512MB但是≥10KB就是bigkey
list、hash、set和zset,个数超过5000就是bigkey(疑问???)

哪些危害
- 内存不均,集群迁移困难
- 超时删除,大key删除作梗
- 网络流量阻塞
如何产生(案例)
社交类:某明星粉丝列表,典型案例粉丝逐步递增
汇总统计:某个报表,月日年经年累月的积累
如何发现
redis-cli --bigkeys
好处,见最下面总结
给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
不足
想查询大于10kb的所有key,--bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
redis-cli --bigkeys -a 111111
|
redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys
|
| 每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
|

MEMORY USAGE 键
计算每个键值的字节数

官网
如何删除
参考《阿里云Redis开发规范》
官网
普通命令
String
一般用del,如果过于庞大unlink
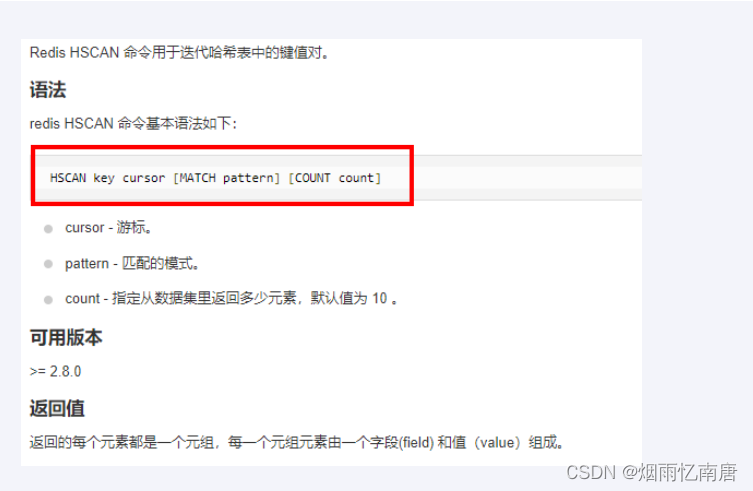
hash
使用hscan每次获取少量field-value,再使用hdel删除每个field
命令
阿里手册
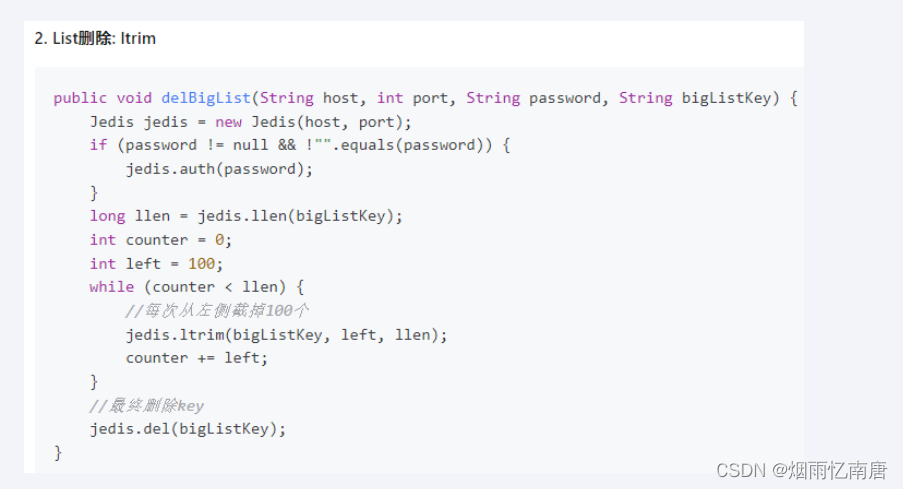
list
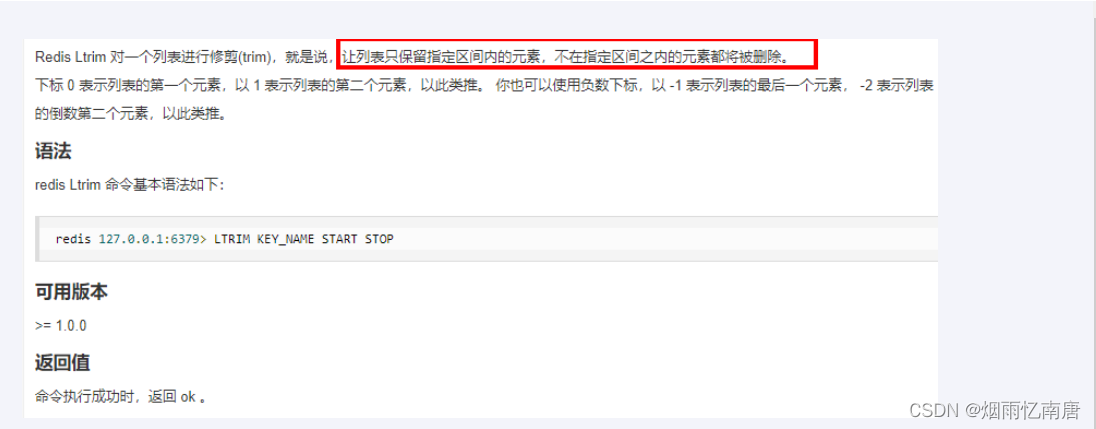
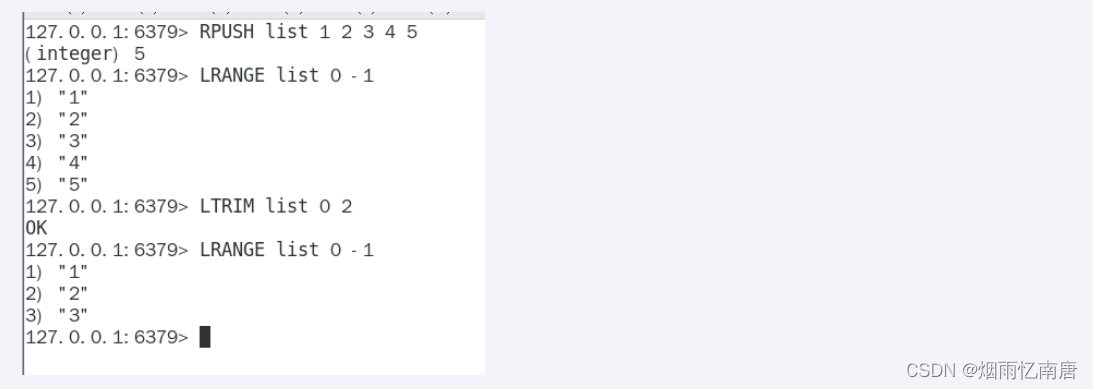
使用ltrim渐进式逐步删除,直到全部删除完成
命令
阿里手册
set
使用sscan每次获取部分元素,再使用srem命令删除每个元素
命令

阿里手册

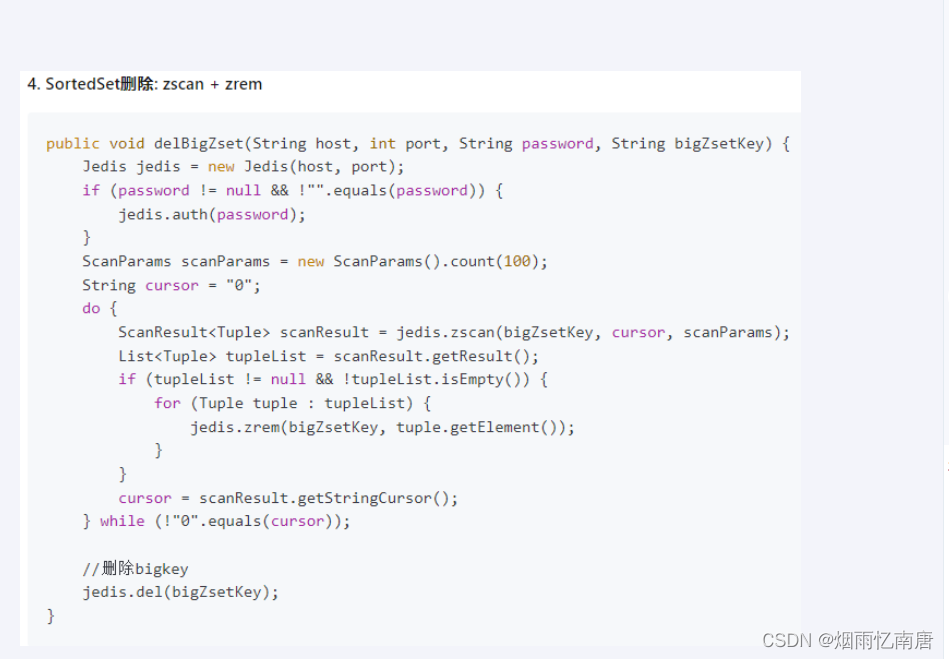
zset
使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素
命令

阿里手册
BigKey生产调优
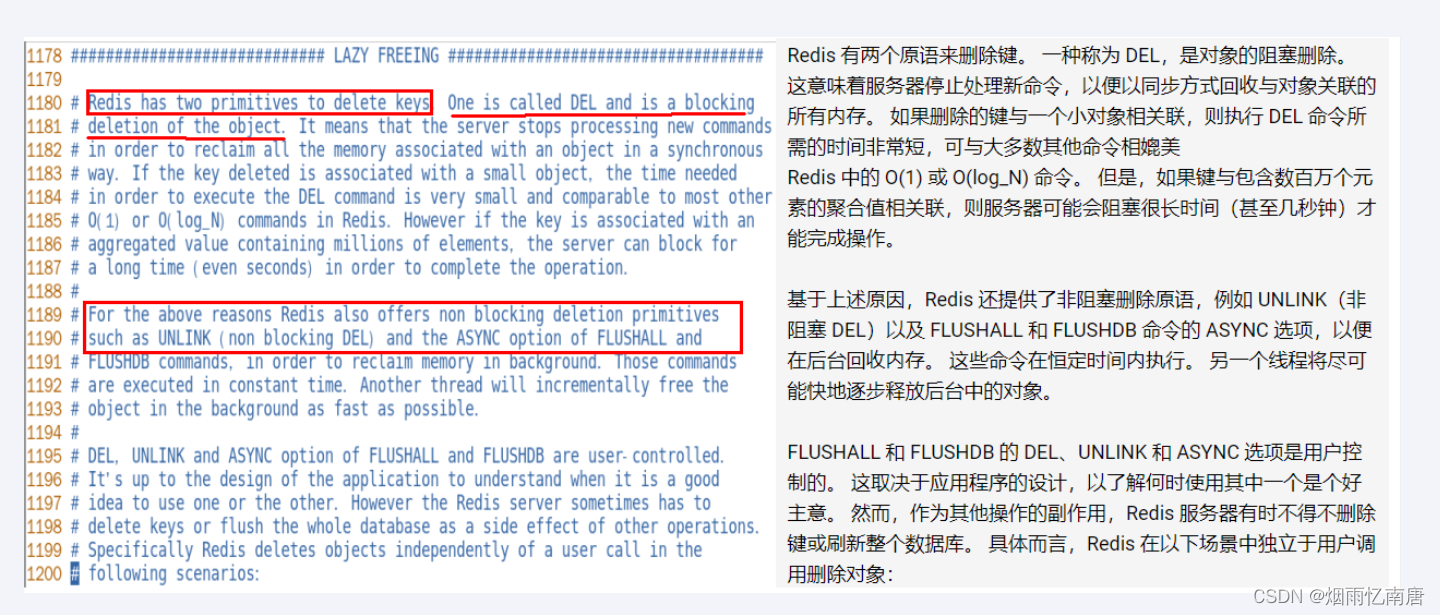
redis.conf配置文件LAZY FREEING相关说明
阻塞和非阻塞删除命令
优化配置
惰性释放
