Redis的事务
什么是Redis的事务
+Redis的事务是一个单独的隔离操作,事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断,所以Redis事务是在一个队列中,一次性、顺序性、排他性地执行一系列命令。
Redis 事务的主要作用就是串联多个命令防止别的命令插队。
Redis事务的相关命令
Redis事务相关的命令主要有以下几种:
- DISCARD:命令取消事务,放弃执行事务队列内的所有命令,恢复连接为非 (transaction) 模式,如果正在使用 WATCH 命令监视某个(或某些) key,那么取消所有监视,等同于执行命令 UNWATCH 。
- EXEC:执行事务队列内的所有命令。
- MULTI:用于标记一个事务块的开始。
- UNWATCH:用于取消 WATCH命令对所有 key 的监视。如果已经执行过了EXEC或DISCARD命令,则无需再执行UNWATCH命令,因为执行EXEC命令时,开始执行事务,WATCH命令也会生效,而 DISCARD命令在取消事务的同时也会取消所有对 key 的监视,所以不需要再执行UNWATCH命令了
- WATCH:用于标记要监视的key,以便有条件地执行事务,WATCH命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。
Redis事务执行的三个阶段
- 开始事务(MULTI)
- 命令入列
- 执行事务(EXEC)
Redis事务的特性
- Redis事务不保证原子性,单条的Redis命令是原子性的,但事务不能保证原子性。
- Redis事务是有隔离性的,但没有隔离级别,事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。(顺序性、排他性)
- Redis事务不支持回滚,Redis执行过程中的命令执行失败,其他命令仍然可以执行。(一次性)
Redis事务为什么不支持回滚?
在Redis的事务中,命令允许失败,但是Redis会继续执行其它的命令而不是回滚所有命令,是不支持回滚的。
主要原因有以下两点:
-
Redis 命令只在两种情况失败:
-
- 语法错误的时候才失败(在命令输入的时候不检查语法)。
- 要执行的key数据类型不匹配:这种错误实际上是编程错误,这应该在开发阶段被测试出来,而不是生产上。
-
因为不需要回滚,所以Redis内部实现简单并高效。(在Redis为什么是单线程而不是多线程也用了这个思想,实现简单并且高效)
Redis的集群、主从、哨兵
Redis集群的实现方案有哪些?
在说Redis集群前,先说下为什么要使用Redis集群,Redis单机版主要有以下几个缺点:
- 不能保证数据的可靠性,服务部署在一台服务器上,一旦服务器宕机服务就不可用。
- 性能瓶颈,内存容量有限,处理能力有限
Redis集群就是为了解决Redis单机版的一些问题,Redis集群主要有以下几种方案
- Redis 主从模式
- Redis 哨兵模式
- Redis 自研
- Redis Clustert
下面对这几种方案进行简单地介绍:
Redis主从模式
Redis单机版通过RDB或AOF持久化机制将数据持久化到硬盘上,但数据都存储在一台服务器上,并且读写都在同一服务器(读写不分离),如果硬盘出现问题,则会导致数据不可用,为了避免这种问题,Redis提供了复制功能,在master数据库中的数据更新后,自动将更新的数据同步到slave数据库上,这就是主从模式的Redis集群,如下图

主从模式解决了Redis单机版存在的问题,但其本身也不是完美的,主要优缺点如下:
优点:
- 高可靠性,在master数据库出现故障后,可以切换到slave数据库
- 读写分离,slave库可以扩展master库节点的读能力,有效应对大并发量的读操作
缺点:
- 不具备自动容错和恢复能力,主节点故障,从节点需要手动升为主节点,可用性较低
Redis 哨兵模式
为了解决主从模式的Redis集群不具备自动容错和恢复能力的问题,Redis从2.6版本开始提供哨兵模式
哨兵模式的核心还是主从复制,不过相比于主从模式,多了一个竞选机制(多了一个哨兵集群),从所有从节点中竞选出主节点,如下图