都说 redis 是单线程的,其实并不是说 redis 只有一个线程,单线程指的是 所有的执行命令在一个线程中进行,这个线程也就是主线程,不过它还存在其他后台线程,比如关闭文件后台线程,AOF 日志同步写回后台线程,惰性删除执行内存释放后台线程等。
因为执行命令只在主线程中进行,这就要求单个命令的执行时间不能太长,否则会影响后续执行命令的响应时效性。在发生数据删除的时候,当然也要避免对主线程长时间的阻塞,下面就来讨论下如何避免数据删除给主线程造成的阻塞影响。
数据删除场景
涉及到数据删除的场景有很多,盘点有如下场景:
场景一:客户端执行的显示删除/清除命令,比如 del,flushdb 等;
场景二:某些指令带有的隐式删除命令,比如 move , rename 等;
场景三:到达过期时间的数据需要删除;
场景四:使用内存达到 maxmemory 后被选出来要淘汰的数据需要删除;
场景五:在主从同步全量同步阶段,从库收到主库的 RDB 文件后要先删除现有的数据再加载 RDB 文件;
而这些删除场景其实都存在阻塞主线程的风险:
big-key 带来的阻塞风险:在删除单个键值对的场景下,如果这个键值对小一般没什么问题,但是如果要删除的是一个 big-key,阻塞时间可能比较长,这对于响应时效性要求高的场景是不可以接受的;
同时删除多个 key 带来的阻塞风险:即使没有 big-key 的存在,如果同一时间要删除的是多个键,阻塞时间也不可忽略。
要怎么避免阻塞主线程?
首先,在使用上肯定要避免 big-key 的存在,它带来的影响不仅仅是在数据删除时存在阻塞风险, 在 AOF 文件的重写,RDB 文件的生成中都存在阻塞风险。
其次,对于同时删除多个 key 的需求,在主动删除的场景下,我们其实是有办法的 -- 分批删除,比如对于一个大的集合,我们可以通过 scan 以循环的方式每次扫描 100 个键然后删除,对于多个 key 的删除,就直接按 key 分批处理就行了,虽然是麻烦了点,却是可以保证不对主线程造成影响;然而分批删除却没法应用于被动删除的场景。
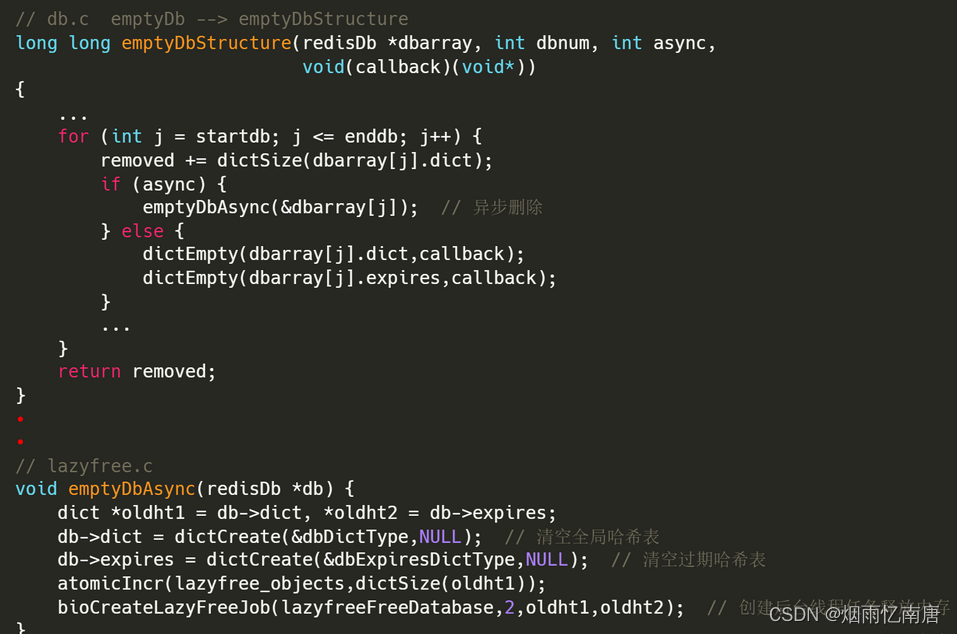
为了解决以上问题,在 redis 4.0 以后,redis 新增了异步删除的功能 : lazy free,也叫 惰性删除,它可以 将 “数据删除” 放到后台线程中去执行,进而避免对主线程的阻塞。
lazy free
概念
redis 是用 c 语言实现的,而我们知道 c 语言是没有垃圾回收的,也就说对于程序申请的内存是需要程序来释放的,因此,在 redis 中删除数据包含两个步骤:
步骤一:将待删除数据对从字典表中删除;
步骤二:释放待删除数据所占用的内存空间。
如果这两个步骤同步执行,就叫 同步删除;而如果只执行步骤一,将来通过后台线程来执行步骤二,就叫 异步删除。而惰性删除 里的惰性其实指的就是 删除时只执行步骤一,而将步骤二 "延迟" 到后台线程执行。
配置
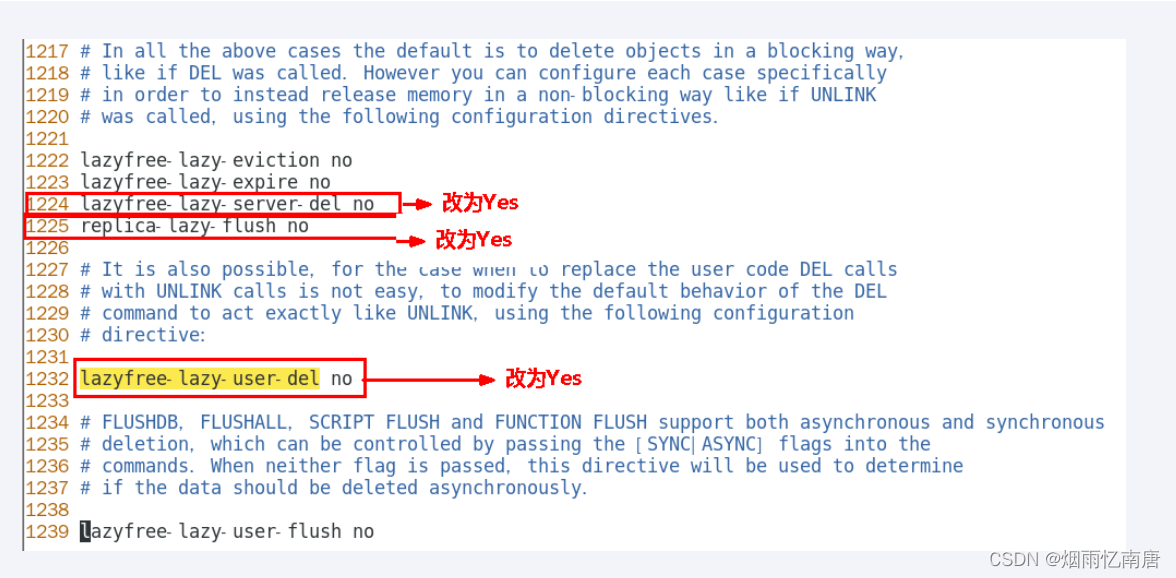
对应到之前盘点的删除场景,redis 提供了对应的配置项来控制对应场景下是否启用惰性删除:
lazyfree-lazy-user-del / lazyfree_lazy_user_flush (6.0 新增): 对应场景一显示删除/清除命令场景;
lazyfree-lazy-server-del:对应场景二会隐式进行删除操作的命令执行场景;
lazyfree-lazy-expire:对应场景三过期数据的删除场景;
lazyfree-lazy-eviction:对应场景四缓存淘汰时的数据删除场景。
replica-lazy-flush:对应场景五从节点完成全量同步后,删除原有旧数据的场景。
但你要知道的是,即使开启了惰性删除,并不代表着就一定会执行异步删除,redis 还会先评估删除开销,如果开销较小,会直接做同步删除。
源码剖析(版本 6.2.6)
删除数据包含的两个步骤在源码中合在一个函数里: dictGenericDelete() 函数,通过参数 nofree 来控制是否执行步骤二:
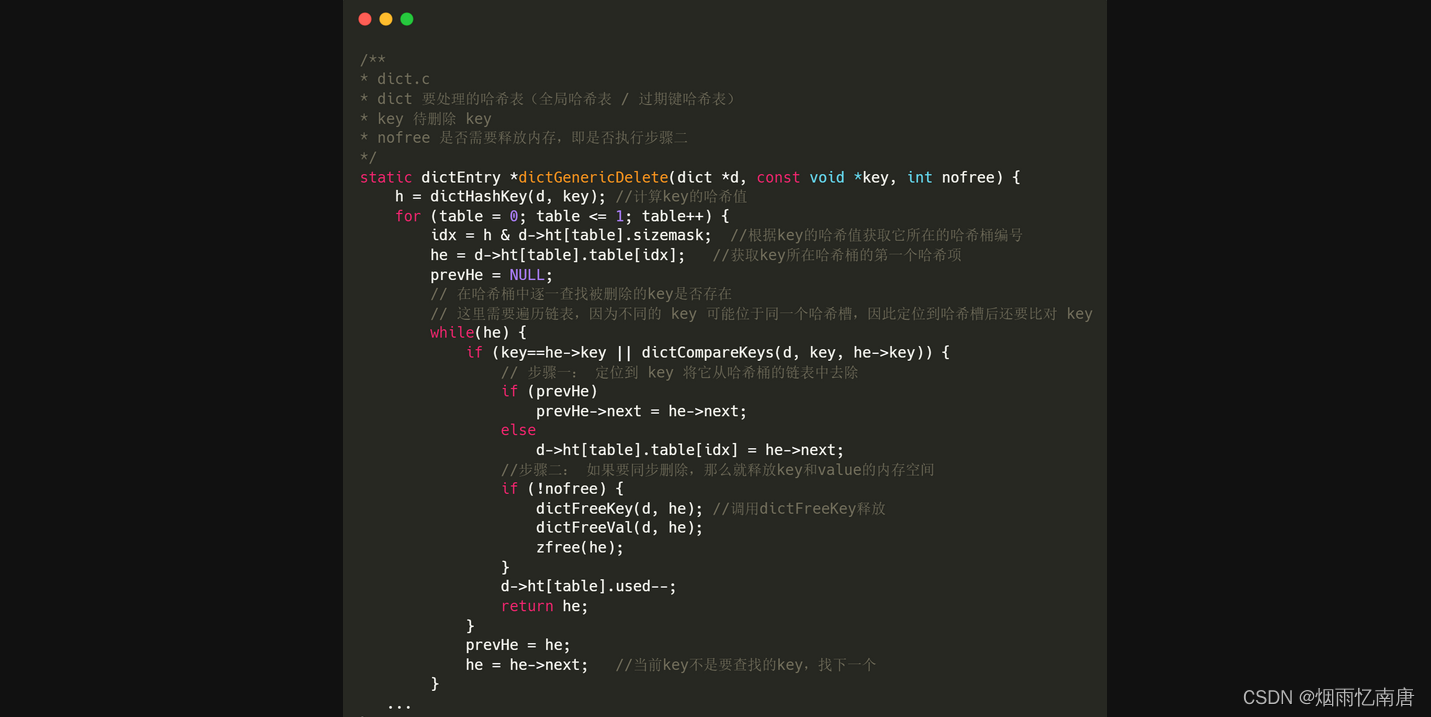
删除逻辑比较简单:首先根据 key 值定位到哈希桶,哈系桶存储的是一个链表,所以还要沿着这个链表逐个比对 key 值;找到 key 以后,首先执行步骤一,将 key 从链表中删除,然后根据参数 nofree 决定是否要执行步骤二,如果 nofree = 0,则执行步骤二,如果 nofree= 1,则不执行。
在该函数的基础上,redis 又提供了两个封装函数 dictDelete 和 dictUnlink:

两个函数都调用 dictGenericDelete() 执行删除,区别就是 nofree 的值不同,以后删除 key 的时候只会调用这两个函数。
场景一:客户端执行的显示删除/清除命令
DEL / UNLINK 命令