从上图中可以看出,哨兵模式相比于主从模式,主要多了一个哨兵集群,哨兵集群的主要作用如下:
- 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。
- 故障切换:当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换master。同时那台有问题的旧主也会变为新主的从,也就是说当旧的主即使恢复时,并不会恢复原来的主身份,而是作为新主的一个从。
哨兵模式的优缺点:
优点:
- 哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。
缺点:
- 浪费资源,集群里所有节点保存的都是全量数据,数据量过大时,主从同步会严重影响性能
- Redis主机宕机后,投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
- 只有一个master库执行写请求,写操作会单机性能瓶颈影响
Redis 自研
哨兵模式虽然解决了主从模式存在的一些问题,但其本身也存在一些弊端,比如数据在每个Redis实例中都是全量存储,极大地浪费了资源,为了解决这个问题,Redis提供了Redis Cluster,实现了数据分片存储,但Redis提供Redis Cluster之前,很多公司为了解决哨兵模式存在的问题,分别自行研发Redis集群方案。
客户端分片
客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则(使用哈希算法),把对Key的访问转发到不同的Redis实例中,查询数据时把返回结果汇集。如下图

客户端分片的优缺点:
**优点:**Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。
缺点:
- 客户端sharding不支持动态增删节点。服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
- 运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。
- 在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如:java项目、PHP项目里共用一套Redis集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套。
代理分片
客户端分片的最大问题就是服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
为了解决这个问题,代理分片出现了,代理分片将客户端分片模块单独分了出来,作为Redis客户端和服务端的桥梁,如下图
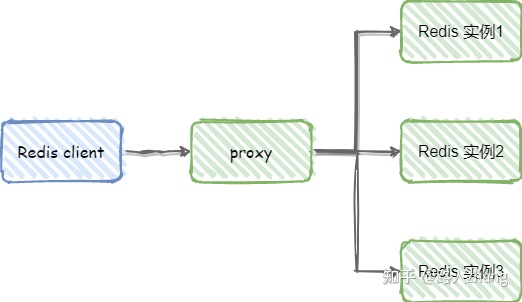
代理模式的优点:解决了服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整的问题。缺点是由于Redis客户端的每个请求都经过代理才能到达Redis服务器,这个过程中会产生性能损失。
常见的代理分片有Twitter开源的Redis代理Twemproxy和豌豆荚自主研发的Codis
Redis Cluster
前面介绍了为了解决哨兵模式的问题,各大企业提出了一些数据分片存储的方案,在Redis3.0中,Redis也提供了响应的解决方案,就是Redist Cluster。
Redis Cluster是一种服务端Sharding技术,Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。
**什么是Redis哈希槽呢?**本来不想详细介绍这个的,但面试确实经常问,还是简单说一下,
在介绍slot前,要先介绍下一致性哈希(客户端分片经常会用的哈希算法),那这个一致性哈希有什么用呢?其实就是用来保证节点负载均衡的,那么多主节点,到底要把数据存到哪个主节点上呢?就可以通过一致性哈希算法要把数据存到哪个节点上。
一致性哈希
下面详细说下一致性哈希算法,首先就是对key计算出一个hash值,然后对2^32取模,也就是值的范围在[0, 2^32 -1],一致性哈希将其范围抽象成了一个圆环,使用CRC16算法计算出来的哈希值会落到圆环上的某个地方。