两个命令都是通过调用 delGenericCommand() 函数来执行删除的,是否执行惰性删除取决于函数的 lazy 参数:UNLINK 命令传递固定值 1;而 DEL 命令则是传递的配置项 lazyfree_lazy_user_del (6.0 新增)。
代码很简单: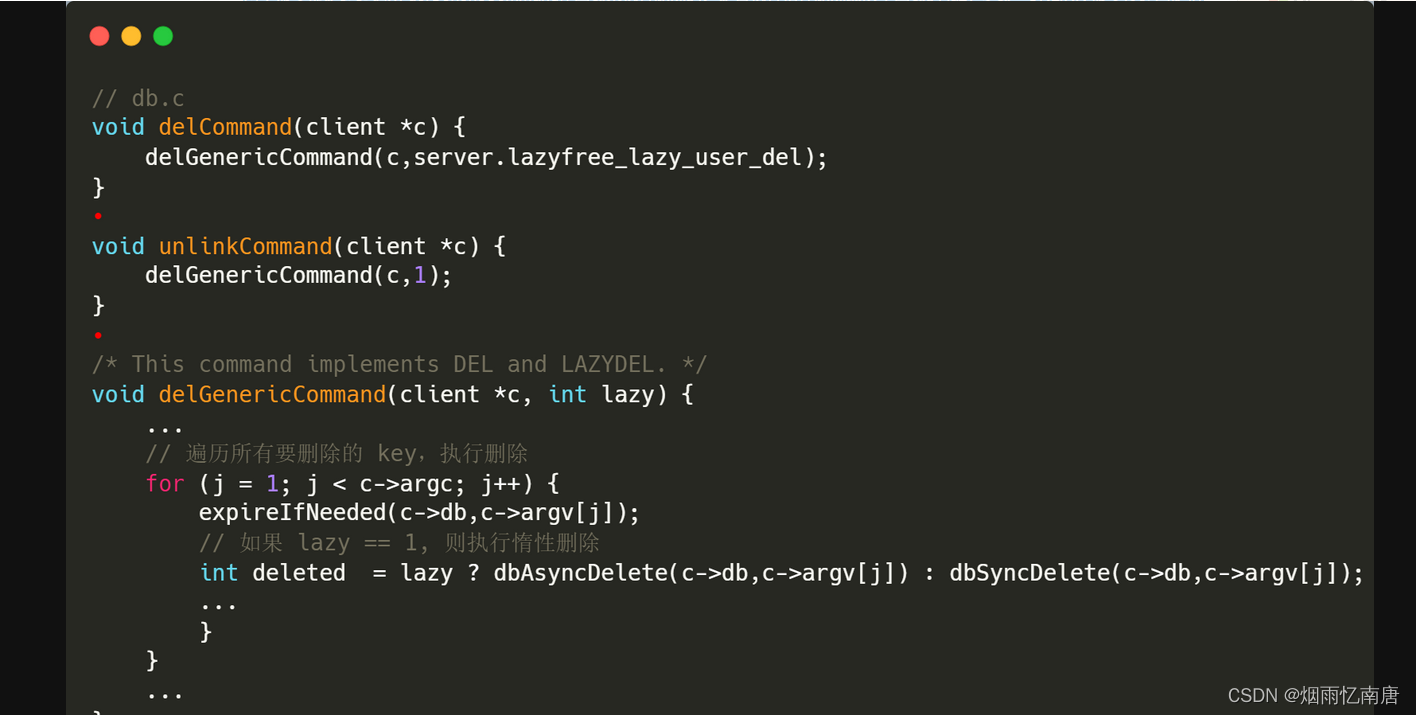
如果 lazy = 1,则调用 dbAsyncDelete() 执行惰性删除, 否则调用 dbSyncDelete() 执行同步删除,继续看下 dbAsyncDelete() 是怎么执行惰性删除的:
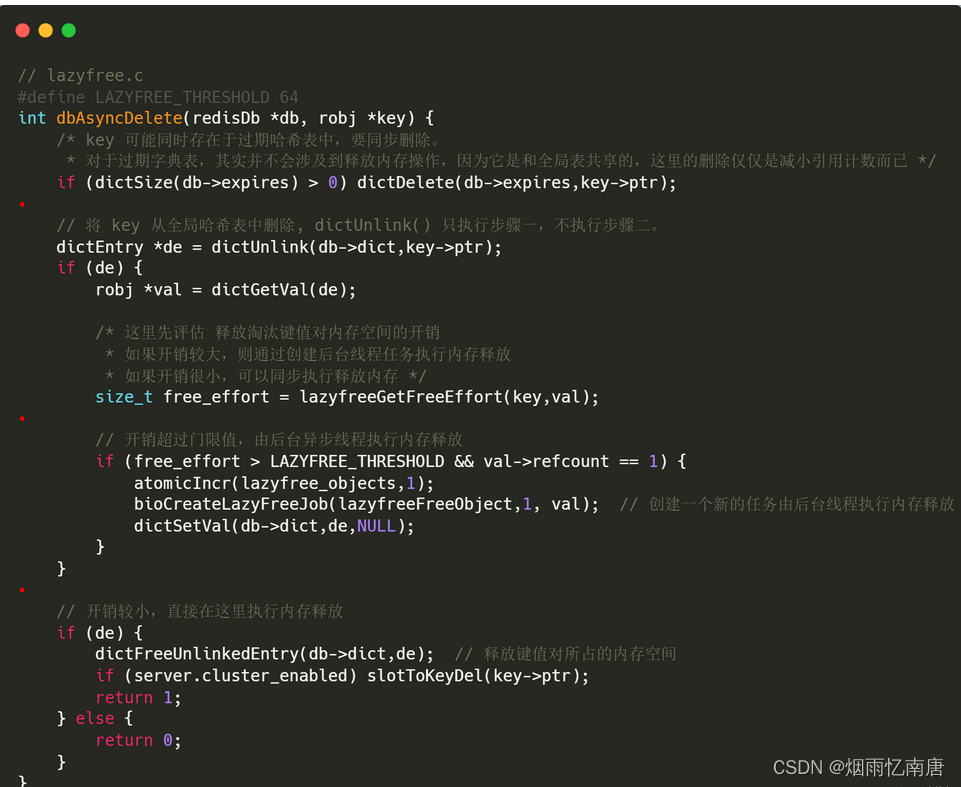
惰性删除包含三步操作:
调用 dictDelete() 从过期表中删除数据,从过期表中删除数据只会减小引用计数,不会真正删除数据;
调用 dictUnlink() 从全局表中删除数据,该函数只执行步骤一,不执行步骤二,即不会释放待删除数据的占用内存;
调用 lazyfreeGetFreeEffort() 评估释放内存开销,如果开销超过门限值 LAZYFREE_THRESHOLD(默认 64),则通过 bioCreateBackgroundJob() 创建一个新的删除任务,由后台线程来执行内存释放;如果开销较小,则直接调用 dictFreeUnlinkedEntry() 函数执行内存释放。
可以看到,即使开启了惰性删除,在实际执行过程中,redis 也会先评估删除数据的开销,然后再决定是执行异步删除还是同步删除。
我们继续看下 lazyfreeGetFreeEffort() 函数是怎么评估删除开销的:
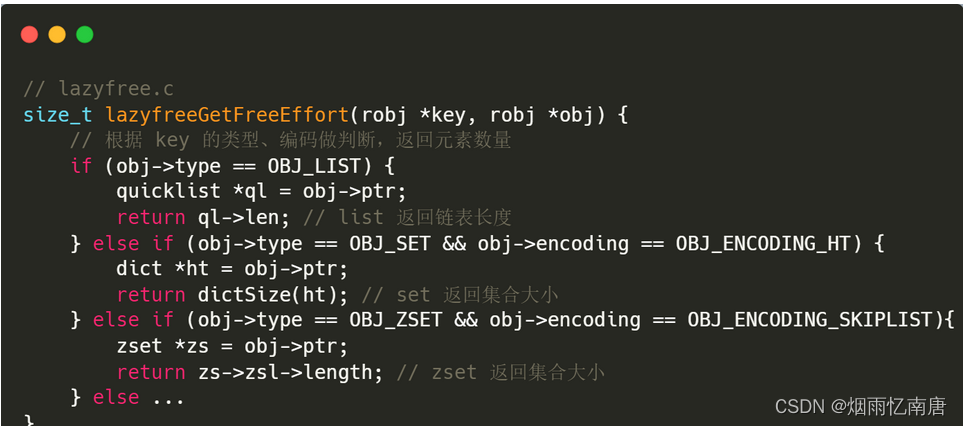
可以看到,当键值对类型属于List、Hash、Set 和 Sorted Set,并且没有使用紧凑型内存结构来保存的时候,这个键值对的删除开销就等于集合中的元素个数,不属于以上情况的删除开销就等于1。也就是说,即使开启了惰性删除,针对 String(不管内存占用多大)、List(少量元素)、Set(int 编码存储)、Hash/ZSet(ziplist 编码存储)这些情况下的 key,在对删除数据做开销评估时因为小于门限值,依旧会在主线程中进行同步删除。
此外,你可能注意到, delGenericCommand() 在执行删除前还调用了函数 expireIfNeeded(),从名字来看它是用来判断 key 是否已经过期的,此时你是否有疑问,为什么这个 key 都要被删除了,还要判断它是否已经过期呢?不是直接删除就好了吗?