现在将Redis实例也分布在圆环上,如下图(图片来源于网络)
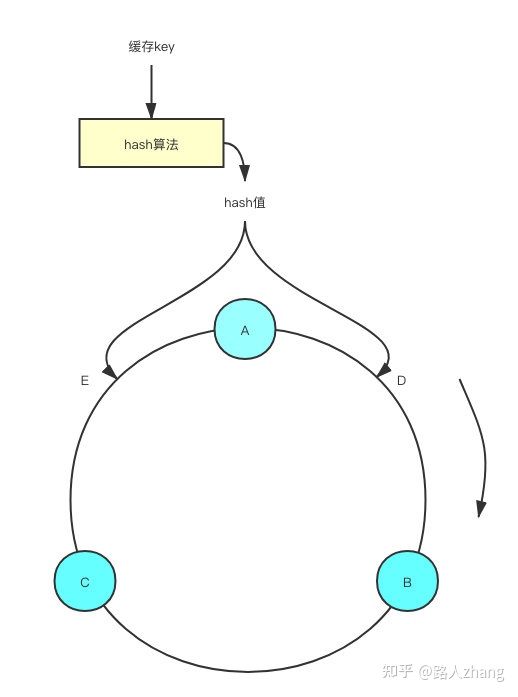
假设A、B、C三个Redis实例按照如图所示的位置分布在圆环上,通过上述介绍的方法计算出key的hash值,发现其落在了位置E,按照顺时针,这个key值应该分配到Redis实例A上。
如果此时Redis实例A挂了,会继续按照顺时针的方向,之前计算出在E位置的key会被分配到RedisB,而其他Redis实例则不受影响。
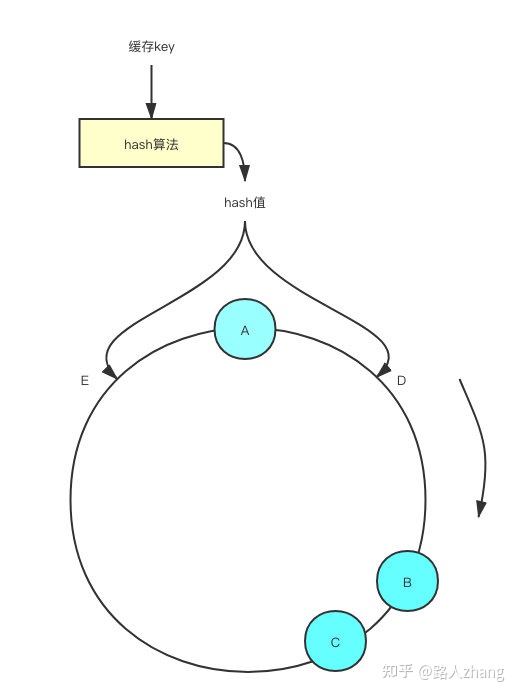
但一致性哈希也不是完美的,主要存在以下问题:当Redis实例节点较少时,节点变化对整个哈希环中的数据影响较大,容易出现部分节点数据过多,部分节点数据过少的问题,出现数据倾斜的情况,如下图(图片来源于网络),数据落在A节点和B节点的概率远大于B节点
为了解决这种问题,可以对一致性哈希算法引入虚拟节点(A#1,B#1,C#1),如下图(图片来源于网络),

那这些虚拟节点有什么用呢?每个虚拟节点都会映射到真实节点,例如,计算出key的hash值后落入到了位置D,按照顺时针顺序,应该落到节点C#1这个虚拟节点上,因为虚拟节点会映射到真实节点,所以数据最终存储到节点C。
虚拟槽
在Redis Cluster中并没有使用一致性哈希,而引进了虚拟槽。虚拟槽的原理和一致性哈希很像,Redis Cluster一共有2^14(16384)个槽,所有的master节点都会有一个槽范围比如0~1000,槽数是可以迁移的。master节点的slave节点不分配槽,**只拥有读权限,**其实虚拟槽也可以看成一致性哈希中的虚拟节点。
虚拟槽和一致性哈希算法的实现上也很像,先通过CRC16算法计算出key的hash值,然后对16384取模,得到对应的槽位,根据槽找到对应的节点,如下图。

使用虚拟槽的好处:
- 更加方便地添加和移除节点,增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了,当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了,不需要停掉Redis任何一个节点的服务(采用一致性哈希需要增加和移除节点需要rehash)
Redis Cluster 结构
上面介绍了Redis Cluster如何将数据分配到合适的节点,下面来介绍下Redis Cluster结构,简单来说,Redis Cluster可以看成多个主从架构组合在一起,如下图

上图看起来比较乱,其实很好理解,上图中一个Redis Cluster有两组节点组成(官方推荐,一般至少三主三从六个节点,画多个节点看起来太乱,所以上图只画了两个主节点),每组节点可以看成一个主从模式,并且每组节点负责的slot不同(假设有4个slot,A组节点负责第1个和第二个slot,B组节点负责第3个和第4个,其中master节点负责写,slave节点负责读)
上图中共有三种线
主备复制的线很好理解,就和主从模式一样,在master库中的数据更新后,自动将更新的数据同步到slave库上
对外服务的线也很好理解,就是外部在对Redis进行读取操作,访问master进行写操作,访问slave进行读操作
Redis Bus的作用相对复杂些,这里简单说下,
首先要知道Redis Cluster是一个去中心化的架构,不存在统一的配置中心,Redis Cluster中的每个节点都保存了集群的配置信息,在Redis Cluster中,这个配置信息通过Redis Cluster Bus进行交互,并最后达成一致性。
配置信息的一致性主要依靠PING/PONG,每个节点向其他节点频繁的周期性的发送PING/PONG消息。对于大规模的集群,如果每次PING/PONG 都携带着所有节点的信息,则网络开销会很大。此时Redis Cluster 在每次PING/PONG,只包含了随机的一部分节点信息。由于交互比较频繁,短时间的几次交互之后,集群的状态也会达成一致。