我们进入这个函数看看:
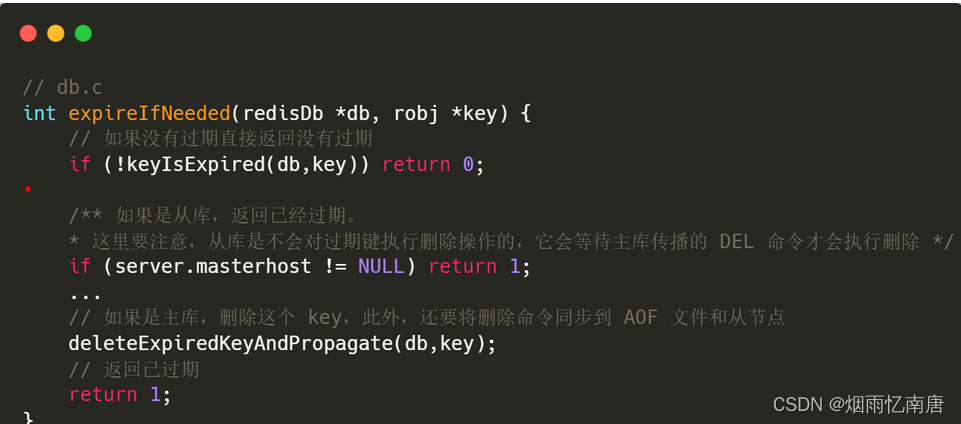
函数很简短:
- 先判断是否过期,如果没有过期,直接返回 0 表示没有过期;
- 如果已经过期,继续判断是否是主库,如果不是主库,直接返回已过期;
- 如果已经过期且是主库,继续调用 deleteExpiredKeyAndPropagate():
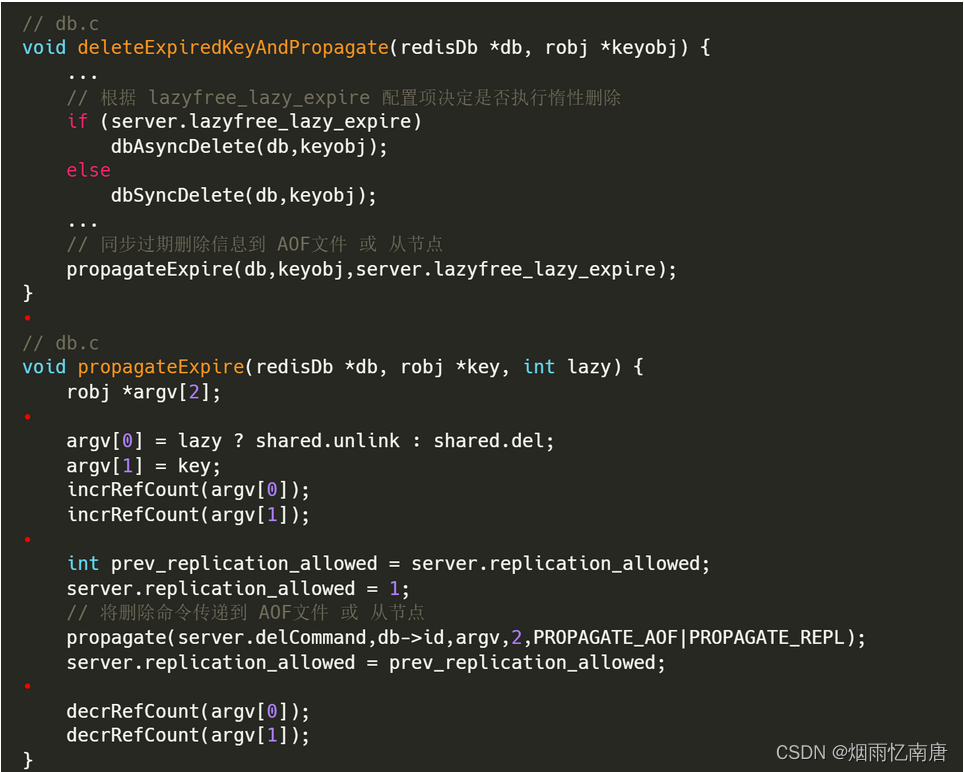
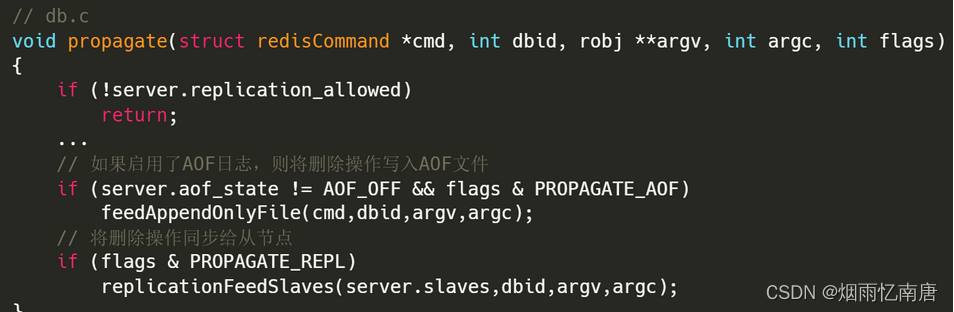
deleteExpiredKeyAndPropagate() 先根据配置项 lazyfree_lazy_expire 来决定是否执行惰性删除,这个其实属于场景三过期键删除的一种方式,这个待会我们再分析。现在我们只需要知道,在执行删除命令的时候,也会先判断这个 key 是否已经过期,如果已经过期,则会按照过期键删除的策略对 key 进行删除;然后它还会继续调用 propagateExpire() 函数将删除动作传递到 AOF文件 或 从节点。
所以,从这个过程我们又了解到,在执行删除命令的时候,redis 会优先判断 key 是否已经过期,如果 已经过期且是主库,则按照过期键删除策略对 key 进行删除,然后还要将同步删除命令到 AOF文件 和 从节点。而对于从库上的删除操作,即使已经过期,也不会做过期处理。
为什么要区分主从库
因为 redis 主从模式采用的是读写分离方式,也就是说 从库只进行读操作,所有的数据修改都应该交由主库发送同步命令。因此,如果删除命令发生在主库,要先检测 key 是否过期,如果过期要将过期的 key 同步一个删除命令到 AOF 文件和从库,同步到 AOF 文件是为了以后做恢复时保证数据一致性,而同步到从节点当然是为了保证主从一致性;而如果发生在从库,可以认为该命令是从主库同步过来的,只要将数据删除即可。
最后,我们也顺便看下同步删除 dbSyncDelete() 函数,逻辑很简单,直接看下源码注释就可以了。
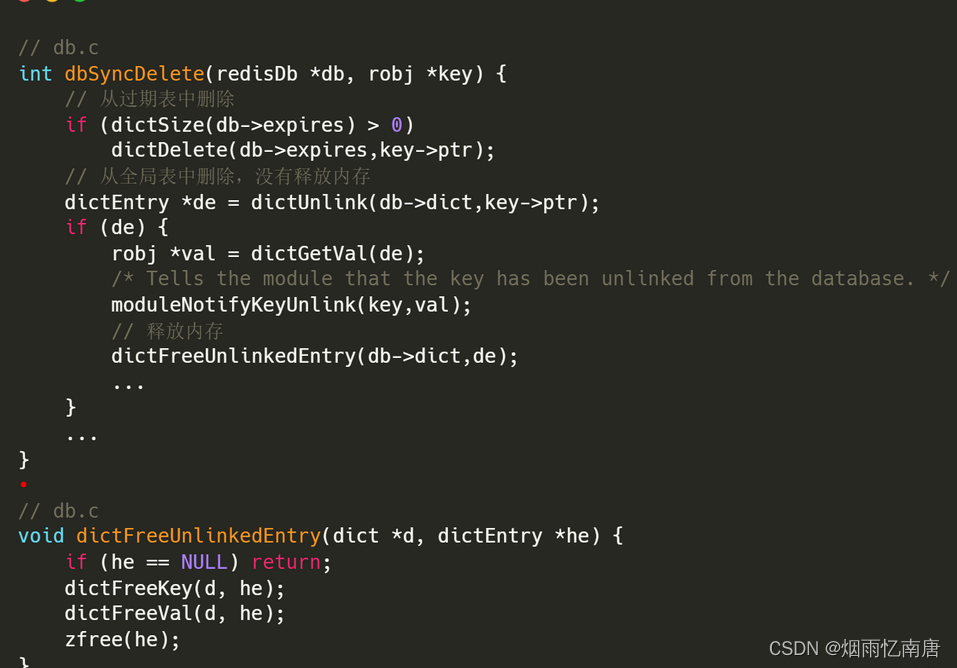
到此为止,整个删除命令的执行过程全部结束了,这个过程讲的特别详细,其实它包含了后面其他场景都会涉及到的一些共有的逻辑,后续我们看其他的删除场景的时候会看到有很多函数都在这里出现过,所以理清这一个过程后,看其他的就会比较简单了。
这里画了一个流程图描述整个删除过程,可以参考下:

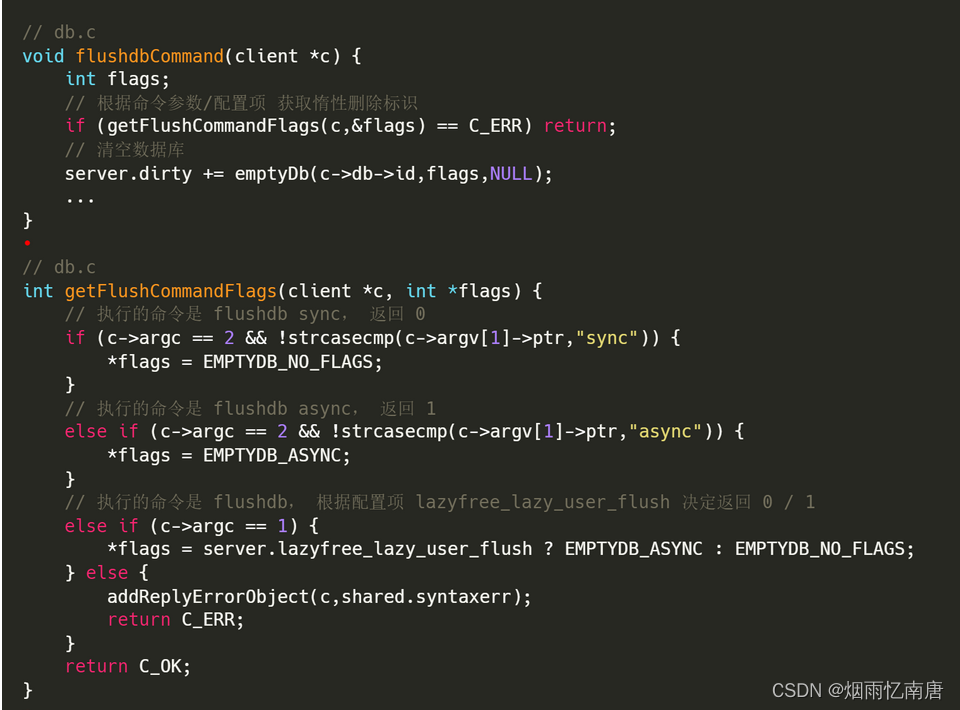
flushdb [sync/async] 命令
这个命令本身可以通过参数 sync/async 来指定是否执行惰性删除;如果没有携带参数执行,它才会根据配置项 lazyfree_lazy_user_flush 来决定删除策略。过程很简单:
1、 根据命令参数/配置项 获取惰性删除标识;
2、根据删除标识决定是否采用异步删除的方式清空数据库。
场景二:某些指令带有的隐式删除命令
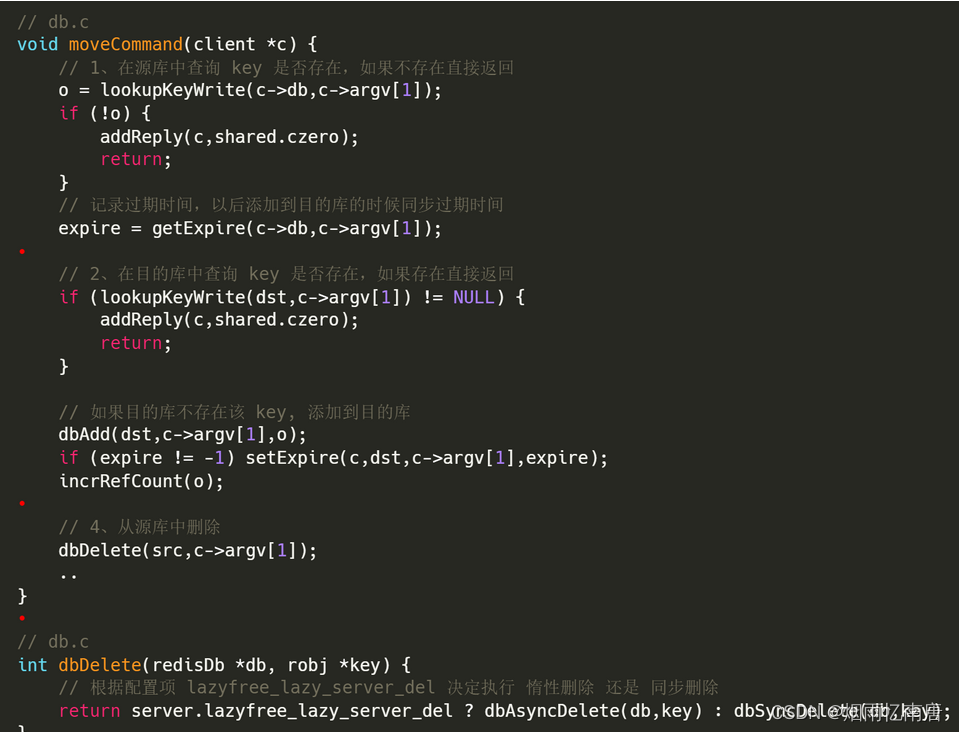
以 move 命令为例,看下执行过程:
在 源库中查询 key 是否存在,如果不存在直接返回;
在目的库中查询 key 是否存在,如果存在直接返回;如果不存在则添加到目的库;
从源库中删除。根据配置项 lazyfree_lazy_server_del 决定执行 惰性删除还是同步删除。
在以上第一步和第二步调用 lookupKeyWrite() 函数查询 key 的过程中,其实也会调用到 expireIfNeeded() 函数来判断是否过期并做相应的处理,忘记了的也可以回头去看看处理过程。
场景三:删除过期数据
针对过期数据的删除,redis 提供两种删除策略:
请求时删除:执行命令时,先检查 key 是否过期,若过期则删除,反之继续操作;
定期删除:每隔一段时间,检查并删除已过期的 key。
分别看下两种策略下是如何执行删除的:
请求时删除
我们在之前的删除命令中已经看到过请求时删除的调用时机,你还记得吗?其实就是 expireIfNeeded() 函数的调用时机,在这个函数里面就是根据配置项 lazyfree-lazy-expire 来决定是否执行惰性删除的 。
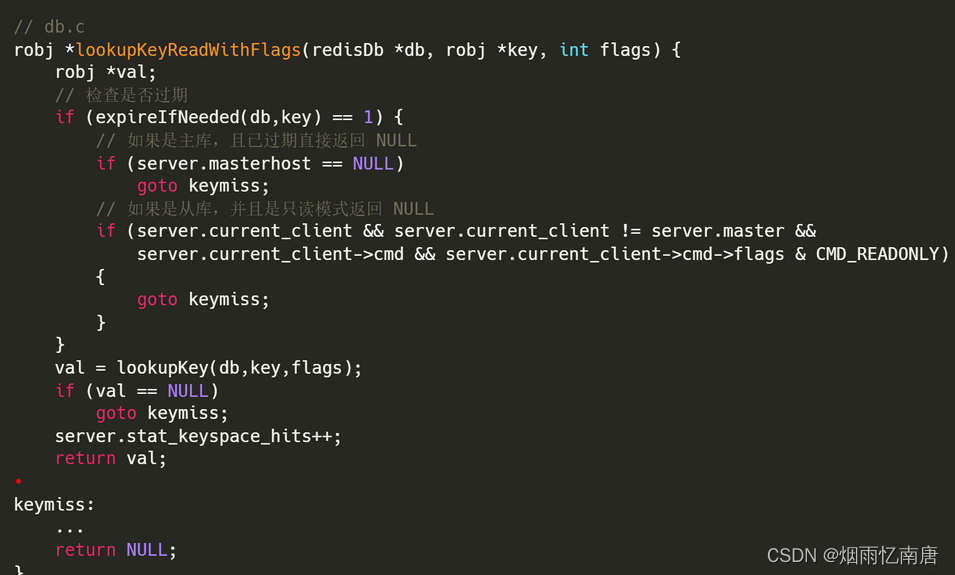
这里我们再以查询一个 key 为例看下:在对某个 key 执行查询时,会调用到 lookupKeyReadWithFlags() 函数,它首先就会调用 expireIfNeeded() 函数来查询这个 key 是否已经过期,有区别是,这里接收了该函数的返回值,通过返回值判断 key 是否已经过期:
对于主库, expireIfNeeded() 函数会执行删除操作,然后同步删除命令到 AOF 文件和从库,最后返回 key 已过期, lookupKeyReadWithFlags() 判断 key 已过期,返回客户端 key 不存在;
对于从库,expireIfNeeded() 只检测到 key 已过期就直接返回, 然后 lookupKeyReadWithFlags() 判断 key 已过期,返回客户端 key 不存在; 也就是说,对于从库而言,即使这个过期键还存在于数据库(它还再等待主库同步过来的删除命令),也会返回客户端 key 不存在。
从这里我们看到 redis 真的是超级精细了,即使主从库在数据同步上存在一定的延迟性,但是通过区分读写操作可以尽量保证在读操作上的数据准确性。
定期删除
定期删除位于主循环中,在 beforeSleep() 函数中调用 activeExpireCycle() 函数,这个函数的主要作用是:在一定的时间内,从过期字典中随机的选出一定量的过期键,调用 activeExpireCycleTryExpire() 函数执行删除。

场景四:内存淘汰数据删除
当使用内存达到 maxmemory 后,redis 会根据配置的内存淘汰策略选出一定量的数据进行删除,关于数据淘汰相关知识可以看下 Redis 缓存淘汰策略以及 LRU、LFU 算法 。
现在我们先想想内存淘汰的执行时机,其实比较容易想到,就是处理命令之前要先检查内存是否查过最大限制,所以我们直接去到 processCommand() 函数:
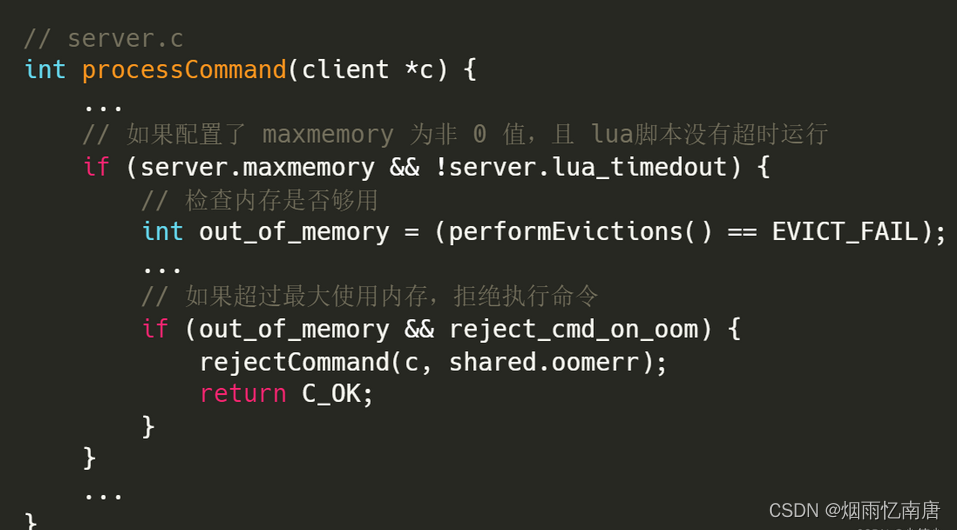
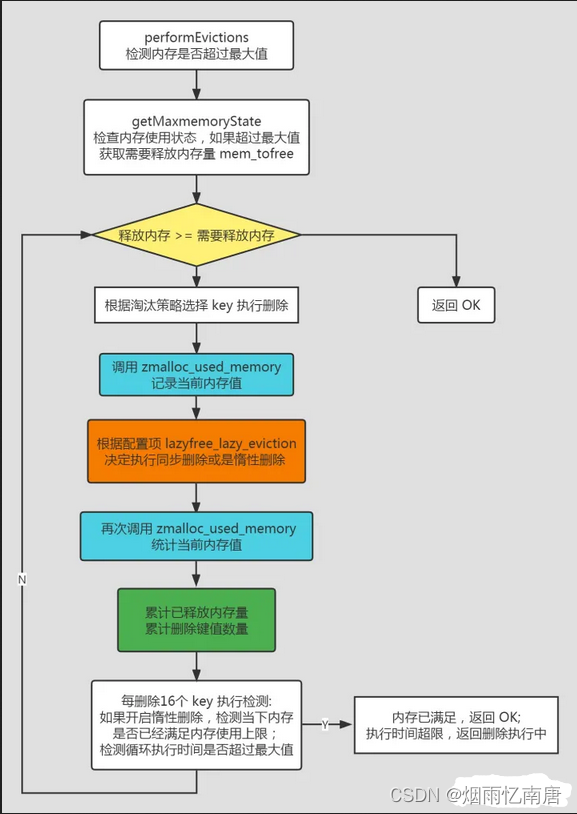
可以看到,该函数会调用 performEvictions() 函数来检测是否超过最大使用内存,如果已经超过最大值,就会拒绝执行命令直接返回,继续看看是怎么检测的:
过程稍微有点长,分为以下步骤:
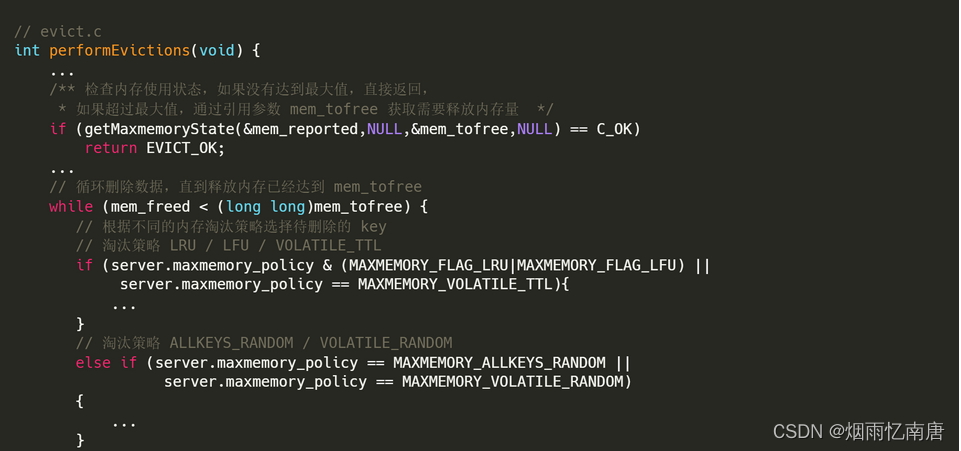
首先检查目前的内存使用状态,如果没有达到最大值,直接返回,如果超过最大值,调用 getMaxmemoryState() 获取需要释放内存量 mem_tofree ;
循环地删除数据,直到释放内存达到需要释放的内存量或者时间执行时间超过限制。
循环过程:
根据不同的内存淘汰策略选择待删除的 key;
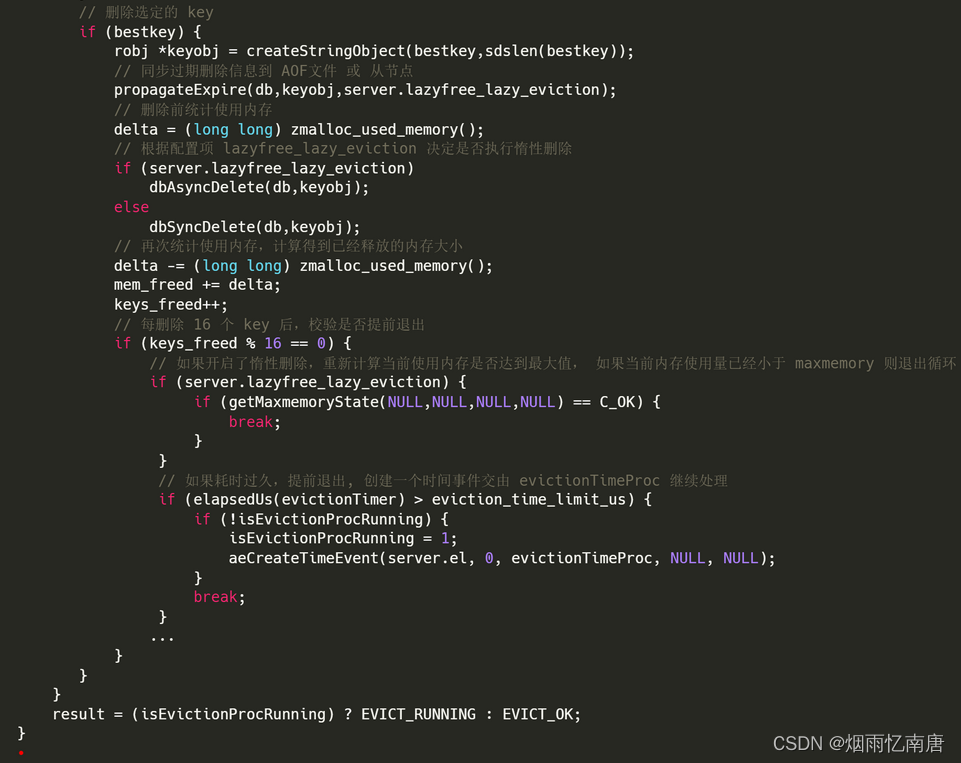
在删除前调用 zmalloc_used_memory() 函数获取当前的使用内存值;
调用 propagateExpire() 函数检查该 key 是否过期,如果过期要同步删除命令到 AOF 文件 和 从库;
删除数据,根据配置项 lazyfree_lazy_eviction 决定是否执行惰性删除;
再次调用 zmalloc_used_memory() 函数获取当前使用内存,减去删除前记录的内存值得到已经释放的内存大小;
累计已经释放的内存量 mem_freed,累计删除 key 值数量 keys_freed;
每删除16个 key 后,做提前退出检查:如果开启了惰性删除,再次调用 getMaxmemoryState() 校验当前使用内存是否已经没有超过 maxmemory,如果 已经满足则退出循环;检查循环执行时间,如果执行时间超过限制值,也提前退出,由 evictionTimeProc 后台删除。
整个过程有 4 个地方统计了当前使用内存:
第一次是为了获取要释放的内存量;