当Cluster 结构不发生变化时,各个节点通过gossip 协议(Redis Cluster各个节点之间交换数据、通信所采用的一种协议)在几轮交互之后,便可以得知Cluster的结构信息,达到一致性的状态。但是当集群结构发生变化时(故障转移/分片迁移等),优先得知变更的节点会将自己的最新信息扩散到Cluster,并最终达到一致。
其实,上面说了半天也不太容易理解,简单来说Redis Bus是用于节点之间的信息交路,交互的信息有以下几个:
- 数据分片(slot)和节点的对应关系(对应上图中的slot1和slot2在masterA节点上,就是要知道哪个slot在哪个节点上)
- 集群中每个节点可用状态(不断向其他节点发消息看看你挂了没)
- 集群结构发生变更时,通过一定的协议对配置信息达成一致。数据分片的迁移、主备切换、单点master的发现和其发生主备关系变更等,都会导致集群结构变化。(发现有的节点挂了或者有新的节点加进来了,赶紧和其他节点同步信息)
Redis主从架构中数据丢失吗
Redis主从架构丢失主要有两种情况
- 异步复制同步丢失
- 集群产生脑裂数据丢失
下面分别简单介绍下这两种情况:
异步复制同步丢失:
Redis主节点和从节点之间的复制是异步的,当主节点的数据未完全复制到从节点时就发生宕机了,master内存中的数据会丢失。
如果主节点开启持久化是否可以解决这个问题呢?
答案是否定的,在master 发生宕机后,sentinel集群检测到主节点发生故障,重新选举新的主节点,如果旧的主节点在故障恢复后重启,那么此时它需要同步新主节点的数据,此时新的主节点的数据是空的(假设这段时间中没有数据写入)。那么旧主机点中的数据就会被刷新掉,此时数据还是会丢失。
集群产生脑裂:
简单来说,集群脑裂是指一个集群中有多个主节点,像一个人有两个大脑,到底听谁的呢?
例如,由于网络原因,集群出现了分区,master与slave节点之间断开了联系,哨兵检测后认为主节点故障,重新选举从节点为主节点,但主节点可能并没有发生故障。此时客户端依然在旧的主节点上写数据,而新的主节点中没有数据,在发现这个问题之后,旧的主节点会被降为slave,并且开始同步新的master数据,那么之前的写入旧的主节点的数据被刷新掉,大量数据丢失。
如何解决主从架构数据丢失问题?
在Redis的配置文件中,有两个参数如下:
min-slaves-to-write 1
min-slaves-max-lag 10
其中,min-slaves-to-write默认情况下是0,min-slaves-max-lag默认情况下是10。
上述参数表示至少有1个salve的与master的同步复制延迟不能超过10s,一旦所有的slave复制和同步的延迟达到了10s,那么此时master就不会接受任何请求。
通过降低min-slaves-max-lag参数的值,可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往master中写入数据。
这种解决数据丢失的方法是降低系统的可用性来实现的。
Redis集群的主从复制过程是什么样的?
主从复制主要有以下几步:
- 设置服务器的地址和端口号
- 建立套接字连接(建立主从服务器之间的连接)
- 发送PING命令(检验套接字是否可用)
- 身份验证
- 同步(从主库向从库同步数据,分为全量复制和部分复制)
- 命令传播(经过上面同步操作,此时主从的数据库状态其实已经一致了,许主服务器马上就接受到了新的写命令,执行完该命令后,主从的数据库状态又不一致。数据同步阶段完成后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性)
简单解释下全量复制和部分复制:
在Redis2.8以前,从节点向主节点发送sync命令请求同步数据,此时的同步方式是全量复制;在Redis2.8及以后,从节点可以发送psync命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。
- 全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作。
- 部分复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
Redis是如何保证主从服务器一致处于连接状态以及命令是否丢失?