第二次和第三次分别位于对某个key 进行删除的前后调用,因为如果开启了惰性删除,删除数据可能是在异步线程中执行的,因此不能直接获取删除的内存大小,需要通过在删除数据的前后都获取当前使用内存然后计算差值得到已经释放的内存量;
第四次也是在执行删除函数后检测的,这里也是考虑了异步删除可能在某个时间点删除数据后已经满足了最大内存使用值,所以可以提前退出循环。
这里也画了一个流程图,可以参考下:
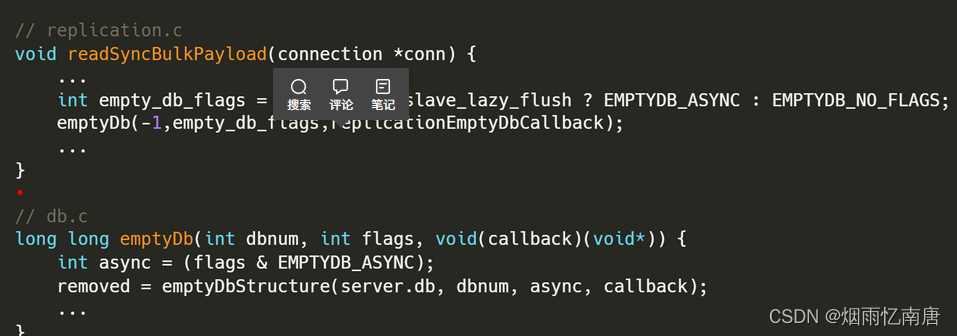
场景五:主从同步清空从库
主从同步本身是一个比较复杂的过程,我们这里只简单了解下异步删除的配置,不做过多介绍了。
小结
本文主要介绍了 redis 删除数据的过程,因为 redis 单线程处理命令的特性,要求所有的执行命令都不能耗时太久,而删除数据也是在主线程中执行的,因此我们要避免删除数据对主线程造成长时间的阻塞。
我们首先盘点了所有涉及到删除数据的场景,分析了各场景对主线程的阻塞可能性,了解到 big key 和 大量key 被动删除的时候没有办法在同步删除的条件下避免阻塞,然后通过引入 redis 4.0 提供的 lazy free 惰性删除特性来解决问题。
在讲惰性删除机制前,我们讲到 redis 删除数据是分为两个步骤的: 从字典表中删除数据 和 释放数据占用内存。
然后介绍惰性删除,我们了解到 lazy free 不是默认开启的,此外,对于不同场景存在对应的配置项,我们需要分别开启对应的配置项才能在对应的场景下开启惰性删除,惰性删除可以将内存释放动作放到后台线程中执行,不会阻塞主线程。
最后,我们阅读了每个删除场景的源码,通过阅读源码得知:即使开启了惰性删除,redis 也不一定就会执行异步删除,它会先评估内存释放开销,如果开销很小,则会直接在主线程对删除数据执行内存释放,如果开销超过门限值,才会创建一个新任务由后台线程执行内存释放。这里需要特别注意的是,评估开销中对于 string 类型的 key 比较特殊,因为它不管 value 多大,开销都是 1,所以我们一定要避免这种类型的大值存在。
此外,我们也了解了 redis 对于过期键的优雅处理,不仅区分了主从库的差异,还会根据对 key 执行的是写操作还是读操作进行分别处理。
面试题
阿里广告平台,海量数据里查询某一固定前缀的key?
小红书,你如何生产上限制keys */flushdb/flushall等危险命令以防止误删误用?
美团,MEMORY USAGE 命令你用过吗?
BigKey问题,多大算big?你如何发现?如何删除?如何处理?
BigKey你做过调优吗?惰性释放lazyfree了解过吗?
Morekey问题,生产上redis数据库有1000W记录,你如何遍历?key *可以吗?
。。。