命令传播阶段,从服务器会利用心跳检测机制定时的向主服务发送消息。
因为网络原因在主从复制过程中停止复制会怎么样?
如果出现网络问题断开,会自动重连,并且支持断点续传,接着上次复制的地方继续复制,而不是重新复制一份。
下面说下其中的实现细节,首先需要了解replication buffer和replication backlog
**replication buffer:**主库连接的每一个从库的对应一个 replication buffer,主库执行完每一个操作命令后,会将命令分别写入每一个从库所对应的 replication buffer
**replication backlog:**replication backlog 是一个环形区域,大小可以通过 repl-backlog-size参数设置,并且和 replication buffer不同的是,一个主库中只有一个 replication backlog。

主库会通过 master_repl_offset 记录写入的位置,从库会通过 slave_repl_offset 记录自己读取的位置,这里的位置也叫做偏移量。
刚开始复制数据的时候,上述两者的值相同,且都位于初始位置。每当主库向 replication backlog 写入一个操作,master_repl_offset 就会增加 1,从库复制完操作命令后,slave_repl_offset 也会增加 1。
正常情况下,slave_repl_offset 会跟着 master_repl_offset 变化,两者保持一个小的差距,或者相等。
如果主从库之间的网络连接中断,从库便无法继续复制主库的操作命令,但是主库依然会向 replication backlog 中写入操作命令。
当网络恢复之后,从库会继续向主库请求同步数据,主库通过slave_repl_offset知道从库复制操作命令的位置。这个时候,主库只需要把 master_repl_offset 和 slave_repl_offset 之间的操作命令同步给从库就可以了。
但是前面提到 replication backlog 是一个环形结构,如果网络中断的时间过长,随着主库不断向其中写入操作命令,master_repl_offset 不断增大,就会有从库没有复制的操作命令被覆盖。如果出现这种情况,就需要重新进行全量复制了。
为了避免全量复制的情况,可以通过修改 repl-backlog-size 参数的值,为 replication backlog 设置合适的大小。
这个值需要结合实际情况来设置,具体思路是:从命令在主库中产生到从库复制完成所需要的时间为 t,每秒钟产生的命令的数量为 c,命令的大小为 s,这个值不能低于他们的乘积。考虑到突发的网络压力以及系统运行过程中可能出现的阻塞等情况,应该再将这个值乘以 2 或者更多。
此处参考博客:https://juejin.cn/post/7017827613544546335
了解Redis哈希槽吗?
见Redis Cluster处
Redi集群最大的节点个数是多少?为什么?
16384个
Redis作者的回答:
- Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.
- At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
上面主要说了两点,
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K),也就是说使用2k的空间创建了16k的槽数。虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要8k的心跳包,作者认为这样做不太值得
由于其他设计折衷,一般情况下一个redis集群不会有超过1000个master节点
Redis集群是如何选择数据库的?
Redis 集群目前无法做数据库选择,默认在 0 数据库。
Redis高可用方案如何实现?
常见的Redis高可用方案有以下几种:
- 数据持久化
- 主从模式
- Redis 哨兵模式
- 8 (8 bit) * 1024(1k) = 16K
),也就是说使用2k的空间创建了16k的槽数。虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K`),也就是说需要8k的心跳包,作者认为这样做不太值得
由于其他设计折衷,一般情况下一个redis集群不会有超过1000个master节点
Redis集群是如何选择数据库的?
Redis 集群目前无法做数据库选择,默认在 0 数据库。
Redis高可用方案如何实现?
常见的Redis高可用方案有以下几种:
- 数据持久化
- 主从模式
- Redis 哨兵模式
- Redis 集群(自研及Redis Cluster)









![[Java基础练习-002]综合应用(基础进阶)](https://img-blog.csdnimg.cn/022445a7ea4b4549aaed79cf7a92ecc4.png)